DbUnitとは
- Java でデータベースのテストを行うためのフレームワーク
- JUnit でテストを実行する前にデータベースにテストデータを登録したり、テスト後のデータベースの状態が期待通りか検証したりできたりする
- テストデータや期待値は XML、CSV、Excel 形式で定義できる
- 結構昔からあるけど、2022年現在も Java でデータベースのテストをする場合は DbUnit が現役らしい1
環境
OS とか Java とかのバージョン。
>gradle --version
------------------------------------------------------------
Gradle 7.4.2
------------------------------------------------------------
Build time: 2022-03-31 15:25:29 UTC
Revision: 540473b8118064efcc264694cbcaa4b677f61041
Kotlin: 1.5.31
Groovy: 3.0.9
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 18.0.1.1 (Oracle Corporation 18.0.1.1+2-6)
OS: Windows 10 10.0 amd64
データベース
基本的に HSQLDB をインメモリモードで利用する。
ただし、一部だけ PostgreSQL を使用している。
PostgreSQL は、 Docker で起動。
services:
postgres:
image: postgres:14.4
container_name: postgres-14.4
ports:
- "5432:5432"
volumes:
- postgres-14.4:/var/lib/postgresql/data
environment:
POSTGRES_PASSWORD: postgres
volumes:
postgres-14.4: {}
Hello World
実装
|-build.gradle
`-src/test/
|-java/
| `-sandbox/dbunit/
| `-HelloDbUnitTest.java
`-resources/
`-sandbox/dbunit/HelloDbUnitTest/test/
|-setUp.xml
`-expected.xml
plugins {
id "java"
}
sourceCompatibility = 18
targetCompatibility = 18
[compileJava, compileTestJava]*.options*.encoding = "UTF-8"
repositories {
mavenCentral()
}
dependencies {
testRuntimeOnly "org.hsqldb:hsqldb:2.6.1"
testImplementation "org.junit.jupiter:junit-jupiter:5.8.2"
testImplementation "org.dbunit:dbunit:2.7.3"
}
test {
useJUnitPlatform()
}
package sandbox.dbunit;
import org.dbunit.IDatabaseTester;
import org.dbunit.JdbcDatabaseTester;
import org.dbunit.database.IDatabaseConnection;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import static org.dbunit.Assertion.assertEquals;
public class HelloDbUnitTest {
static IDatabaseTester databaseTester;
static IDatabaseConnection connection;
@BeforeAll
static void beforeAll() throws Exception {
databaseTester =
new JdbcDatabaseTester("org.hsqldb.jdbcDriver", "jdbc:hsqldb:mem:test");
connection = databaseTester.getConnection();
// DB初期化(テーブル作成)
Connection jdbcConnection = connection.getConnection();
try (
PreparedStatement ps = jdbcConnection.prepareStatement("""
create table test_table (
id integer primary key,
value varchar(8)
)""");
) {
ps.execute();
}
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet =
readXmlDataSet("/sandbox/dbunit/HelloDbUnitTest/test/setUp.xml");
databaseTester.setDataSet(setUpDataSet);
databaseTester.onSetup();
}
@Test
void test() throws Exception {
XmlDataSet expected =
readXmlDataSet("/sandbox/dbunit/HelloDbUnitTest/test/expected.xml");
IDataSet actual = connection.createDataSet();
assertEquals(expected, actual);
}
@AfterAll
static void afterAll() throws Exception {
if (connection != null) {
connection.close();
}
}
private XmlDataSet readXmlDataSet(String path) throws Exception {
try (InputStream inputStream = getClass().getResourceAsStream(path)) {
return new XmlDataSet(inputStream);
}
}
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>hoge</value>
</row>
<row>
<value>2</value>
<value>fuga</value>
</row>
<row>
<value>3</value>
<value>piyo</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>HOGE</value>
</row>
<row>
<value>2</value>
<value>fuga</value>
</row>
<row>
<value>3</value>
<value>piyo</value>
</row>
</table>
</dataset>
実行結果
Actual value='hoge' is not equal to expected value='HOGE': value (table=test_table, row=0, col=value) expected:<HOGE> but was:<hoge>
Expected :HOGE
Actual :hoge
説明
dependencies {
...
testImplementation "org.dbunit:dbunit:2.7.3"
}
- org.dbunit:dbunit を依存関係に追加する
public class HelloDbUnitTest {
static IDatabaseTester databaseTester;
static IDatabaseConnection connection;
@BeforeAll
static void beforeAll() throws Exception {
databaseTester =
new JdbcDatabaseTester("org.hsqldb.jdbcDriver", "jdbc:hsqldb:mem:test");
connection = databaseTester.getConnection();
...
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet =
readXmlDataSet("/sandbox/dbunit/HelloDbUnitTest/test/setUp.xml");
databaseTester.setDataSet(setUpDataSet);
databaseTester.onSetup();
}
...
@AfterAll
static void afterAll() throws Exception {
if (connection != null) {
connection.close();
}
}
private XmlDataSet readXmlDataSet(String path) throws Exception {
try (InputStream inputStream = getClass().getResourceAsStream(path)) {
return new XmlDataSet(inputStream);
}
}
}
- まずは、
JdbcDatabaseTesterのインスタンスを生成する- コンストラクタ引数で、接続先の DB の情報を設定する
-
setDataSet(IDataSet)で、テスト前に DB に投入するテストデータを設定する(まだ投入はされない)- DbUnit では、データのまとまりをデータセットと呼び、
IDataSetというインタフェースで表現している- データセットには、複数のテーブルが含まれる
- 投入データだけでなく、期待値のデータも
IDataSetで表現する
-
IDataSetには、データの取得方法によって様々な実装クラスが用意されている- データベース →
DatabaseDataSet - Excel →
XlsDataSet - CSV →
CsvDataSet/CsvURLDataSet - XML →
XmlDataSet,FlatXmlDataSet
- データベース →
- ここでは、 XML からデータを読み取る
XmlDataSetでテストデータを読み込んでいる
- DbUnit では、データのまとまりをデータセットと呼び、
-
IDatabaseTesterのgetConnection()で、IDatabaseConnectionを取得しておく- あとで、検証のためにデータベースの状態を取得したりするのに利用する
- 生成にはコストがかかるので、一度作成したインスタンスは再利用することが推奨されている
- データベース接続を管理しているので、
@AfterAllで確実にクローズする
-
IDatabaseTester#onSetup()を、テスト前に実行する-
setDataSet()で設定したテストデータの投入などが行われる - デフォルトでは、データは DELETE → INSERT される
-
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>HOGE</value>
</row>
...
</table>
</dataset>
- XML でデータセットを定義している
- 前述のとおり、 XML 以外にも Excel などで定義することも可能
IDatabaseConnection connection;
...
@Test
void test() throws Exception {
XmlDataSet expected =
readXmlDataSet("/sandbox/dbunit/HelloDbUnitTest/test/expected.xml");
IDataSet actual = connection.createDataSet();
assertEquals(expected, actual);
}
-
IDatabaseConnectionのcreateDataSet()で、実際のデータベースのデータを表すIDataSetを取得できる -
org.dbunit.Assertion#assertEquals(IDataSet, IDataSet)で、IDataSet同士の検証ができる
検証用の自作 JUnit 拡張
以降は、コードを書きやすくするために、以下の自作の JUnit 拡張を利用する前提でコードを記述する。
package sandbox.dbunit;
import org.dbunit.IDatabaseTester;
import org.dbunit.JdbcDatabaseTester;
import org.dbunit.database.IDatabaseConnection;
import org.dbunit.dataset.Column;
import org.dbunit.dataset.DataSetException;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.ITableMetaData;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.extension.AfterAllCallback;
import org.junit.jupiter.api.extension.BeforeAllCallback;
import org.junit.jupiter.api.extension.ExtensionContext;
import java.io.IOException;
import java.io.InputStream;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class MyDbUnitExtension implements BeforeAllCallback, AfterAllCallback {
private IDatabaseTester databaseTester;
private IDatabaseConnection connection;
@Override
public void beforeAll(ExtensionContext context) throws Exception {
String testClassName = context.getRequiredTestClass().getSimpleName();
databaseTester = new JdbcDatabaseTester(
"org.hsqldb.jdbcDriver", "jdbc:hsqldb:mem:" + testClassName );
connection = databaseTester.getConnection();
}
@Override
public void afterAll(ExtensionContext context) throws Exception {
if (connection != null) {
connection.close();
}
}
public void sql(String sql) {
try (PreparedStatement ps = connection.getConnection().prepareStatement(sql)) {
ps.execute();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public XmlDataSet readXmlDataSet(String path) {
try (InputStream inputStream = getClass().getResourceAsStream(path)) {
return new XmlDataSet(inputStream);
} catch (DataSetException | IOException e) {
throw new RuntimeException(e);
}
}
public void printTable(String tableName) {
try {
System.out.println(tableName + " {");
ITable table = this.getConnection().createDataSet().getTable(tableName);
ITableMetaData metaData = table.getTableMetaData();
for (int row=0; row<table.getRowCount(); row++) {
List<String> values = new ArrayList<>();
for (Column column : metaData.getColumns()) {
Object value = table.getValue(row, column.getColumnName());
values.add(column.getColumnName() + "=" + format(value));
}
System.out.println(" " + String.join(", ", values));
}
System.out.println("}");
} catch (DataSetException | SQLException e) {
throw new RuntimeException(e);
}
}
private String format(Object value) {
if (value == null) {
return "null";
}
if (value instanceof String) {
return "'" + value + "'";
}
return value.toString();
}
public IDatabaseTester getDatabaseTester() {
return databaseTester;
}
public IDatabaseConnection getConnection() {
return connection;
}
}
- テストクラスごとに毎回必要になる以下の処理をまとめている
-
@BeforeAllで、IDatabaseTesterとIDatabaseConnectionの生成 -
@AfterAllで、IDatabaseConnectionのclose()
-
- 検証をしやすくするために、以下のメソッドを定義している
-
sql(String)- 指定された任意の SQL を実行する
-
readXmlDataSet(String)- 指定されたパスから
XmlDataSetを読み込む
- 指定されたパスから
-
printTable(String)- 指定されたテーブルの中身を標準出力に出力する
-
nullの場合は、単にnullと出力する - 文字列(
String) の場合は、シングルクォート(') で括って出力する - それ以外の場合は、単に
toString()した値を出力する
-
テスト前後のクリーンアップなどの挙動を変える
IDatabaseTester.onSetup() で実行する処理は、 setSetUpOperation(DatabaseOperation) で変更できる。
以下のようなクラスを準備して、それぞれの DatabaseOperation での動きを確認する。
package sandbox.dbunit;
import org.dbunit.dataset.xml.XmlDataSet;
import org.dbunit.operation.DatabaseOperation;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
public class DatabaseOperationTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
value varchar(32)
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
foo_id integer,
foreign key (foo_id) references foo_table (id)
)""");
}
@BeforeEach
void setUp() {
myDbUnitExtension.sql("truncate table bar_table");
myDbUnitExtension.sql("truncate table foo_table");
myDbUnitExtension.sql("insert into foo_table values (9, 'HOGE')");
myDbUnitExtension.sql("insert into foo_table values (99, 'FUGA')");
myDbUnitExtension.sql("insert into bar_table values (10, 9)");
myDbUnitExtension.sql("insert into bar_table values (100, 99)");
System.out.println("[初期状態]");
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
private void printTables() {
System.out.println("[onSetup()実行後]");
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
}
-
foo_tableとbar_tableを作成し、テストごとに初期データを投入している
UPDATE
@Test
void testUpdate() throws Exception {
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.UPDATE);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testUpdate.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>foo</value>
</row>
<row>
<value>9</value>
<value>UPDATE</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=9, VALUE='UPDATE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
-
UPDATEでは、データセットに存在するレコードだけが更新される - データセットには存在するけど実際には存在しないレコードの更新は無視される
- 更新対象外の既存レコードは変更されない
INSERT
@Test
void testInsert() throws Exception {
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.INSERT);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testInsert.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>foo</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=1, VALUE='foo'
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
-
INSERTでは、データセットで指定されたレコードが追加される - 既存レコードは更新されない
DELETE
@Test
void testDelete() throws Exception {
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.DELETE);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testDelete.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<row>
<value>1</value>
</row>
<row>
<value>9</value>
</row>
</table>
<table name="bar_table">
<column>id</column>
<row>
<value>10</value>
</row>
<row>
<value>100</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=99, VALUE='FUGA'
}
bar_table {
}
-
DELETEでは、データセットで指定されたレコードだけが削除される - 削除は、データセット上の並び順の逆で行われる
- 外部キー制約を考慮した挙動
- データセットに存在するけど実際には存在しないレコードについては無視される
DELETE_ALL
@Test
void testDeleteAll() throws Exception {
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.DELETE_ALL);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testDeleteAll.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="bar_table">
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
}
-
DELETE_ALLでは、データセットで指定されたテーブルの全データが削除される - 削除は、データセット上での順序の逆順で行われる
- 外部キー制約を考慮した動き
TRUNCATE
@Test
void testTruncate() throws Exception {
myDbUnitExtension
.getDatabaseTester().setSetUpOperation(DatabaseOperation.TRUNCATE_TABLE);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testTruncate.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
</table>
<table name="bar_table">
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
}
bar_table {
}
-
TRUNCATEでは、データセットで指定されたテーブルを切り捨てる - 切り捨ては、データセット上の順番の逆順で行われる
- 外部キー制約を考慮した動き
REFRESH
@Test
void testRefresh() throws Exception {
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.REFRESH);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testRefresh.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>foo</value>
</row>
<row>
<value>9</value>
<value>UPDATE</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=1, VALUE='foo'
ID=9, VALUE='UPDATE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
-
REFRESHでは、INSERTとUPDATEを組み合わせたような更新が行われる- データセットには存在するけど実際には存在しないレコードは追加される
- データセットにも実際にも既存するレコードは更新される
CLEAN_INSERT
@Test
void testCleanInsert() throws Exception {
myDbUnitExtension
.getDatabaseTester().setSetUpOperation(DatabaseOperation.CLEAN_INSERT);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testCleanInsert.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>foo</value>
</row>
</table>
<table name="bar_table">
<column>id</column>
<column>foo_id</column>
<row>
<value>1</value>
<value>1</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=1, VALUE='foo'
}
bar_table {
ID=1, FOO_ID=1
}
-
CLEAN_INSERTでは、DELETE_ALLとINSERTを組み合わせた処理が行われる- データセットで指定されたテーブルのデータが全て削除されたうえで、データの登録が行われる
-
setSetUpOperation()が未指定の場合、デフォルトではこの処理が設定されている
DataseOperation を手動で実行する
@Test
void testManual() throws Exception {
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testManual.xml");
DatabaseOperation.CLEAN_INSERT.execute(myDbUnitExtension.getConnection(), xmlDataSet);
System.out.println("execute()実行後");
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>9</value>
<value>UPDATE</value>
</row>
</table>
<table name="bar_table">
<column>id</column>
<row>
<value>100</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
execute()実行後
foo_table {
ID=9, VALUE='UPDATE'
}
bar_table {
ID=100, FOO_ID=null
}
-
DatabaseOperation.execute(IDatabaseConnection, IDataSet)メソッドを使えば、onSetup()で行われている処理を手動で実行できる
テスト後の後処理
@Test
void testOnTearDown() throws Exception {
myDbUnitExtension.getDatabaseTester().setTearDownOperation(DatabaseOperation.UPDATE);
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DatabaseOperationTest/testOnTearDown.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onTearDown();
printTables();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>9</value>
<value>TEAR_DOWN</value>
</row>
</table>
</dataset>
[初期状態]
foo_table {
ID=9, VALUE='HOGE'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
[onSetup()実行後]
foo_table {
ID=9, VALUE='TEAR_DOWN'
ID=99, VALUE='FUGA'
}
bar_table {
ID=10, FOO_ID=9
ID=100, FOO_ID=99
}
-
IDatabaseTester.onTearDown()を実行すると、setDataSet(IDataSet)で設定されたデータセットを使って後処理が実行される - ただし、デフォルトでは
DatabaseOperation.NONEが設定されているため、そのままでは何も実行されない - 何かしら処理をさせたい場合は、
IDatabaseTester.setTearDownOperation(DatabaseOperation)でNONE以外を設定する必要がある
Equality Comparison
-
assertEquals(IDataSet, IDataSet)などの検証では、 Equality Comparison (同値比較?)が行われる - Equality Comparison では、2つのデータセットが完全に一致していることが検証される
- それぞれのデータセットに含まれるテーブルやカラムの数が異なる場合、デフォルトではテストが失敗する
org.dbunit.assertion.DbComparisonFailure[table countexpected:<3>but was:<2>]
org.dbunit.assertion.DbComparisonFailure[column count (table=foo_table, expectedColCount=2, actualColCount=3)expected:<[id, text]>but was:<[id, numeric, text]>]
特定のテーブルだけを比較する
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<row>
<value>1</value>
<value>foo</value>
<value>99</value>
</row>
</table>
<table name="bar_table">
<column>id</column>
<column>text</column>
<row>
<value>1</value>
<value>bar</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<row>
<value>1</value>
<value>foo</value>
<value>99</value>
</row>
</table>
</dataset>
- 期待値の XML には
bar_tableが存在しないので、そのまま検証すると失敗する
package sandbox.dbunit;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import static org.dbunit.Assertion.assertEquals;
public class AssertSpecifiedTableTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
text varchar(32),
numeric integer
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
text varchar(32)
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/AssertSpecifiedTableTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUpDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void testGetTable() throws Exception {
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
ITable actualFooTable = actual.getTable("foo_table");
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/AssertSpecifiedTableTest/expected.xml");
ITable expectedFooTable = expected.getTable("foo_table");
assertEquals(expectedFooTable, actualFooTable);
}
}
-
IDataSetのgetTable(String)を使うと、テーブル単位でデータを抽出できる - テーブル単位のデータは、
ITableという型で表現される -
ITableを比較するためのassertEquals(ITable, ITable)が用意されているので、これを使うことでテーブル単位の比較ができる
IDatbaseConnection には createTable(String) というメソッドもあり、 IDataSet を介さずに直接 ITable を取得することもできる。
しかし、 Javadoc に書いてある通り実行される SQL は select * from tableName となっていてソート条件が指定されない。
ソート条件が指定されないと検索結果の並びは DB 依存で予測できなくなるので、テストで使うには不向きな気がする。
なお、 IDataSet の getTable() で取得した場合は主キーでソートされている。
クエリ結果を ITable として取得する
@Test
void testCreateQueryTable() throws Exception {
ITable actualFooTable = myDbUnitExtension.getConnection()
.createQueryTable("foo_table", "select * from foo_table order by id");
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/AssertSpecifiedTableTest/expected.xml");
ITable expectedFooTable = expected.getTable("foo_table");
assertEquals(expectedFooTable, actualFooTable);
}
-
IDatabaseConnectionのcreateQueryTable(String, String)を使用することで、任意のクエリ結果をITableとして取得できる- 第一引数にはテーブル名を設定する
- この名前は、返却される
ITableのgetTableMetaData()で取得できるITableMetaDataのgetTableName()が返す値に使用される - 特に実際のテーブル名と異なっていてもエラーにはならないが、基本は実際のテーブル名に合わせるのがいい気がする
- join している場合とかは、識別しやすい名前にしとくのがいいのかもしれない
- この名前は、返却される
- 第二引数には、実行するクエリを設定する
- 第一引数にはテーブル名を設定する
- 任意のクエリなので、 join 結果を受け取ることもできる
期待値に存在するカラムだけで比較する
値が自動採番されるIDや更新日時のようなカラムは実行時に値が決定するため、あらかじめ決まった値の期待値を用意しておくことが難しい。
このため、そういうカラムだけテストの検証から除外したくなることがまれによくある。
ただ、できる限りそういうカラムもテスト対象に含めるべきだとは個人的に思う。
IDがシーケンスオブジェクトで採番されているのであれば、テスト前にシーケンスオブジェクトを更新して狙った値が採番されるように調整したり、日時項目はテストのときだけ指定値が利用されるような仕組みにしておくなど。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<row>
<value>1</value>
<value>foo</value>
<value>99</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>text</column>
<row>
<value>1</value>
<value>foo</value>
</row>
</table>
</dataset>
- 期待値の XML には、
numericカラムが存在しない - このまま単純に
assertEquals()で比較すると、テストは失敗する
package sandbox.dbunit;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.filter.DefaultColumnFilter;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import static org.dbunit.Assertion.assertEquals;
public class IgnoringSomeColumnsTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
text varchar(32),
numeric integer
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/IgnoringSomeColumnsTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUpDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void test() throws Exception {
ITable actualFooTable = myDbUnitExtension
.getConnection().createDataSet().getTable("foo_table");
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/IgnoringSomeColumnsTest/expected.xml");
ITable expectedFooTable = expected.getTable("foo_table");
ITable filteredActualFooTable = DefaultColumnFilter
.includedColumnsTable(
actualFooTable,
expectedFooTable.getTableMetaData().getColumns()
);
assertEquals(expectedFooTable, filteredActualFooTable);
}
}
-
DefaultColumnFilterのincludedColumnsTable(ITable, Column[])を使用すると、第二引数で指定したカラムだけに絞ったITableが返される - 実際の DB から生成され全てのカラムを持つ
actualFooTableから、期待値のexpectedFooTableだけが持つカラムだけに絞ったITableを作ることで、期待値で定義したカラムだけで検証ができるようになる
ソート条件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>3</value>
<value>aaa</value>
</row>
<row>
<value>2</value>
<value>bbb</value>
</row>
<row>
<value>1</value>
<value>ccc</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>3</value>
<value>aaa</value>
</row>
<row>
<value>2</value>
<value>bbb</value>
</row>
<row>
<value>1</value>
<value>ccc</value>
</row>
</table>
</dataset>
-
setUp.xmlとexpected.xmlは、全く同じ内容にしている
package sandbox.dbunit;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
public class RowOrderingTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
value varchar(8)
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUp = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/RowOrderingTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUp);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void test() throws Exception {
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/RowOrderingTest/expected.xml");
assertEquals(expected, actual);
}
}
-
setUp.xmlを投入してexpected.xmlと比較する
org.dbunit.assertion.DbComparisonFailure[Actual value='1' is not equal to expected value='3': value (table=test_table, row=0, col=id)expected:<3>but was:<1>]
-
IDatabaseConnection#createDataSet()で取得したデータセットは、デフォルトでは主キーでソートされている -
assertEquals()による比較は、データの順序も検証対象となる - したがって、上のテストは1行目から
idに差異が生まれエラーとなっている-
expectedは XML で定義したままid=3が1行目になっている -
actualは主キーでソートされているので、id=1が1行目になっている
-
- テーブルに主キーが存在しない場合、ソート順序は不定となる
- その場合、テストが成功するかどうかも不定になる
- このため、ソート条件は必ず設定された状態にすべき
ソート条件を指定する
明示的にソート条件を指定したい場合、1つは前述した IDatabaseConnection#createQueryTable(String) を使用する方法がある
もう1つの方法として、 SortedTable を使う方法がある。
public class RowOrderingTest {
...
@Test
void testSortedTable() throws Exception {
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
SortedTable sortedActualTestTable =
new SortedTable(actual.getTable("test_table"), new String[]{"value"});
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/RowOrderingTest/expected.xml");
ITable expectedTestTable = expected.getTable("test_table");
assertEquals(expectedTestTable, sortedActualTestTable); // このテストは成功する
}
}
-
SortedTableを使うと、指定したITableのデータをソートした状態にできる- コンストラクタの第一引数でソートしたい
ITableを指定する - 第二引数にはソート対象のカラムを配列で指定する
- コンストラクタの第一引数でソートしたい
数値項目を数値としてソートする
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<row>
<value>1</value>
<value>ccc</value>
<value>10</value>
</row>
<row>
<value>2</value>
<value>bbb</value>
<value>2</value>
</row>
<row>
<value>3</value>
<value>aaa</value>
<value>1</value>
</row>
<row>
<value>4</value>
<value>ddd</value>
<value>10</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<row>
<value>3</value>
<value>aaa</value>
<value>1</value>
</row>
<row>
<value>2</value>
<value>bbb</value>
<value>2</value>
</row>
<row>
<value>1</value>
<value>ccc</value>
<value>10</value>
</row>
<row>
<value>4</value>
<value>ddd</value>
<value>10</value>
</row>
</table>
</dataset>
-
nemeric→textの順番にソートして取得することを期待した状態にしておく
package sandbox.dbunit;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.SortedTable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import static org.dbunit.Assertion.assertEquals;
public class SortedTableForNumericTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
text varchar(8),
numeric integer
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUp = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/SortedTableForNumericTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUp);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void testDefault() throws Exception {
ITable actualTestTable = myDbUnitExtension
.getConnection().createDataSet().getTable("test_table");
SortedTable sortedActualTestTable =
new SortedTable(actualTestTable, new String[]{"numeric", "text"});
ITable expectedTestTable = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/SortedTableForNumericTest/expected.xml")
.getTable("test_table");
assertEquals(expectedTestTable, sortedActualTestTable);
}
}
-
SortedTableで、nemeric→textの順番でソートして比較する
org.dbunit.assertion.DbComparisonFailure[value (table=test_table, row=1, col=id)expected:<2>but was:<1>]
- 2行目で
id=2 (numeric=2, text=bbb)を期待していたのに、実際にはid=1 (numeric=10, text=ccc)が来てしまいテストが失敗した -
SortedTableは、デフォルトでは各値を文字列としてソートするようになっている- このため、
sortedActualTestTableは以下の順序でソートされている- id=3, text=aaa, numeric=1
- id=1, text=ccc, numeric=10
- id=4, text=ddd, numeric=10
- id=2, text=bbb, numeric=2
-
numericを文字列としてソートするため、 "1" -> "10" -> "2" の順番になっている
- このため、
- 数値項目を数値としてソートしたい場合は、
setUseComparable(boolean)にtrueを設定する必要がある
public class SortedTableForNumericTest {
...
@Test
void testUseComparableTrue() throws Exception {
ITable actualTestTable = myDbUnitExtension
.getConnection().createDataSet().getTable("test_table");
SortedTable sortedActualTestTable =
new SortedTable(actualTestTable, new String[]{"numeric", "text"});
sortedActualTestTable.setUseComparable(true); // ★
ITable expectedTestTable = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/SortedTableForNumericTest/expected.xml")
.getTable("test_table");
assertEquals(expectedTestTable, sortedActualTestTable); // このテストは成功する
}
}
-
SortedTableのインスタンスを生成した直後に、setUseComaprable(true)を実行する-
setUseComparable()はコンストラクタでインスタンスを生成した直後に呼ばなければならない - だったらコンストラクタの引数に指定できるようにしておけばいい気がするが、それをするとすで4つ存在している
SortedTableのコンストラクタが8つに増大するためしないらしい2
-
- これにより、数値項目は数値としてソートされるようになる
値が異なる箇所をすべて収集する
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>aaa</value>
</row>
<row>
<value>2</value>
<value>bbb</value>
</row>
<row>
<value>3</value>
<value>ccc</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>AAA</value>
</row>
<row>
<value>3</value>
<value>bbb</value>
</row>
<row>
<value>4</value>
<value>CCC</value>
</row>
</table>
</dataset>
- わざと複数の差分が発生するように期待値を設定している
package sandbox.dbunit;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import static org.dbunit.Assertion.assertEquals;
public class CollectDifferencesTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
value varchar(8)
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUp = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/CollectDifferencesTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUp);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void testDefault() throws Exception {
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/CollectDifferencesTest/expected.xml");
assertEquals(expected, actual);
}
}
-
setUp.xmlを投入して、expected.xmlと比較
org.dbunit.assertion.DbComparisonFailure[Actual value='aaa' is not equal to expected value='AAA': value (table=test_table, row=0, col=value)expected:<AAA>but was:<aaa>]
- デフォルトでは、カラムの値を比較していって最初に差分が見つかった時点で即座にテストは失敗する
- もし、すべての差分を集めてからテストを失敗させたい場合は、
DiffCollectingFailureHandlerを使用する
@Test
void testCollectDifferences() throws Exception {
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/CollectDifferencesTest/expected.xml");
DiffCollectingFailureHandler failureHandler = new DiffCollectingFailureHandler();
assertEquals(expected, actual, failureHandler);
@SuppressWarnings("unchecked")
List<Difference> diffList = failureHandler.getDiffList();
if (!diffList.isEmpty()) {
String errorMessage = diffList.stream()
.map(diff -> String.format("row=%d, column=%s, failMessage=%s",
diff.getRowIndex(),
diff.getColumnName(),
diff.getFailMessage()))
.collect(Collectors.joining("\n"));
fail(errorMessage);
}
}
org.opentest4j.AssertionFailedError: row=0, column=value, failMessage=Actual value='aaa' is not equal to expected value='AAA'
row=1, column=id, failMessage=Actual value='2' is not equal to expected value='3'
row=2, column=id, failMessage=Actual value='3' is not equal to expected value='4'
row=2, column=value, failMessage=Actual value='ccc' is not equal to expected value='CCC'
- すべての差分の情報が収集できている
-
assertEquals()には、第三引数にFailureHandlerを受け取ることができるメソッドが用意されている -
FailureHandlerは、検証でエラーになったときのもろもろの制御を定義するインタフェースとなっている -
DiffCollectingFailureHandlerは、カラムの値に差分があっても例外をスローせずに内部のListに差分(Difference)を収集するようになっている - したがって、差分があっても
assertEquals()は失敗せずに戻るようになっている -
DiffCollectingFailureHandlerのgetDiffList()で、収集されたDifferenceのリストを取得できる- まさかの raw 型!
- また、
DifferenceをそのままtoString()しただけだと余分な情報が多すぎて読みにくいので、適度に必要な情報だけに絞って出力した方がいい
DiffCollectingFailureHandler を指定した場合に assertEquals() が例外をスローしないのは各カラムの値を比較したときに差分があった場合の話で、テーブル数やレコード数に差があったり、カラム数が異なっているなどそもそもカラムの値の比較ができないような状態では即座に例外がスローされるので注意。
DiffCollectingFailureHandler の実装はかなりアレなので、自分なら代わりに以下のようなクラスを作る気がする。
package sandbox.dbunit;
import org.dbunit.assertion.DefaultFailureHandler;
import org.dbunit.assertion.Difference;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import static org.junit.jupiter.api.Assertions.fail;
public class MyDiffCollectingFailureHandler extends DefaultFailureHandler {
private List<Difference> diffList = new ArrayList<>();
@Override
public void handle(Difference diff) {
diffList.add(diff);
}
public void failIfExistsDifferences() {
if (diffList.isEmpty()) {
return;
}
String errorMessage = diffList.stream()
.map(diff -> String.format("row=%d, column=%s, failMessage=%s",
diff.getRowIndex(),
diff.getColumnName(),
diff.getFailMessage()))
.collect(Collectors.joining("\n"));
fail(errorMessage);
}
}
データ型
数値や文字列型の項目の場合は、データセットファイルに書いた値がそのままデータベースに取り込まれる。
一方、 BLOB 型や日付型の項目の場合、書式はどう指定すればいいのか以下でまとめる。
BLOB 型
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>text</column>
<column>base64</column>
<column>file</column>
<column>url</column>
<row>
<value>1</value>
<value>[TEXT UTF-8]あいうえお</value>
<value>[BASE64]44GL44GN44GP44GR44GT</value><!-- UTF-8でデコードすると「かきくけこ」になる -->
<value>[FILE]./src/test/resources/sandbox/dbunit/BlobTest/file.txt</value>
<value>[URL]file:./src/test/resources/sandbox/dbunit/BlobTest/url.txt</value>
</row>
</table>
</dataset>
さしすせそ
たちつてと
package sandbox.dbunit;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.nio.charset.StandardCharsets;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class BlobTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
text blob,
base64 blob,
file blob,
url blob
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/BlobTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUpDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void test() throws Exception {
ITable testTable = myDbUnitExtension
.getConnection().createDataSet().getTable("test_table");
// 以下のテストはすべて成功する
assertEquals(toString(testTable.getValue(0, "text")), "あいうえお");
assertEquals(toString(testTable.getValue(0, "base64")), "かきくけこ");
assertEquals(toString(testTable.getValue(0, "file")), "さしすせそ");
assertEquals(toString(testTable.getValue(0, "url")), "たちつてと");
}
private String toString(Object value) {
byte[] bytes = (byte[]) value;
return new String(bytes, StandardCharsets.UTF_8);
}
}
BLOB 型の項目に値を設定する場合は、以下のような書式で値を記述する。
[DATA_TYPE]value
-
DATA_TYPEでバイナリデータを読み込む方法を指定して、valueで読み込むデータのソースを指定する。 -
DATA_TYPEには、以下のいずれかが指定できる-
TEXT-
valueで指定した値を文字列として扱い、バイナリにエンコードした値を読み込む -
[TEXT UTF-8]のようにして、エンコードするときの文字コードを指定できる - 未指定の場合は、デフォルトで
UTF-8でエンコードされる
-
-
BASE64-
valueで指定した値を、 Base64 でエンコードされた文字列として読み込む
-
-
FILE-
valueで指定した値をファイルのパスとして扱い、ファイルの内容を読み込む
-
-
URL-
valueで指定した値を URL として扱い、 URL から読み取った内容をバイナリとして読み込む -
http://~のような URL を指定すれば、インターネット経由でファイルを読み込むようなことも可能
-
-
日付型
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>date_value</column>
<column>time_value</column>
<column>timestamp_value</column>
<row>
<value>1</value>
<value>2022-7-12</value>
<value>12:13:14</value>
<value>2022-08-01 12:30:42.123</value>
</row>
</table>
</dataset>
package sandbox.dbunit;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.sql.Date;
import java.sql.Time;
import java.sql.Timestamp;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class DateTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
date_value date,
time_value time,
timestamp_value timestamp
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/DateTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUpDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void test() throws Exception {
ITable testTable = myDbUnitExtension
.getConnection().createDataSet().getTable("test_table");
Date dateValue = (Date) testTable.getValue(0, "date_value");
Time timeValue = (Time) testTable.getValue(0, "time_value");
Timestamp timestampValue = (Timestamp) testTable.getValue(0, "timestamp_value");
// 以下のテストは全て成功する
assertEquals(dateValue, Date.valueOf("2022-07-12"));
assertEquals(timeValue, Time.valueOf("12:13:14"));
assertEquals(timestampValue, Timestamp.valueOf("2022-08-01 12:30:42.123"));
}
}
- DATE 型、 TIME 型、 TIMESTAMP 型の項目は、それぞれ java.sql.Date#valueOf(String), java.sql.Time#valueOf(String), java.sql.Timestamp#valueOf(String) でパースされて読み込まれる
- したがって、書式はそれぞれのメソッドの仕様に準拠する
-
DATE型ならyyyy-[m]m-[d]d -
TIME型ならhh:mm:ss -
TIMESTAMP型ならyyyy-[m]m-[d]d hh:mm:ss[.f...]
-
現在時刻からの相対時間を設定する
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>now</column>
<column>date_value</column>
<column>time_value</column>
<column>timestamp_value</column>
<row>
<value>1</value>
<value>[now]</value>
<value>[now+2d]</value>
<value>[now-3h+20m]</value>
<value>[now+2y+1M 10:00]</value>
</row>
</table>
</dataset>
package sandbox.dbunit;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
public class RelativeDateTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
now timestamp,
date_value date,
time_value time,
timestamp_value timestamp
)""");
}
@BeforeEach
void beforeEach() throws Exception {
XmlDataSet setUpDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/RelativeDateTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUpDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void test() throws Exception {
ITable testTable = myDbUnitExtension
.getConnection().createDataSet().getTable("test_table");
System.out.println("[now] = " + testTable.getValue(0, "now"));
System.out.println("[now+2d] = " + testTable.getValue(0, "date_value"));
System.out.println("[now-3h+20m] = " + testTable.getValue(0, "time_value"));
System.out.println("[now+2y+1M 10:00] = " + testTable.getValue(0, "timestamp_value"));
}
}
[now] = 2022-07-05 22:31:49.514
[now+2d] = 2022-07-07
[now-3h+20m] = 19:51:49
[now+2y+1M 10:00] = 2024-08-05 10:00:00.0
- 日時系の型には、現在日時からの相対的な時間を設定するための特別な構文が用意されている
[now{DIFF}{TIME}]
-
DIFFには、現在日時からの差分を指定する- 差分は
+1y,-2dのように、+,-の後に時間量を続けることで記述する - 時間量は
1y,10mのように、量と単位をつなげて記述する - 時間量の単位には、以下のいずれかが使用できる
-
y: 年 -
M: 月 -
d: 日 -
h: 時 -
m: 分 -
s: 秒
-
- 差分は
+1d-2m+3sのように連続して記述することができる
- 差分は
-
TIMEを指定した場合は、時分秒が指定された値に置き換わる- java.time.LocalTime#parse(String) でパースされるので、この書式に合わせて記述する
データセット
データセットを定義するための様々なファイルの書き方についてまとめる。
FlatXmlDataSet
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<foo_table id="1" value="hoge" />
<bar_table id="1" foo_id="1" />
<foo_table id="2" />
<bar_table id="2" foo_id="2" />
<foo_table id="3" value="piyo" />
</dataset>
package sandbox.dbunit;
import org.dbunit.dataset.xml.FlatXmlDataSet;
import org.dbunit.dataset.xml.FlatXmlDataSetBuilder;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.net.URL;
public class FlatXmlDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
value varchar(32)
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
foo_id integer,
foreign key (foo_id) references foo_table (id)
)""");
}
@Test
void testStandard() throws Exception {
FlatXmlDataSetBuilder builder = new FlatXmlDataSetBuilder();
URL xml = this.getClass()
.getResource("/sandbox/dbunit/FlatXmlDataSetTest/testStandard.xml");
FlatXmlDataSet dataSet = builder.build(xml);
myDbUnitExtension.getDatabaseTester().setDataSet(dataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
}
foo_table {
ID=1, VALUE='hoge'
ID=2, VALUE=null
ID=3, VALUE='piyo'
}
bar_table {
ID=1, FOO_ID=1
ID=2, FOO_ID=2
}
-
FlatXmlDataSetでは、 XML でデータセットを記述する- トップレベルに書くタグが、テーブルの1レコードに対応する
- タグ名がテーブル名となる
- カラムの値は、タグの属性に書く
- 属性を省略した場合、そのカラムには
nullが設定される - データは、 XML ファイル内の上から順番に登録される
-
FlatXmlDataSetのインスタンスは、FlatXmlDataSetBuilderを使って生成する
1レコード目にnull値を設定する場合の注意
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<foo_table id="1" />
<foo_table id="2" value="fuga" />
<foo_table id="3" value="piyo" />
</dataset>
foo_table {
ID=1, VALUE=null
ID=2, VALUE=null
ID=3, VALUE=null
}
- FlatXmlDataSet では、1行目のレコードが持つカラムでテーブルの定義が決まる
- このため、1行目で
valueを省略してnullにすると、foo_tableにはidカラムしか存在しない扱いになり、残りのレコードではvalue属性が無視されてしまう - この問題は、以下のいずれかの方法で回避できる
- DTD を定義する
-
columnSensingにtrueを設定する
- 後者の方法を以下で説明する
@Test
void testColumnSensingTrue() throws Exception {
FlatXmlDataSetBuilder builder = new FlatXmlDataSetBuilder();
builder.setColumnSensing(true); // true を設定
URL xml = this.getClass()
.getResource("/sandbox/dbunit/FlatXmlDataSetTest/testFirstRecordHasNull.xml");
FlatXmlDataSet dataSet = builder.build(xml);
myDbUnitExtension.getDatabaseTester().setDataSet(dataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("foo_table");
}
foo_table {
ID=1, VALUE=null
ID=2, VALUE='fuga'
ID=3, VALUE='piyo'
}
-
FlatXmlDataSetBuilderのsetColumnSensing()でtrueを設定すると、レコードをすべて読み込んだうえでカラム定義が決まるため、1レコード目にnull値を設定していても残りのレコードが無視されることはなくなる
XmlDataSet
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value1</column>
<column>value2</column>
<row>
<value>1</value>
<value>hoge</value>
</row>
<row>
<value>2</value>
<value>foo</value>
<value>bar</value>
</row>
<row>
<value>3</value>
<null />
<value>fuga</value>
</row>
</table>
<table name="bar_table">
<column>id</column>
<column>foo_id</column>
<row>
<value>1</value>
<value>1</value>
</row>
<row>
<value>2</value>
<value>2</value>
</row>
</table>
</dataset>
package sandbox.dbunit;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.io.InputStream;
public class XmlDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
value1 varchar(8),
value2 varchar(8)
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
foo_id integer,
foreign key (foo_id) references foo_table (id)
)""");
}
@Test
void test() throws Exception {
try (
InputStream inputStream = this.getClass()
.getResourceAsStream("/sandbox/dbunit/XmlDataSetTest/test.xml");
) {
XmlDataSet xmlDataSet = new XmlDataSet(inputStream);
myDbUnitExtension.getDatabaseTester().setDataSet(xmlDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
}
foo_table {
ID=1, VALUE1='hoge', VALUE2=null
ID=2, VALUE1='foo', VALUE2='bar'
ID=3, VALUE1=null, VALUE2='fuga'
}
bar_table {
ID=1, FOO_ID=1
ID=2, FOO_ID=2
}
- XmlDataSet では、 XML でデータセットを定義する
-
FlatXmlDataSetと違って、より汎用的なフォーマットとなっている -
<table>タグで、テーブルごとのデータを定義する-
name属性でテーブルの名前を設定する -
<table>タグ内の先頭で、<column>タグを使って存在するカラムと順番を定義する
-
-
<row>タグで、1レコードずつデータを定義する-
<value>タグで、各カラムの値を設定する -
<value>に指定した値は、<column>で定義した順序でカラムに設定される -
<column>で定義したカラム数に対して<value>の数が不足している場合は、足りないカラムにはnullが設定される - 明示的に
nullを設定する場合は、<null />タグを設定する
-
- データは、 XML ファイル内の上から順番に登録される
XlsDataSet
dependencies {
...
testRuntimeOnly "org.apache.poi:poi-ooxml:4.1.0" // 追加
}
test.xlsx
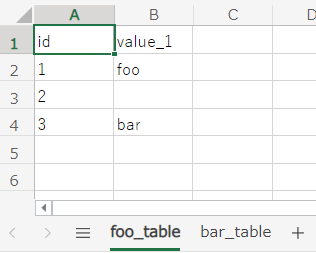
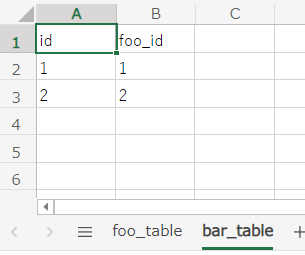
package sandbox.dbunit;
import org.dbunit.dataset.excel.XlsDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.io.InputStream;
public class XlsDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
value_1 varchar(8),
value_2 varchar(8)
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
foo_id integer,
foreign key (foo_id) references foo_table (id)
)""");
}
@Test
void test() throws Exception {
try (
InputStream inputStream = this.getClass()
.getResourceAsStream("/sandbox/dbunit/XlsDataSetTest/test.xlsx");
) {
XlsDataSet xlsDataSet = new XlsDataSet(inputStream);
myDbUnitExtension.getDatabaseTester().setDataSet(xlsDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
}
foo_table {
ID=1, VALUE_1='foo', VALUE_2=null
ID=2, VALUE_1=null, VALUE_2=null
ID=3, VALUE_1='bar', VALUE_2=null
}
bar_table {
ID=1, FOO_ID=1
ID=2, FOO_ID=2
}
- XlsDataSet では、 Excel でデータセットを定義する
-
XlsDataSetを使う場合は、依存関係に Apache POI を追加する必要がある-
*.xls形式を使う場合はorg.apache.poi:poiを追加する -
*.xlsx形式を使う場合はorg.apache.poi:poi-ooxmlを追加する - どのバージョンを入れるのが良いかドキュメントには見当たらなかったのでソースを確認したら
4.1.0を使ってた
-
- 1つのシートに1つのテーブルのデータを設定する
- シート名がテーブル名となる
- シートの1行目は、カラム名を設定する
- 2行目以降にデータを記述する
- 書式による自動変換による事故を避けるため、全セル文字列形式にしておいたほうがいい気がする(個人的意見)
- 空セルは
nullになる- 昔のブログとかを見ると空セルは空文字になるってあるけど、挙動変わった?
- 逆に空文字を設定するために
ReplacementDataSetを使うことになるのかも(後述)
- Excel に定義しなかったカラムには
nullが設定される - データは、左のシートから順番に登録される
空セルを空文字として設定する
昔は空セルが空文字として登録されてしまうため、 ReplacementDataSet というのを使って null に置き換えたりする必要があったっぽい。
しかし、現在は上述のように空セルは null になる。
ということは、逆に空セルを空文字として登録したい場合は、 ReplacementDataSet を使うことになる(少なくとも、ドキュメントには空文字を明示的に設定する方法とかは言及されてない)。
@Test
void testWithReplacementDataSet() throws Exception {
myDbUnitExtension.getDatabaseTester()
.setOperationListener(new DefaultOperationListener() {
@Override
public void connectionRetrieved(IDatabaseConnection connection) {
super.connectionRetrieved(connection);
DatabaseConfig config = connection.getConfig();
config.setProperty(DatabaseConfig.FEATURE_ALLOW_EMPTY_FIELDS, true);
}
});
try (
InputStream inputStream = this.getClass()
.getResourceAsStream("/sandbox/dbunit/XlsDataSetTest/test.xlsx");
) {
XlsDataSet xlsDataSet = new XlsDataSet(inputStream);
ReplacementDataSet replacementDataSet = new ReplacementDataSet(xlsDataSet);
replacementDataSet.addReplacementObject(null, "");
myDbUnitExtension.getDatabaseTester().setDataSet(replacementDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
myDbUnitExtension.printTable("foo_table");
}
foo_table {
ID=1, VALUE_1='foo', VALUE_2=null
ID=2, VALUE_1='', VALUE_2=null
ID=3, VALUE_1='bar', VALUE_2=null
}
-
ReplacementDataSetを使うと、データセット内の特定の値を別の値に差し替えることができる -
addReplacementObject(Object, Object)で、差し替えの内容を登録する- 第一引数が変更前の値
- 第二引数が変更後の値
- そのままだと、
table.column=foo_table.VALUE_1 value is empty but must contain a value (to disable this feature check, set DatabaseConfig.FEATURE_ALLOW_EMPTY_FIELDS to true)というエラーが発生して、空文字での投入はできなかった - エラーメッセージに従い、 FEATURE_ALLOW_EMPTY_FIELDS に
trueを設定するようにしたら、空文字で登録ができた-
DatabaseConfigの設定方法の詳細については後述
-
CsvDataSet / CsvURLDataSet
`-src/test/
|-java/
| `-sandbox/dbunit/CsvURLDataSetTest.java
`-resources/
`-sandbox/dbunit/CsvURLDataSetTest/
|-foo_table.csv
|-bar_table.csv
`-table-ordering.txt
id,value_1
1,hoge
"2","\"hello,world\""
3,
4,""
5,null
6,"null"
7,'null'
id,foo_id
1, 1
2 ,2
3 ," 3 "
foo_table
bar_table
package sandbox.dbunit;
import org.dbunit.DefaultOperationListener;
import org.dbunit.database.DatabaseConfig;
import org.dbunit.database.IDatabaseConnection;
import org.dbunit.dataset.csv.CsvURLDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.net.URL;
public class CsvURLDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
value_1 varchar(32),
value_2 varchar(32)
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
foo_id integer,
foreign key (foo_id) references foo_table (id)
)""");
}
@Test
void test() throws Exception {
myDbUnitExtension.getDatabaseTester()
.setOperationListener(new DefaultOperationListener() {
@Override
public void connectionRetrieved(IDatabaseConnection connection) {
super.connectionRetrieved(connection);
final DatabaseConfig config = connection.getConfig();
config.setProperty(DatabaseConfig.FEATURE_ALLOW_EMPTY_FIELDS, true);
}
});
URL base = this.getClass().getResource("/sandbox/dbunit/CsvURLDataSetTest/");
CsvURLDataSet csvURLDataSet = new CsvURLDataSet(base);
myDbUnitExtension.getDatabaseTester().setDataSet(csvURLDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
}
foo_table {
ID=1, VALUE_1='hoge', VALUE_2=null
ID=2, VALUE_1='"hello,world"', VALUE_2=null
ID=3, VALUE_1='', VALUE_2=null
ID=4, VALUE_1='', VALUE_2=null
ID=5, VALUE_1=null, VALUE_2=null
ID=6, VALUE_1=null, VALUE_2=null
ID=7, VALUE_1=''null'', VALUE_2=null
}
bar_table {
ID=1, FOO_ID=1
ID=2, FOO_ID=2
ID=3, FOO_ID=3
}
-
CsvDataSet または CsvURLDataSet では、 CSV でデータセットを定義する
-
CsvDataSetは、ベースディレクトリをFileで指定する -
CsvURLDataSetは、ベースディレクトリをURLで指定する- 末尾の
/を忘れるとディレクトリ扱いされないので注意
- 末尾の
-
- それぞれのクラスのコンストラクタには、データセットを定義したファイルを配置しているディレクトリ(仮にベースディレクトリと呼称)を指定する
- ベースディレクトリには、以下のファイルを配置する
- テーブルごとにデータを定義した CSV ファイル
- ファイル名はテーブル名と一致させる
- 投入するテーブル名を列挙したファイル
- ファイル名は
table-ordering.txt固定 - このファイルに記載されている順序でデータが投入される
- ファイル名は
- テーブルごとにデータを定義した CSV ファイル
- 各テーブルごとの CSV ファイルは、以下の書式で記述する
- 基本ルール
- カラムの区切り文字はカンマ(
,) - 囲い文字はダブルクォーテーション(
")- 囲い文字は、あってもなくてもいい
- 囲い文字の中でダブルクォーテーションを記述したい場合は、バックスラッシュでエスケープする(
\")
- カラムの区切り文字はカンマ(
- 1行目にはカラム名を記載する
- ここで定義されていないカラムには
nullが設定される
- ここで定義されていないカラムには
- 2行目以降に、テーブルに投入するデータを記載する
- 空文字は、そのまま空文字として扱われる
- 設定で
FEATURE_ALLOW_EMPTY_FIELDSをtrueにしておかないとエラーになるので注意
- 設定で
-
nullまたは"null"と記述すると、null値として扱われる- 基本的に需要はないと思うけど、
nullという文字列を設定したい場合はXlsDataSetのときみたいにReplacementDataSetを使って何とかすることになると思う
- 基本的に需要はないと思うけど、
-
ドキュメントでは、カンマ区切り文字の前にある数値項目の末尾に空白スペースを入れたら文字列扱いされてしまうからするな、って書いてある
-
Numeric CSV data file fields must not have trailing spaces before the comma-separator as will interpret it as a String instead of a number.
- しかし、実際にやってみると普通に数値として登録できているのでドキュメントが間違ってるっぽい
-
- 空文字は、そのまま空文字として扱われる
- 基本ルール
StreamingDataSet
XmlDataSet などの他のデータセットは、すべてのデータをメモリ上に読み込むようになっている。
データのサイズが小さければ問題ないが、大きくなってくると OOME などの問題が発生する可能性がある。
StreamingDataSet を使用すると、使用する分だけデータを順次メモリ上に読み込むようになるので、この問題を回避できるようになる。
以下、 StreamingDataSet を使う場合とそうでない場合とで、メモリの使用量がどう変わるかを検証する。
StreamingDataSet の検証ではメモリ使用量を確認しているため、ここだけ DB にはオンメモリの HSQLDB は使わずに PostgreSQL (14.4)を使用している。
JDBC ドライバの依存は以下。
dependencies {
...
testRuntimeOnly "org.postgresql:postgresql:42.4.0"
}
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<test_table id="1" value="aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" />
<test_table id="2" value="aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" />
<test_table id="3" value="aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" />
以下、同様のレコードが 50 万行続く...
</dataset>
- 巨大なデータセットファイル
- ファイルサイズは、約 500 MB
test {
...
minHeapSize = "768m"
maxHeapSize = "768m"
}
- テスト時のヒープメモリのサイズを 768MB に設定
- XML のテストデータを全部読み込んでもちょっと余るくらいにしている
- 2GB とか余裕ありすぎなサイズにすると、全然 GC が発生せず
StreamingDataSetを使っているときと使っていないときでメモリ消費に差が出なくなる3ので、これくらいのサイズにしている
package sandbox.dbunit;
import org.dbunit.DefaultOperationListener;
import org.dbunit.database.IDatabaseConnection;
import org.dbunit.dataset.xml.FlatXmlDataSet;
import org.dbunit.dataset.xml.FlatXmlDataSetBuilder;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.net.URL;
public class StreamingDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("drop table if exists test_table");
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
value varchar(1024)
)""");
}
@Test
void testNoStreaming() throws Exception {
myDbUnitExtension.getDatabaseTester()
.setOperationListener(new DefaultOperationListener() {
@Override
public void connectionRetrieved(IDatabaseConnection connection) {
super.connectionRetrieved(connection);
connection.getConfig()
.setProperty(DatabaseConfig.FEATURE_BATCHED_STATEMENTS, true);
}
});
FlatXmlDataSetBuilder builder = new FlatXmlDataSetBuilder();
URL url =
this.getClass().getResource("/sandbox/dbunit/StreamingDataSetTest/setUp.xml");
FlatXmlDataSet dataSet = builder.build(url);
myDbUnitExtension.getDatabaseTester().setDataSet(dataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
}
- まずは、
StreamingDataSetを使わずにFlatXmlDataSetで読み込んだ場合のメモリ消費の様子を確認 - 実装の細かい説明は後述
FlatXmlDataSet で読み込んだ場合のメモリ使用量推移
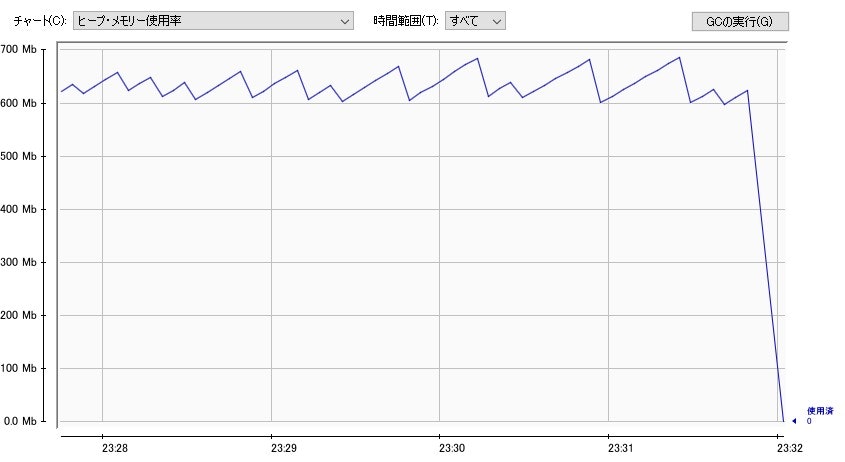
- 約 600MB 以上消費された状態が続いている
- XML のファイルサイズは約 500MB なので、 XML の内容がずっとメモリ上に確保され続けていることが分かる
次に、 StreamingDataSet を使って読み込んでみる。
import org.dbunit.dataset.stream.StreamingDataSet;
import org.dbunit.dataset.xml.FlatXmlDataSetBuilder;
import org.dbunit.dataset.xml.FlatXmlProducer;
import org.dbunit.operation.DatabaseOperation;
import org.xml.sax.InputSource;
...
public class StreamingDataSetTest {
...
@Test
void testStreaming() throws Exception {
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.INSERT);
myDbUnitExtension.getDatabaseTester()
.setOperationListener(new DefaultOperationListener() {
@Override
public void connectionRetrieved(IDatabaseConnection connection) {
super.connectionRetrieved(connection);
connection.getConfig()
.setProperty(DatabaseConfig.FEATURE_BATCHED_STATEMENTS, true);
}
});
URL url =
this.getClass().getResource("/sandbox/dbunit/StreamingDataSetTest/setUp.xml");
FlatXmlProducer producer = new FlatXmlProducer(new InputSource(url.toString()));
StreamingDataSet dataSet = new StreamingDataSet(producer);
myDbUnitExtension.getDatabaseTester().setDataSet(dataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
}
StreamingDataSet で読み込んだ場合のメモリ使用量推移
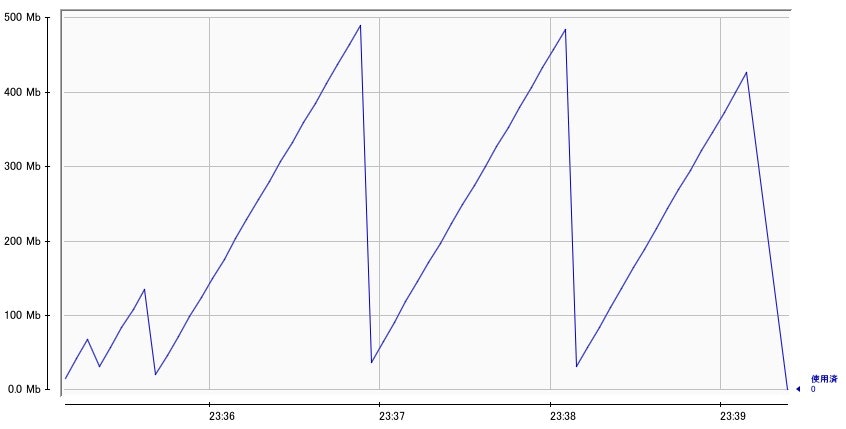
- 500MB くらいまで行くたびに一気にメモリが解放されているのが分かる
- XML のデータは順次読み込まれているだけで、全部が一気にメモリ上に読み込まれているわけではないことが分かる
実装の説明
connection.getConfig().setProperty(DatabaseConfig.FEATURE_BATCHED_STATEMENTS, true);
- デフォルトでは、データの登録に JDBC のバッチ更新は使用されない
-
FEATURE_BATCHED_STATEMENTS に
trueを設定すると、バッチ更新が有効になる - デフォルトが
falseの理由は、 DB 製品によってはバッチ更新をサポートしていない可能性があるため - しかし、 DBUnit としてはサポートされているなら
trueを設定することを推奨している- ただし、データセットのサイズがそれほど大きくない場合は、あまり影響はないとも言っている
-
FEATURE_BATCHED_STATEMENTS に
- バッチ更新が使用される場合、デフォルトは 100 件ごとに
executeBatch()が実行される- この間隔は、 PROPERTY_BATCH_SIZE で変更できる
URL url =
this.getClass().getResource("/sandbox/dbunit/StreamingDataSetTest/setUp.xml");
FlatXmlProducer producer = new FlatXmlProducer(new InputSource(url.toString()));
StreamingDataSet dataSet = new StreamingDataSet(producer);
myDbUnitExtension.getDatabaseTester().setDataSet(dataSet);
-
StreamingDataSetで順次データを読み込むには、IDataSetProducerを実装したクラスを使用してデータセットを読み込む必要がある - ここでは、
FlatXmlDataSet用のIDataSetProducer実装であるFlatXmlProducerを使用している- 他の実装については IDataSetProducer の Javadoc を参照
myDbUnitExtension.getDatabaseTester().setSetUpOperation(DatabaseOperation.INSERT);
- セットアップ時の処理を、デフォルトの
CLEAN_INSERTからINSERTに変更している -
IDatabaseTester.onSetup()でStreamingDataSetを使ってデータを読み込む場合は、こうしないと以下のエラーになるjava.lang.UnsupportedOperationException: Only one iterator allowed!
-
StreamingDataSetは、その性質上データセットファイルを一度しかイテレーションできず、もう一度読み込もうとすると上述のエラーが発生する - セットアップ時のデフォルトである
CLEAN_INSERTは、CLEAN(DELETE)とINSERTでそれぞれ1回ずつsetDataSet()で設定したデータセットを読み込もうとする - したがって、デフォルトの
CLEAN_INSERTのままだとエラーが発生してしまう - このため、
onSetup()でStreamingDataSetを使ってデータセットを読み込みたい場合は、INSERTを設定しておく必要がある
CompositeDataSet
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>hello</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="bar_table">
<column>id</column>
<column>foo_id</column>
<row>
<value>1</value>
<value>1</value>
</row>
</table>
<table name="foo_table">
<column>id</column>
<column>value</column>
<row>
<value>2</value>
<value>world</value>
</row>
</table>
</dataset>
package sandbox.dbunit;
import org.dbunit.dataset.CompositeDataSet;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
public class CompositeDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
myDbUnitExtension.sql("""
create table foo_table (
id integer primary key,
value varchar(8)
)""");
myDbUnitExtension.sql("""
create table bar_table (
id integer primary key,
foo_id integer,
foreign key (foo_id) references foo_table (id)
)""");
}
@Test
void test() throws Exception {
XmlDataSet dataSet1 = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/CompositeDataSetTest/dataSet1.xml");
XmlDataSet dataSet2 = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/CompositeDataSetTest/dataSet2.xml");
CompositeDataSet compositeDataSet = new CompositeDataSet(dataSet1, dataSet2);
myDbUnitExtension.getDatabaseTester().setDataSet(compositeDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("foo_table");
myDbUnitExtension.printTable("bar_table");
}
}
foo_table {
ID=1, VALUE='hello'
ID=2, VALUE='world'
}
bar_table {
ID=1, FOO_ID=1
}
-
CompositeDataSet を使うと、複数の
IDataSetを1つにまとめることができる - 同じテーブルが複数のデータセットに存在する場合は、1つにマージされる
- データの登録順序は、データセットを前から読んでいって現れた順番になる
FilteredDataSet
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="fuga_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>FUGA</value>
</row>
</table>
<table name="piyo_table">
<column>id</column>
<column>hoge_id</column>
<row>
<value>1</value>
<value>1</value>
</row>
</table>
<table name="hoge_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>HOGE</value>
</row>
</table>
</dataset>
package sandbox.dbunit;
import org.dbunit.dataset.FilteredDataSet;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
public class FilteredDataSetTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table hoge_table (
id integer primary key,
value varchar(32)
)""");
myDbUnitExtension.sql("""
create table fuga_table (
id integer primary key,
value varchar(32)
)""");
myDbUnitExtension.sql("""
create table piyo_table (
id integer primary key,
hoge_id integer,
foreign key (hoge_id) references hoge_table (id)
)""");
}
@Test
void test() throws Exception {
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/FilteredDataSetTest/testStandard.xml");
FilteredDataSet filteredDataSet =
new FilteredDataSet(new String[]{"hoge_table", "piyo_table"}, xmlDataSet);
myDbUnitExtension.getDatabaseTester().setDataSet(filteredDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("hoge_table");
myDbUnitExtension.printTable("fuga_table");
myDbUnitExtension.printTable("piyo_table");
}
}
hoge_table {
ID=1, VALUE='HOGE'
}
fuga_table {
}
piyo_table {
ID=1, HOGE_ID=1
}
-
FilteredDataSetを使用すると、既存のデータセットから指定したテーブルだけを抽出した新しいデータセットを作成できる - 抽出するテーブルは、
FilteredDataSetのコンストラクタの第一引数でString配列を使って指定する - テーブルは、この
String配列で指定された順番で抽出される(元のデータセット上の順番は無視される)
順番は元のデータセットのままにして抽出する
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="hoge_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>HOGE</value>
</row>
</table>
<table name="fuga_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>FUGA</value>
</row>
</table>
<table name="piyo_table">
<column>id</column>
<column>hoge_id</column>
<row>
<value>1</value>
<value>1</value>
</row>
</table>
</dataset>
@Test
void testIncludeFilter() throws Exception {
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/FilteredDataSetTest/testIncludeFilter.xml");
IncludeTableFilter filter =
new IncludeTableFilter(new String[]{"piyo_table", "hoge_table"});
FilteredDataSet filteredDataSet = new FilteredDataSet(filter, xmlDataSet);
myDbUnitExtension.getDatabaseTester().setDataSet(filteredDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("hoge_table");
myDbUnitExtension.printTable("fuga_table");
myDbUnitExtension.printTable("piyo_table");
}
hoge_table {
ID=1, VALUE='HOGE'
}
fuga_table {
}
piyo_table {
ID=1, HOGE_ID=1
}
-
FilteredDataSetのコンストラクタの第一引数には、テーブルのフィルタ方法を定義したITableFilterを指定することもできる -
IncludeTableFilterを使用すると、テーブルを読み込む順序は元のデータセットのままにして、テーブル名だけで対象を絞り込むことができる
指定したテーブルを除外する
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="hoge_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>HOGE</value>
</row>
</table>
<table name="fuga_table">
<column>id</column>
<column>value</column>
<row>
<value>1</value>
<value>FUGA</value>
</row>
</table>
<table name="piyo_table">
<column>id</column>
<column>hoge_id</column>
<row>
<value>1</value>
<value>1</value>
</row>
</table>
</dataset>
@Test
void testExcludeFilter() throws Exception {
XmlDataSet xmlDataSet = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/FilteredDataSetTest/testExcludeFilter.xml");
ExcludeTableFilter filter =
new ExcludeTableFilter(new String[]{"piyo_table", "hoge_table"});
FilteredDataSet filteredDataSet = new FilteredDataSet(filter, xmlDataSet);
myDbUnitExtension.getDatabaseTester().setDataSet(filteredDataSet);
myDbUnitExtension.getDatabaseTester().onSetup();
myDbUnitExtension.printTable("hoge_table");
myDbUnitExtension.printTable("fuga_table");
myDbUnitExtension.printTable("piyo_table");
}
hoge_table {
}
fuga_table {
ID=1, VALUE='FUGA'
}
piyo_table {
}
-
ExcludeTableFilterを使用すると、指定したテーブルを除外できる
パターン指定
IncludeTableFilter と ExcludeTableFilter は、テーブル名をパターンで指定することができる。
@Test
void testPattern() throws Exception {
IncludeTableFilter filterWithAsterisk =
new IncludeTableFilter(new String[]{"*d"});
assertFalse(filterWithAsterisk.accept("first"));
assertTrue(filterWithAsterisk.accept("second"));
assertTrue(filterWithAsterisk.accept("third"));
assertFalse(filterWithAsterisk.accept("forth"));
assertFalse(filterWithAsterisk.accept("fifth"));
IncludeTableFilter filterWithQuestion =
new IncludeTableFilter(new String[]{"f????"});
assertTrue(filterWithQuestion.accept("first"));
assertFalse(filterWithQuestion.accept("second"));
assertFalse(filterWithQuestion.accept("third"));
assertTrue(filterWithQuestion.accept("forth"));
assertTrue(filterWithQuestion.accept("fifth"));
IncludeTableFilter filterWithPatterns =
new IncludeTableFilter(new String[]{"s*", "*th"});
assertFalse(filterWithPatterns.accept("first"));
assertTrue(filterWithPatterns.accept("second"));
assertFalse(filterWithPatterns.accept("third"));
assertTrue(filterWithPatterns.accept("forth"));
assertTrue(filterWithPatterns.accept("fifth"));
}
-
*は、 0 文字以上の任意の文字列にマッチする -
?は、任意の1文字にマッチする
ValueComparer
dependencies {
..
testRuntimeOnly "junit:junit:4.13.2"
}
-
IsActualWithinToleranceOfExpectedTimestampValueComparerというクラスがなぜか JUnit 4 以下の API に依存してしまっているので、使用するなら依存を追加しなければならない
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<column>timestamp_value</column>
<row>
<value>1</value>
<value>hoge</value>
<value>10</value>
<value>2022-07-09 11:12:13.123</value>
</row>
</table>
</dataset>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<column>timestamp_value</column>
<row>
<value>1</value>
<value>hoge</value>
<value>9</value>
<value>2022-07-09 11:12:13.000</value>
</row>
</table>
</dataset>
- 投入データと期待値は完全には一致していない
package sandbox.dbunit;
import org.dbunit.assertion.comparer.value.ValueComparer;
import org.dbunit.assertion.comparer.value.ValueComparers;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.xml.XmlDataSet;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.util.Map;
import static org.dbunit.Assertion.assertWithValueComparer;
public class ValueComparerTest {
@RegisterExtension
static MyDbUnitExtension myDbUnitExtension = new MyDbUnitExtension();
@BeforeAll
static void beforeAll() {
// DB初期化(テーブル作成)
myDbUnitExtension.sql("""
create table test_table (
id integer primary key,
text varchar(32),
numeric integer,
timestamp_value timestamp
)""");
}
@BeforeEach
void setUp() throws Exception {
XmlDataSet setUp = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/ValueComparerTest/setUp.xml");
myDbUnitExtension.getDatabaseTester().setDataSet(setUp);
myDbUnitExtension.getDatabaseTester().onSetup();
}
@Test
void test() throws Exception {
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/ValueComparerTest/expected.xml");
ITable expectedTable = expected.getTable("test_table");
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
ITable actualTable = actual.getTable("test_table");
Map<String, ValueComparer> comparers = Map.of(
"numeric", ValueComparers.isActualGreaterThanExpected,
"timestamp_value", ValueComparers.isActualWithinOneSecondNewerOfExpectedTimestamp
);
ValueComparer defaultComparer = ValueComparers.isActualEqualToExpected;
// テストは成功する
assertWithValueComparer(expectedTable, actualTable, defaultComparer, comparers);
}
}
-
assertWithValueComparer(ITable, ITable, ValueComparer, Map<String, ValueComparer>)を使用すると、ValueComparerを使った検証ができる -
ValueComparerを使うと、カラムごとに完全一致以外の検証が可能になる- 「期待値より大きい(小さい)」
- 「期待値の時刻との差が1秒以内」
- etc...
-
assertWithValueComparer()の第三引数には、デフォルトで使用するValueComparerを指定する- ここでは、 ValueComparers に定義されている
isActualEqualToExpectedを使用している -
ValueComparersには、よく利用しそうなValueComparerが定数としてあらかじめ定義されている -
isActualEqualToExpectedは、完全に一致するかどうかを比較するValueComparer - 普通に
assertEquals()したときも裏ではこれが使われている
- ここでは、 ValueComparers に定義されている
-
assertWithValueComparer()の第四引数には、カラムごとに使用するValueComparerを定義したMapを指定する- ここでは、
numericカラムに対してisActualGreaterThanExpectedを、
timestamp_valueカラムに対してはisActualWithinOneSecondNewerOfExpectedTimestampを指定している -
isActualGreaterThanExpectedは、期待値よりも実際の値が大きいことを検証する -
isActualWithinOneSecondNewerOfExpectedTimestampは、実際の値の時刻が期待値の時刻より1秒以内の未来の時刻であることを検証する
- ここでは、
ValueComparers で定義されいている定数
isActualEqualToExpected
期待値と実際の値が完全一致することを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
abc |
abc |
Abc |
isActualNotEqualToExpected
期待値と実際の値が一致しないことを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
abc |
Abc |
abc |
isActualContainingExpectedStringValueComparer
実際の値を文字列として扱ったときに、期待値の文字列表現を含んでいることを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
hoge |
og |
Og |
101 |
01 |
11 |
isActualGreaterThanExpected
実際の値が期待値より大きいことを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
10 |
9 |
10 |
isActualGreaterThanOrEqualToExpected
実際の値が期待値以上であることを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
10 |
10 |
11 |
isActualLessThanExpected
実際の値が期待値より小さいことを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
10 |
11 |
10 |
isActualLessOrEqualToThanExpected
実際の値が期待値以下であることを検証する。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
10 |
10 |
9 |
isActualWithinOneSecondNewerOfExpectedTimestamp
実際の値の時刻が、期待値の時刻から1秒以内の未来時刻であることを検証する。
Timestamp 型のカラムにのみ指定可能。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
2022-01-01 00:00:00.123 |
2021-12-31 23:59:59.123 |
2021-12-31 23:59:59.122 |
isActualWithinOneMinuteNewerOfExpectedTimestamp
実際の値の時刻が、期待値の時刻から1分以内の未来時刻であることを検証する。
Timestamp 型のカラムにのみ指定可能。
| 実際の値 | OKとなる期待値の例 | NGとなる期待値の例 |
|---|---|---|
2022-01-01 00:00:00.123 |
2021-12-31 23:59:00.123 |
2021-12-31 23:59:00.122 |
isActualEqualToExpectedTimestampWithIgnoreMillis
isActualWithinOneSecondNewerOfExpectedTimestamp と同じ。
ValueComparer には isActualWithinOneMinuteOlderOfExpectedTimestamp, isActualWithinOneSecondOlderOfExpectedTimestamp という、1秒(分)以内の過去時刻であることを検証できそうな定数が用意されている。
しかし 2.7.3 現在、おそらくこれらの定数はバグっている。
public static final ValueComparer isActualWithinOneSecondOlderOfExpectedTimestamp =
new IsActualWithinToleranceOfExpectedTimestampValueComparer(ONE_SECOND_IN_MILLIS, 0);
ValueComparers では、上記のように定数が定義されている。
IsActualWithinToleranceOfExpectedTimestampValueComparer のコンストラクタ引数は、第一引数が許容できる時間の下限で、第二引数が上限を指定するようになっている。
上記の実装では、下限に 1000 (1秒のミリ秒表現)を、上限に 0 を設定していることになる。
下限のほうが大きい値になってしまっており、この結果内部では「0以下かつ1000以上であること」を検証してしまっていて、絶対に検証OKにならない状態になっている。
IsActualWithinToleranceOfExpectedTimestampValueComparer の単体テストを見ても下限>上限となっているケースがないので、おそらくバグ。
ValueComparer を自作する
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE dataset SYSTEM "dataset.dtd">
<dataset>
<table name="test_table">
<column>id</column>
<column>text</column>
<column>numeric</column>
<column>timestamp_value</column>
<row>
<value>1</value>
<value>HOGE</value>
<value>10</value>
<value>2022-07-09 11:12:13.123</value>
</row>
</table>
</dataset>
@Test
void testCustomValueComparer() throws Exception {
XmlDataSet expected = myDbUnitExtension
.readXmlDataSet("/sandbox/dbunit/ValueComparerTest/testCustomValueComparer.xml");
ITable expectedTable = expected.getTable("test_table");
IDataSet actual = myDbUnitExtension.getConnection().createDataSet();
ITable actualTable = actual.getTable("test_table");
Map<String, ValueComparer> comparers = Map.of(
"text", new ValueComparerTemplateBase() {
@Override
protected boolean isExpected(
ITable expectedTable,
ITable actualTable,
int rowNum,
String columnName,
DataType dataType,
Object expectedValue,
Object actualValue
) throws DatabaseUnitException {
if (expectedValue == null || actualValue == null) {
return expectedValue == actualValue;
}
return expectedValue.toString()
.equalsIgnoreCase(actualValue.toString());
}
@Override
protected String getFailPhrase() {
return "not equals ignore case";
}
}
);
ValueComparer defaultComparer = ValueComparers.isActualEqualToExpected;
// テストは成功する
assertWithValueComparer(expectedTable, actualTable, defaultComparer, comparers);
}
-
ValueComparerを実装すれば、任意の比較方法を定義できる- ここでは、大文字・小文字に関係なく文字列が一致していることを検証する
ValueComparerを作成している
- ここでは、大文字・小文字に関係なく文字列が一致していることを検証する
-
ValueComparerTemplateBaseというベースとなるクラスが用意されているので、それを継承して作成すると楽 -
isExpected()とgetFailPhrase()の2つの抽象メソッドを実装する -
isExpected()では、実際に検証を行って結果をbooleanで返却する(OK ならtrue) -
getFailPharse()では、検証 NG となったときに使用するエラーメッセージの一部を返却する-
Actual value='%s' is %s expected value='%s'というメッセージの、真ん中の%sのところに埋め込まれる
-
プロパティ
IDatabaseConnection connection = databaseTester.getConnection();
DatabaseConfig config = connection.getConfig();
config.setProperty(DatabaseConfig.FEATURE_BATCHED_STATEMENTS, true);
- DbUnit の細かい振る舞いを調整するためのクラスとして、 DatabaseConfig というクラスが用意されている
-
DatabaseConfigは、IDatabaseConnectionごとに割り当てられている-
DatabaseConfigのインスタンスは、IDatabaseConnectionの内部で生成されている- 設定済みのインスタンスを外部から渡すわけではない
-
DatabaseConfigのインスタンスは、IDatabaseConnectionのgetConfig()メソッドで取得できる -
getConfig()で取得したDatabaseConfigのsetProperty(String, Object)メソッドを使うことで、そのコネクションにおける設定を調整できる
-
-
setProperty()で指定できるキーは、DatabaseConfigに定数として定義されている- Configurable Features and Properties に、それぞれのキーの説明が書かれている
- 設定には「Feature Flags」と「Properties」の2種類存在している
- 「Feature Flags」は値が
booleanで、「Properties」は値が任意のオブジェクトという差がある -
DatabaseConfigには setFeature(String, boolean) と setProperty(String, Object) の2つのメソッドが存在している -
setProperty()でも「Feature Flags」の設定は可能なので、使うのはsetProperty()だけでいい-
setFeature()は非推奨となっている -
setProperty()で「Feature Flags」を設定できるようになったのは 2.4.6 以降
-
- 「Feature Flags」は値が
onSetup(), onTearDown() で使用される IDatabaseConnection の調整
databaseTester.setOperationListener(new DefaultOperationListener() {
@Override
public void connectionRetrieved(IDatabaseConnection connection) {
super.connectionRetrieved(connection);
DatabaseConfig config = connection.getConfig();
config.setProperty(DatabaseConfig.FEATURE_ALLOW_EMPTY_FIELDS, true);
}
});
...
databaseTester.onSetup();
-
IDatabaseTesterのonSetup()およびonTearDown()で使用されるIDatabaseConnectionは、IDatabaseTesterの内部で生成されていて外部から単純にはアクセスできない- このため、
onSetup(),onTearDown()で使用されるIDatabaseConnectionの設定を調整するにはちょっと特殊な手段が必要になる
- このため、
-
IDatabaseTesterにはsetOperationListener(IOperationListener)というメソッドが用意されており、DatabaseOperationの実行に対するリスナーを登録できるようになっている -
IOperationListenerのconnectionRetrieved(IDatabaseConnection)を実装すれば、DatabaseOperationが実行される前に処理を挟むことができる- 引数に、
DatabaseOperationの実行で使用されるIDatabaseConnectionが渡される - この
IDatabaseConnectionからDatabaseConfigを取得すれば、onSetup()やonTearDown()の調整ができる
- 引数に、
参考
-
どちらのケースも 1GB くらいメモリを使って終わってしまう ↩