scikit-learnを使うと、機械学習の体験が簡単にできるらしい。本当か?
数学もプログラミングも残念なオイラが、初めてのPython実装を目指し、ひとまず調査を行ってみると気づく、なんとも概念的なお話の多いことか・・・いや基礎理論は大切でそちらを理解しないと本当の意味での実践はできないのかもしれないけど、いや一寸、サクッと試したいのに重すぎるし、そして実際のコーディング体験はチュートリアルや定番のモデル処理に終始し、とりあえず実践してみるのに手頃なサンプルの少ないこと・・・面白そうなサンプルが少ない。(顔認識して好みを学習させ好みの判別をさせるのは面白かった)
とりあえずやってみたいこと・・・
好き勝手なフォーマットで送られてくるFAXドキュメントの向きを自動補正してブラウジングできるようにすること。手書きと活字の度合いを計測し事前に把握できるようにすること。前者はOCR系のソフトウェアがスキャン画像の向き補正を自動的にしてくれるのと同等に、複合機が受け取ったFAXドキュメントの転送を向きでだけでも自動補正できないだろうかということ。向きと手書度合いの2系統の識別が可能なのか?疑問だったがそれらしい情報が見つからないので、パーセンテージを4段階に単純化してマトリックス構成したらイケるかなぁ〜と思った次第。
どこまでやるの?
- 複合機が受け取ったFAXはPDF添付ファイルとしてメール転送できる。
- 最近の複合機はどれも簡単な設定で転送できる。smb経由で保存できるものもあるがプロトコル実装が古いと最新のmacOS(SAMBA)やWindow10相手にコケまくるので却下
- 自動的にメール受信して添付PDFファイルを実体化させる
- PDFの1ページ目を画像フォーマットで保存する
- モノクロ2値、200dpiの解像度からグレースケール72dpi程度まで落として保存。最終的にはフルカラー32bitの正方形画像データ配列に成形する。なにしろscikitさんが配列すうが異なると処理できないと仰るもので(..;)
- PDFブラウジングアプリでそれらをとりあえず閲覧できるようにする(この辺りは既にできてたw)
- 向きや、手書き度合いの正解を設定できるUIを作る
- scikit-learnに流し込む配列データに変換する
- ある程度溜まったところで、正解データと画像データをscikit-learnに流し込み学習させる
- 学習データを元にメール受信保存のタイミングで自動推測処理をかます
- ブラウジングアプリは推測データがあればそれに従い、正解があればそちらを優先し回転表示させる
といった具合の機能まで実装してみたいと思う。
落とし穴が
いよいよ基本動作ができるようになってきた終盤に、なんということでしょう。推測結果と正解が異なる場合、既存の学習データに追加する形で再学習させることができないと言うことを知るorz -> sklearnのモデル再学習について
このあたりは、一定期間の正解データのみを定時に抽出して学習セットを作成し、夜間ゼロベース学習をスケジュールすることで回避するしかなさそう。
まずはインストール。
前回homebrewを入れてPython3はいれたのでpip3によるモジュールの導入は簡単だ。
$ brew install python3
$ pip3 install pillow
$ pip3 install scikit-learn
そしてコーディング・・・
わずか100行足らずでセット学習と、永続化した学習データからの推測処理が書けてしまうPython素敵すぎる。この推測処理を、PDF添付メールを受け取ってファイル実体化した直後に処理してあげると・・・なんということでしょう!!結構いい感じの確率で、書類の向きが補正できるではありませんか。
# !/usr/local/bin/python3
"""
引数なし:usage
引数:ファイル名(~~~~~.pdf)
機械学習した情報を元に推測を行う。(~~~~~.pdf.txt)に上書き
引数:ディレクトリパス
そのディレクトリ内を検証して、ラーニングする。
"""
import sys
import os
import glob
import configparser
import urllib.parse
import numpy as np
# import cv2
from PIL import Image
# from skimage import data
from sklearn.externals import joblib
from sklearn import svm
my_path = os.path.dirname(os.path.abspath(__file__))
# clf = []
datas = []
labels = []
def convertImageVector3(img):
s = img.shape[0] * img.shape[1] * img.shape[2]
img_vector3 = img.reshape(1, s)
return img_vector3[0]
def loadImage(path):
img = Image.open(path) # GIF画像を読み込み
img = img.convert("RGB") # RGBカラーに変換
img = img.resize((600, 600)) # 200dpi A4(1654 x 2339)モノクロ2値 -> 72dpi A4(595x842)グレースケールに
return np.asarray(img) # 変換して保存されているものを -> RGBカラー正方形に成形(600x600)
def learn_fax(files):
for pdf_file in files:
ini_file = pdf_file + ".txt" # ~~~~.pdf.txt
img_file = pdf_file + ".gif" # ~~~~.pdf.gif
ini = configparser.ConfigParser()
ini.read(ini_file, 'UTF-8')
label = ini["RootSection"]["LABEL"] # 教師データあり、ラベル情報読み込み
as_arrayed_img = loadImage(img_file) # GIF画像を配列に変換して読み込み
if (len(as_arrayed_img.shape) == 3):
datas.append(convertImageVector3(as_arrayed_img))
print("label = "+label)
labels.append(label)
else:
print("skip label="+label)
#clf = joblib.load(my_path+'/fitfax.pkl.z') # 永続化したものを読み込んで続きの学習ができると思ってたorz
clf = svm.LinearSVC() # インスタンス生成
clf.fit(datas,labels) # 学習!!!この1行がほぼ全てだ
joblib.dump(clf, my_path+"/fitfax.pkl.z", compress=True)
print("learned.")
def main():
args = sys.argv
if(len(args)>1):
path = args[1] # PDFファイルが沢山はいっているパス...学習ディレクトリ
if(os.path.isdir(path)): # ディレクトリ指定なので、学習モード
filelists = glob.glob(path+'./*.pdf')
#print(filelists)
learn_fax(filelists)
else:
# ファイル指定なので、ラベル推測を実施
if(path[-4:] == '.pdf'):
pdf_file = path # ~~~~.pdf
ini_file = pdf_file + ".txt" # ~~~~.pdf.txt
img_file = pdf_file + ".gif" # ~~~~.pdf.gif PDFの1ページ目をGIF画像に変換したもの
ini = configparser.ConfigParser()
ini.read(ini_file, 'UTF-8')
as_arrayed_img = loadImage(img_file) # GIF画像を配列に変換して読み込み
datas.append(convertImageVector3(as_arrayed_img))
clf = joblib.load(my_path+'/fitfax.pkl.z') # 保存している学習データを読み込み
res = clf.predict(datas) # データを推測
print("LABEL guess = " + res[0]) # 推測結果
ini.set('RootSection', 'GUESS', res[0]) # INIフォーマットに設定
with open(ini_file, 'w') as configfile:
ini.write(configfile) # INI保存
else:
print("Usage: fax.py `Path/to/date_dir` to learn SVM")
print(" fax.py `Path/to/pdf` to guess label")
if __name__ == '__main__':
main()
ラベル
今回、正解ラベルデータには、向き方向4段階、手書き度合い4段階の16段階にクラスタリングできるように構成してみた。ファックスで受け取った画像のパターンから、書類の向きと、100%手書きや完全活字の判別は結構な確率で正解に導き出せるようになったみたい。
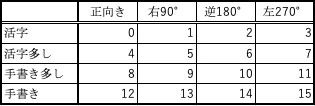
できたっぽい
画像の向きを検出したラベル値をINIファイルに保存して、標示のタイミングでINIの値を読み込んで回転させている。(元画像を変更しちゃうと、正解結果のフィードバックができなくなってしまうから)
[RootSection]
ID=123456
FROM=0123456789
DATE=2019/06/25
TIME=04:20:24
FILENAME=7146_001.pdf
PAGE=1
DIRECTIION=2
HANDWRITING=30
送信元=hogehoge
GUESS=5
LABEL=5
GUESSが推測値、LABELが手動正解設定値。こうして動き出すと、ふとあることに気づく・・・見せられるスクリーンショットがねぇ・・・下記は逆さまになった手書きのファックスを、学習のために正解ラベル設定を行っている所・・・
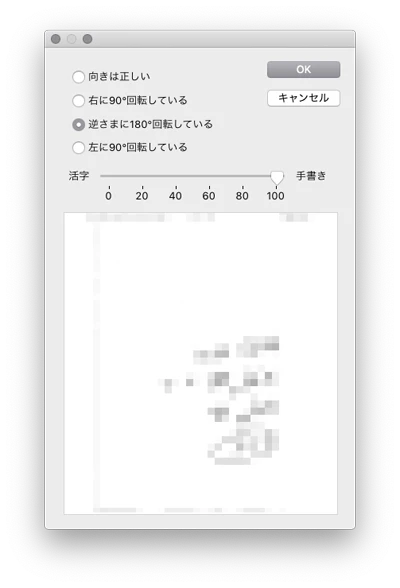
クラサバでつながっている端末どこでも、統一して受け取ったファックス書類が閲覧できる機能は、少し便利で・・・その処理に流行りの機械学習機能が実装されているなんて、だれも気づかないだろうな・・・それにしても勝手に正向きに補正されてプレビューできるのは快適だ!!
問題や課題、その他
- 180°回転した逆さまの書類検出が、時々コケる。(90°反転は右も左も概ね順調)
- 同じく180°回転した活字画像が、正常向きの手書きと認識する?時があるorz
- 罫線のない活字を手書きとして認識する?時があるorz
- configparser.ConfigParser()のINI書き込みが全文字強制小文字化してくれてハマる
- グレースケール画像をGIFで保存しているのは、書類の特性上(白ベタが多い)圧縮効率が良いから
- 自動検出のスコアがどれくらいか?気が向いたら検証する
- 600x600ピクセルの画像は大きすぎるのか?クッソ重い(300x300)程度に変更して・・・こちらも気が向いたら検証する
- 10日分の受信ファックスをすべて学習させたら、ウチのショボい環境では4時間ほどかかったでござる。