共起解析
前回の記事【https://qiita.com/osakasho/items/0a0b50fc17c38d96c45e 】
では、形態素解析までしかやらなかったので、今度は共起解析もしてグラフ化してみます。
必要なものをインストールする
pip install pyvis
コード
import spacy
nlp = spacy.load('ja_ginza_nopn')
import re
import itertools
import collections
from pyvis.network import Network
import pandas as pd
import time
"""--------- 分解モジュール --------"""
def sentence_separator(path, colname):
black_list = ["test"]
df = pd.read_csv(path, encoding="utf_8_sig")
data = df[colname]
sentence = []
for d in data:
try:
total_ls, noun_ls, verm_ls = ginza(d)
sentence.append(total_ls)
except:
pass
return sentence
def ginza(word):
doc = nlp(word)
# 調査結果
total_ls = []
Noun_ls = [chunk.text for chunk in doc.noun_chunks]
Verm_ls = [token.lemma_ for token in doc if token.pos_ == "VERB"]
for n in Noun_ls:
total_ls.append(n)
for v in Verm_ls:
total_ls.append(v)
return total_ls, Noun_ls, Verm_ls
"""-------------------------------------"""
# テキストデータの取得を行う。
filename = "list.csv"
file_path = filename
colname = "歌詞"
# 文章
sentences = sentence_separator(file_path, colname)
sentence_combinations = [list(itertools.combinations(sentence, 2)) for sentence in sentences]
sentence_combinations = [[tuple(sorted(words)) for words in sentence] for sentence in sentence_combinations]
target_combinations = []
for sentence in sentence_combinations:
target_combinations.extend(sentence)
# ネットワーク描画のメイン処理
def kyoki_word_network():
# got_net = Network(height="500px", width="100%", bgcolor="#222222", font_color="white", notebook=True)
got_net = Network(height="1000px", width="95%", bgcolor="#FFFFFF", font_color="black", notebook=True)
# set the physics layout of the network
# got_net.barnes_hut()
got_net.force_atlas_2based()
got_data = pd.read_csv("kyoki.csv")[:150]
sources = got_data['first'] # count
targets = got_data['second'] # first
weights = got_data['count'] # second
edge_data = zip(sources, targets, weights)
for e in edge_data:
src = e[0]
dst = e[1]
w = e[2]
got_net.add_node(src, src, title=src)
got_net.add_node(dst, dst, title=dst)
got_net.add_edge(src, dst, value=w)
neighbor_map = got_net.get_adj_list()
# add neighbor data to node hover data
for node in got_net.nodes:
node["title"] += " Neighbors:<br>" + "<br>".join(neighbor_map[node["id"]])
node["value"] = len(neighbor_map[node["id"]])
got_net.show_buttons(filter_=['physics'])
return got_net
# まとめルンバ
ct = collections.Counter(target_combinations)
print(ct.most_common())
print(ct.most_common()[:10])
# データを一時保存
pd.DataFrame([{'first' : i[0][0], 'second' : i[0][1], 'count' : i[1]} for i in ct.most_common()]).to_csv('kyoki.csv', index=False, encoding="utf_8_sig")
time.sleep(1)
# 処理の実行
got_net = kyoki_word_network()
got_net.show("kyoki.html")
結果
kyoki.htmlが出力されていると思うので、ブラウザで起動してください。
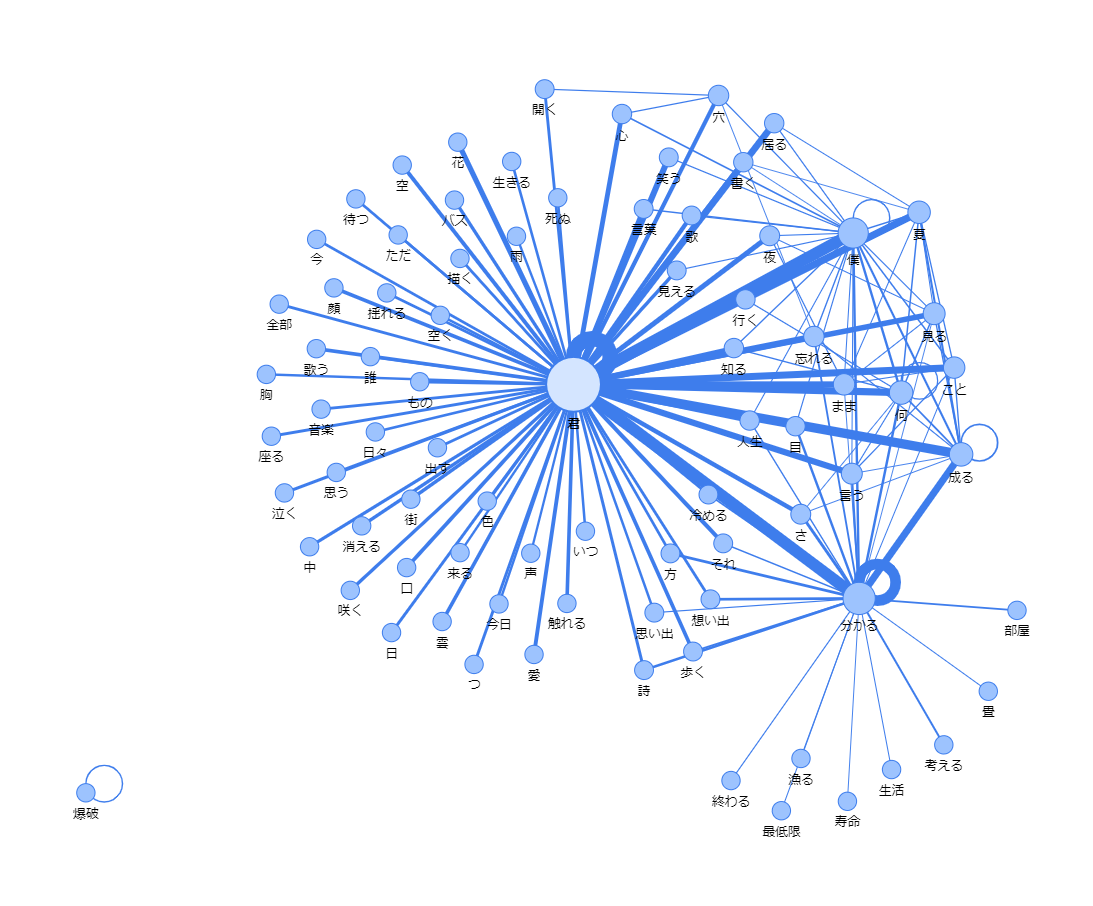
終わり。