雑多な内容ですが、Azure Durable FunctionとAzure OpenAIを使用して、メッセージの内容によって生成する回答を変えてみるという試みです。
雑な部分が多いですが、個人の備忘録も兼ねてなのでご了承ください🙏
今回はパターン1の関数チェーンをやってみます。
Durable Functionsのセットアップはこちらを参考に行います。言語はpythonです。
最終的なディレクトリ構造と関数の役割はこんな感じになりました。
#オーケストレーター
├── orchestator
│ └──__init__.py
│ └──__fuction.json
#スターター
├── chat
│ └──__init__.py
│ └──__fuction.json
#cognative serviceに接続してメッセージのネガポジ分析
├── cognative
│ └──__init__.py
│ └──__fuction.json
#cognativeの結果で何のデータを取得するか決める
├── query
│ └──__init__.py
│ └──__fuction.json
#最終的な回答を生成
├── final
│ └──__init__.py
│ └──__fuction.json
├── host.json
├── local.settings.json
├── requirements.txt
├── .funcignore
各関数の準備
それでは各関数を準備していきます。
各内容を記載していきます。
オーケストレーター関数
# この関数は、Durable Functions の Orchestrator として実行されます。
import logging
import json
import azure.functions as func
import azure.durable_functions as df
def orchestrator_function(context: df.DurableOrchestrationContext):
# スターターから渡される値を、context.get_input() で取得。
message = context.get_input()
# 1つ目の Activity Functionを呼び出す
cognative = yield context.call_activity('cognative', message)
# 2つ目の Activity Function を呼び出す。
query = yield context.call_activity('query', cognative)
# 3つ目の Activity Function を呼び出す。
answer = yield context.call_activity('final', query)
return [answer]
main = df.Orchestrator.create(orchestrator_function)
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "context",
"type": "orchestrationTrigger",
"direction": "in"
}
]
}
スターター関数
スターター関数はHTTPトリガーを使用します。
# この関数はDurable Functions用のHTTPスターター関数です。
import logging
import azure.functions as func
import azure.durable_functions as df
async def main(req: func.HttpRequest, starter: str) -> func.HttpResponse:
#Formで送られてくる想定
message = req.form.get("message")
# "starter" を使って DurableOrchestrationClient オブジェクトを初期化しています。
# このクライアントは、オーケストレーション関数を制御するために使用されます。
client = df.DurableOrchestrationClient(starter)
#client.start_new("オーケストレーション関数名", NoneにするとIDが自動採番される, 引数)
instance_id = await client.start_new("orchestrator", None, message)
logging.info(f"Started orchestration with ID = '{instance_id}'.")
return client.create_check_status_response(req, instance_id)
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"name": "req",
"type": "httpTrigger",
"direction": "in",
"route": "chat",
"methods": "post"
},
{
"name": "$return",
"type": "http",
"direction": "out"
},
{
"name": "starter",
"type": "durableClient",
"direction": "in"
}
]
}
アクティビティ関数 (cognative)
1つめのアクティビティ関数です。
Cognative Serviceを使用して感情分析を実施します。
今回はめちゃくちゃざっくりとsentimentの値しか取ってない感じです。
# この関数はオーケストレーションから呼び出されるアクティビティ関数です。
import json
import os
from io import StringIO
import logging
from azure.ai.textanalytics import TextAnalyticsClient
from azure.core.credentials import AzureKeyCredential
class TextSentimentAnalyzer:
def __init__(self):
self.endpoint = os.environ.get("TEXT_ANALYSIS_ENDPOINT")
self.key = os.environ.get("TEXT_ANALYSIS_APIKEY")
self.client = self.authenticate_client()
def authenticate_client(self):
ta_credential = AzureKeyCredential(self.key)
text_analytics_client = TextAnalyticsClient(
endpoint=self.endpoint,
credential=ta_credential)
return text_analytics_client
def analyze_sentiment(self, text):
response = self.client.analyze_sentiment(documents=[text],language="ja")[0]
return response.sentiment
#メッセージを受け取り感情分析を実施
def main(message: str) -> dict:
sentiment = TextSentimentAnalyzer().analyze_sentiment(message)
print(sentiment)
cognative = {"analysis": sentiment, "message": message }
return cognative
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "message",
"type": "activityTrigger",
"direction": "in"
}
]
}
アクティビティ関数 (query)
2つめのアクティビティ関数です。
Azure OpenAI Enbeddingを使ってベクトル検索をします。
ここで何がやりたかったかというと、ポジティブな言葉を投げてくれたらちゃんと類似度が高いものを教えてあげて、ネガティブな事を言っているようなら類似度が逆に低いものを教えてあげようとした訳です。
今回、こちらの映画のレビューデータにベクトル加工など施したCSVファイルをAzureBlobStorageに格納して使用してます。
# この関数はオーケストレーションから呼び出される2つめのアクティビティ関数です。
import os
from io import StringIO
import openai
from openai.embeddings_utils import get_embedding
from azure.storage.blob import BlobServiceClient
import ast
import logging
from typing import Dict
import pandas as pd
import numpy as np
openai.api_type = "azure"
openai.api_base = "<エンドポイント名>"
openai.api_version = "2023-03-15-preview"
openai.api_key=os.environ.get("OPENAI_KEY")
connection_string = os.environ.get("BLOB_KEY")
blob_service_client = BlobServiceClient.from_connection_string(connection_string)
blob_client = blob_service_client.get_blob_client("moviedata", "data_embeddings.csv")
#ストレージからデータを取得する
class Dataframe:
def __init__(self, blob_client):
self.blob_client = blob_client
def get_dataframe(self):
blob_data = self.blob_client.download_blob().readall()
s = str(blob_data, 'utf-8')
data = StringIO(s)
df = pd.read_csv(data)
df["embedd"] = df["embedd"].apply(lambda x: np.array(ast.literal_eval(x)))
return df
# 1つめの関数から値を受け取り、検索した結果を返す。
def main(cognative: dict) -> dict:
analysis = cognative.get("analysis")
message = cognative.get("message")
# ポジティブなメッセージだったら類似した検索を
if analysis == "positive":
function_response = find_euclidean_most(query=message)
func_content = function_response["title"]
return_message = {
"message": message,
"func_content": func_content,
}
return return_message
#それ以外は逆を
else:
function_response = find_euclidean_least(query=message)
func_content = function_response["title"]
return_message = {
"message": message,
"func_content": func_content,
}
return return_message
#最も距離が近い上位5つを返す(ユークリッド距離で測る類似性)
def find_euclidean_most(query: str):
# Dataframeクラスのインスタンスを作成
df_instance = Dataframe(blob_client)
# データフレームを取得
df = df_instance.get_dataframe()
# クエリをベクトル化
vec = np.array(get_embedding(query, engine='text-embedding-ada-002'))
# データフレームからベクトルを取得
vectors = np.vstack(df['embedd'].values)
# ユークリッド距離を計算
distances = np.linalg.norm(vectors - vec, axis=1)
# 距離が小さい順にインデックスを取得
min_indices = np.argsort(distances)
# 最も距離が小さい(最も類似性が高い)上位5つの行を返す
subset_df = df.iloc[min_indices[:5]]
# 各カラムを文字列として連結
res = {
"title": " ".join(subset_df["title"].astype(str)),
"combined": " ".join(subset_df["combined"].astype(str)),
"synopsis": " ".join(subset_df["synopsis"].astype(str)),
}
return res
# 最も距離が大きい上位5つを返す(ユークリッド距離で測る乖離性)
def find_euclidean_least(query:str):
# Dataframeクラスのインスタンスを作成
df_instance = Dataframe(blob_client)
# データフレームを取得
df = df_instance.get_dataframe()
# クエリをベクトル化
vec = np.array(get_embedding(query, engine='text-embedding-ada-002'))
# データフレームからベクトルを取得
vectors = np.vstack(df['embedd'].values)
# ユークリッド距離を計算
distances = np.linalg.norm(vectors - vec, axis=1)
# 距離が大きい順にインデックスを取得
max_indices = np.argsort(distances)[::-1]
# 最も距離が大きい上位5つの行を返す
subset_df = df.iloc[max_indices[:5]]
# 各カラムを文字列として連結
res = {
"title": " ".join(subset_df["title"].astype(str)),
"combined": " ".join(subset_df["combined"].astype(str)),
"synopsis": " ".join(subset_df["synopsis"].astype(str)),
}
return res
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "cognative",
"type": "activityTrigger",
"direction": "in"
}
]
}
最後の関数 (final)
最後の関数です。2つめの関数で得られた情報(映画のタイトル)を元に回答を生成して返します。
# この関数は最後の関数です
import json
import os
import openai
openai.api_type = "azure"
openai.api_base = "<エンドポイント名>"
openai.api_version = "2023-03-15-preview"
openai.api_key=os.environ.get("OPENAI_KEY")
def main(query: dict) -> str:
func_content = query.get("func_content")
if func_content:
message = query.get("message")
try:
# 最終的なチャット回答を取得
answer = third_process(message,func_content)
return answer
except Exception as e:
print(f"Openai error: {e}")
return "エラーが発生したわ。"
else:
return "エラーが発生したわ。"
# OPEAIから回答を生成
def third_process(message:str, func_content: str) -> str:
prompt = f""" \
You should generate your response based on the information in {func_content}.\
Never generate responses other than the information in {func_content}.\
Be absolutely sure to give the {func_content} information.\
Please only accept questions about the film, as we do not know anything other than questions about the film.\
Responses should be in Japanese with a pictogram at the end of the sentence.\
Please follow the sample responses below.\
___Answer Example___ \
あなたへのオススメは、{func_content}です♡\
"""
# 関数実行結果を使ってもう一度質問
response = openai.ChatCompletion.create(
engine="gpt-35model",
messages=[
{"role": "system", "content": prompt},
{"role": "assistant", "content": func_content},
{"role": "user", "content": message}
],
)
return response.choices[0]["message"]["content"].strip()
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "llmmessage",
"type": "activityTrigger",
"direction": "in"
}
]
}
実行結果
VS CodeからAzureへデプロイし、Postmanで叩いてみましょう。
以下はデプロイ方法の参考です
メッセージにわざとネガティブな感じを付け足してみます。
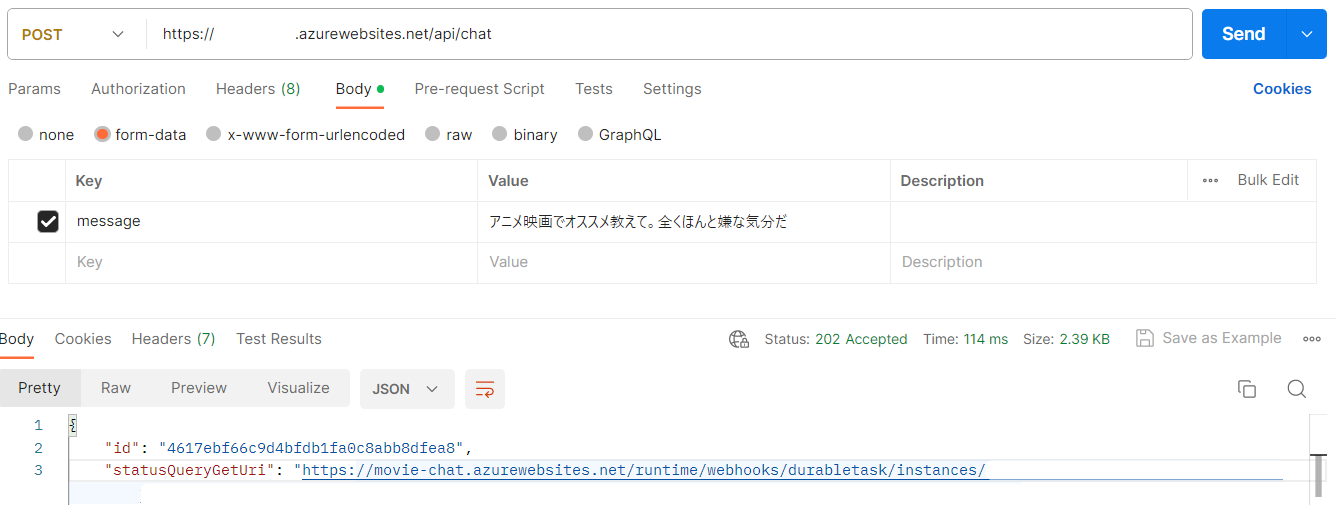
いくつかURLが払い出されるので、statusQueryGetUriにアクセスしてみます。

runtimeStatusがCompletedになって、outputに返答が格納されていますね。
「ボヘミアン・ラプソディ シャーロック・ホームズシャドウゲーム インディ・ジョーンズ/最後の聖戦 ラ・ラ・ランド ホビット思いがけない冒険」っておい。確かに適当感が満載です。
プロンプトが良くないのか文章からサイコ感が伝わり、嫌な気分が加速します💦
気持ちを入れ替えてポジティブに問いかけます。
Completedになったので、確認してみると…

普通に返してきましたね...
やってみて何ですが、キャラブレが激しくてなんか疲れます。
色々と試してみると予期せぬ動作は多々ありますがとりあえずの検証はできたかかと思います😅
それにしてもDrurableFunctionは便利ですね!継続して色々試していこうと思います!
参考