概要
Monitoring Kubernetes with Datadog を読んでk8s環境における監視の考え方や大事なポイントのメモ
現在進捗はInvestigating recursivelyまで、読み進み次第追記予定。
Kubernetes環境において必要なモニタリングは2つ
- Kubernetes上で動くコンテナ群のモニタリング
- Kubernetesクラスタ自身のモニタリング
Monitoring Theory
Collecting the right data
この理論では以下の3種類のメトリクスを集める

- システムが正常に働いている度合いを示すメトリクス
- スループット
- エラー率
- レスポンスタイム
- レイテンシー
Resource metrics
- システムが正常に働いているかどうかを知るメトリクス
- CPU
- メモリ
- ディスク容量
Events
- システムで発生したイベント
- スケール
- デプロイ
- クラスタの切替
- DNS変更
Alert on actionable work metrics
- アラートはアクションが必要なメトリクスのみに対して出す
- Work metricsは「システムが正常に動いているかどうか」を示す
- Work metricsの値に異常があれば何かしら対応が必要になるのでアラートを出すべきである
- Resource metricsについては基本的にアラートは出さない
- CPUやメモリが80%を超えたからと言って何か対応するわけではない
- アプリケーションに影響が影響が出ているかどうかが重要
Investigating recursively
問題があったときに調査するする際は以下の順番でメトリクスを確認する
- Work metrics
- Reousrce metrics
- Events
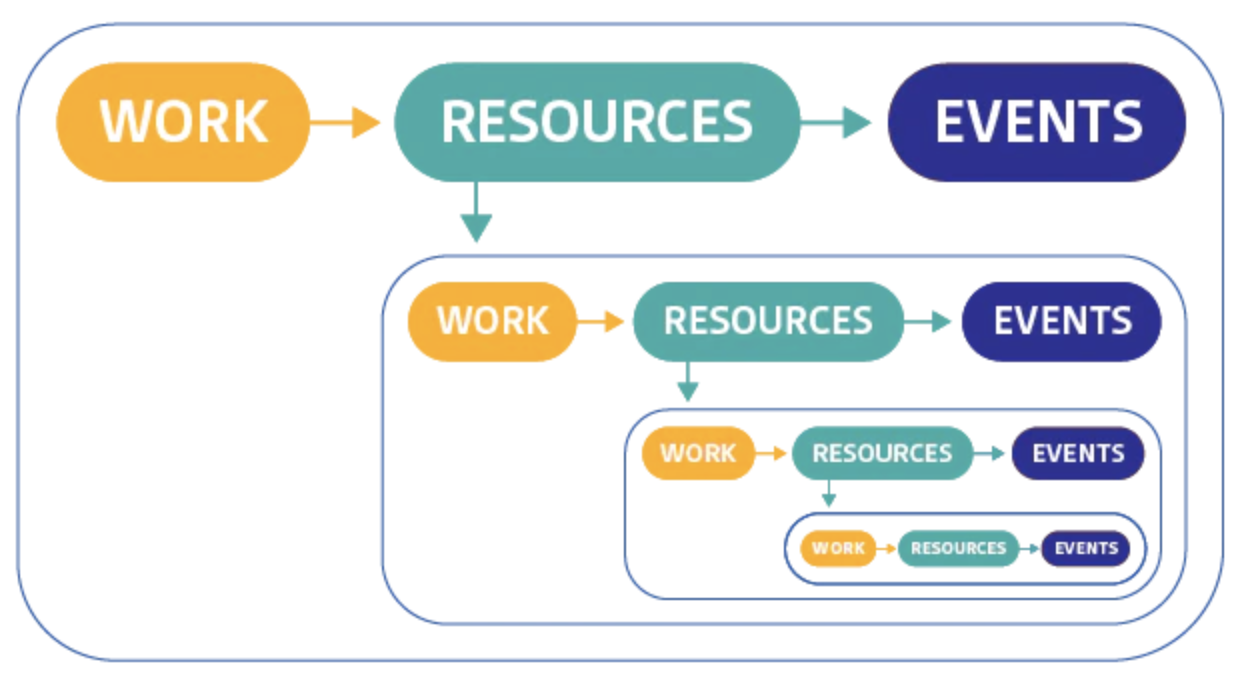
メトリクスは再起的に見る必要がある
例えばDBのアラートが発生した場合は以下のようにドリルダウンしてメトリクスを確認する
- アプリケーションのスループット(Work metrics)
- DBのクエリレイテンシ(Resource metrics)
- CPUやメモリ(Resource metrics)
- セールなど高負荷が発生しそうなイベントをやっていないか確認(Events)
- CPUやメモリ(Resource metrics)
- DBのクエリレイテンシ(Resource metrics)