はじめに
Salesforceのデータ移行では、CSV受領、マッピングシート作成、Excelでのクレンジング、Data Loaderでの取込、エラー確認、再修正といった作業が発生します。
特に実務では、以下のような問題が起こりやすいです。
- お客様がCSVを出力できない
- 元データがテーブル構造になっていない
- 案件単位のデータをAccount / Contact / Opportunityに分解する必要がある
- マッピングシート作成に時間がかかる
- Excelでのクレンジング作業が属人化する
- テスト移行と本番移行で同じクレンジング作業を繰り返す
そこで今回は、従来のSalesforceデータ移行モデルを整理したうえで、Claude Code / Codex / AI APIを活用した新しい移行モデルを考えてみます。
現行のデータ移行フロー
これまでの一般的なデータ移行手順は、以下のような流れでした。
① お客様からCSV形式でデータをいただく
② マッピングシート作成
③ お客様と要件定義を行う
④ CSVデータをExcelでクレンジング
⑤ Data Loaderでデータ移行
⑥ お客様に移行結果を確認していただく
⑦ フィードバックをもとにマッピング修正
⑧ 再度CSVをいただいて、再クレンジング
図にすると、以下のようなイメージです。
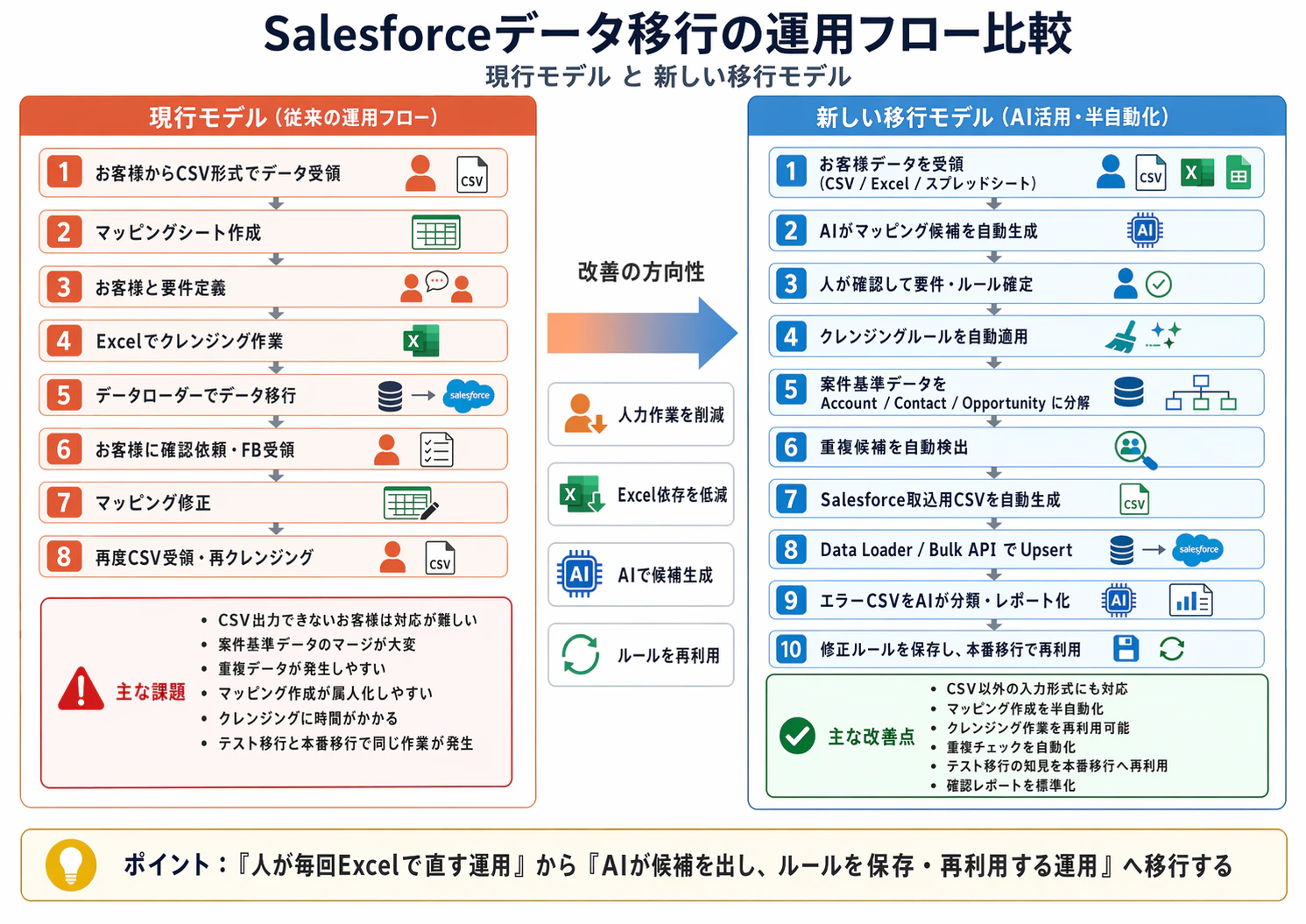
現行モデルの問題点
CSV出力できないお客様に対応しづらい
従来の進め方では、最初に「お客様からCSVをいただく」ことが前提になっています。
しかし、実際には以下のようなケースがあります。
- 独自システムからCSVを出力できない
- Excelで管理しているが、形式が統一されていない
- 画面上では見られるが、一覧出力機能がない
- ITリテラシーの問題で、データ抽出をお客様自身で実施できない
この場合、データ移行の入口で止まってしまいます。
案件基準データをSalesforce構造に変換するのが大変
お客様の元データが、必ずしもSalesforceのようなオブジェクト単位で管理されているとは限りません。
例えば、以下のように「案件基準」でデータが存在するケースがあります。
| 案件番号 | 顧客名 | 担当者名 | 案件名 | 金額 |
|---|---|---|---|---|
| A001 | ABC株式会社 | 山田太郎 | 契約A | 100,000 |
| A002 | ABC株式会社 | 山田太郎 | 契約B | 200,000 |
Salesforceでは、これを以下のように分解する必要があります。
- Account
- Contact
- Opportunity
この分解処理をExcelで手作業すると、重複や紐付けミスが発生しやすくなります。
マッピングシート作成が属人化しやすい
マッピングシート作成では、移行元データとSalesforce項目を対応付けます。
例:
| 移行元項目 | Salesforce項目 |
|---|---|
| 顧客名 | Account.Name |
| 電話番号 | Account.Phone |
| 案件名 | Opportunity.Name |
| 金額 | Opportunity.Amount |
この作業では、以下の理解が必要です。
- 移行元データの意味
- Salesforceのオブジェクト構造
- Salesforce項目のデータ型
- 必須項目
- 選択リスト値
- 参照関係
そのため、担当者の知識に依存しやすくなります。
クレンジング作業を毎回Excelで実施している
現行運用で特に負荷が高いのが、Excelでのクレンジングです。
よくあるクレンジング例は以下です。
| 対象 | 変換例 |
|---|---|
| 電話番号 |
03-1234-5678 → 0312345678
|
| 郵便番号 |
1234567 → 123-4567
|
| 日付 |
2026年4月1日 → 2026-04-01
|
| 空白 | 前後スペースを削除 |
| 表記ゆれ |
(株)ABC → 株式会社ABC
|
Excelで直接修正すると、作業内容がルールとして残りにくいです。
そのため、テスト移行で行った修正を、本番移行時にもう一度実施することになります。
新しい移行モデルの考え方
新しい移行モデルでは、以下の考え方に切り替えます。
人が毎回Excelで直す
↓
AIが候補を出す
↓
人が確認してルール化する
↓
ルールを保存する
↓
テスト移行・本番移行で再利用する
ポイントは、すべてをAIに任せることではありません。
重要なのは、人が判断した内容をルールとして保存し、次回以降に再利用できるようにすることです。
新しいデータ移行フロー
新しい運用フローは、以下のような流れです。
① お客様データを受領
CSV / Excel / スプレッドシートなどを許容
② AIがマッピング候補を自動生成
移行元項目とSalesforce項目の対応候補を作成
③ 人が確認して要件・ルールを確定
AIの候補をそのまま採用せず、人が確認する
④ クレンジングルールを自動適用
電話番号、日付、空白、表記ゆれなどをルール化
⑤ 案件基準データをSalesforce構造に分解
Account / Contact / Opportunityに分ける
⑥ 重複候補を自動検出
完全一致だけでなく、類似一致も確認する
⑦ Salesforce取込用CSVを自動生成
Data Loader / Bulk API用のCSVを作成
⑧ Data Loader / Bulk APIでUpsert
外部IDを使って再実行しやすい形にする
⑨ エラーCSVをAIが分類・レポート化
エラー原因と対応方針を整理する
⑩ 修正ルールを保存し、本番移行で再利用
AI活用ポイント
1. マッピング候補生成
移行元のヘッダーとサンプルデータをもとに、Salesforce項目との対応候補を作成します。
例:
| 移行元項目 | Salesforce候補 | 信頼度 | 確認要否 |
|---|---|---|---|
| 顧客名 | Account.Name | 95% | 不要 |
| 電話番号 | Account.Phone | 90% | 不要 |
| 案件名 | Opportunity.Name | 85% | 要確認 |
| ステータス | Status__c | 70% | 要確認 |
AIに最終判断を任せるのではなく、候補出しをさせるのがポイントです。
2. クレンジングルール生成
AIにデータの揺れを検出させ、クレンジング候補を出させます。
例:
{
"trim_spaces": true,
"normalize_width": true,
"remove_phone_hyphen": true,
"date_format": "YYYY-MM-DD",
"convert_to_blank": ["未設定", "なし", "不明"]
}
このようにルール化しておけば、テスト移行と本番移行で同じ処理を再利用できます。
3. 重複候補検出
完全一致だけではなく、表記ゆれを考慮した重複候補を検出します。
例:
| データA | データB | 判定 |
|---|---|---|
| 株式会社ABC | (株)ABC | 重複候補 |
| 山田 太郎 | 山田太郎 | 重複候補 |
| 03-1234-5678 | 0312345678 | 同一候補 |
Salesforceに取り込んだ後で重複を直すより、取込前に候補を検出する方が安全です。
4. Data Loaderエラーの分類
Data LoaderのエラーCSVをAIで分類すると、修正方針を整理しやすくなります。
| エラー | 主な原因 | 対応方針 |
|---|---|---|
| REQUIRED_FIELD_MISSING | 必須項目不足 | 元データ確認 |
| INVALID_OR_NULL_FOR_RESTRICTED_PICKLIST | 選択リスト不一致 | 変換表を追加 |
| DUPLICATE_VALUE | 外部ID重複 | 重複データを確認 |
| INVALID_CROSS_REFERENCE_KEY | 参照先なし | 親データの取込状況を確認 |
エラー分類を自動化すると、お客様への確認事項も作成しやすくなります。
Claude Code と Codex の使い分け
今回のようなSalesforceデータ移行支援ツールを作る場合、Claude CodeとCodexは以下のように使い分けるのがよいと考えています。
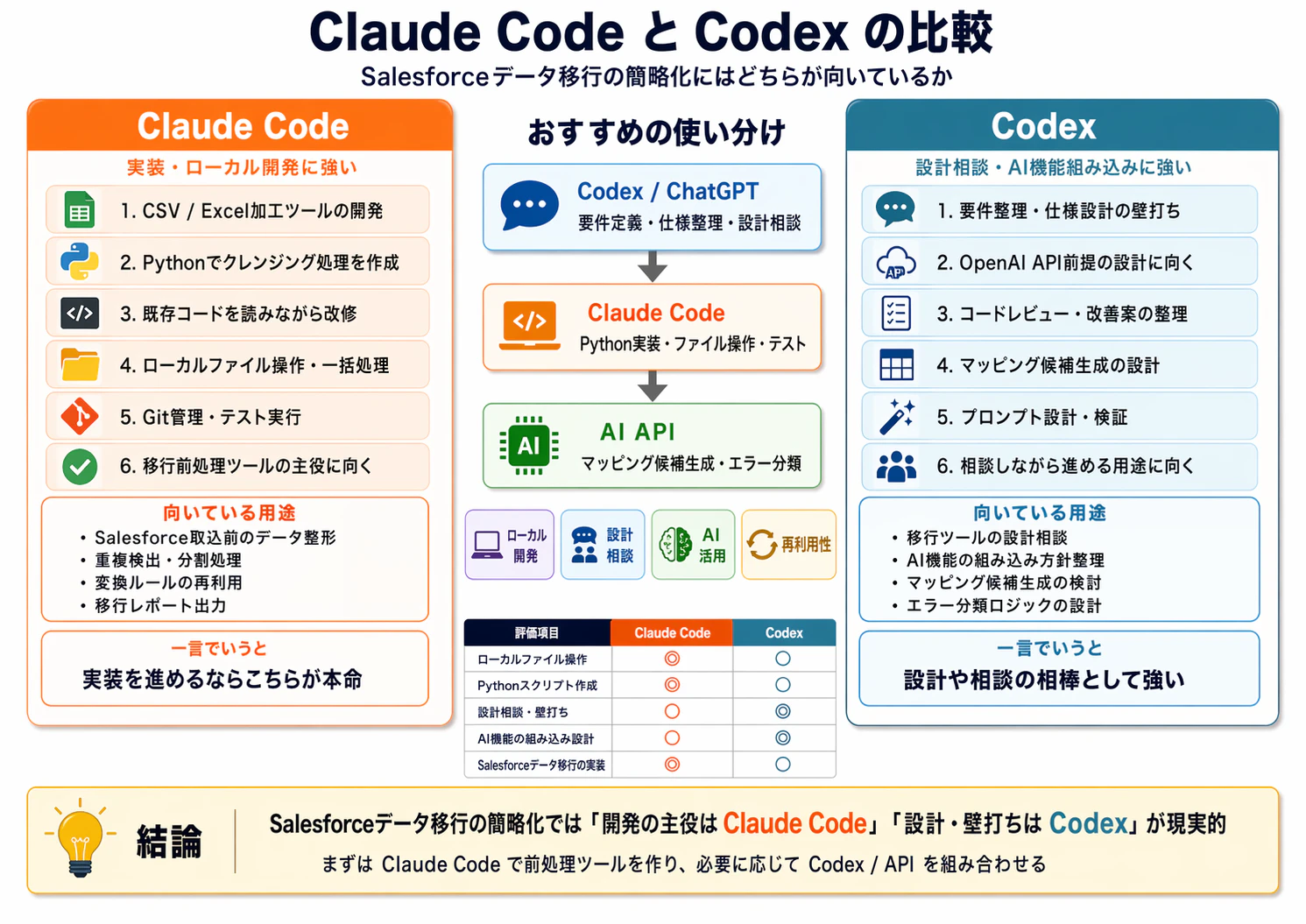
Claude Codeが向いている作業
Claude Codeは、ローカル開発や実装作業に向いています。
具体的には、以下のような作業です。
- CSV / Excel加工ツールの開発
- Pythonでクレンジング処理を作成
- 既存コードを読みながら改修
- ローカルファイル操作
- 一括処理
- Git管理
- テスト実行
- 移行レポート出力
Salesforceデータ移行でいうと、以下のような前処理ツールを作る用途に向いています。
Excel / CSV
↓
クレンジングルール適用
↓
Account.csv / Contact.csv / Opportunity.csv を生成
↓
移行レポートを出力
つまり、実装を進めるならClaude Codeが本命です。
Codexが向いている作業
Codexは、設計相談やAI機能の組み込み方針を整理する用途に向いています。
具体的には、以下のような作業です。
- 要件整理
- 仕様設計の壁打ち
- OpenAI API前提の設計
- コードレビュー
- 改善案の整理
- マッピング候補生成の設計
- プロンプト設計
- エラー分類ロジックの設計
Salesforceデータ移行でいうと、以下のような相談役として使うのがよいです。
どのような移行支援ツールにするか
どの処理をAIに任せるか
どの処理は人が確認すべきか
どのようなJSON形式でルールを保存するか
つまり、設計や相談の相棒としてCodexを使うイメージです。
おすすめの構成
個人的には、以下の構成が現実的だと思います。
Codex / ChatGPT
↓
要件定義・仕様整理・設計相談
Claude Code
↓
Python実装・ファイル操作・テスト
AI API
↓
マッピング候補生成・エラー分類
役割を分けると、以下のようになります。
| 役割 | ツール |
|---|---|
| 要件整理・仕様設計 | Codex / ChatGPT |
| 実装・ローカル開発 | Claude Code |
| AI判定・分類 | OpenAI API / Claude API |
| Salesforce取込 | Data Loader / Bulk API |
まず作るなら何か
いきなり大きなAI移行ツールを作るのではなく、まずは以下のような小さな前処理ツールから始めるのがよいです。
data-migration-assistant/
├── input/
│ └── customer_data.xlsx
├── rules/
│ └── cleansing_rules.json
├── mapping/
│ └── account_mapping.xlsx
├── output/
│ ├── Account.csv
│ ├── Contact.csv
│ ├── Opportunity.csv
│ └── migration_report.xlsx
├── scripts/
│ ├── clean_data.py
│ ├── split_objects.py
│ ├── detect_duplicates.py
│ └── generate_report.py
└── README.md
最初からAIで完全自動化する必要はありません。
まずは以下を自動化するだけでも、かなり効果があります。
- 電話番号の正規化
- 日付形式の統一
- 空白除去
- 選択リスト値の変換
- 重複候補の抽出
- Salesforce取込用CSVの出力
- 移行件数レポートの出力
最終的な運用イメージ
最終的には、以下のような運用を目指します。
お客様データを受領
↓
AIがマッピング候補を生成
↓
人が確認してルール確定
↓
Pythonツールでクレンジング実行
↓
Salesforce取込用CSVを生成
↓
Data Loader / Bulk APIでUpsert
↓
エラーCSVをAIで分類
↓
修正ルールを保存
↓
本番移行で再利用
この形にできれば、移行作業は以下のように変わります。
Excelで毎回手作業する運用
↓
ルールを保存して再利用する運用
まとめ
Salesforceデータ移行を簡略化するうえで重要なのは、AIにすべてを任せることではありません。
重要なのは、以下の3点です。
- AIに候補を出させる
- 人が確認してルールを確定する
- ルールを保存して再利用する
特に効果が大きいのは、クレンジング作業の再利用化です。
人が毎回Excelで直す
↓
AIが候補を出す
↓
人が承認する
↓
ルールを保存する
↓
テスト移行・本番移行で再利用する
Claude CodeとCodexの使い分けとしては、以下が現実的です。
開発の主役:Claude Code
設計・壁打ち:Codex / ChatGPT
AI判定エンジン:OpenAI API / Claude API
まずはClaude Codeで、CSV / ExcelをSalesforce取込用CSVに変換する前処理ツールを作るところから始めるのがよいと思います。