当記事について
要件定義工程にて実施するタスクに「システム方式設計」がありますが、経験が無いとゼロから書いていくのは非常に難しいと思います。
経験者であっても、過去案件の資料をもとに案件の特性に合わせて加筆訂正をしていくことが多いのではないでしょうか。
「でも、良さげな過去案件の資料が無い・・・」という方に朗報です。
TISがシステム方式設計のサンプルを公開してくれていたので紹介していきたいと思います。
システム方式設計 目次
TISのシステム方式設計サンプルの目次は以下のようになっています。
先日、WBSタスク一覧を紹介しましたが、あそこに書かれていたアプリの方式設計はこれぐらいボリュームがある作業となります。
1. はじめに
2. 全体概要
2.1. アプリケーション全体図
2.2. ソフトウェア構成
3.画面処理方式
3.1. 同期処理方式
3.1.1. 処理方式概要
3.1.2. HTTPメソッドの使い分け
3.1.3. ブラウザキャッシュ制御
3.1.4. オートコンプリート
3.1.5. 二重サブミット防止
3.1.6. データの保持
3.1.7. 開閉局
3.1.8. エラー処理
3.1.9. URL設計
3.1.10. コンテンツ更新
3.1.11. ウィルス対策
3.1.12. 複数ウィンドウ/タブの同時操作時の挙動
3.2. 非同期処理方式
3.2.1. 非同期処理方式概要
3.2.2. 非同期処理方式詳細
3.2.3. 非同期処理のエラー時対応
4. バッチ処理方式
4.1. 都度起動バッチ
4.1.1. 処理方式概要
4.1.2. 処理制御
4.1.3. 基本的な処理シーケンス
4.1.4. コミット間隔
4.1.5. 0件データ処理
4.1.6. 処理済みデータの設定
4.1.7. エラー処理
4.2. 常駐バッチ
4.2.1. 処理方式概要
4.2.2. 処理制御
4.2.3. コミット間隔
4.2.4. エラー処理
5. 入力処理方式
5.1. ファイル転送(集信)
5.1.1. 処理方式概要
5.1.2. 処理フロー
5.1.3. 基本構造・責務配置
5.1.4. 開閉局
5.1.5. 入力値精査
5.1.6. エラー処理
5.1.7. リカバリ方法
6. 出力処理方式
6.1. メッセージ仕向け(REST)
(1) 処理フロー
(2) メッセージレイアウト
(3) エラー処理
(4) 開閉局
(5) ログ出力
6.2. ファイル転送(配信)
6.2.1. 処理方式概要
6.2.2. 処理フロー
6.2.3. 基本構造・責務配置
6.2.4. 開閉局
6.2.5. エラー処理
6.2.6. リカバリ方法
6.3. メール送信
6.3.1. 処理方式概要
6.3.2. メール送信方式
6.3.3. メールテンプレート
6.3.4. メールフォーマット
6.3.5. エラー処理
6.3.6. 文字コード
6.3.7. 送信履歴
7. 処理方式共通
7.1. 入力値精査
7.1.1. 入力値精査処理方式の選択
7.1.2. 入力値精査の種類と対象
7.1.2. 単項目精査、項目間精査およびFormで完結しない精査の実現方式
7.2. 文字コード
7.2.1. 基本方針
7.2.2. システムで使用する文字コード
7.2.3. 文字コード変換方式
7.3. DBアクセス処理
7.3.1. コネクション
7.3.2. データベース接続
7.3.3. SQL文の生成
7.3.4.トランザクション制御
7.4. ファイルアクセス処理
7.4.1. ファイルアクセス処理概要
7.4.2. データ入出力
7.4.3. ファイルクリーニング
7.4.4. クリーニングジョブ
7.5. 認証・認可
7.5.1. 認証
7.5.2. 認可
7.5.3. 認証・認可の管理運用
7.6. メッセージ管理方式
7.6.1. 基本方針
7.6.2. メッセージのロード方式
7.7. コード管理方式
7.7.1. 基本方針
7.7.2. コードのロード方式
7.8. 採番方式
7.8.1. 基本方針
7.8.2. 値のリセット方法
7.8.3. 採番処理の実装方針
7.9. 日付・時刻処理方式
7.9.1. 基本概念
7.9.2. 業務日付
7.9.3. システム日時
7.10. ファイル管理
7.10.1. ファイル管理概要
7.10.2. ファイル管理詳細
7.11. 暗号化・ハッシュ化
7.11.1. 暗号化
7.11.2. 項目暗号化
7.12. 負荷分散
7.13. ログ
7.13.1. ログ定義
7.13.2. 各処理方式のログ
7.13.3. ログファイルごとのフォーマット
7.13.4. ログの種類ごとのフォーマット
7.13.5. エラー通知
7.13.6. シェルスクリプトのログ
サンプルの資料一式は以下にあります。
アプリケーション方式設計書サンプル
上記の目次にて、どんな内容を記載するかは実物を見ていただいた方が良いと思いますが、「手早くポイントだけ知りたい」という方のために、ざっくりと解説したいと思います。
1.はじめに
「はじめに」の資料には、ドキュメントの目的や位置付けが書かれています。
この資料って何のために作ってるんだっけ?とか、関連する設計資料との位置付けが分かるためのものです。具体的な設計資料の説明に入る前に、こういった "資料の前提" を記載しておくことで、資料一式の全体感を知ることができます。
2.全体概要
アプリケーションの全体概要と、ソフトウェア構成(OSやMWレベル)を図示した資料です。
プロジェクトの序盤から終盤までいろんな人が目にする資料なので、「ぱっと見で分かる資料」であればあるほど良く、文章でつらつらと書くよりも図で書かれていることが望ましいとされます。
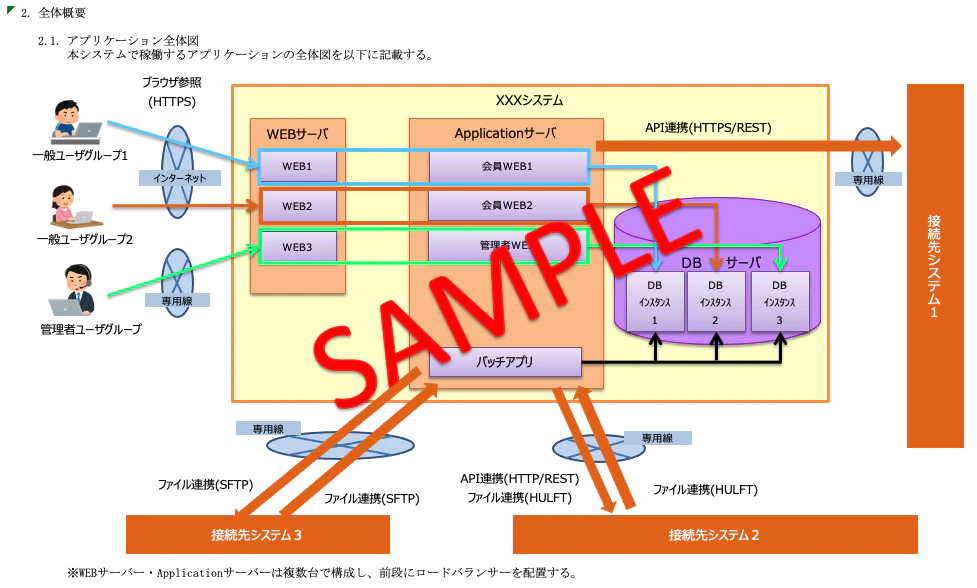
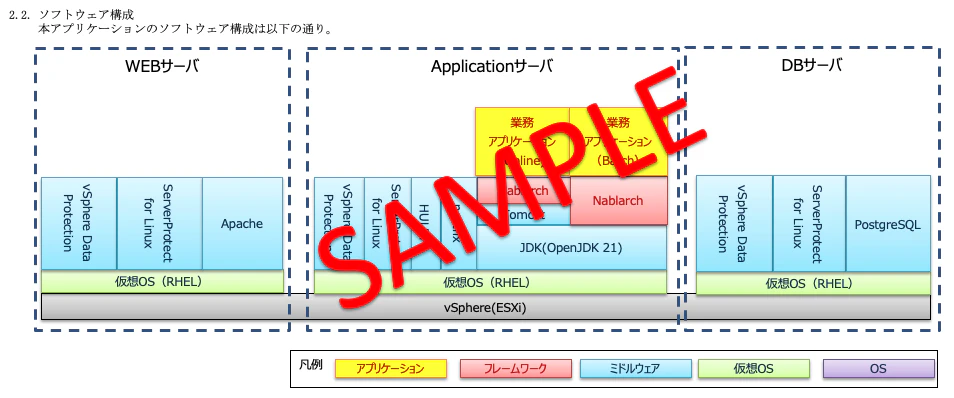
3.画面処理方式
画面処理方式は、大きく「同期処理方式」と「非同期処理方式」に分かれます。
・同期処理方式
処理が完了するまで次の処理が実行されない方式。
・非同期処理方式
処理が並行して行われる方式。前の処理が終わらなくても次の処理が実行される。
同期処理は、「画面操作→処理完了→画面出力」といった一般的な画面処理の流れになるのに対し、非同期処理は「画面操作→処理を待たずに画面出力」といった流れになります。画面の入力をテーブルに格納しておき"処理を受け付けました"といったメッセージを画面に返して、裏でバッチで処理するようなイメージです。
3.1. 同期処理方式
3.1.1. 処理方式概要
「同期処理方式とは」を簡単に記載します。
同期処理方式とは、処理が完了するまで次の処理が実行されない方式で、Webブラウザからのリクエストをもとにデータ照会・更新等の処理を行い、処理結果をWebブラウザへ返却する流れになります。
3.1.2. HTTPメソッドの使い分け
HTTPメソッドの使い分けを記載しています。
HTTPメソッドは、GET,PUT,POST,DELETEなどがありますが、それぞれをどんな時に使うかをシステムの特性に合わせて決めておきます。
今回のサンプルではGETとPUTのみを使うようにしています。

3.1.3. ブラウザキャッシュ制御
ブラウザキャッシュとは、ブラウザなどが取得したウェブページのデータを一時的に保存する機能で、同じページに繰り返しアクセスした際、インターネット上のデータではなく、保存していたデータを参照することで応答性を高めることができます。
TISのサンプルでは、ブラウザキャッシュ制御の手段を2つ挙げた上で、今回のシステムでの方針を定義しています。

3.1.4. オートコンプリート
オートコンプリートとは、過去に入力した文字を記憶して予測表示する機能で、利用者の入力の手間を省くことができます。
TISのサンプルでは、こちらも実現手段を列挙した上で、今回のシステムでの方針を定義しています。

3.1.5. 二重サブミット防止
二重サブミット防止とは、ユーザーが誤ってフォームを二度送信するのを防ぐ技術で、これを防がないと注文や送金、データ登録などで重複が発生し、システム不具合やユーザー混乱の原因となります。
TISのサンプルでは、クライアント側とサーバ側の実現方法を列挙した上で、方針を定義しています。

3.1.6. データの保持
検索結果画面での検索条件の保持や、登録画面から確認画面への入力データを保持する方法です。
以下、TISのサンプル。
なお、文中にある「Nablarch(ナブラーク)」はTISのJavaアプリのフレームワークのことです。
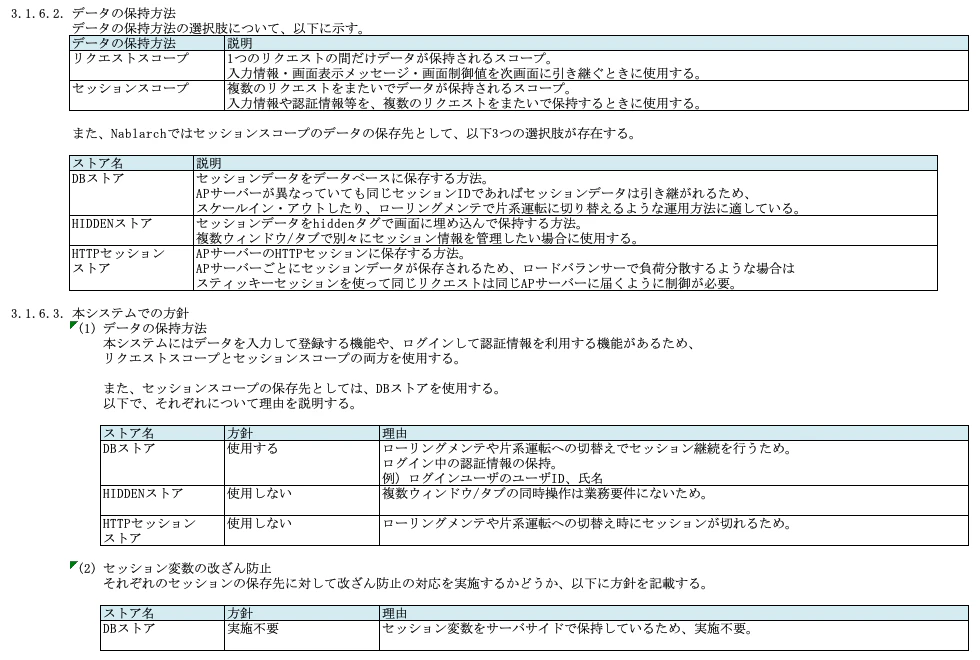
3.1.7. 開閉局
開閉局は、Webアプリケーションを業務時間に応じてサービス提供停止(閉局処理)したり、その再開(開局処理)を行うことです。例えば、システムメンテナンス時へのリクエスト受付停止などの要件への実現手段として検討が求められたりします。
・開閉局の切り替え単位
・開閉局の切り替え方法
・開閉局のチェック方法
などを定義します。
以下、TISのサンプル。

3.1.8. エラー処理
画面におけるエラー処理の方式について定義しています。
一般的に以下の2つに分類されます。
業務例外(業務エラー): ユーザの入力誤りによるエラー。ユーザ側で対処可能。
システム例外(システムエラー): システム要因のエラー。ユーザ側で対処できない。
以下、TISのサンプル。
エラー発生時の共通方針を定義しています。(エラーハンドリング、ロールバック、ログ出力)

3.1.9. URL設計
URL内でのディレクトリやページの階層構造の設計です。
以下、TISのサンプル。

3.1.10. コンテンツ更新
運用担当者が、サーバーを再起動することなく、ウェブサイトのコンテンツを簡単に更新できる方法を定義しています。(私はあまり書いたことがありませんが、TISのサンプルにあったのでそのまま引用します)
以下、TISのサンプル。

3.1.11. ウィルス対策
ファイルアップロード機能がある場合、ウィルス対策ソフトを導入してチェックすることでセキュリティリスクを軽減することができます。
TISのサンプルではアップロード機能が無いとのことで対策不要となっています。
3.1.12. 複数ウィンドウ/タブの同時操作時の挙動
複数ウィンドウや複数タブを開いて同時に操作した場合の挙動について述べています。
TISのサンプルでは、「業務要件が無いので対策行わない方針とする」と書かれていますが、挙動は以下のように書かれています。
なお、本システムではセッションストアにHIDDENストアは使用せずDBストアのみを使用する方針としている。このため、複数ウィンドウ/タブで操作された場合、セッションストアに保存しているデータは後勝ちとなる。
3.2. 非同期処理方式
3.2.1. 非同期処理方式概要
「非同期処理方式とは」を簡単に記載します。
同期処理方式とは、端末から要求が発生してもすぐには処理せず、一定量あるいは一定時間分をまとめて(バックグラウンドで実行する)処理する方式です。
なお、バックグラウンドで実行された処理の結果を確認する必要がある場合は、処理結果を確認できる画面の用意が必要となったりします。
3.2.2. 非同期処理方式詳細
非同期処理方式の実現方法を記載します。
一般的には、画面の入力をテーブル等に格納しておき、バッチを起動(あるいは定時起動)して入力したデータを処理させる方式が多いと思います。
以下、TISのサンプル。

3.2.3. 非同期処理のエラー時対応
非同期処理にてエラーが発生した場合の対応について記載します。
※画面処理でのエラーは前述の「3.1.8.エラー処理」を参照し、バッチ処理でのエラーは後述の「4.2.5.エラー処理」を参照するようにしています。
4. バッチ処理方式
続いて、バッチの処理方式です。
TISのNablarchフレームワークに基づいて説明すると、バッチの処理方式には、「都度実行」「常駐実行」の2種類があります。
・都度実行
ジョブスケジューラから定時起動する方式
・常駐実行
プロセスを起動しておき、一定間隔でバッチを実行する方式
4.1. 都度起動バッチ
4.1.1. 処理方式概要
「都度起動バッチとは」を簡単に述べます。
都度起動バッチとは、ジョブスケジューラからの定刻起動等により、大量データを一括実行する処理方式である(いわゆる一般的なバッチ処理)。
4.1.2. 処理制御
都度起動バッチをどのように実現するのかを記載します。
ジョブスケジューラ(ジョブ管理)、ジョブネット、ジョブの3つで制御するシステムが多いと思います。(JP1とか)
以下、TISのサンプル。
ジョブフロー図が若干分かりづらいので補足すると、ジョブネットAの途中で、ジョブネットBの起動〜終了が前提条件になっており、終了後に後続ジョブが動く例となっています。
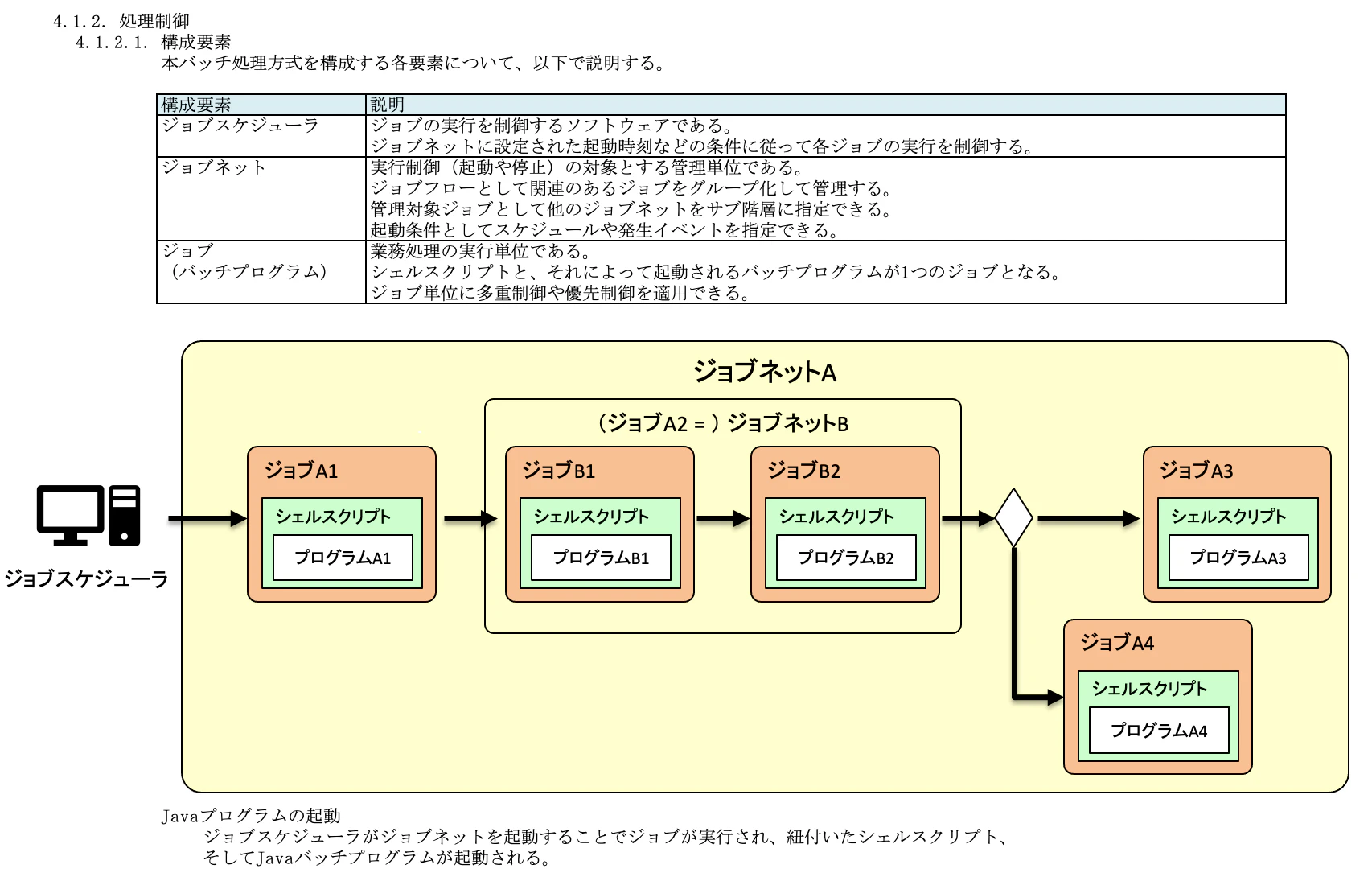
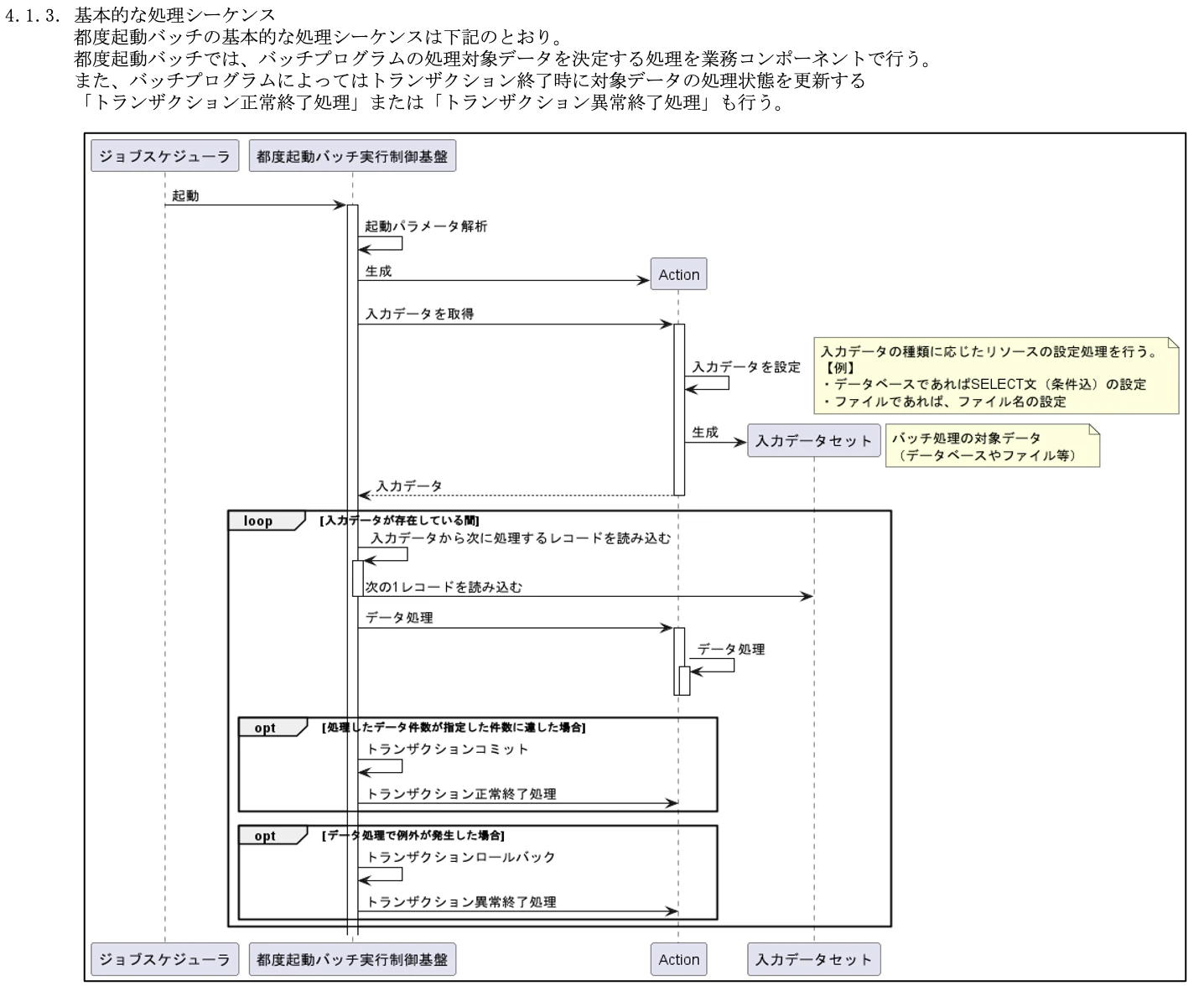
4.1.3. 基本的な処理シーケンス
バッチ処理の基本的な処理シーケンスを説明しています。
これもTISのNablarchフレームワークを利用していることから添付画像のようなシーケンスになっています。
4.1.4. コミット間隔
バッチは大量のデータを更新する機能もあるので、トランザクションをどの程度まとめてコミットするかを定義しておきます。
なお、コミット間隔が大きすぎるとDBのトランザクションログ(リカバリログ)が肥大化し、ディスク容量を圧迫する恐れがあるので、適切な間隔を定義する必要があります。
コミット間隔が大きすぎるとDBのトランザクション管理領域に負荷を与えることがあるので、1000件を基本とし必要に応じて調整を行う。
4.1.5. 0件データ処理
入力データ(DBやファイル)が0件の場合の処理方針を定義します。
「0件の場合は処理をせずにスキップ」が一般的かと思います。
(TISサンプルも同様なのでサンプル掲載は割愛)
4.1.6. 処理済みデータの設定
バッチ処理の途中でプログラムが異常終了した場合に備えて、どこまで処理していたかが分かるようにしておく方法を述べます。
DBの場合は処理済みのフラグを設けたり、ファイルの場合は処理件数を記録したり別ファイルとして書き出したり、といろいろ方法があります。
(TISサンプルはDBはフラグ制御、ファイルは処理済み件数を記録して判断している)
4.1.7. エラー処理
画面と同じく、業務例外とシステム例外があります。
・業務例外
入力ファイルやテーブルの値が不正な値だった場合のエラー。
・システム例外
システム要因のエラー。(入力データを正しても復旧しない)
画面と同じく、エラー発生時の共通方針が書かれていますが、同じ内容なので掲載は割愛します。
4.2. 常駐バッチ
4.2.1. 処理方式概要
「常駐バッチとは」を簡単に述べます。
常駐バッチとは、プロセスを起動しておき、一定間隔でバッチ処理を実行する方式で、例えば、オンライン処理で作成された要求データを定期的に一括処理するような場合に使用します。(例:画面で処理を受け付けて、バッチでメールを送信処理する)
また、常駐バッチをどのように実現するかを述べます。
以下、TISのサンプル。

4.2.2. 処理制御
前述の処理方式について、どのように常駐バッチを起動するか、停止するかを定義する。
(TISのサンプルでは、常駐バッチの死活監視方法についても合わせて述べている)

4.2.3. コミット間隔
常駐バッチにおけるコミット間隔の方針を定義します。
システムの仕様でコミット間隔は変わりますが、基本的に画面からの受け付けたデータに対して1:1の割合でコミットをするのが一般的かと思います。(TISサンプルも同様の記載となっています)
4.2.4. エラー処理
基本的には都度起動バッチと同じですが、常駐バッチでは「エラー発生時の自動リトライ」が追加で記載されています。

5. 入力処理方式
5.1. ファイル転送(集信)
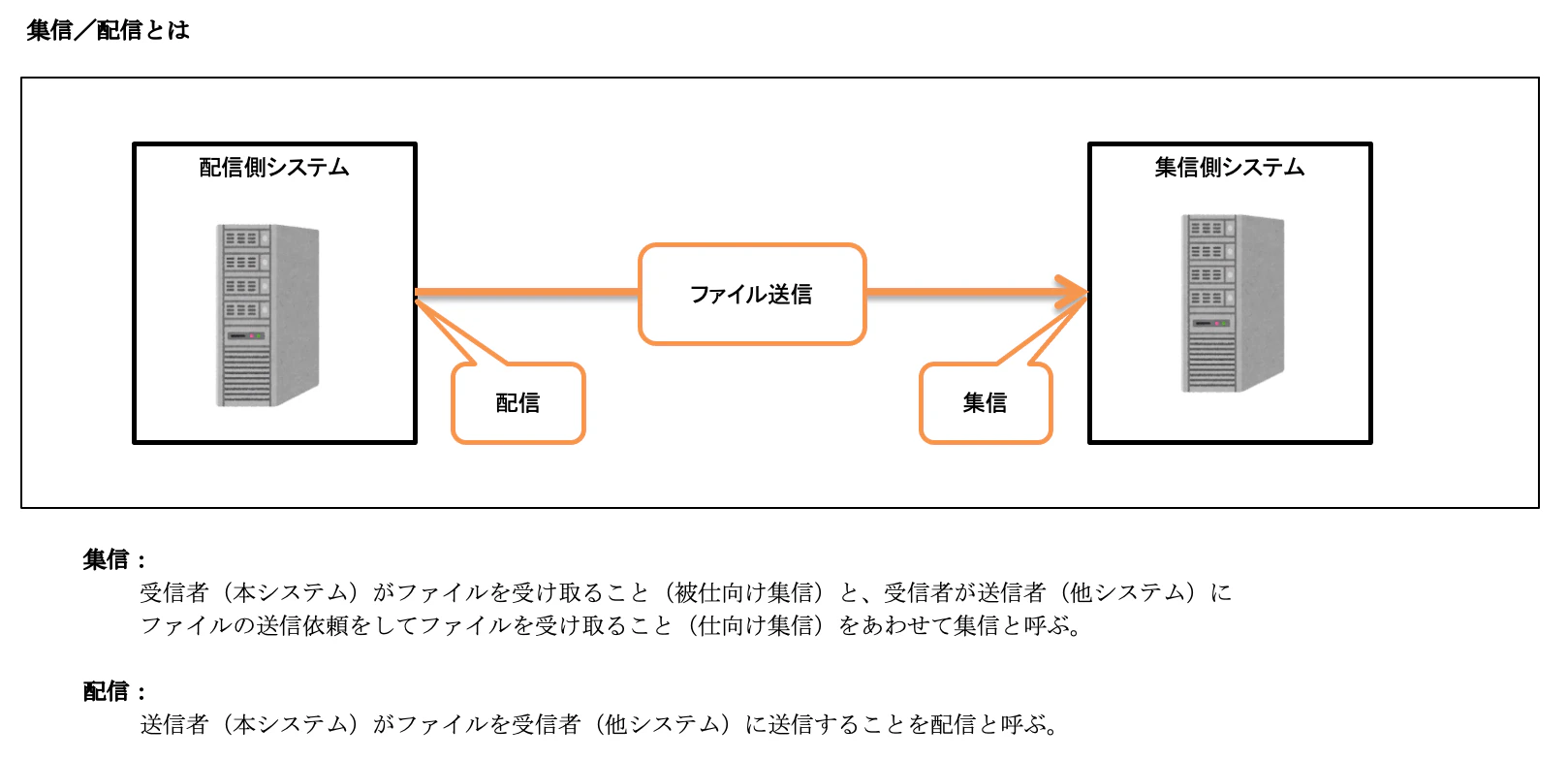
ファイル転送は、ファイルを送信することを「配信」、受け取ることを「集信」と呼びます。
以下、TIS資料から引用します。
5.1.1. 処理方式概要
当該システムでのファイル集信の方式を述べます。
私の経験だけかもしれませんが、HULFTを使うことが多い気がします。
以下、TISのサンプル。

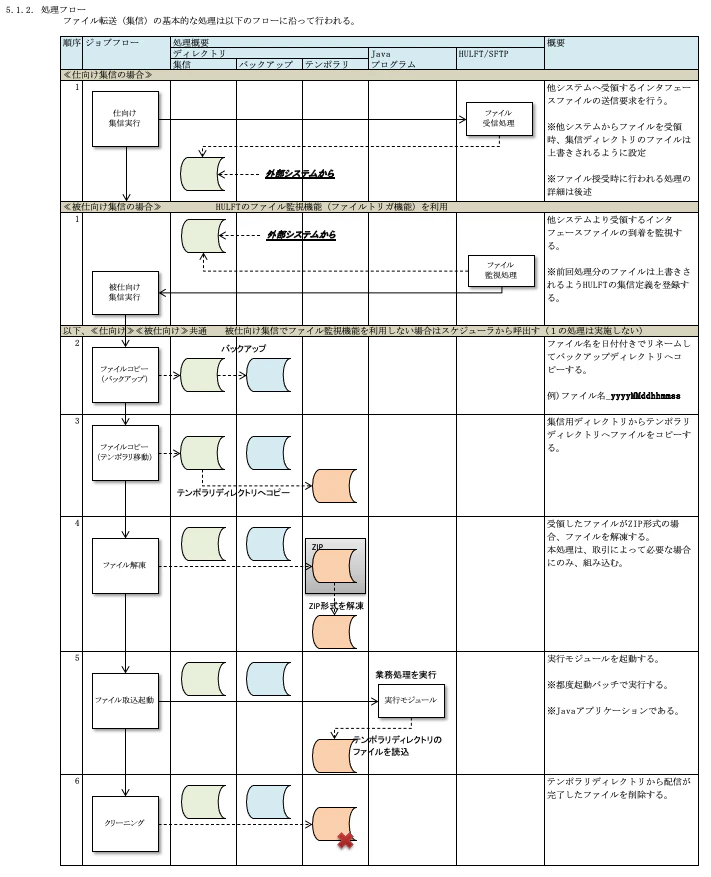
5.1.2. 処理フロー
集信の処理フローを記載します。
TISの資料では、「仕向け集信」と「被仕向け集信」という言葉が使われているので、簡単に説明しておきます。
・仕向け集信
集信側が、配信側のサーバにデータを取りにいく方式。
・被仕向け集信
配信側が、集信側のサーバにデータを保管する方式。
以下、TISのサンプル。
集信データをバックアップディレクトリ、テンポラリディレクトリにコピーした上で、解凍し業務処理を実行しているフロー図です。
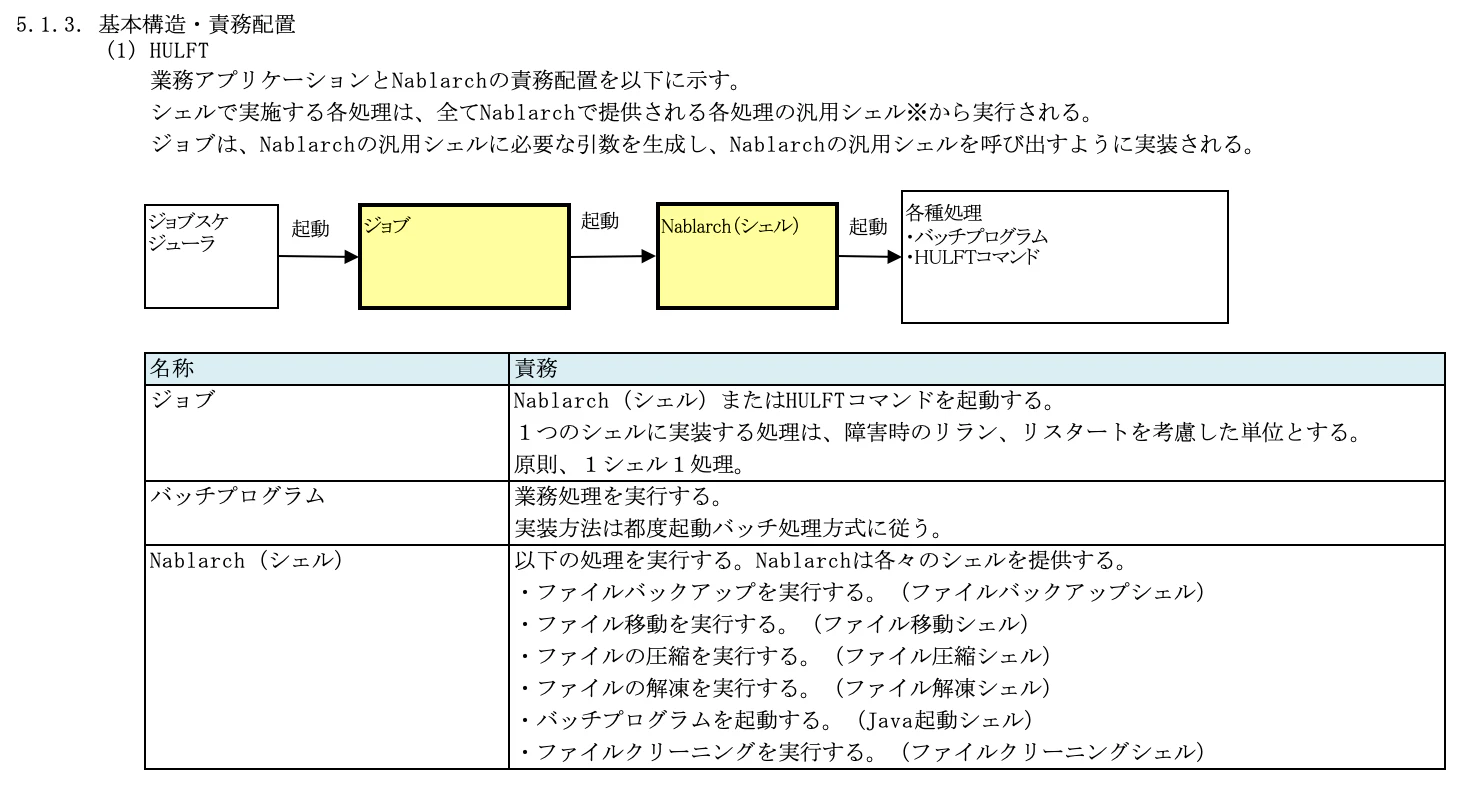
5.1.3. 基本構造・責務配置
業務アプリケーションでの責務を定義するために、基本構造と合わせて述べています。
TISのサンプルでは、Nablarchフレームワークを前提した構造になっており、各業務処理やコマンドはNablarchから起動されるようです。
5.1.4. 開閉局
メンテナンス時間に応じて、ファイル集信を停止(閉局処理)したり、再開(開局処理)する必要がある場合は、その方法を定義します。
TISのサンプルでは、各システム間のファイル連携が定時実行されることから、開閉局の制御は行わないと記載しています。
5.1.5. 入力値精査
受信ファイルに対する入力チェックをどうするかを定義します。
HULFTはフォーマットチェック機能があるので、それを利用する場合は記載します。
基本的には業務アプリケーション側での入力チェックが主流だと思います。(TISサンプルも同様)
5.1.6. エラー処理
ファイル集信のエラー処理に関して述べます。
バッチジョブにファイル集信が組み込まれているのでバッチジョブとしてエラーを検出するのが一般的かと思います。(バッチプログラムでエラーは「4.1.7.エラー処理」を参照)
TISサンプルも同様となっています。
5.1.7. リカバリ方法
ファイル集信処理が発生した場合のリカバリ方法を記載します。
ファイル集信時に障害が発生した場合と、ファイル集信後に障害が発生した場合のパターンがあるので、それぞれのリカバリ方針を定義しておきます。
以下、TISのサンプル。

6. 出力処理方式
ここからは出力処理の方式となります。
TISのサンプルでは、以下の3つについて述べています。
・メッセージ仕向け(REST)
・ファイル転送(配信)
・メール送信
6.1. メッセージ仕向け(REST)
メッセージ仕向けとは、メッセージ送信だと思っていただいてOKです。
メッセージ連携というと、私はメッセージキューのイメージが強いのですが、TISのサンプルでは、API連携もメッセージに含まれているようです。
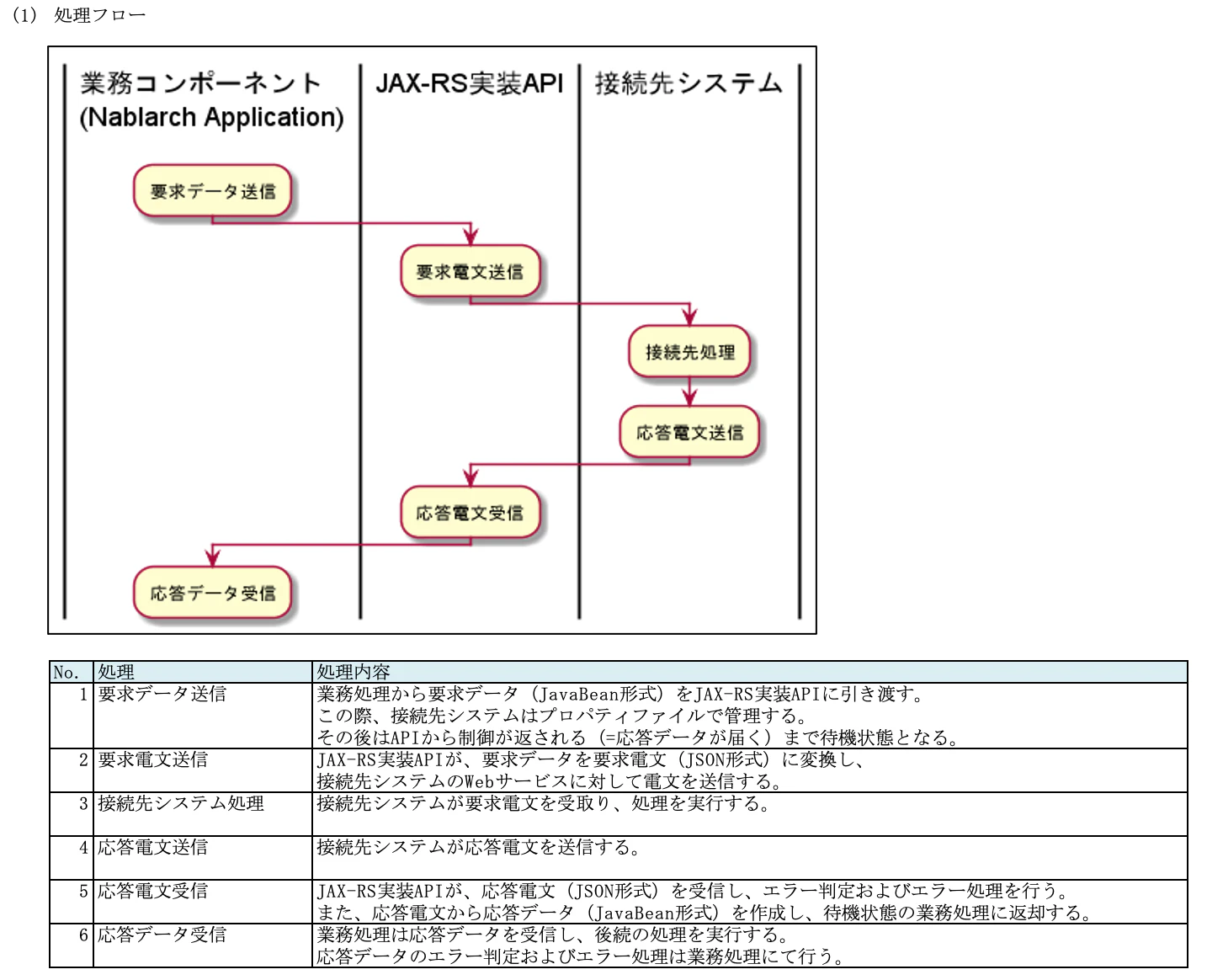
(1) 処理フロー
これまでと同様に、どのような方式で、メッセージ仕向け(メッセージ送信)を実現するのか方針を定義します。
TISのサンプルは以下の通り。
本システム側に接続システムの処理を呼び出すためのAPIを用意する方式となっています。
ちなみに、JAX-RS実装APIとは、「JavaでRESTfulなWEBサービスを実装するためのAPI仕様」だそうです。
(2) メッセージレイアウト
JSONが一般的だと思いますが、CSVファイルでやりとりしたい、と言われる可能性もあるかもしれないので定義しておきます。
(3) エラー処理
想定されるエラーと発生時のエラー処理を記載します。

また、API連携においては、接続先システムのトランザクション制御ができないため、エラーやタイムアウトが発生した場合にデータの不整合が発生してしまう可能性があります。
TISのサンプルでは、こういった不整合状態を抑制するための、業務アプリの設計指針を定義しています。

さらに、TISのサンプルでは、不整合が生じた場合の「処理のリトライ」についても記載されています。

(4) 開閉局
APIの呼び出しにおいての開閉局の方法を定義します。
TISのサンプルでは、画面からAPIを呼び出す仕様のようで、画面側で開閉局が制御されるため、APIでの開閉局制御は行わない方針となっています。
(5) ログ出力
ログ出力の方針について述べます。
TISサンプルでは基本的に送受信したパラメータを全てログに出力する方針とのこと。
6.2. ファイル転送(配信)
6.2.1. 処理方式概要
ファイル配信の処理方式について記載します。
基本的に、ファイル集信と同様になると思います。
(TISのサンプルでは、HULFTとSFTPを使用する旨が書かれていますが、集信と同じ内容なので掲載は割愛します)
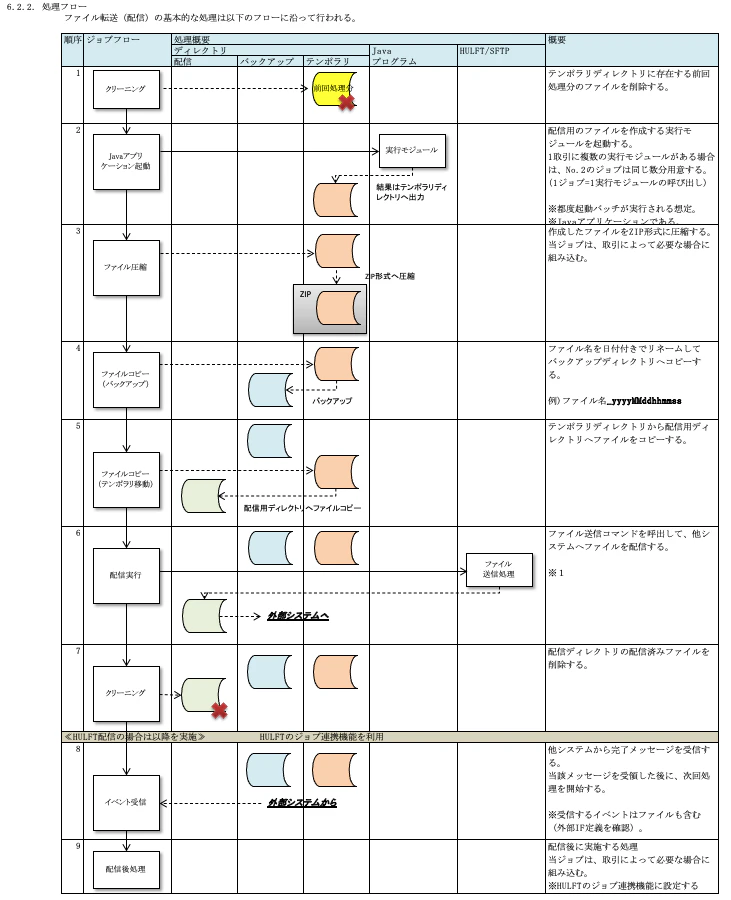
6.2.2. 処理フロー
ファイル配信の処理フローを記載します。
前回データの削除や、バックアップ要否、配信するファイルの保管場所などを整理する必要があります。
以下、TISのサンプルです。
6.2.3. 基本構造・責務配置
ファイル集信と同様のため割愛。
6.2.4. 開閉局
ファイル集信と同様のため割愛。
6.2.5. エラー処理
ファイル配信でエラーが発生するパターンとしては、「配信ファイルの作成処理(業務アプリ)」と、「ファイル配信(HULFT配信)」での2パターンが考えられます。
業務アプリのエラーについては、バッチ処理のエラーと同様。
HULFT配信のエラーについても、HULFTがエラーコードおよびログを出力し、ジョブスケジューラにて検出される流れとなるのが一般的です。(TISも同様のためサンプルは割愛)
6.2.6. リカバリ方法
前述の障害が発生した場合のリカバリ方法を記載します。
基本的にはファイルを再送信流れとなります。(TISも同様のためサンプルは割愛)
6.3. メール送信
6.3.1. 処理方式概要
メール送信をどのように実現するか処理方式を記載します。
TISのサンプルでは、画面→常駐バッチを経て、Nablarchフレームワークのメール送信機能を用いて送信する流れとなっているようです。

6.3.2. メール送信方式
前述の方式から、以下のような具体的な設計方針を記載します。
メールのTO/CC/BCCの設定方針、宛先の合計数、添付ファイル有無とサイズ・暗号化要否など。
TISのサンプルでは、定型メールと非定型メールが選べるとのことで、その詳細を記載しています。

6.3.3. メールテンプレート
メールテンプレートの手段について記載します。
TISのサンプルでは、Nablarchフレームワークで機能が提供されているらしく、その機能について説明をしています。

6.3.4. メールフォーマット
メッセージ形式はテキストやHTML、リッチテキストなどが選べたりもするので、どれにするかを明記しておきます。

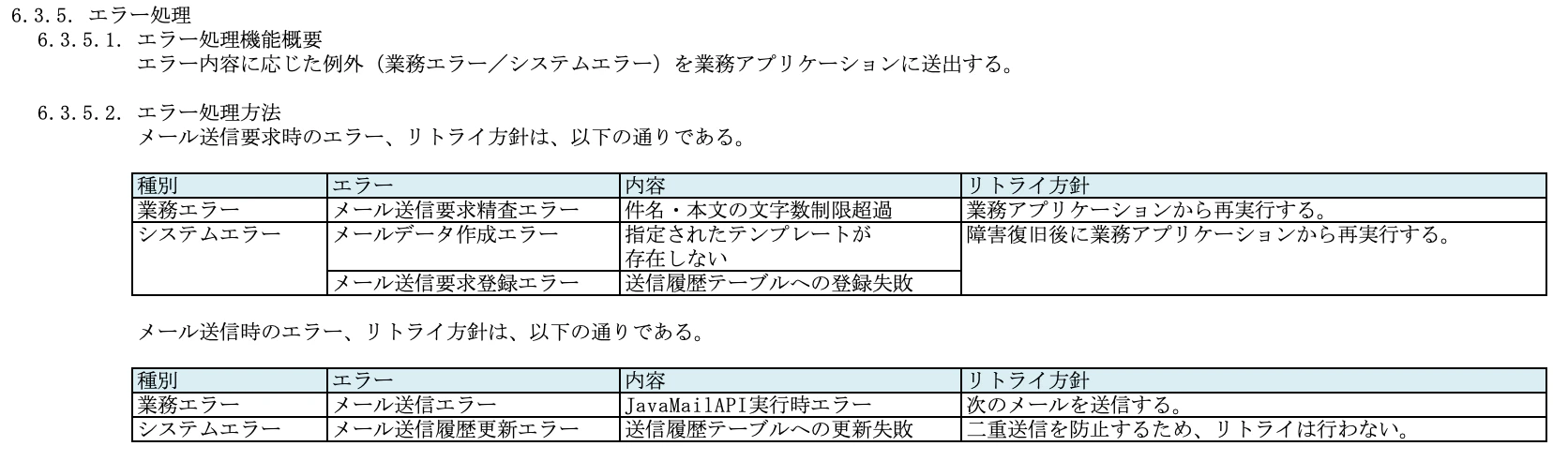
6.3.5. エラー処理
メール送信では、「メール送信要求時のエラー」と「メール送信時のエラー」に分類できます。
それぞれのケースで、想定されるエラー内容とエラー発生時のリトライ方針を記載します。
6.3.6. 文字コード
メールの文字コードを定義します。
TISのサンプルでは「UTF-8」となっています。
6.3.7. 送信履歴
送信履歴の保管有無と、保管方法、削除方法を記載します。
TISのサンプルでは、DBに送信履歴を保管し、バッチで定期的に削除する旨が書かれています。
7. 処理方式共通
7.1. 入力値精査
いわゆる入力チェックの種類やその実現方式を記載します。
単項目チェック、項目間チェック、それ以外のチェックと大きく3つに分類されます。

また、それぞれの実現方法についても記載します。
単項目チェックは、アプリ基盤チームが用意した共通コンポーネント(アノテーション)で実現することが多いと思います。

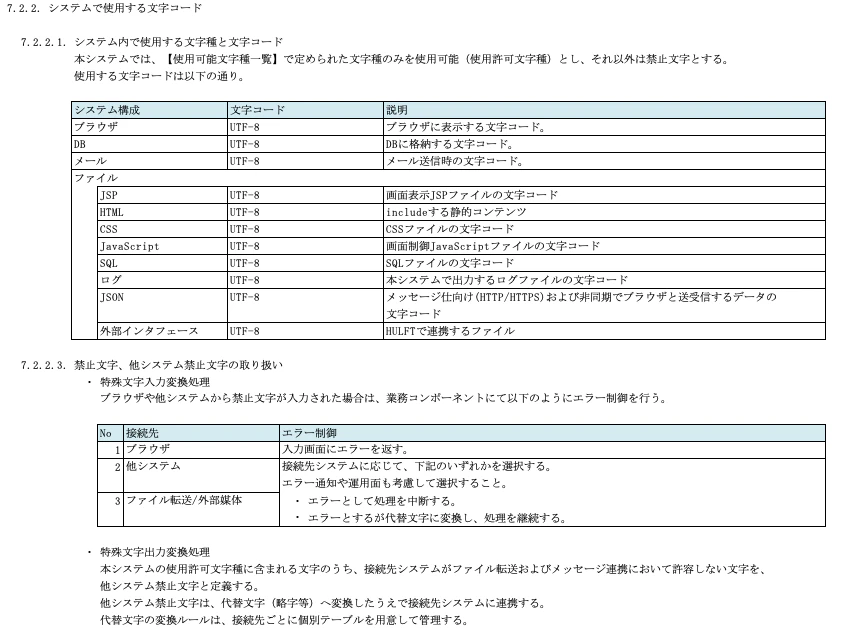
7.2. 文字コード
文字コードについては、システム内で扱う文字コードを決めるだけでなく、他システムと連携するメッセージやファイルの文字コード変換をどちらで行うかの方針を決めておく必要があります。

システム内で扱う文字は、UTF-8が主流ですが、一昔前のシステムだとShift_JISも多いと思います。また、許可する文字と合わせて「禁止文字」への対応も記載しておきます。
文字コードの変換はどのような手段で変換するかを決めておきます。(TISのサンプルではHULFTの変換機能を使うようです)

文字コードの参考資料として以下も合わせてどうぞ。
(参考)TIS_文字の扱い
7.3. DBアクセス処理
7.3.1. コネクション
データベースの接続処理には、比較的大きなコストがかかるため、コネクションの初期化回数を減らすことで性能面の大幅な改善につながります。ただその一方で、コネクションを保持数に比例してメモリリソースを消費するため、アプリケーションに適したコネクション方式を選択する必要があります。
以下、TISのサンプル。

7.3.2. データベース接続
データベース接続機能の実装方法について記載します。
一般的に、アプリケーションがデータベースにアクセスする際、データソースを使うことで、JDBCドライバーの設定やデータベース依存の部分を簡素化でき、プログラムの移植生を向上することができます。
以下、TISのサンプル。

7.3.3. SQL文の生成
SQL文の書き方について方針を記載します。
SQLインジェクション攻撃へのセキュリティ対策として、あるいはメンテナンス時の可読性を高めるためにSQL文の記載ルールを決めておく必要があります。
以下、TISのサンプル。

7.3.4.トランザクション制御
(1) トランザクションの開始と終了
基本的に、トランザクションの開始と終了は個別のプログラムで意識しない(共通コンポーネントで制御)ことが多いと思います。その旨を方針と記載します。
以下はTISのサンプルで、例によってNablarchフレームワークで制御される旨が書かれています。

(2) トランザクション分離レベル
トランザクション分離レベルとは、複数のトランザクションが同時に実行される場合に、どの程度のデータの不整合(同時実行による矛盾)を許容するかを決める設定のことです。分離レベルが高いほど、データの一貫性や整合性が保たれますが、同時実行性が低くなり性能低下の可能性もあります。
以下、TISのサンプルですが、知識が無いと理解が難しいと思うので補足します。

まず、ファジーリードとファントムリードは、読み取り操作中に発生するデータの整合性問題を指す用語です。以下詳細。
| 項目 | ファジーリード(Fuzzy Read) | ファントムリード(Phantom Read) |
|---|---|---|
| 意味 | 同じデータを複数回読み取る際に、途中で変更されることによって結果が異なること | 条件を満たすデータが途中で追加・削除され、その結果、再度クエリを実行した際に異なる結果が得られること |
| 発生状況 | 同じデータが異なるトランザクションによって変更される場合 | 特定の条件でデータを検索した後、その条件を満たすデータが追加・削除される場合 |
| 具体例 | トランザクションAがデータを1回読み取った後、別のトランザクションBがそのデータを更新する | トランザクションAが売上金額1000円以上の注文を読み取った後、別のトランザクションBが新しい注文を追加する |
そして、「READ COMMITTED」は、一般的によく使われるトランザクション分離レベルの一つで、他のトランザクションがコミットしたデータのみを読み取る設定です。読み取り操作中のデータ不整合を抑えることができますが、ファジーリードやファントムリードなどの現象を完全に防ぐわけではありません。
(TISサンプルはユーザビリティを優先して、ファジーリードとファントムリードを許容していると思われます)
(3) 処理のタイムアウト
長時間実行される処理があると、CPUやメモリを不必要に消費してしまいます。これを防ぐためにタイムアウト設定を行うことで、処理が異常に長引くことを防ぎ、リソースを無駄にしないようにします。
以下、TISのサンプル。

(4) 排他制御
排他制御は、複数のトランザクションが同時にデータを操作する場合に生じる競合や不整合を防ぐために必要となります。
要件に応じて、楽観的ロックと悲観的ロックを組み合わせて使うのが一般的かと思います。

なお、楽観的ロックをするにしても、どの単位で制御するかは業務的な仕様に基づいて検討しなければなりません。

7.3.5.データクリーニング
システムのパフォーマンス向上やデータの整合性を維持するために、データクリーニングによって不要なデータの削除を行う必要があります。
データの削除には「物理削除」と「論理削除」があり、それぞれ業務要件に基づいて決定します。
以下、TISのサンプル。

7.4. ファイルアクセス処理
ファイルにおけるデータの入出力方法や、ファイルクリーニングについて定義します。
7.4.1. データ入出力
データの入出力方法について、TISのサンプル。

Nablarchのフレームワーク機能を使います、とだけ書かれており、その詳細は以下のサイトに見ることになります。
(参考)Nablarch_データバインド
ざっくり機能概要を読み解きました。以下の通り。
Nablarchのデータバインド機能は、アプリケーションとファイル間のデータの受け渡しを簡単に行うための仕組みを提供しています。データのマッピングが自動で行われることでコードの記述量が減り、開発の生産性を高めることができるようです。
7.4.2. ファイルクリーニング
ファイルクリーニング機能の仕様統一や実装の負荷軽減を目的に、ファイルクリーニング機能をアプリ基盤チームから提供することも多いと思います。
以下、TISのサンプル。

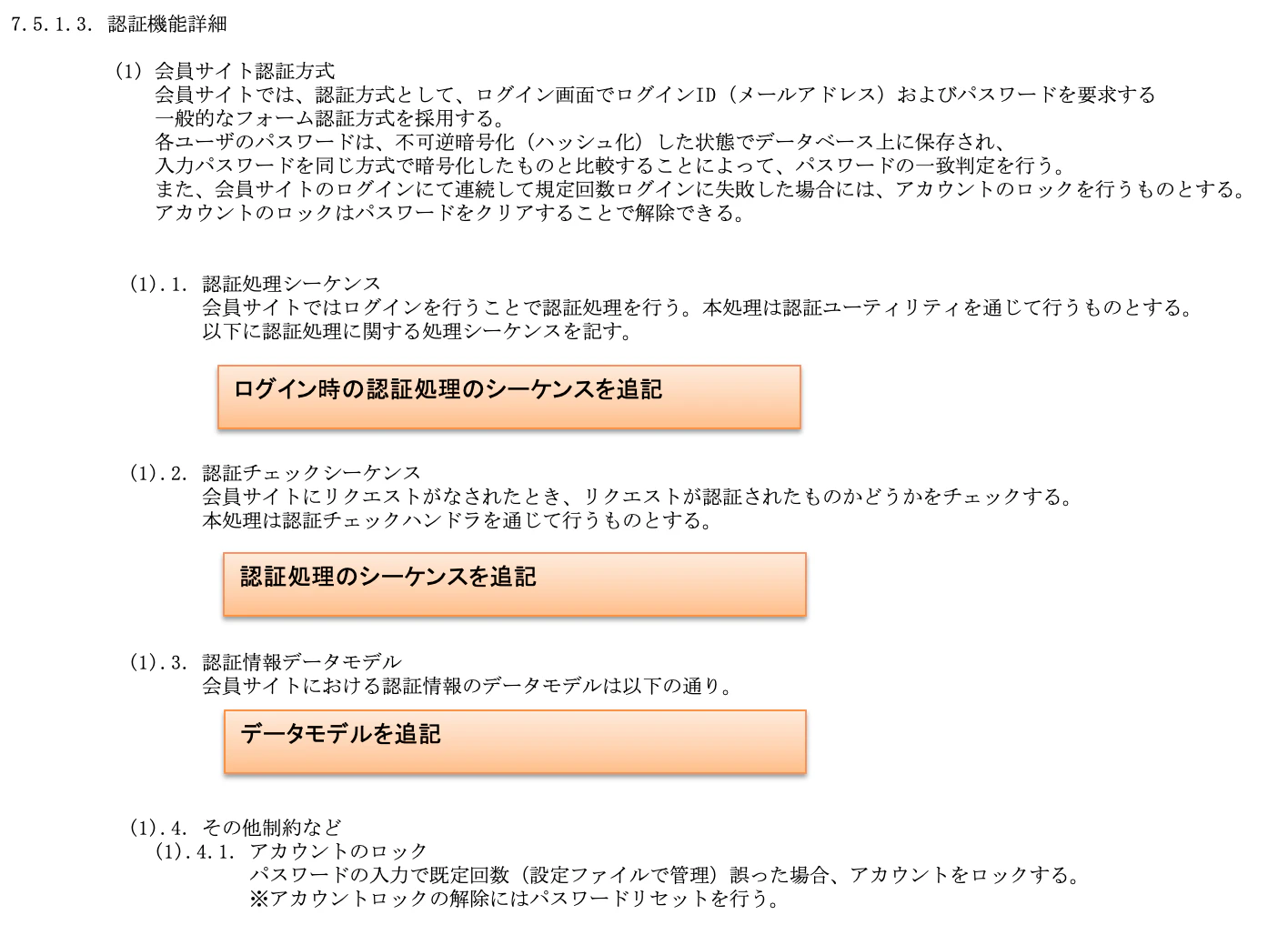
7.5. 認証・認可
認証・認可の実現方法を記載します。
7.5.1. 認証
認証とは、システムにアクセスする際、正規の利用者であることをチェックするプロセスです。利用者IDとパスワードの組み合わせでチェックするのが一般的です。
以下、TISのサンプル。
会員サイトと管理者サイトの2種類があり、それぞれの認証方法を定めています。

なお、認証処理のシーケンスも記載した方が良いのですが、TISのサンプルでは省略されています。
7.5.2. 認可
認可とは、ログインユーザーに対して、どの操作やデータにアクセスできるかを決定するプロセスです。ユーザーの役割や権限に基づいて、システム内で許可されるアクションを制御します。例えば、管理者は全ての機能にアクセスでき、一般ユーザーは限られた機能のみ利用できるといった制限を設けることが認可の役割です。
以下はTISのサンプルで、アクセスする権限に応じたグループ設定を行なっています。

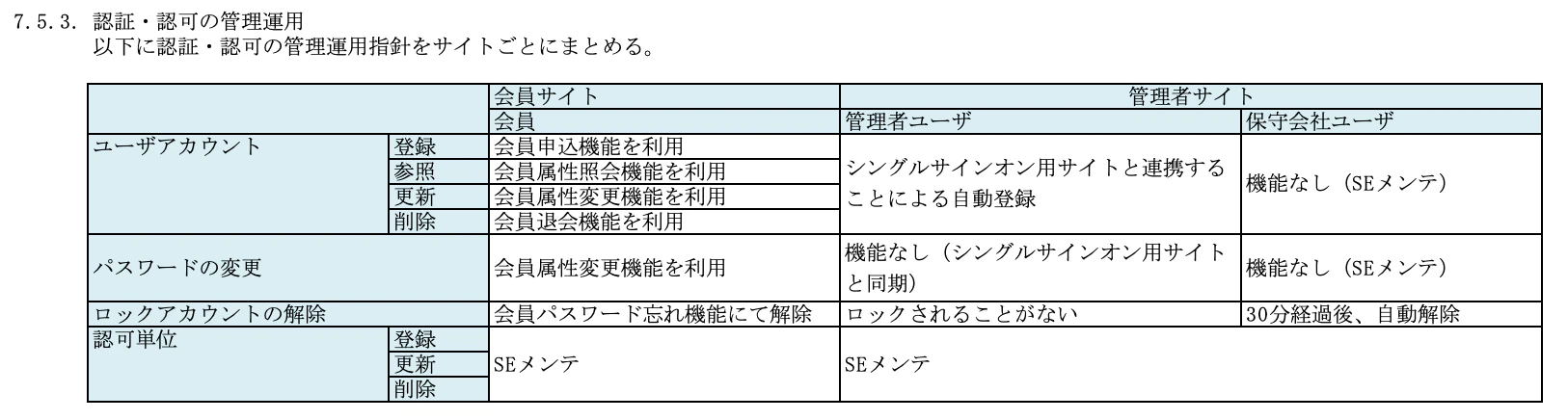
7.5.3. 認証・認可の管理運用
認証・認可に関する管理運用について、どのようにするかを整理します。
業務要件によるところが多いとは思いますが、どのようにユーザアカウントを登録したり、どのように認可グループを更新するか、といったことは決めておく必要があります。
以下、TISのサンプル。
なお、SEメンテとは、機能は用意せずにデータ更新やプログラム改修によって実現するものと思われます。
7.6. メッセージ管理方式
画面やバッチで出力するメッセージの管理方式を記載します。
以下、TISのサンプル。これもNablarchフレームワークに基づいた記載となっています。

7.7. コード管理方式
画面やバッチで使用するコードの管理方式を記載します。
以下、TISのサンプル。これもNablarchフレームワークに基づいた記載となっています。

7.8. 採番方式
システム内で一意な識別子を適切に生成・管理するため、採番方式を定義します。
7.8.1. 基本方針
一般的な採番方法として以下の2種類があります。
・テーブルを使った採番
・シーケンスを使った採番
| 項目 | テーブルを使った値の採番 | シーケンスを使った値の採番 |
|---|---|---|
| 概要 | 採番専用のテーブルを使用して採番処理を行う | シーケンスオブジェクトを使って連番を生成する |
| 一貫性 | トランザクションがロールバックされると、採番もロールバックされ、抜け番が防げる | シーケンスはロールバック時に戻らないため、抜け番が発生する可能性がある |
| 同時処理対応 | テーブルロックを使い、同時に複数のトランザクションで採番要求があっても一意な値を確保 | ロック待機が発生しにくく、同時に複数の採番要求があっても高速に処理される |
| 処理速度 | トランザクション中にロックがかかるため、やや遅くなる可能性がある | ロックが少ないため、非常に高速で処理できる |
| デメリット | テーブルロックによるパフォーマンス低下の可能性 | ロールバック時にシーケンスの値が戻らないため、抜け番が発生する可能性がある |
| 用途 | 業務処理の整合性を重視し、抜け番を防ぎたい場合に適している | 高速な処理が求められる場合や、大量の同時要求がある場合に適している |
以下、TISのサンプル。
・テーブルを使った値の採番

・シーケンスを使った値の採番

7.8.2. 値のリセット方法
システムの運用上、システム障害復旧などを目的に採番をリセットしたい場合があります。その方法について定義します。

7.9. 日付・時刻処理方式
システムと業務上の日付が違うことがあり、それぞれの定義や日付の取得方法を記載します。
7.9.1. 基本概念
・システム日時
システムが動作しているOSから提供される現在の日時で、一般的に認識される日付と基本的に一致します。
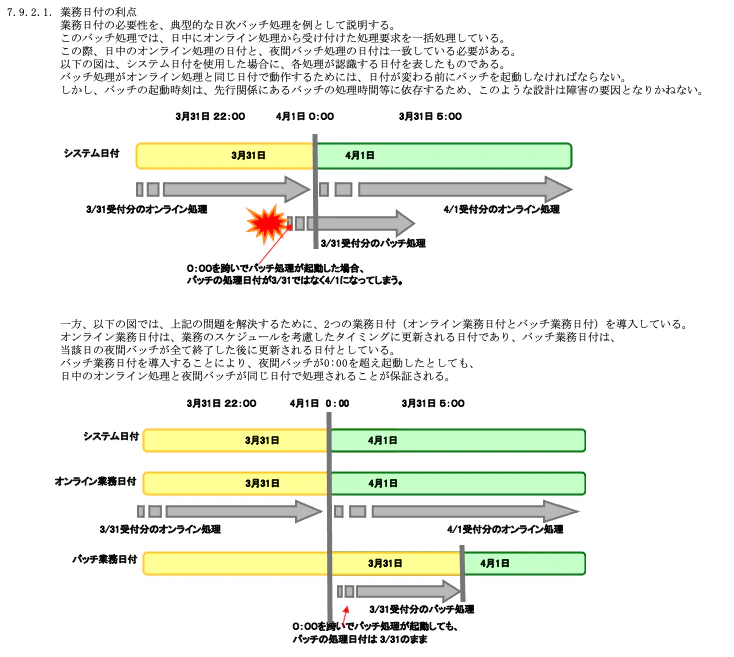
・業務日付
システムの稼働や特定の運用イベントに基づいて設定される日付で、通常のカレンダーの日付とは一致しない場合があります。(例えば、"4月1日 3:00" を "3月31日 27:00" と解釈する場合があります)
TISのサンプルに業務日付の利点が説明されているので引用します。
7.9.2. 業務日付の取得や更新方法
業務日付の取得については、業務日付を取得する共通のコンポーネントを作成するのが一般的です。
また、業務日付の更新は、業務仕様に基づいて定められたタイミングでバッチで更新することが多いと思います。
以下、TISのサンプルですが、Nablarchフレームワークの機能にて取得する方針のようです。

7.10. ファイル管理
7.10.1. ファイル管理概要
アップロードされた、あるいは外部システムから連携されたファイルをどのように管理するかを定義します。
方法としては、以下の2つがあります。
・DBにファイルを保持する
・ディレクトリに保持する
TISのサンプルは以下の通り。

7.10.2. ファイル管理詳細
ファイルをDBに保持する場合と、ディレクトリに保持する場合のそれぞれについて、どのように管理するのか具体的に記載します。
以下、TISのサンプル。
・ファイルをDBに保持する場合

・ファイルをディレクトリに保持する場合

上記の引用にリンクが書かれているので、掲載しておきます。
Nablarch「7.5.ファイルパス管理」
https://nablarch.github.io/docs/5u21/doc/application_framework/application_framework/libraries/file_path_management.html
7.11. 暗号化・ハッシュ化
7.11.1. 暗号化
データの暗号化は、情報が不正にアクセスされた場合でも内容が解読できないように保護するために必要となります。暗号化を行うことにより、機密情報の漏洩を防ぎ、データが盗まれたり改ざんされたりするリスクを低減できます。
以下、TISのサンプル。

7.11.2. 項目暗号化(ハッシュ化)
項目暗号化とは、特定のデータ項目(例えば、パスワードや個人情報)を暗号化して保存する手法のことです。
例えば、ディスク全体を暗号化していたとしても、何かしらの方法でパスワードを格納しているデータベースにアクセスされてしまうとパスワードが漏洩してしまうリスクがあります。
こういったリスクに備えて、データベースにアクセスされたとしても、重要なデータは不可逆の暗号化(ハッシュ化)をしておくことで被害を抑えることができます。
以下、TISのサンプル。

上記の引用にリンクが書かれているので、掲載しておきます。
Nablarch「PBKDF2を用いたパスワード暗号化機能サンプル」
https://nablarch.github.io/docs/5u21/doc/examples/01/0101_PBKDF2PasswordEncryptor.html
7.12. 負荷分散
処理の負荷分散について、対象毎に方法を記載します。
以下、TISのサンプル。

7.13. ログ
ログ出力の方式を記載します。
7.13.1. ログ定義
(1) ログレベル
ログレベルと、本システムでの出力方針を定義します。
以下、TISのサンプル。

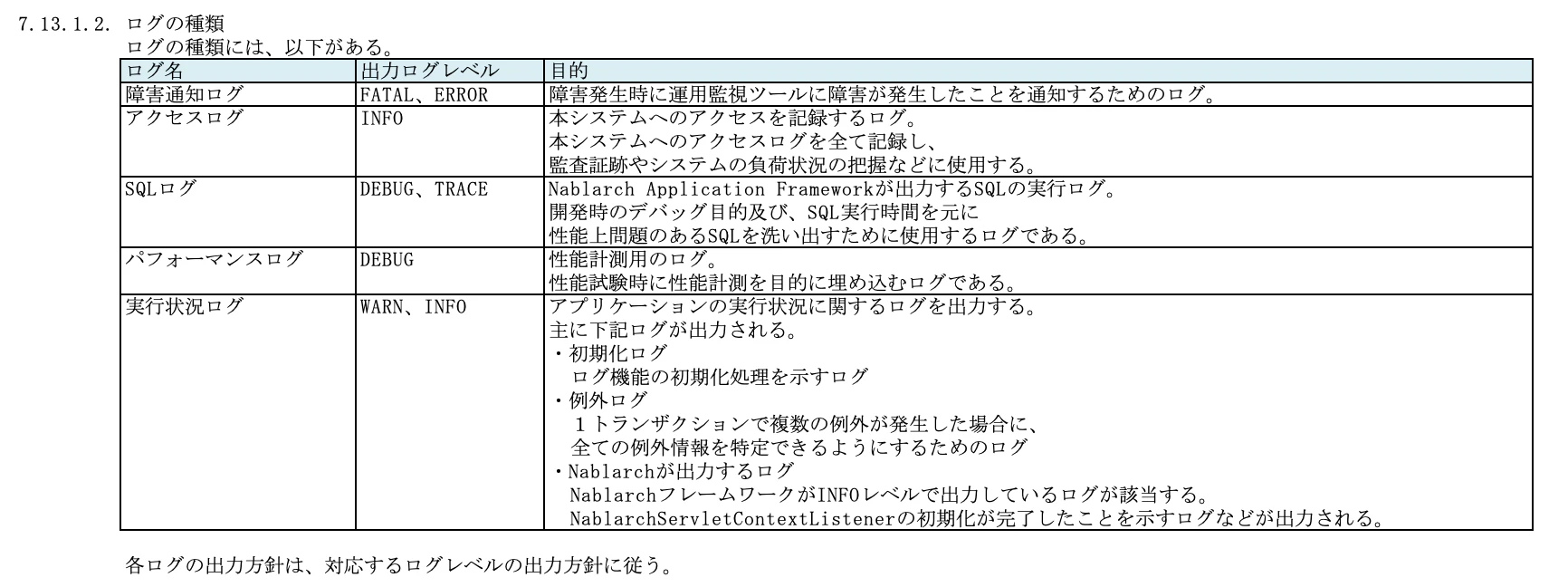
(2) ログの種類
ログには様々な種類がありますので、どういったログがあるのかを一覧で記載します。
(3) 文字コード
ログファイルの文字コードを定義します。一般的にはUTF-8かと思います。
(TISのサンプルもUTF-8)
(4) ログのマスキング
ログに出力するもので重要度が高い項目はマスキングを行うことで、ログ漏洩時の被害を抑えることができます。

7.13.2. 各処理方式のログ
各処理方式について、どのようなログファイルが出力されるかを一覧で整理します。
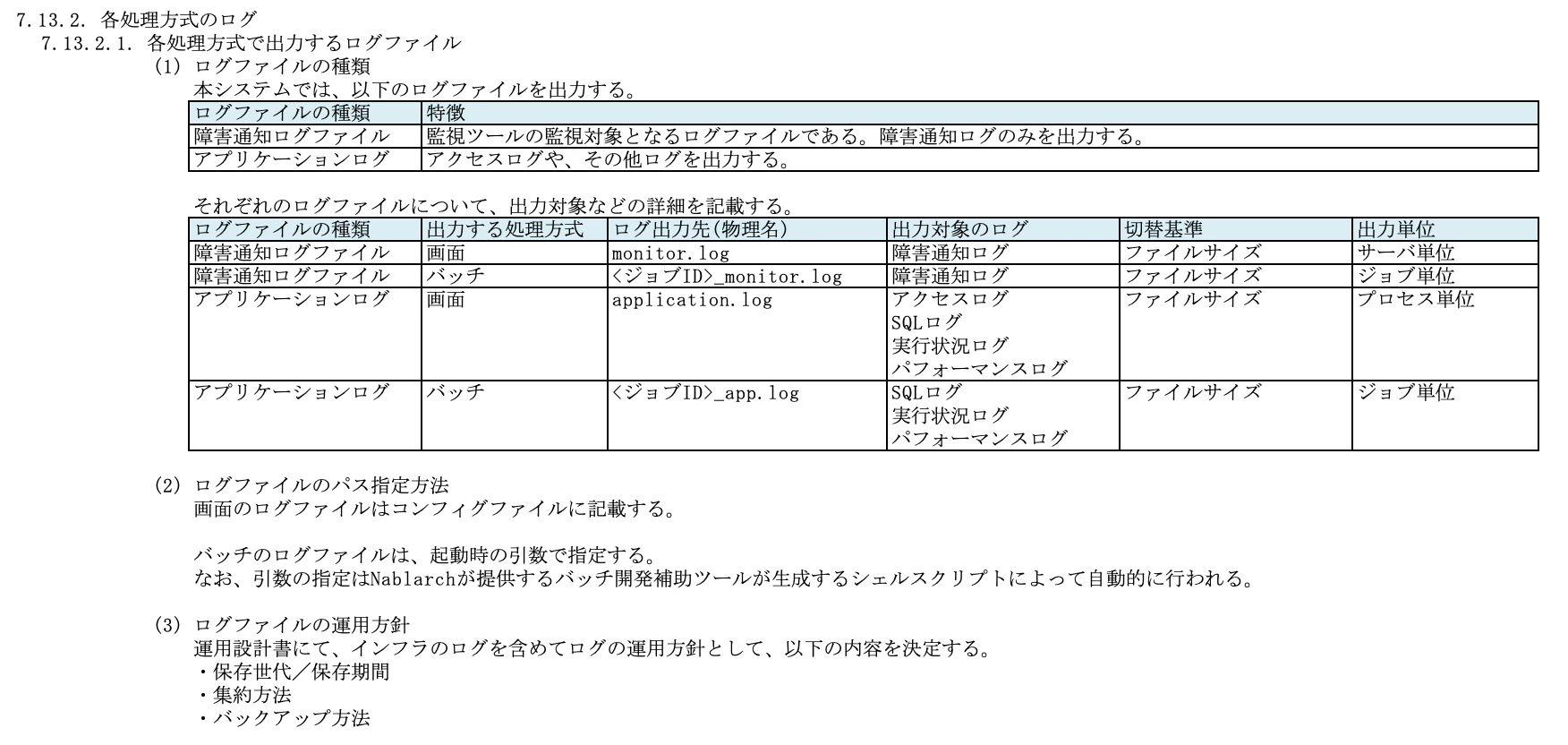
7.13.3. ログファイルごとのフォーマット
ログの種類毎にどのようなフォーマットで出力されるのかを定義します。
これもTISのサンプルを見た方がイメージしやすいと思います。
・障害通知ログファイル

・アプリケーションログファイル
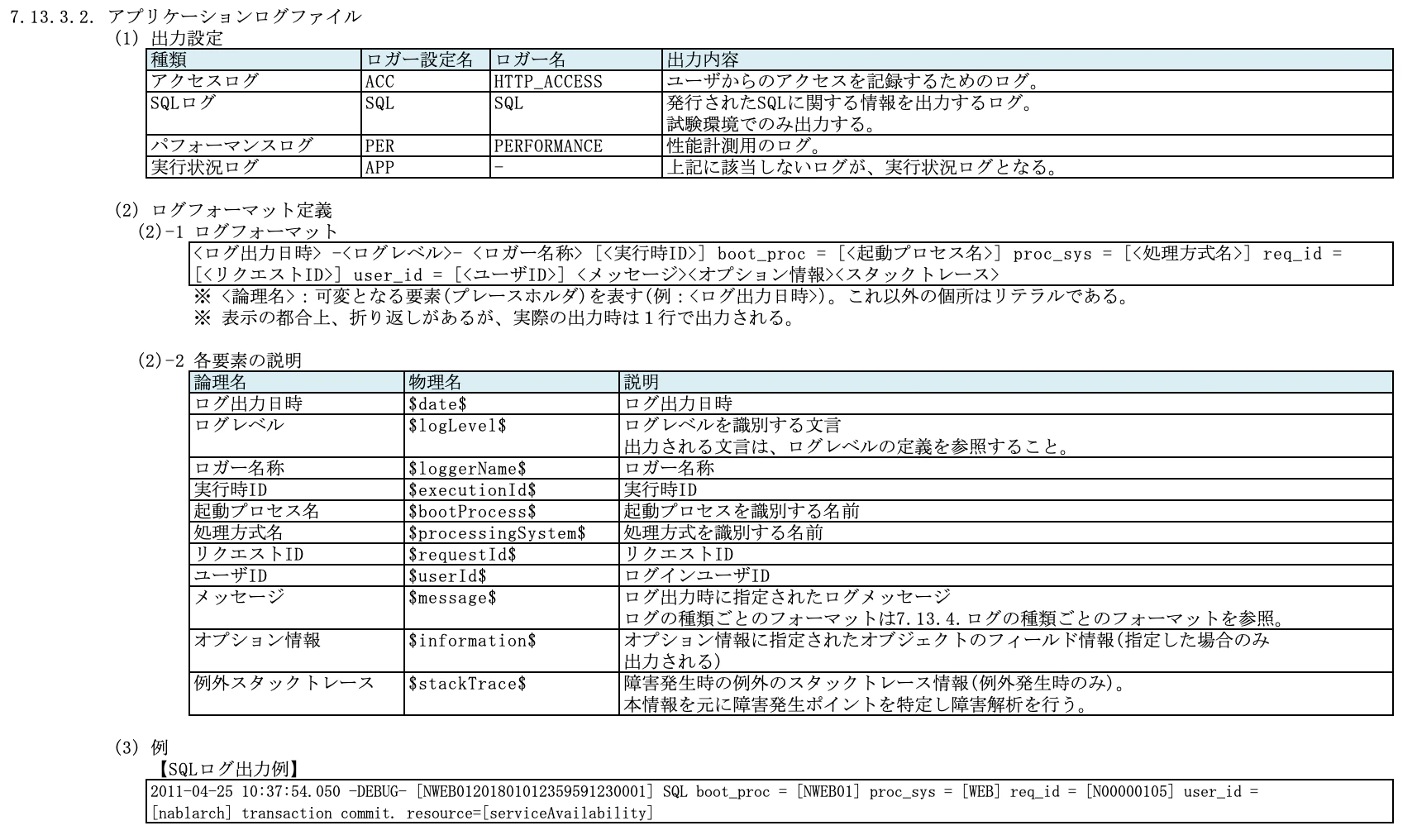
7.13.4. ログの種類ごとのフォーマット(実装上の指定)
前述のログを出力するために、実装上、どのような指定をするのかを記載しています。
(TISのサンプルは、Nablarchフレームワークのフォーマットに準ずるとのこと)

上記の引用にリンクが書かれているので、掲載しておきます。
(実装フォーマット)障害通知ログ
(実装フォーマット)アクセスログ
(実装フォーマット)SQLログ
(実装フォーマット)パフォーマンスログ
7.13.5. エラー通知
どのようにエラー通知(エラーの検出)をするのかを記載します。
TISのサンプルでは、障害通知ログファイルを監視する旨が書かれています。

7.13.6. シェルスクリプトのログ
シェルスクリプトのログ出力方法について記載しています。

資料へのリンク
今回紹介した資料のリンクを以下に記載します。
おわりに
今回は、システム方式設計についてTIS社が公開していた資料を紹介させていただきました。
かなり本格的な内容になっていて現場でも使える箇所が多いと感じていますので、ぜひ活用してみてください。
またいろいろ漁ってみて良さげなドキュメントがあったら共有したいと思います。
関連記事
TISの資料が「WBSのタスク」洗い出しに役立ちそうなので紹介しておく
TISのレビュー記録表テンプレ&サンプルが役立ちそうなので紹介しておく
TISの画面設計書テンプレ&サンプルが役立ちそうなので紹介しておく