この記事でやってみたこと
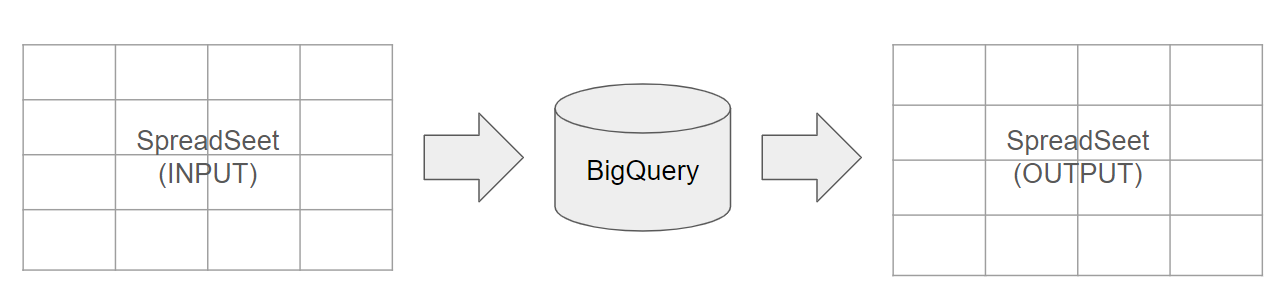
こんな状況におすすめ
- インプットがSpreadSheet、アウトプット(閲覧、分析など)もSpreadSheet
- SpreadSheetでのデータ加工の限界にぶち当たっている(10,000行超えると関数の挙動が遅くなったりします)
- SpreadSheetだと実現できない、複雑すぎるけどSQLだとサクッと加工できる
手順
SpreadSheetの設定
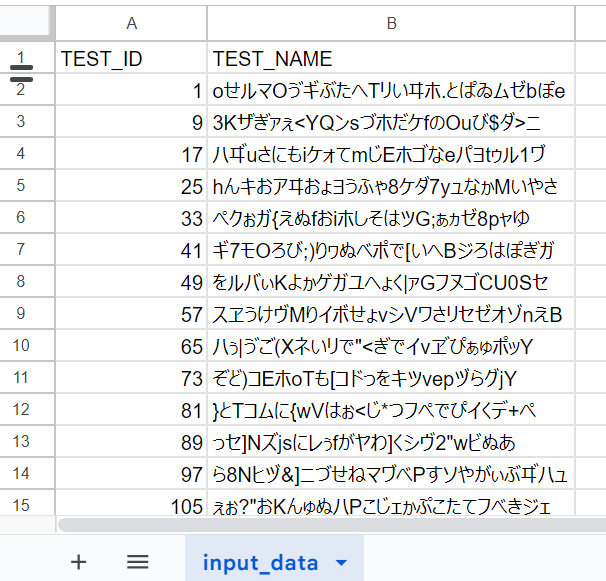
まずはSpreadSheetにデータを用意します。
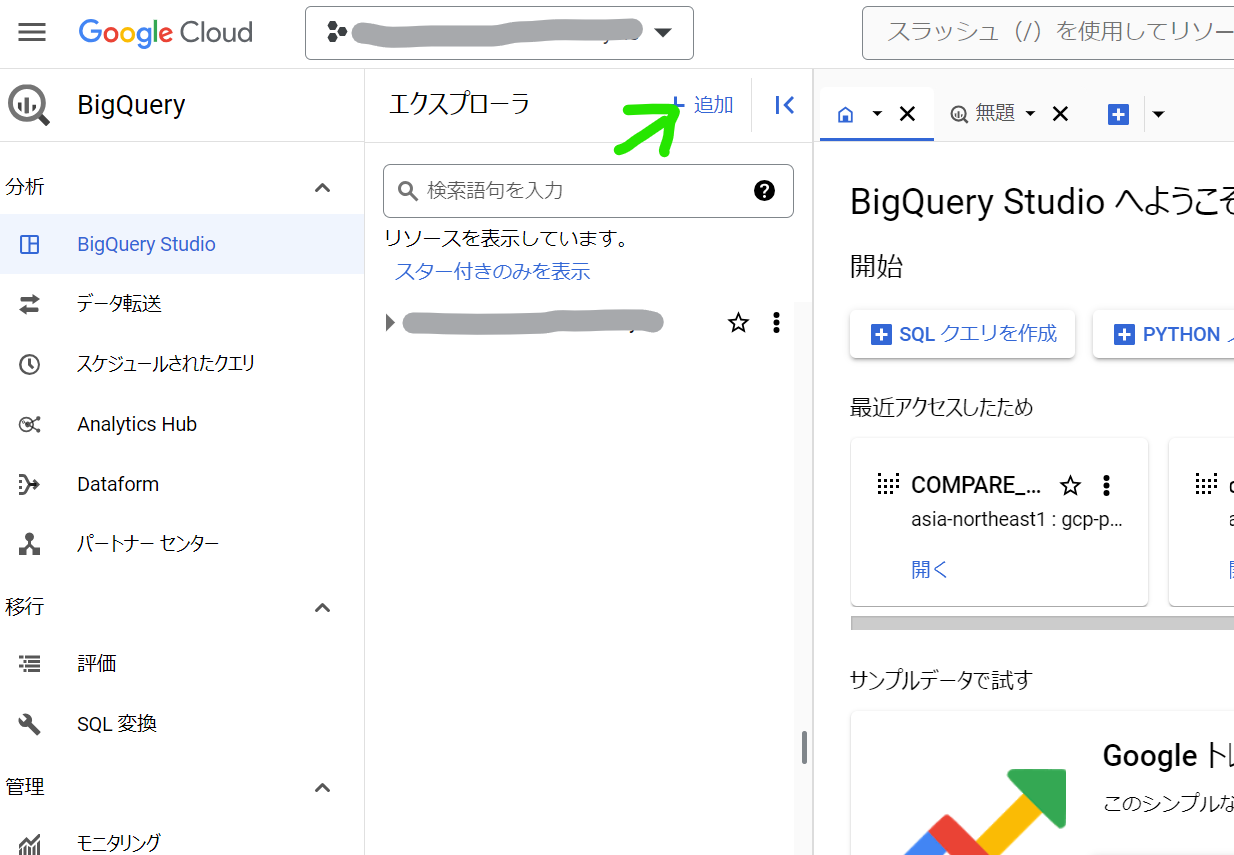
BigQueryへのインポート設定
BigQueryのコンソールを表示して、追加ボタンを押します。
データソースを選択する画面が出てくるので、「Google ドライブ」を選択します。
テーブルを選択するためのコンソールが出てくるので、必要な情報を埋めます。

ソース
- ドライブのURLを選択:SpreadSheetのURLをそのまま貼り付けます
- ファイル形式:Googleスプレッドシートを選択
- シート範囲:データとして取り込む範囲を、「シート名!範囲」の形式で記載します。SpreadSheetのセル参照方法と同じです
データセット
- データセット:送信先のデータセットを記載します
- テーブル:送信先のテーブル名です
- テーブルタイプ:外部テーブル以外選択できません
スキーマ
スキーマは、自動検出と自分で作成する2通りがあります。
自動検出
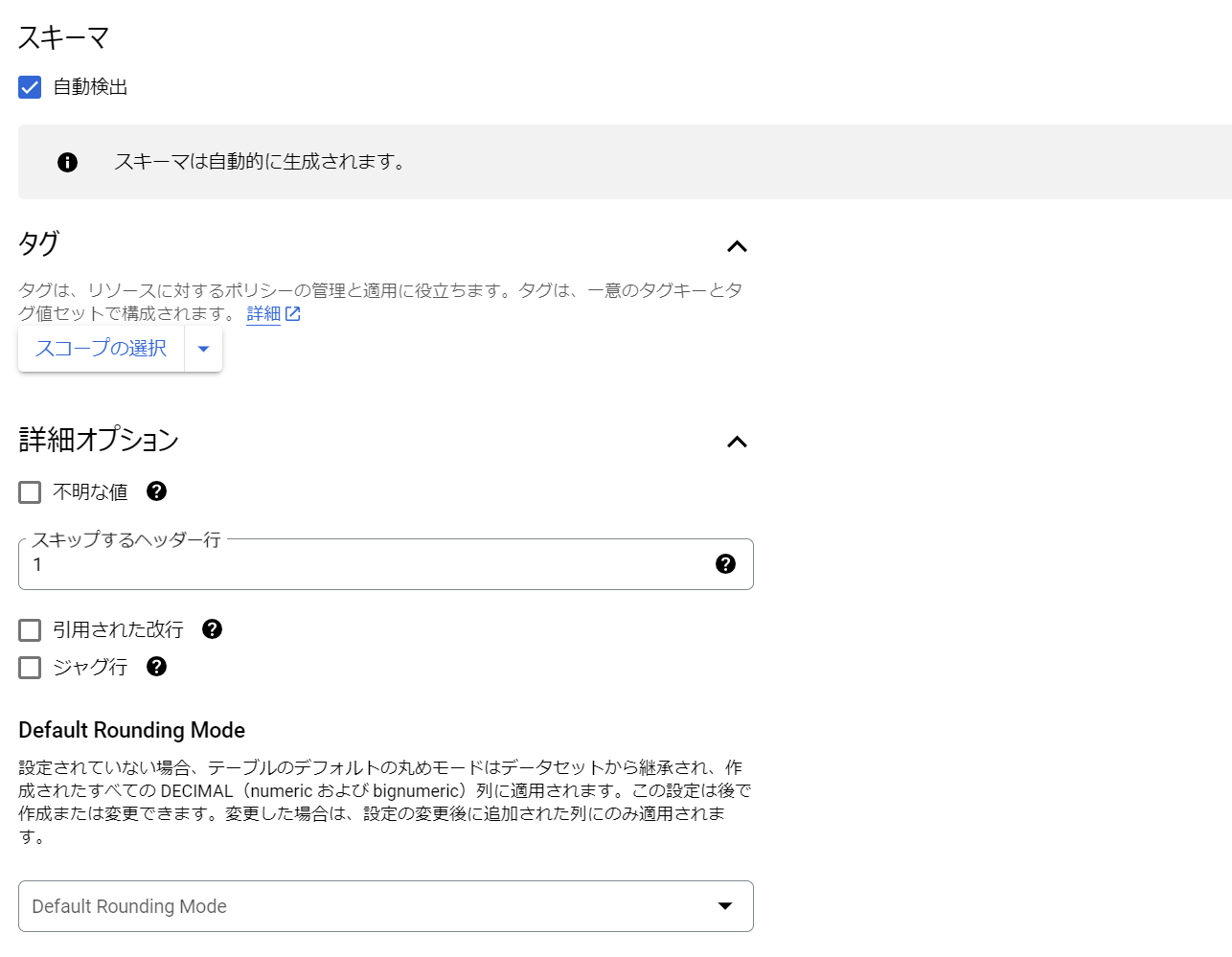
データのヘッダ行をそのままカラム名として取り込んでくれます。
ポイントとしては、詳細オプションの「スキップするヘッダー行」にヘッダ行数(ここでは1)をいれることで、ヘッダを読み取ってくれます。

自動検出で作成したテーブルがこちら。
SpreadSheetのヘッダ行をちゃんと絡むとして読み取ってくれています。
また、データ種類についても、INTEGERとSTRINGを判別してくれています。
手動生成
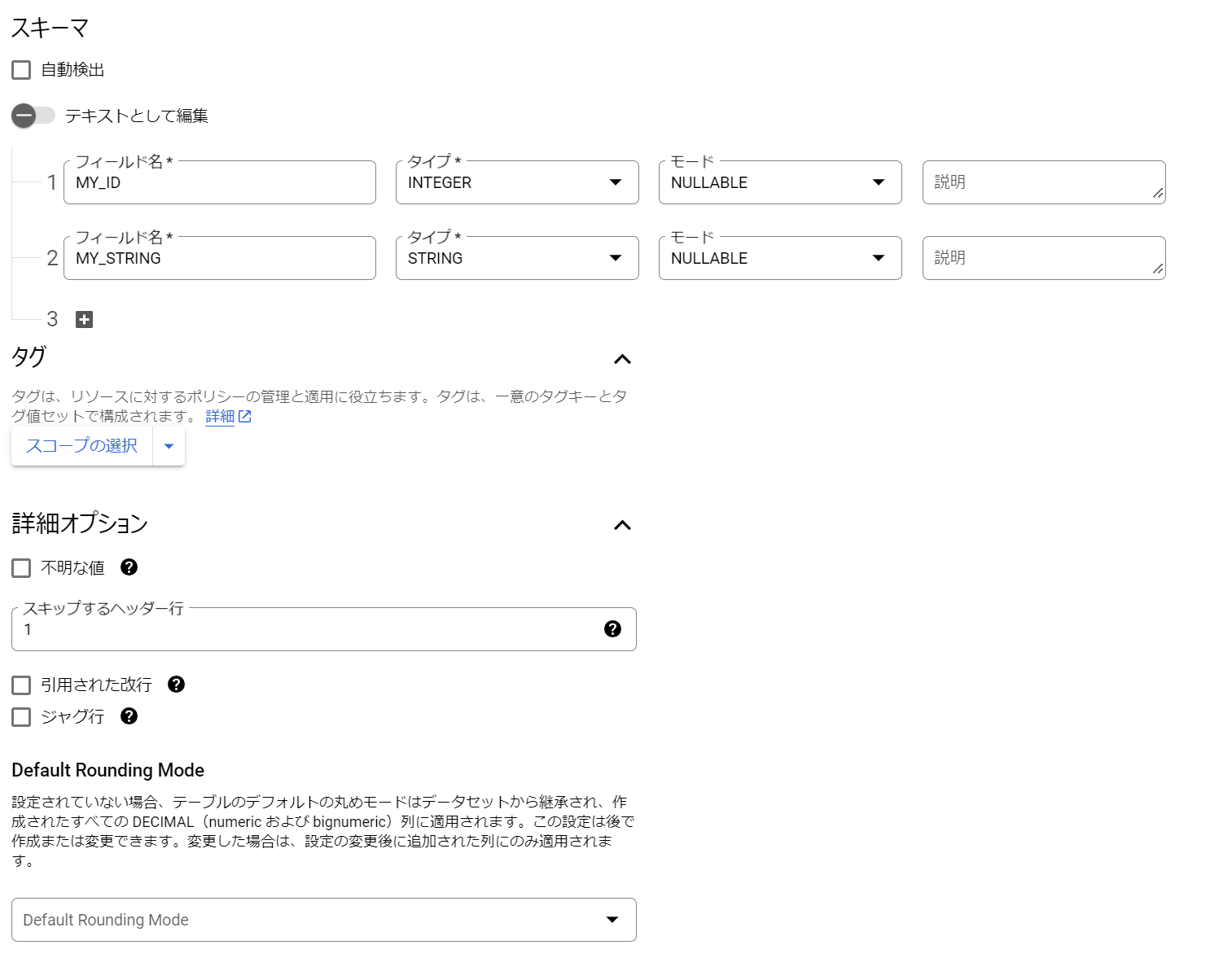
GUIでポチポチしてスキーマの生成ができます。

また、カラム数が多いデータを試行錯誤しながら作成する場合は、何度もGUIをポチポチするのは大変なので、「テキストとして編集」を選択するとテキストモードに切り替わります。
最初にGUIでポチポチしたものをテキストモードに切り替えてコピーして退避すると次回以降の生成の時に楽です。
設定作成
準備ができたところでいよいよテーブルの作成をしてみましょう。
「テーブルを作成」ボタンをポチッと。
無事作成されたようです。
中身を見てみましょう。
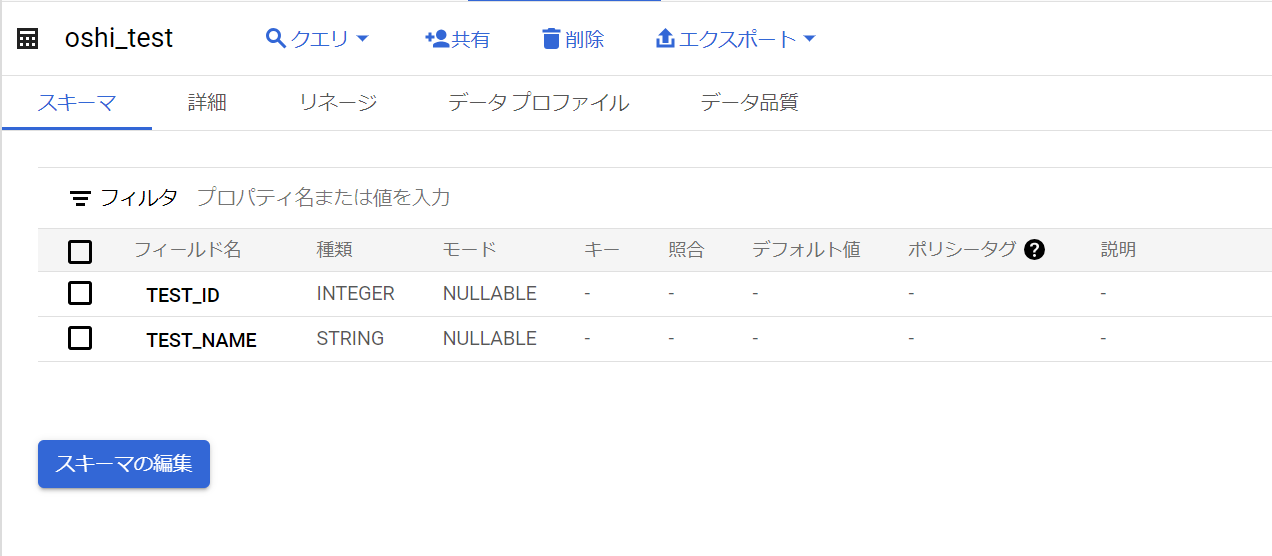
できてるっぽい。
通常のテーブルであればプレビューをすることができますが、SpreadSheetから作成したテーブルはプレビューができないようです。
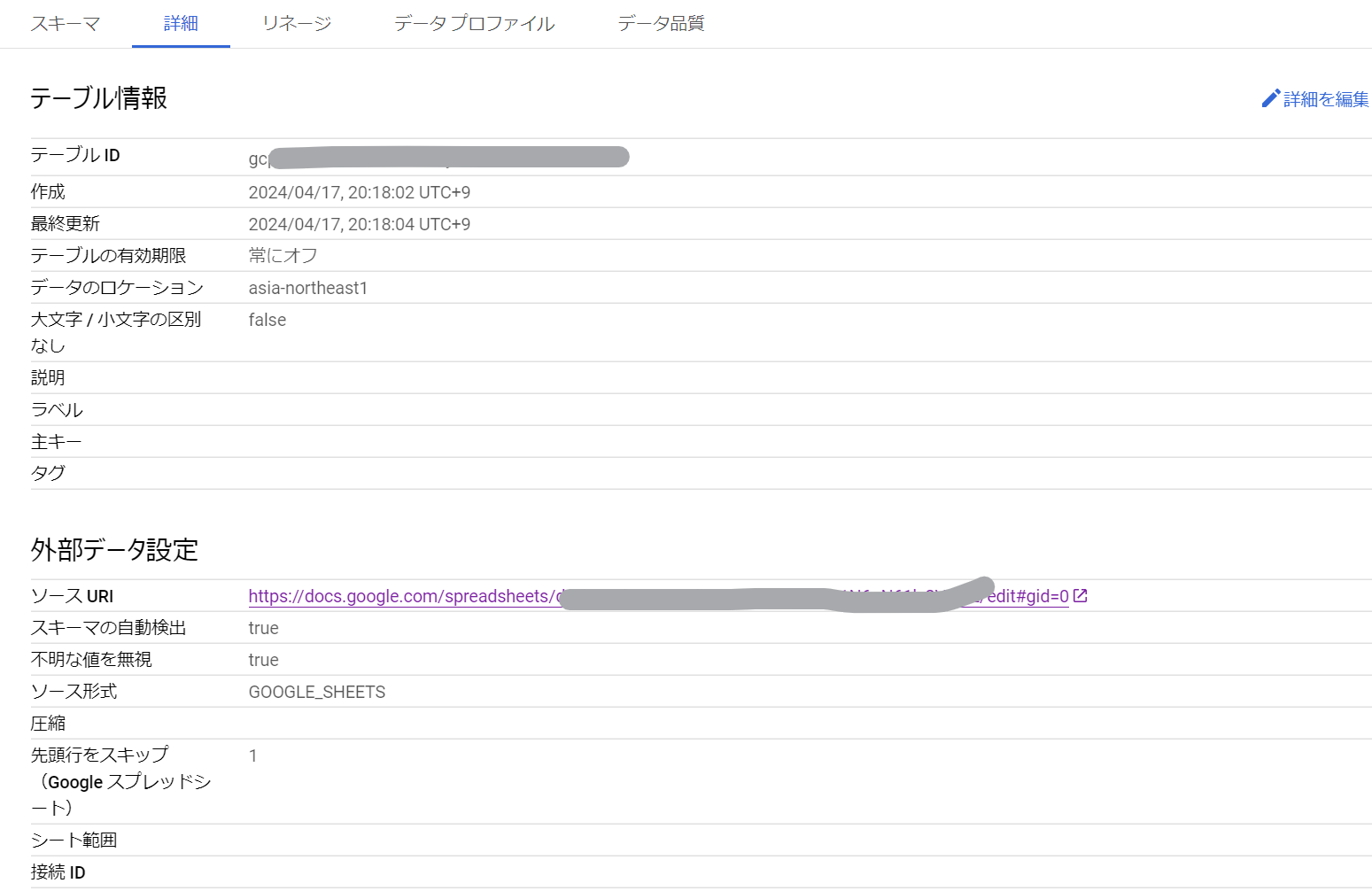
外部データという扱いになっています。
クエリでSelectしてみると中身が見れます。
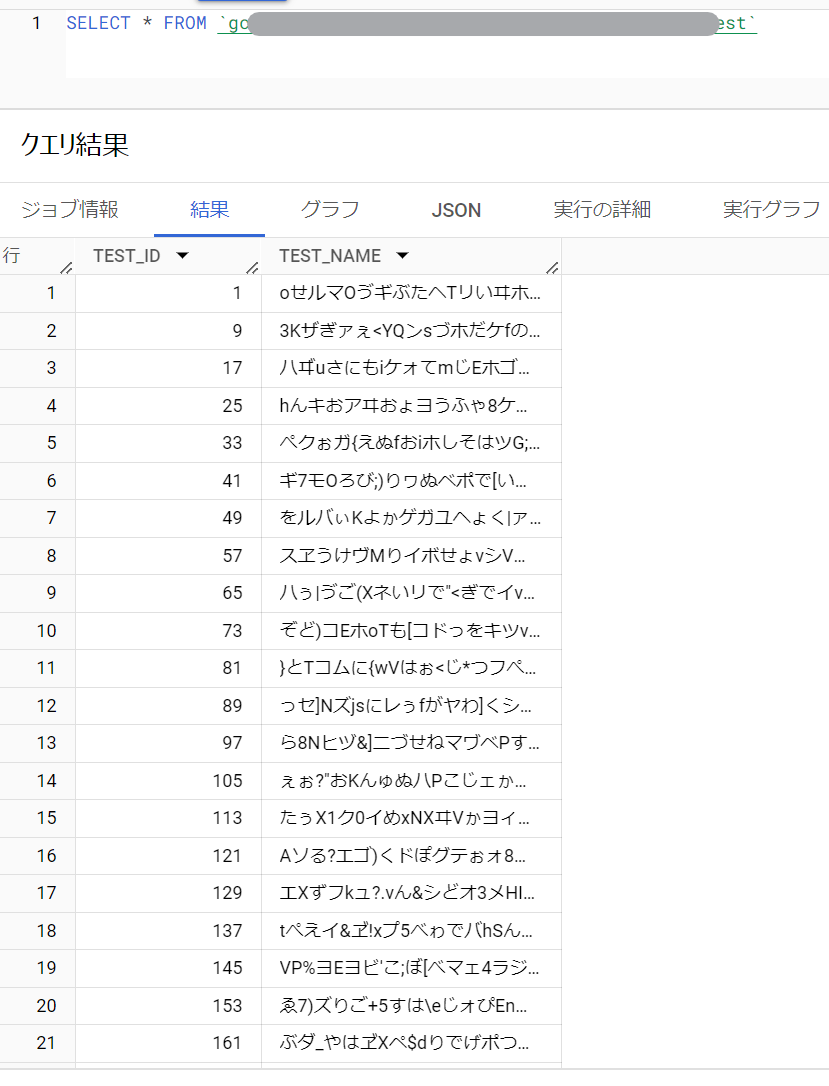
テーブルの作成は無事成功したようです。
リンクしている!
BigQuery上のテーブルは外部のソース(SpreadSheet)にリンクをしているイメージです。
SpreadSheetを変更するとリアルタイムでテーブルへも反映されます。
データの変更時にいちいちインポートしなおさなくていいのでとても楽です。
一方でSelectをする度にSpreadSheet全体を読みに行くので少し遅いです。
用途としては変更頻度が高く、Selectの速度が多少遅くてもいいような場合には有効だと思います。