はじめに
株式会社ジールの @oreo_tです。
2024/10/9のアップデートで、AWSのLambdaとS3間の再起ループの検出と自動停止ができるようになりましたので紹介しようと思います。
今回の更新情報
Lambdaの再起ループ検出について
この機能は、Lambda関数が再帰的に呼び出されることで意図せず延々と動作し、莫大なコストがかかってしまうという事故を防ぐための措置で、デフォルトで有効化されています。
Lambda関数の設定で機能のオンオフの切り替えができますが、ループ処理を16回検知したら停止する、という閾値は変更できず固定になります。
SQS、Lambda、SNS間での再起ループ検出、自動停止は去年の7月に機能が実装されたのですが、このたびLambda、S3間の再起ループにも対応するようになったため検証していきます。
去年の機能実装時の検証は、弊社の別メンバーが記事にしているのでそちらもご参照ください。
検証内容
今回は、
①S3にファイルが配置されたことをS3イベントで検知してLambda関数を実行する
②Lambda関数内の処理としてS3にファイルを配置する
ということを実装し、①⇔②間で処理がループするようにします。
実務で考えると、
①処理すべきファイルがS3に配置されたらLambda関数を実行して処理をする
②Lambda関数での処理が完了したらS3にログファイルを出力する
というような実装をするときに、ログファイルの出力先を誤って処理すべきファイルと同じパスにしてしまい、
ログファイルの配置を検知してLambda関数が実行されてしまうという事故が考えられます。

検証実施
Lambda関数で、S3にファイルを作成するような以下のコードを実装します。
import boto3
import datetime
def lambda_handler(event, context):
# S3クライアントの作成
s3 = boto3.client('s3')
# 現在時刻を取得
dt_now = datetime.datetime.now()
dt_str = dt_now.strftime("%Y%m%d%H%M%S")
# S3のバケット名とアップロードするファイル名を指定
bucket_name = '{自環境のバケット名}'
file_name = (f'output/text_{dt_str}.log')
# ファイルの内容
file_content = 'test'
# S3にファイルをアップロード
response = s3.put_object(
Bucket=bucket_name,
Key=file_name,
Body=file_content
)
# 成功メッセージ
return {
'statusCode': 200,
#'body': res
'body': f'Successfully uploaded {file_name} to {bucket_name}'
}
そのLambda関数に、所定のバケットのoutputフォルダを対象としたS3イベントを設定します。
これで、フォルダに何らかのファイルが配置・作成されるとS3イベントが起動します。
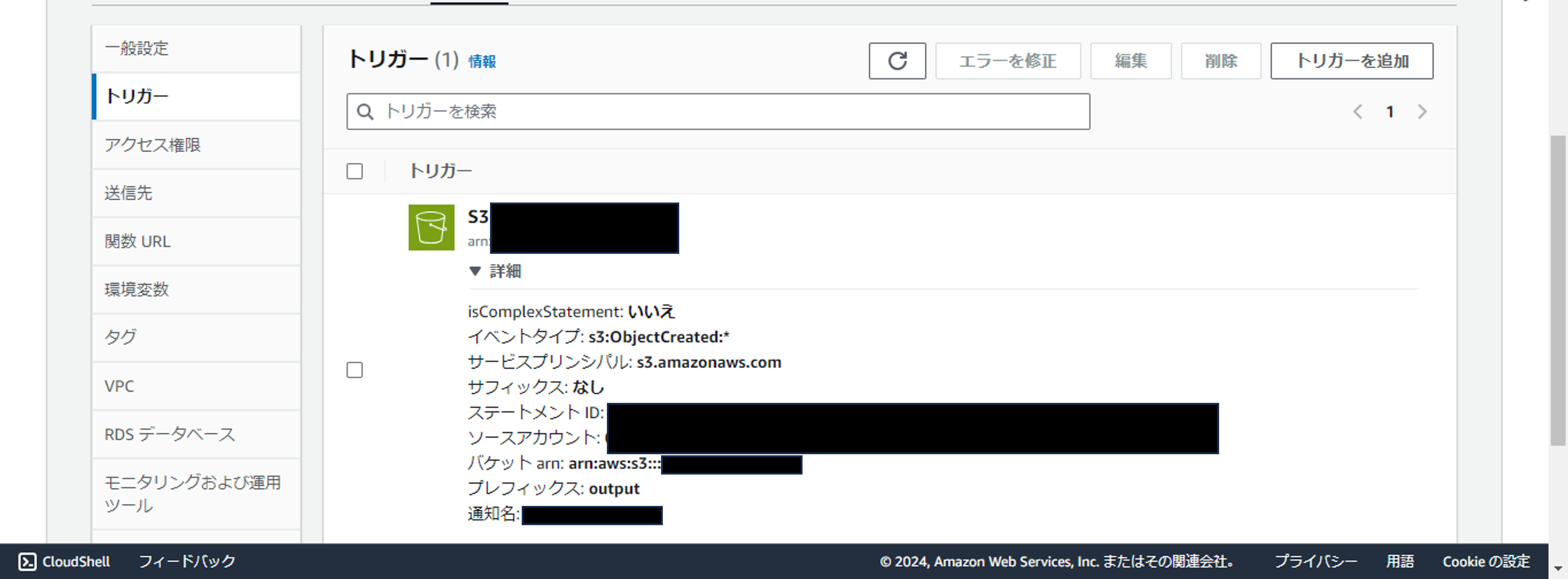
今回は手動でS3のoutputフォルダにファイルをアップロードします。すると……

Lambda関数が実行されてログファイルが次々と作成されますが、16個できた時点でそれ以上増えなくなりました。(元のファイル1個+ログファイル16個の状態)

Lambda関数のモニタリングも見てみましょう。
Invocations(呼び出し回数)は16で止まっていますね。

Recursive invocations dropped(再起呼び出し停止)が1となっていて、再起呼び出しを検知していることが分かります。

このように、LambdaとS3間の再起ループの検出と自動停止が正常に機能していることを確認できました。
まとめ
本来は意図せずループを発生させないように開発・デプロイをするのが理想ですが、ミスというのは起こりえるものです。そこで、ループが発生してもこのように防止策をプラットフォーム側で用意してもらえていれば安心してサービスを利用できるのではないかと思います。
ぜひ今後の参考にしてください。
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: