Database Rider とは
- DBUnit をもっと使いやすくするライブラリ
- アノテーションで初期データや期待値のデータファイルを指定できる
- YAMLやJSONなど、 DBUnit でサポートされていないデータセットが用意されている
Hello World
実装
フォルダ構成
|-build.gradle
`-src/test/
|-java/
| `-sandbox/dbrider/
| `-HelloDatabaseRiderTest.java
`-resources/
`-sandbox/dbrider/
|-hello.yml
`-hello-expected.yml
build.gradle
plugins {
id "java"
}
sourceCompatibility = 17
targetCompatibility = 17
[compileJava, compileTestJava]*.options*.encoding = "UTF-8"
repositories {
mavenCentral()
}
dependencies {
testImplementation "com.github.database-rider:rider-junit5:1.35.0"
testImplementation "org.junit.jupiter:junit-jupiter:5.9.1"
testRuntimeOnly "org.hsqldb:hsqldb:2.7.1"
}
test {
useJUnitPlatform()
}
HelloDatabaseRiderTest.java
package sandbox.dbrider;
import com.github.database.rider.core.api.connection.ConnectionHolder;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.DBUnitExtension;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
@ExtendWith(DBUnitExtension.class)
public class HelloDatabaseRiderTest {
private static final ConnectionHolder connectionHolder =
() -> DriverManager.getConnection("jdbc:hsqldb:mem:test", "sa", "");
private static Connection connection;
@BeforeAll
static void initDatabase() throws Exception {
connection = connectionHolder.getConnection();
executeUpdate("""
create table test_table (
id integer,
value varchar(32)
)
""");
}
@Test
@DataSet("sandbox/dbrider/hello.yml")
@ExpectedDataSet("sandbox/dbrider/hello-expected.yml")
void hello() throws Exception {
executeUpdate("""
update
test_table
set
value = 'WORLD'
where
id = 2
""");
}
@AfterAll
static void closeConnection() throws Exception {
connection.close();
}
private static void executeUpdate(String sql) throws SQLException {
try (final PreparedStatement ps = connection.prepareStatement(sql);) {
ps.executeUpdate();
}
}
}
hello.yml
test_table:
- id: 1
value: hello
- id: 2
value: world
hello-expected.yml
test_table:
- id: 1
value: hello
- id: 2
value: WORLD
説明
build.gradle
dependencies {
testImplementation "com.github.database-rider:rider-junit5:1.35.0"
testImplementation "org.junit.jupiter:junit-jupiter:5.9.1"
testRuntimeOnly "org.hsqldb:hsqldb:2.7.1"
}
- Database Rider を使い始める場合、通常は com.github.database-rider:rider-core を依存に追加する
- しかし、 Database Rider はもともと JUnit4 の Rule として構築されているので、そのままでは JUnit5 で使用できない
- JUnit5 で使用する場合は、 com.github.database-rider:rider-junit5 を依存に追加する
-
rider-coreは推移的な依存関係の解決で引っ張られてこられるので、ここではrider-junit5だけ指定している
- データベースとして、 HSQLDB を使用している
@ExtendWith(DBUnitExtension.class)
public class HelloDatabaseRiderTest {
- JUnit5 で Database Rider を使う場合は、 JUnit5 の Extension として用意されている
DBUnitExtensionを@ExtendWithに指定する- もしくは
@DBRiderを使うことでも同じ効果が得られる -
@DBRiderは、@ExtendWith(DBUnitExtension.class)と@Testの合成アノテーション
- もしくは
private static final ConnectionHolder connectionHolder =
() -> DriverManager.getConnection("jdbc:hsqldb:mem:test", "sa", "");
-
DBUnitExtensionは、テストクラスにあるConnectionHolder型のフィールドか、ConnectionHolderを返すメソッドからデータベースコネクションを取得する- もしくは、後述する設定ファイルで指定した設定からコネクションを生成する
- ここでは、 static フィールドとして HSQLDB の
Connectionを返すConnectionHolderを定義している
@Test
@DataSet("sandbox/dbrider/hello.yml")
@ExpectedDataSet("sandbox/dbrider/hello-expected.yml")
void hello() throws Exception {
-
@DataSetアノテーションを使うことで、初期セットアップ用のデータファイルを指定できる -
@ExpectedDataSetアノテーションを使うことで、期待値となるデータファイルを指定できる
test_table:
- id: 1
value: hello
- id: 2
value: world
- Database Rider を使うと、 YAML でデータセットを定義できる
- 本家の DBUnit では YAML のデータセットは存在しない
- データ構造は、見てのとおり
検証サポート用の拡張機能
- 以下、検証を楽にするためにDBアクセスの処理をサポートする自作の拡張機能を使用する
package sandbox.dbrider;
import org.junit.jupiter.api.extension.AfterAllCallback;
import org.junit.jupiter.api.extension.BeforeAllCallback;
import org.junit.jupiter.api.extension.ExtensionContext;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
public class DatabaseSupport implements BeforeAllCallback, AfterAllCallback {
private final String url;
private Connection connection;
public DatabaseSupport() {
this("jdbc:hsqldb:mem:test");
}
public DatabaseSupport(String url) {
this.url = url;
}
@Override
public void beforeAll(ExtensionContext context) throws Exception {
connection = DriverManager.getConnection(url, "sa", "");
}
@Override
public void afterAll(ExtensionContext context) throws Exception {
connection.close();
}
public void executeUpdate(String sql) {
try (final PreparedStatement ps = connection.prepareStatement(sql);) {
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public void printTable(String table) {
try (
final PreparedStatement ps =
connection.prepareStatement("select * from " + table);
final ResultSet rs = ps.executeQuery();
) {
final ResultSetMetaData metaData = rs.getMetaData();
while (rs.next()) {
Map<String, Object> record = new HashMap<>();
for (int i=1; i<=metaData.getColumnCount(); i++) {
final String columnName = metaData.getColumnName(i);
Object value = rs.getObject(i);
if (value instanceof String) {
value = "\"" + value + "\"";
}
record.put(columnName, value);
}
System.out.println(record);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public Connection getConnection() {
return connection;
}
}
DB接続定義
- Hello Worldでは
ConnectionHolderを使ってDB接続を定義した - これ以外にも、もうちょっと楽にDB接続を定義する方法が用意されている
アノテーションで定義する
package sandbox.dbrider;
import com.github.database.rider.core.api.configuration.DBUnit;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
@DBUnit(url = "jdbc:hsqldb:mem:test", user = "sa", password = "") // ★
public class DefineConnectionByDBUnitAnnotationTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("""
create table test_table (
id integer,
value varchar(32)
)
""");
}
@Test
@DataSet("sandbox/dbrider/hello.yml")
@ExpectedDataSet("sandbox/dbrider/hello-expected.yml")
void test() {
db.executeUpdate("update test_table set value = 'WORLD' where id = 2");
}
}
-
@DBUnitアノテーションを使うことでDB接続を定義できる- 一応
@DBUnitはメソッドにも設定できる
- 一応
設定ファイルで定義する
フォルダ構成
`-src/test/
|-java/
| `-sandbox/dbrider/
| `-DefineConnectionByDbUnitYamlTest.java
`-resources/
`-dbunit.yml
dbunit.yml
connectionConfig:
url: "jdbc:hsqldb:mem:test"
user: "sa"
password: ""
DefineConnectionByDbUnitYamlTest.java
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class DefineConnectionByDbUnitYamlTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("""
create table test_table (
id integer,
value varchar(32)
)
""");
}
@Test
@DataSet("sandbox/dbrider/hello.yml")
@ExpectedDataSet("sandbox/dbrider/hello-expected.yml")
void test() {
db.executeUpdate("update test_table set value = 'WORLD' where id = 2");
}
}
- クラスパス直下に
dbunit.ymlというファイルを配置し、そこでDB接続情報を定義できる - この設定は全テスト共通の設定となる
-
dbunit.ymlと@DBUnitアノテーションが同時に指定された場合は、@DBUnitの設定が優先される - 以降の実装例は、特に断りを入れない限りこの方法でDB接続を定義している前提で書いている
設定ファイルで指定できる設定について
-
dbunit.ymlで指定できる設定については GitHub トップの README や ドキュメント とかに書かれているが、内容や説明に不足がある - 一番確実なのは、
@DBUnitアノテーションの Javadoc を見ることだと思う- Javadoc 自体は公開されているものが見当たらないので、 ソース を直接見に行く必要があるっぽい
-
dbunit.ymlで設定できる設定値は、大きく次の3つに分かれている- Database Rider の設定
- DBUnit の設定
- データベースコネクションの設定
dbunit.yml
cacheConnection: true
...
alwaysCleanAfter: false
properties:
batchedStatements: false
...
tableType: ["TABLE"]
connectionConfig:
driver: ""
url: ""
user: ""
password: ""
- 上の方のトップレベルに並んでいる設定(
cacheConnectionとか)が Database Rider の設定 -
properties以下が DBUnit の設定- DBUnit の設定についての詳細は、 DBUnit のドキュメント を参照するといい
- Feature Flags と Properties の説明とかについては こちら を参照
-
connectionConfigがデータベースコネクションの設定
比較方法
色々なパターンを試して、期待値(@ExpectedDataSet)に設定したデータがどのように比較されるのかを確認する。
以下のようなテストクラスで検証する。
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CompareTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/CompareTest/期待値の方がテーブル数が少ない/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/期待値の方がテーブル数が少ない/expected.yml")
void 期待値の方がテーブル数が少ない() {}
@Test
@DataSet("sandbox/dbrider/CompareTest/期待値の方がテーブル数が多い/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/期待値の方がテーブル数が多い/expected.yml")
void 期待値の方がテーブル数が多い() {}
@Test
@DataSet("sandbox/dbrider/CompareTest/期待値の方がレコード数が少ない/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/期待値の方がレコード数が少ない/expected.yml")
void 期待値の方がレコード数が少ない() {}
@Test
@DataSet("sandbox/dbrider/CompareTest/期待値の方がレコード数が多い/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/期待値の方がレコード数が多い/expected.yml")
void 期待値の方がレコード数が多い() {}
@Test
@DataSet("sandbox/dbrider/CompareTest/期待値の方がカラム数が少ない/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/期待値の方がカラム数が少ない/expected.yml")
void 期待値の方がカラム数が少ない() {}
@Test
@DataSet("sandbox/dbrider/CompareTest/期待値の方がカラム数が多い/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/期待値の方がカラム数が多い/expected.yml")
void 期待値の方がカラム数が多い() {}
@Test
@DataSet("sandbox/dbrider/CompareTest/レコードの順序が異なる/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CompareTest/レコードの順序が異なる/expected.yml")
void レコードの順序が異なる() {}
}
期待値の方がテーブル数が少ない
data-set.yml
foo_table:
- id: 1
value: FOO
bar_table:
- id: 1
value: BAR
expected.yml
foo_table:
- id: 1
value: FOO
結果
成功する。
期待値の方がテーブル数が多い
data-set.yml
foo_table:
- id: 1
value: FOO
bar_table:
- id: 1
value: BAR
expected.yml
foo_table:
- id: 1
value: FOO
bar_table:
- id: 1
value: BAR
unknown_table:
- id: 1
value: unknown
結果
失敗する。
DataSet comparison failed due to following exception:
java.lang.RuntimeException: DataSet comparison failed due to following exception:
at com.github.database.rider.core.dataset.DataSetExecutorImpl.compareCurrentDataSetWith(DataSetExecutorImpl.java:833)
at com.github.database.rider.core.RiderRunner.performDataSetComparison(RiderRunner.java:144)
at com.github.database.rider.core.RiderRunner.runAfterTest(RiderRunner.java:63)
at com.github.database.rider.junit5.DBUnitExtension.afterTestExecution(DBUnitExtension.java:79)
(中略)
Caused by: org.dbunit.dataset.NoSuchTableException: UNKNOWN_TABLE
at app//org.dbunit.database.DatabaseDataSet.getTableMetaData(DatabaseDataSet.java:305)
at app//org.dbunit.database.DatabaseDataSet.getTable(DatabaseDataSet.java:333)
at app//com.github.database.rider.core.dataset.DataSetExecutorImpl.compareCurrentDataSetWith(DataSetExecutorImpl.java:831)
... 72 more
期待値の方がレコード数が少ない
data-set.yml
foo_table:
- id: 1
value: FOO
- id: 2
value: BAR
expected.yml
foo_table:
- id: 1
value: FOO
結果
失敗する。
row count (table=FOO_TABLE) expected:<1> but was:<2>
Expected :1
Actual :2
期待値の方がレコード数が多い
data-set.yml
foo_table:
- id: 1
value: FOO
expected.yml
foo_table:
- id: 1
value: FOO
- id: 2
value: BAR
結果
失敗する。
row count (table=FOO_TABLE) expected:<2> but was:<1>
Expected :2
Actual :1
期待値の方がカラム数が少ない
data-set.yml
foo_table:
- id: 1
value: FOO
expected.yml
foo_table:
- id: 1
結果
成功する。
期待値の方がカラム数が多い
data-set.yml
foo_table:
- id: 1
value: FOO
expected.yml
foo_table:
- id: 1
value: FOO
unknown_column: unknown
結果
失敗する。
column count (table=FOO_TABLE, expectedColCount=3, actualColCount=2) expected:<[ID, UNKNOWN_COLUMN, VALUE]> but was:<[ID, VALUE]>
Expected :[ID, UNKNOWN_COLUMN, VALUE]
Actual :[ID, VALUE]
レコードの順序が異なる
data-set.yml
foo_table:
- id: 1
value: ONE
- id: 2
value: TWO
- id: 3
value: THREE
expected.yml
foo_table:
- id: 3
value: THREE
- id: 1
value: ONE
- id: 2
value: TWO
結果
失敗する。
value (table=FOO_TABLE, row=0, col=ID) expected:<3> but was:<1>
Expected :3
Actual :1
まとめ
| パターン | 結果 |
|---|---|
| 期待値の方がテーブル数が少ない | 成功 |
| 期待値の方がテーブル数が多い | 失敗 |
| 期待値の方がレコード数が少ない | 失敗 |
| 期待値の方がレコード数が多い | 失敗 |
| 期待値の方がカラム数が少ない | 成功 |
| 期待値の方がカラム数が多い | 失敗 |
| レコードの順序が異なる | 失敗 |
-
@ExpectedDataSetに記載しているテーブルのみが比較対象となる -
@ExpectedDataSetに記載しているカラムのみが比較対象となる - 存在しないテーブルやカラムを
@ExpectedDataSetに記載した場合はエラー(当たり前) - レコード数が等しいことも比較される
- レコードの順序が等しいことも比較される
比較時のソート条件を指定する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class OrderByTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/OrderByTest/data-set.yml")
@ExpectedDataSet(
value = "sandbox/dbrider/OrderByTest/expected.yml",
orderBy = "id" // ★
)
void test() {}
}
-
@ExpectedDataSetのorderByにidを指定している
data-set.yml
foo_table:
- id: 1
value: ONE
- id: 2
value: TWO
- id: 3
value: THREE
expected.yml
foo_table:
- id: 3
value: THREE
- id: 1
value: ONE
- id: 2
value: TWO
-
data-set.ymlとexpected.ymlは、データの順序が異なるように定義している - このテストは成功する
-
@ExpectedDataSetのorderByでデータを比較するときのソート条件(カラム名)が指定できる- 実際のデータと期待値の両方がこの条件でソートされて比較される
-
orderByには配列で複数のカラム名を指定できる
ExpectedDataSet で指定したデータが含まれることを検証する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.CompareOperation;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CompareContainsTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table test_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/CompareContainsTest/data-set.yml")
@ExpectedDataSet(
value = "sandbox/dbrider/CompareContainsTest/expected.yml",
compareOperation = CompareOperation.CONTAINS // ★
)
void test() {}
}
data-set.yml
test_table:
- id: 1
value: one
- id: 2
value: two
- id: 3
value: three
expected.yml
test_table:
- id: 3
value: three
- id: 2
value: two
このテストは成功する
@ExpectedDataSet(
value = "sandbox/dbrider/CompareContainsTest/expected.yml",
compareOperation = CompareOperation.CONTAINS
)
-
@ExpectedDataSetのcompareOperationにCompareOperation.CONTAINSを指定すると、データセットに記載したデータが実際のテーブルに含まれるかどうかで検証が行われるようになる- デフォルトは
CompareOperation.EQUALSで、上で試したように順序や件数まで含めた完全一致することが検証される
- デフォルトは
- レコードが含まれるかどうかだけなので、順序はチェックされない
VIEW や SYNONYM を検証する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class TableTypeTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create view foo_view as select * from foo_table");
}
@Test
@DataSet("sandbox/dbrider/TableTypeTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/TableTypeTest/expected.yml")
void test() {}
}
-
foo_tableテーブルを丸コピーしたfoo_viewビューを作成している
data-set.yml
foo_table:
- id: 1
value: foo
- id: 2
value: bar
expected.yml
foo_view:
- id: 1
value: foo
- id: 2
value: bar
- 期待値は
foo_viewビューの内容を検証している
実行結果
DataSet comparison failed due to following exception:
java.lang.RuntimeException: DataSet comparison failed due to following exception:
at com.github.database.rider.core.dataset.DataSetExecutorImpl.compareCurrentDataSetWith(DataSetExecutorImpl.java:833)
...
Caused by: org.dbunit.dataset.NoSuchTableException: FOO_VIEW
at app//org.dbunit.database.DatabaseDataSet.getTableMetaData(DatabaseDataSet.java:305)
...
- デフォルトでは、読み込みの対象となるものは実際のテーブルに限られている
- このため、 VIEW などを検査対象にしようとするとテーブルが見つからないというエラーになる
- VIEW などの実テーブル以外も対象にしたい場合は、以下のように設定する
dbunit.yml
properties:
tableType:
- TABLE
- VIEW
- 設定ファイル (
dbunit.yml) でproperties.tableTypeに読み込み対象としてVIEWを追加する- デフォルトは
TABLEのみとなっている
- デフォルトは
-
properties.tableTypeには DatabaseMetaData.getTableTypes() で取得できる値のいずれかを指定できる -
@DBUnitアノテーションのtableTypeでも指定できる - 上記設定を入れたうえでテストを実行すると、テストは成功する
バッチ更新
dbunit.yml
properties:
batchedStatements: true
batchSize: 100
- 設定ファイル(
dbunit.yml)で、properties.batchedStatementsにtrueを指定することで、JDBCのバッチ更新が有効になる- デフォルトは
falseで無効になっている - 理由は こちら を参照
- デフォルトは
-
properties.batchSizeで、更新間隔を指定できる- デフォルトは 100
-
@DBUnitアノテーションでも指定可能
クリーンアップ
基本
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CleanUpTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@BeforeEach
void setUp() {
db.executeUpdate("insert into foo_table values (1, 'hello')");
db.executeUpdate("insert into foo_table values (2, 'world')");
db.executeUpdate("insert into bar_table values (1, 'bar')");
}
@Test
@DataSet("sandbox/dbrider/CleanUpTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CleanUpTest/expected.yml")
void test() {}
}
-
foo_tableとbar_tableの2つを作成し、foo_tableにはレコードを2件、bar_tableにはレコードを1件登録しておく
data-set.yml
foo_table:
- id: 3
value: FOO
-
@DataSetで、foo_tableのみレコードを1件を登録するような記述にしておく
expected.yml
foo_table:
- id: 3
value: FOO
bar_table:
- id: 1
value: bar
-
foo_tableは@DataSetで指定した状態に、bar_tableは変化なしを期待する形で@ExpectedDataSetを設定する - このテストは成功する
説明
-
@DataSetで指定したデータファイルに存在するテーブルは、 DELETE-INSERT される -
@DataSetに含まれないテーブルは、変更されない
外部参照制約が設定されたテーブルが存在する場合
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CleanUpForeignKeyTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("""
create table parent_table (
id integer primary key,
value varchar(32)
)""");
db.executeUpdate("""
create table child_table (
parent_id integer primary key,
value varchar(32),
foreign key (parent_id) references parent_table (id)
)""");
db.executeUpdate("""
create table grand_child (
child_id integer primary key,
value varchar(32),
foreign key (child_id) references child_table (parent_id)
)""");
}
@BeforeEach
void setUp() {
db.executeUpdate("insert into parent_table values (1, 'parent')");
db.executeUpdate("insert into child_table values (1, 'child')");
db.executeUpdate("insert into grand_child_table values (1, 'grand_child')");
}
@Test
@DataSet(value = "sandbox/dbrider/CleanUpForeignKeyTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CleanUpForeignKeyTest/expected.yml")
void test() {}
}

- 外部参照制約を設定したテーブルを用意し、それぞれのテーブルにレコードを登録しておく
data-set.yml
child_table:
- id: 9
value: fuga
parent_table:
- id: 9
value: hoge
grand_child_table:
- 親・子テーブルだけ値を設定、孫テーブルは名前は記載するがデータは空
- テーブル名の記述の順序は適当にしておく
expected.yml
parent_table:
- id: 9
value: hoge
child_table:
- id: 9
value: fuga
grand_child_table:
-
data-set.ymlと同じ内容(テーブル名の順序だけ整理) - このテストは成功する
説明
-
@DataSetで指定したテーブルに外部参照制約が設定されている場合、 Database Rdier はテーブルの依存関係を調べて適切な順序で DELETE-INSERT をしてくれるようになっている - つまり、依存するテーブルを列挙しておけば、記述の順番は気にしなくていい
- 子テーブルを記載しないと DELETE-INSERT の対象にならないので、親テーブルを DELETE しようとしたときに外部参照制約エラーになる
- したがって、依存するテーブルはすべて記載しておかなければならない
DELETE-INSERT 以外の処理にする
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.core.api.dataset.SeedStrategy;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class StrategyTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@BeforeEach
void setUp() {
db.executeUpdate("insert into foo_table values (9, 'default value')");
}
@Test
@DataSet(
value = "sandbox/dbrider/StrategyTest/data-set.yml",
strategy = SeedStrategy.INSERT // ★
)
@ExpectedDataSet("sandbox/dbrider/StrategyTest/expected.yml")
void test() {}
}
-
@BeforeEachで初期データを登録している -
@DataSetのstrategyにSeedStrategy.INSERTを設定している
data-set.yml
foo_table:
- id: 1
value: foo
expected.yml
foo_table:
- id: 9
value: default value
- id: 1
value: foo
- 期待値は、初期データと
data-set.ymlで指定したデータの両方が存在することを期待するように定義している - このテストは成功する
-
@DataSetのstrategyを変更することで、デフォルトの DELETE-INSERT の動きを変更できる-
INSERTの場合は、 DELETE が行われず INSERT だけが行われる - 何が指定できるかについては、
SeedStrategyに定義されている定数と このあたり を参考のこと
-
DataSetで指定していないテーブルもすべてをクリーンする
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CleanUpAllTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@BeforeEach
void setUp() {
db.executeUpdate("insert into foo_table values (1, 'foo')");
db.executeUpdate("insert into bar_table values (1, 'bar')");
}
@Test
@DataSet(
value = "sandbox/dbrider/CleanUpAllTest/data-set.yml",
cleanBefore = true // ★
)
@ExpectedDataSet("sandbox/dbrider/CleanUpAllTest/expected.yml")
void test() {}
}
- テーブルを2つ用意し、それぞれレコードを登録しておく
-
@DataSetアノテーションのcleanBeforeにtrueを設定する
data-set.yml
foo_table:
- id: 9
value: FOO
-
foo_tableのみ、@DataSetでデータを登録するように設定する
expected.yml
foo_table:
- id: 9
value: FOO
bar_table:
-
foo_tableはdata-set.ymlで設定した状態と同じになっていることを、bar_tableは空になっていることを期待値として設定している - このテストは成功する
説明
@DataSet(
value = "sandbox/dbrider/CleanUpAllTest/data-set.yml",
cleanBefore = true // ★
)
-
@DataSetアノテーションのcleanBeforeにtrueを設定すると、データベースに存在するすべてのテーブルがクリアされてからテストが実行される- デフォルトは
false -
valueを指定しなくてもcleanBeforeだけ指定することも可能(@DataSet(cleanBefore=true))なので、とりあえず全テーブルクリアしてテストを実行、といったことができる
- デフォルトは
- テスト終了後にクリアする場合は
cleanAfterにtrueを設定する - クリアを行う直前にデータベースに存在する外部参照制約が無効化されるため、外部参照制約のあるテーブルもすべてクリアできるようになっている
- クリーンが終わったら外部参照制約は有効化される
-
@DataSetごとではなく、すべてのテストでデータベースのクリーンを行いたい場合は、dbunit.ymlファイルでalwaysCleanBeforeにtrueを設定する-
alwaysCleanBeforeとcleanBeforeが同時に設定された場合は、どちらか片方がtrueだったらクリーンが行われる - 実装箇所
-
dbunit.yml
alwaysCleanBefore: true
特定のテーブルはクリーンアップの対象外にする
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CleanUpAllSkipTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table hoge_table (id integer, value varchar(32))");
db.executeUpdate("create table fuga_table (id integer, value varchar(32))");
db.executeUpdate("create table piyo_table (id integer, value varchar(32))");
}
@BeforeEach
void setUp() {
db.executeUpdate("insert into hoge_table values (1, 'hoge')");
db.executeUpdate("insert into fuga_table values (1, 'fuga')");
db.executeUpdate("insert into piyo_table values (1, 'piyo')");
}
@Test
@DataSet(
value = "sandbox/dbrider/CleanUpAllSkipTest/data-set.yml",
cleanBefore = true,
skipCleaningFor = "PIYO_TABLE" // ★
)
@ExpectedDataSet("sandbox/dbrider/CleanUpAllSkipTest/expected.yml")
void test() {}
}
-
skipCleaningForに、クリーンアップの除外対象としてpiyo_tableの名前を設定している- 配列で複数指定可能
- 内部的にデータベースからテーブル名の一覧を取得しており、そのときのテーブル名が大文字で取得されているため、大文字で指定しないとうまく適用されなかった(多分データベース製品に依存する)
data-set.yml
hoge_table:
- id: 9
value: HOGE
-
hoge_tableだけ設定している
expected.yml
hoge_table:
- id: 9
value: HOGE
fuga_table:
piyo_table:
- id: 1
value: piyo
-
fuga_tableは空を期待するが、pyio_tableはクリアされていないことを期待している - このテストは成功する
説明
@DataSet(
value = "sandbox/dbrider/CleanUpAllSkipTest/data-set.yml",
cleanBefore = true,
skipCleaningFor = "PIYO_TABLE" // ★
)
-
skipCleaningForにテーブル名を指定することで、cleanBefore,cleanAfterの対象から除外できる
複数のデータセットを指定する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class MultipleDataSetsTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table hoge_table (id integer, value varchar(32))");
db.executeUpdate("create table fuga_table (id integer, value varchar(32))");
db.executeUpdate("create table piyo_table (id integer, value varchar(32))");
db.executeUpdate("insert into hoge_table values (9, 'default value')");
db.executeUpdate("insert into fuga_table values (9, 'default value')");
db.executeUpdate("insert into piyo_table values (9, 'default value')");
}
@Test
@DataSet({
"sandbox/dbrider/MultipleDataSetsTest/data-set1.yml",
"sandbox/dbrider/MultipleDataSetsTest/data-set2.yml"
})
@ExpectedDataSet("sandbox/dbrider/MultipleDataSetsTest/expected.yml")
void test() {}
}
-
@DataSetのvalueに複数のデータセットファイルを指定している - また、各テーブルには1レコードずつデフォルトデータを登録している
data-set1.yml
hoge_table:
- id: 1
value: from data-set1.yml
data-set2.yml
hoge_table:
- id: 2
value: from data-set2.yml
fuga_table:
- id: 1
value: from data-set2.yml
-
hoge_tableは、data-set1.ymlとdata-set2.ymlの両方に定義し、fuga_tableはdata-set2.ymlでだけ定義している -
piyo_tableはいずれのデータセットファイルにも記載していない
expected.yml
hoge_table:
- id: 1
value: from data-set1.yml
- id: 2
value: from data-set2.yml
fuga_table:
- id: 1
value: from data-set2.yml
piyo_table:
- id: 9
value: default value
-
hoge_tableは、data-set1.ymlとdata-set2.ymlの両方で定義したレコードが登録されていることを期待している -
fuga_tableは、data-set2.ymlで定義したレコードが登録されていることを期待している -
piyo_tableは、デフォルトで登録したレコードだけが存在していることを期待している - このテストは成功する
-
@DataSetのvalueで複数のデータセットを指定した場合、それらのデータセットに記載されたレコードが全て登録されるようになる- 単純に追加 INSERT されるだけなので、主キーの重複などがあった場合は実行時にエラーになる
複数の期待値を指定する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class MultipleExpectedDataSetsTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/MultipleExpectedDataSetsTest/data-set.yml")
@ExpectedDataSet({
"sandbox/dbrider/MultipleExpectedDataSetsTest/expected1.yml",
"sandbox/dbrider/MultipleExpectedDataSetsTest/expected2.yml"
})
void test() {}
}
-
@ExpectedDataSetのvalueに複数のデータセットファイルを指定している
data-set.yml
foo_table:
- id: 1
value: foo
- id: 2
value: FOO
bar_table:
- id: 1
value: bar
expected1.yml
foo_table:
- id: 1
value: foo
expected2.yml
foo_table:
- id: 2
value: FOO
bar_table:
- id: 1
value: bar
- このテストは成功する
-
@ExpectedDataSetのvalueに複数のデータセットファイルを指定した場合、それらを複合した状態で検証が行われる
データ形式
YAML
@Test
@DataSet("sandbox/dbrider/DataSetTypeTest/testYaml/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/DataSetTypeTest/testYaml/expected.yaml")
void testYaml() {}
data-set.yml
foo_table:
- &template
id: 1
value: foo
bar_table:
- value: bar
<<: *template
expected.yaml
foo_table:
- id: 1
value: foo
bar_table:
- id: 1
value: bar
- YAML でデータセットのファイルを定義できる
- 本家 DBUnit には存在しない形式で、 Database Rider 独自の実装となっている(YamlDataSet)
- トップレベルはMap構造にして、キーにテーブル名、値にレコードの配列を記載する
- 各レコードはMap構造で記載し、キーにカラム名、値にカラムの値を記載する
- 内部的にはSnakeYAMLが使われているので、SnakeYAMLがサポートしている記法なら書くことができる
- SnakeYAML がサポートしている記法は SnakeYAML のドキュメント を参照
- 拡張子を
ymlまたはyamlにすると、 YAML として処理される
JSON
@Test
@DataSet("sandbox/dbrider/DataSetTypeTest/testJson/data-set.json")
@ExpectedDataSet("sandbox/dbrider/DataSetTypeTest/testJson/expected.json")
void testJson() {}
data-set.json
{
"foo_table": [
{
"id": 1,
"value": "foo"
}
],
"bar_table": [
{
"id": 1,
"value": "bar"
}
]
}
- JSON でデータセットを定義できる
- 本家 DBUnit には存在しない形式で、 Database Rider 独自の実装となっている(JSONDataSet)
- トップレベルはオブジェクトにして、キーにテーブル名、値にレコードの配列を記載する
- 各レコードはオブジェクトで記載し、キーにカラム名、値にカラムの値を記載する
- 拡張子を
jsonにすると、 JSON として処理される
XML
@Test
@DataSet("sandbox/dbrider/DataSetTypeTest/testXml/data-set.xml")
@ExpectedDataSet("sandbox/dbrider/DataSetTypeTest/testXml/expected.xml")
void testXml() {}
<?xml version="1.0" encoding="UTF-8" ?>
<dataset>
<foo_table id="1" value="foo" />
<bar_table id="1" value="bar" />
</dataset>
- XML でデータセットを定義できる
- これは、本家DBUnitの
FlatXmlDataSetが使用されている -
FlatXmlDataSetの使い方については こちら を参照
- これは、本家DBUnitの
XLS, XLSX
@Test
@DataSet("sandbox/dbrider/DataSetTypeTest/testXls/data-set.xls")
@ExpectedDataSet("sandbox/dbrider/DataSetTypeTest/testXls/expected.xls")
void testXls() {}
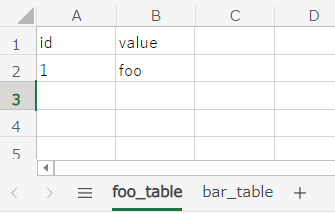
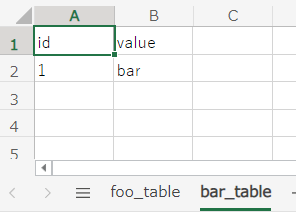
- Excel でデータセットを定義できる
- これは、本家DBUnitの
XlsDataSetが使用されている -
XlsDataSetの使い方については こちら を参照
- これは、本家DBUnitの
-
ただし、使用できるのは Excel 97-2003 形式(*.xls)のみ実装で拡張子がxlsのものしかハンドリングしていないので、xlsxは読み込めない「Excel」とか「xlsx」で issue を検索しても何も引っかからないので、多分対応予定はなさそう(DBUnit 自体は xlsx も読み込めるので、条件追加するだけでよさそうだけど需要ないのかな?)- xlsx もサポートする PR を出してマージしてもらえたので、 1.35.1 から xlsx も使えるようになった
CSV
フォルダ構成
`-src/test/
|-java/
| `-sandbox/dbrider/
| `-DataSetTypeTest.java
`-resources/
`-sandbox/dbrider/DataSetTypeTest/testCsv/
|-data-set/
| |-foo_table.csv
| |-bar_table.csv
| `-table_ordering.txt
`-expected/
|-foo_table.csv
|-bar_table.csv
`-table_ordering.txt
@Test
@DataSet("sandbox/dbrider/DataSetTypeTest/testCsv/data-set/foo_table.csv")
@ExpectedDataSet("sandbox/dbrider/DataSetTypeTest/testCsv/expected/foo_table.csv")
void testCsv() {}
foo_table.csv
id,value
1,foo
bar_table.csv
id,value
1,bar
table_ordering.txt
foo_table
bar_table
- Excel でデータセットを定義できる
- これは、本家DBUnitの
CsvDataSetが使用されている -
CsvDataSetの使い方については こちら を参照
- これは、本家DBUnitの
-
@DataSetおよび@ExpectedDataSetのvalueに設定したパスの1つ上のパスがCsvDataSetのコンストラクタに渡される- したがって、用意した CSV ファイルのどれを指定しても問題ない(ファイルの存在チェックはされるので、存在しないファイル名だとエラーになる)
- 拡張子を
csvにすると、 CSV として処理される
正規表現
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class RegularExpressionsTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/RegularExpressionsTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/RegularExpressionsTest/expected.yml")
void test() {}
}
data-set.yml
foo_table:
- id: 10
value: Hello World!!
expected.yml
foo_table:
- id: "regex:\\d+"
value: "regex:^Hello.*"
-
@ExpectedDataSetで指定したデータセットの値をregex:<正規表現>と記述することで、正規表現を使った検証ができるようになる - このテストは成功する
DataSet Replacers
DBUnitには、データセットに書かれた特定の文字列を実行時に別の値に置き換えるReplacementDataSetというデータセットが存在する。
Database Riderは、この ReplacementDataSet を使いやすくした DataSet Replacers という仕組みを提供している。
Date replacer
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class DateTimeReplacerTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, date_value timestamp)");
}
@Test
@DataSet("sandbox/dbrider/ReplacerTest/testDateTimeReplacer/data-set.yml")
void testDateTimeReplacer() {
db.printTable("foo_table");
}
}
data-set.yml
foo_table:
- id: 1
date_value: "[DAY,NOW]"
- id: 2
date_value: "[DAY,YESTERDAY]"
- id: 3
date_value: "[DAY,WEEK_AFTER]"
- id: 4
date_value: "[MIN,NOW]"
- id: 5
date_value: "[MIN,PLUS_ONE]"
- id: 6
date_value: "[MIN,MINUS_30]"
- id: 7
date_value: "[SEC,NOW]"
- id: 8
date_value: "[SEC,MINUS_ONE]"
- id: 9
date_value: "[SEC,PLUS_TEN]"
実行結果(分かりやすいように末尾にコメントを追加)
{DATE_VALUE=2022-12-14 20:34:55.0, ID=1} // [DAY,NOW]
{DATE_VALUE=2022-12-13 20:34:55.0, ID=2} // [DAY,YESTERDAY]
{DATE_VALUE=2022-12-21 20:34:55.0, ID=3} // [DAY,WEEK_AFTER]
{DATE_VALUE=2022-12-14 20:34:55.0, ID=4} // [MIN,NOW]
{DATE_VALUE=2022-12-14 20:35:55.0, ID=5} // [MIN,PLUS_ONE]
{DATE_VALUE=2022-12-14 20:04:55.0, ID=6} // [MIN,MINUS_30]
{DATE_VALUE=2022-12-14 20:34:55.0, ID=7} // [SEC,NOW]
{DATE_VALUE=2022-12-14 20:34:54.0, ID=8} // [SEC,MINUS_ONE]
{DATE_VALUE=2022-12-14 20:35:05.0, ID=9} // [SEC,PLUS_TEN]
-
[<種別>,<差分>]と記述することで、実行時の現在日時からの相対日時に置き換えることができる -
<種別>には、差分の種類として以下のいずれかを指定する
| 種別 | 説明 |
|---|---|
DAY |
日 |
HOUR |
時 |
MIN |
分 |
SEC |
秒 |
-
<差分>には、<種別>ごとに実行日時からどれくらいの相対時間に置き換えるかを指定する
| 種別 | 差分 | 説明 |
|---|---|---|
DAY |
NOW |
現在日時 |
YESTERDAY |
1日前 | |
TOMORROW |
1日後 | |
WEEK_BEFORE |
7日前 | |
WEEK_AFTER |
7日後 | |
MONTH_BEFORE |
30日前 | |
MONTH_AFTER |
30日後 | |
YEAR_BEFORE |
365日前 | |
YEAR_AFTER |
365日後 | |
HOUR |
NOW |
現在日時 |
MINUS_ONE |
1時間前 | |
PLUS_ONE |
1時間後 | |
MINUS_TEN |
10時間前 | |
PLUS_TEN |
10時間後 | |
MIN |
NOW |
現在日時 |
MINUS_ONE |
1分前 | |
PLUS_ONE |
1分後 | |
MINUS_TEN |
10分前 | |
PLUS_TEN |
10分後 | |
MINUS_30 |
30分前 | |
PLUS_30 |
30分後 | |
SEC |
NOW |
現在日時 |
MINUS_ONE |
1秒前 | |
PLUS_ONE |
1秒後 | |
MINUS_TEN |
10秒前 | |
PLUS_TEN |
10秒後 | |
MINUS_30 |
30秒前 | |
PLUS_30 |
30秒後 |
Unix Timestamp replacer
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.time.Instant;
@DBRider
public class UnixTimestampReplacerTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value bigint)");
}
@Test
@DataSet("sandbox/dbrider/UnixTimestampReplacerTest/data-set.yml")
void test() {
System.out.println("epoch seconds = " + Instant.now().getEpochSecond());
db.printTable("foo_table");
}
}
data-set.yml
foo_table:
- id: 1
value: "[UNIX_TIMESTAMP]"
実行結果
epoch seconds = 1671103956
{ID=1, VALUE=1671103956}
- データセットの値を
[UNIX_TIMESTAMP]と記述すると、Unix時間に置換される
Null replacer
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class NullReplacerTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/NullReplacerTest/data-set.yml")
void test() {
db.printTable("foo_table");
}
}
data-set.yml
foo_table:
- id: 1
value: null
- id: 2
value: "null"
- id: 3
value: "[null]"
実行結果
{ID=1, VALUE=null}
{ID=2, VALUE="null"}
{ID=3, VALUE=null}
- データセットの値を
[null]と記述すると、その値はnullに置き換えられる - YAML のデータセットだと普通に
nullと書けばnullになるので、ぶっちゃけ使う機会はない -
nullを表現できない形式のデータセットでなら活用できる
Include replacer
dbunit.yml
connectionConfig:
url: "jdbc:hsqldb:mem:test"
user: "sa"
password: ""
properties:
replacers: [!!com.github.database.rider.core.replacers.IncludeReplacer {}]
-
IncludeReplacerはデフォルトでは無効なので、設定ファイル(dbunit.yml)に修正が必要になる -
properties.replacersに、IncludeReplacerを追加することで有効になる -
dbunit.ymlは、クラスパス直下に配置する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class IncludeReplacerTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/IncludeReplacerTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/IncludeReplacerTest/expected.yml")
void test() {}
}
data-set.yml
foo_table:
- id: "1"
value: "[INCLUDE]sandbox/dbrider/IncludeReplacerTest/message.txt"
sandbox/dbrider/IncludeReplacerTest/message.txt
Hello World!!
expected.yml
foo_table:
- id: "1"
value: Hello World!!
- データセットの値を
[INCLUDE]<リソースのパス>と記述することで、指定されたリソースファイルの内容で置換される - リソースは、
ClassLoaderのgetResourceAsStream()で読み込まれているので、それで読み込めるようにファイルやパスを調整する - ところで、
IncludeReplacerの内部では各カラムの値に対して[INCLUDE]のプレースホルダがあるかどうかを判定しているところがあり、すべてカラムの値を一律Stringにキャストしている部分がある- 実装箇所
- これが原因で、
IncludeReplacerを使う場合は置換対象以外のカラムもすべて文字列で記載しておかないと、実行時にClassCastExceptionがスローされるという残念な状態になっている - 上記の例だと、
idを数値で記載(id: 1のように記載)すると例外が発生する
-
IncludeReplacerはデフォルトでは有効にはなっていないので、必要であれば冒頭のように設定ファイル(dbunit.yml)に記載が必要となる-
properties.replacersを設定すると、デフォルトで有効になっている Replacer (ここまでに紹介した Replacer 達)はすべて無効になる - デフォルトの Replacer も必要な場合は、以下のように明示的に設定してあげる必要がある
-
dbunit.yml
properties:
replacers:
- !!com.github.database.rider.core.replacers.DateTimeReplacer {}
- !!com.github.database.rider.core.replacers.UnixTimestampReplacer {}
- !!com.github.database.rider.core.replacers.NullReplacer {}
- !!com.github.database.rider.core.replacers.IncludeReplacer {}
自作の Replacer を使用する
CustomReplacer.java
package sandbox.dbrider;
import com.github.database.rider.core.replacers.Replacer;
import org.dbunit.dataset.ReplacementDataSet;
public class CustomReplacer implements Replacer {
@Override
public void addReplacements(ReplacementDataSet dataSet) {
dataSet.addReplacementSubstring("[replace-me]", "World");
}
}
- 自作の Replacer
-
Replacerインタフェースを実装して作成する -
addReplacements(ReplacementDataSet)メソッドをオーバーライドして、置換内容を定義する-
ReplacementDataSetのaddReplacementSubstring(String, String)メソッドで、置換対象のプレースホルダと置換後の文字列を登録する - ここでは、
[replace-me]という文字列をWorldに置換するということを定義している - 置換は実行時に都度行われるのではなく、あらかじめ定義しておいた固定値で置換される
-
-
公式ガイドの実装例 では、なぜか
equals()とhashCode()をオーバーライドしているが、デフォルトで提供されている NullReplacer とかでは実装していないので必要はなさそう
CustomReplacerTest.java
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CustomReplacerTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/CustomReplacerTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/CustomReplacerTest/expected.yml")
void test() {}
}
data-set.yml
foo_table:
- id: 1
value: "Hello [replace-me]!!"
expected.yml
foo_table:
- id: 1
value: "Hello World!!"
dbunit.yml
connectionConfig:
url: "jdbc:hsqldb:mem:test"
user: "sa"
password: ""
properties:
replacers:
- !!sandbox.dbrider.CustomReplacer {}
- 自作の Replacer を有効にするため、
dbunit.ymlに設定する
アノテーションで Replacer を指定する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class CustomReplacerAtAnnotationTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet(
value = "sandbox/dbrider/CustomReplacerAtAnnotationTest/data-set.yml",
replacers = CustomReplacer.class // ★
)
@ExpectedDataSet("sandbox/dbrider/CustomReplacerAtAnnotationTest/expected.yml")
void test() {}
}
-
@DataSetのreplacersに、自作の Replacer を指定している
data-set.yml
foo_table:
- id: 1
value: Hello [replace-me]!?
expected.yml
foo_table:
- id: 1
value: Hello World!?
- このテストは成功する
-
@DataSetのreplacersで、そのDataSetだけで使用する Replacer を指定できる -
replacersを指定した場合は、デフォルトで適用されるReplacer(NullReplacerなど)は適用されなくなる -
@ExpectedDataSetにもreplacersは存在しており、同じようにその@ExpectedDataSetでだけ適用したい Replacer を指定できる
Scriptable DataSets
データセットに記述する値を、スクリプト言語で記述できる。
Groovy
build.gradle
dependencies {
...
testRuntimeOnly "org.codehaus.groovy:groovy-all:2.4.6"
}
- Groovyによる Scriptable DataSets を使用する場合は、org.codehaus.groovy:groovy-allの
2.4.6を依存関係に追加するように ガイドされている ので追加する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class ScriptableDataSetsTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/ScriptableDataSetsTest/testGroovy/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/ScriptableDataSetsTest/testGroovy/expected.yml")
void testGroovy() {}
}
data-set.yml
foo_table:
- id: 1
value: "groovy:['hello', 'world'].collect { it.toUpperCase() }.join('-')"
expected.yml
foo_table:
- id: 1
value: "HELLO-WORLD"
- データセットの値を
groovy:<任意のスクリプト>と記述することで、 Groovy の式として処理された結果が設定される - 仕組みとしては
:より前の部分(groovy)が、Javaの標準APIであるScriptEngineManager.getEngineByName(String)に渡されてScriptEngineが取得され、:より後ろがスクリプトとして処理される、という形になっている -
ScriptEngineのプロバイダを登録すれば任意のスクリプトで実行できる?- →
jsかgroovyで判定しているところがあるからできない(実装箇所)
- →
Script Assertions
data-set.yml
foo_table:
- id: 1
value: hello world
expected.yml
foo_table:
- id: 1
value: "groovy:(value.equalsIgnoreCase('HELLO WORLD'))"
- 期待値の値で、スクリプトを使って任意のアサーションを実施できる
-
groovy:(<式>)と記述する- 括弧(
())は必須なので注意 -
<式>は、真偽値を返すように記述する-
trueの場合はアサートは成功扱いになる
-
- アサート対象となる実際の値は
valueという名前で参照できる- 式の中に
valueがあることが Script Assertion として処理される条件になっているので、必ず記述が必要 - 実装箇所
- 式の中に
- 括弧(
- 整理すると、 Script Assertions で使用する式は以下の条件を満たしている必要がある
- 全体が
()で囲われている - 式の中に
valueの記述がある
- 全体が
- Script Assertions の条件を満たさない場合は、普通に式の評価結果が期待値になって実際の値と比較される
JavaScript
Java 15 で Nashorn(組み込みのJavaScriptエンジン)が削除されたことで、Java 15 以上では利用できなくなっている(自力でエンジンを追加すれば使えると思うけど、面倒なので試してない)。
Java17で試したときのエラーログ
Could not create dataset for test 'testJavaScript'.
java.lang.RuntimeException: Could not create dataset for test 'testJavaScript'.
...
Caused by: java.lang.RuntimeException: Could not find script engine by name 'js'
at com.github.database.rider.core.script.ScriptEngineManagerWrapper.getScriptEngine(ScriptEngineManagerWrapper.java:68)
at com.github.database.rider.core.script.ScriptEngineManagerWrapper.getScriptResult(ScriptEngineManagerWrapper.java:42)
at com.github.database.rider.core.api.dataset.ScriptableTable.getValue(ScriptableTable.java:45)
... 74 more
テスト実行前に任意のSQLを実行する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class ExecuteStatementsBeforeTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@Test
@DataSet(
value = "sandbox/dbrider/ExecuteStatementsBeforeTest/data-set.yml",
executeStatementsBefore =
"create table foo_table (id integer, value varchar(32))" // ★
)
@ExpectedDataSet("sandbox/dbrider/ExecuteStatementsBeforeTest/expected.yml")
void test() {}
}
-
@DataSetのexecuteStatementsBeforeにfoo_tableを作成する DDL を指定している
data-set.yml
foo_table:
- id: 1
value: foo
expected.yml
foo_table:
- id: 1
value: foo
- このテストは成功する
-
@DataSetのexecuteStatementsBeforeを指定することで、テストの実行前に任意の SQL を実行できる - SQL は
valueで指定したデータセットのデータが投入される前に実行される - テスト後に任意の SQL を実行したい場合は
executeStatementsAfterを指定する - いずれも、配列で複数の SQL を指定できる
任意の SQL をファイルで指定する
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class ExecuteScriptsBeforeTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@Test
@DataSet(
value = "sandbox/dbrider/ExecuteScriptsBeforeTest/data-set.yml",
executeScriptsBefore =
"sandbox/dbrider/ExecuteScriptsBeforeTest/create-table.sql" // ★
)
@ExpectedDataSet("sandbox/dbrider/ExecuteScriptsBeforeTest/expected.yml")
void test() {}
}
-
@DataSetのexecuteScriptsBeforeに、実行したい SQL ファイルを指定している
create-table.sql
create table foo_table (
id integer,
value varchar(32)
)
data-set.yml
foo_table:
- id: 1
value: foo
expected.yml
foo_table:
- id: 1
value: foo
- このテストは成功する
-
@DataSetのexecuteScriptsBeforeに SQL ファイルを指定することで、テスト前に任意の SQL を実行できる - SQL ファイルは
valueで指定したデータセットのデータが投入される前に実行される - テスト後に任意の SQL ファイルを実行したい場合は
executeScriptsAfterを指定する - いずれも、配列で複数のファイルを指定できる
データセットのマージ
デフォルトの動作
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
@DataSet(
value = "sandbox/dbrider/MergeDataSetTest/class-level-data-set.yml",
executeStatementsBefore = "insert into bar_table values (10, 'class level')"
)
public class MergeDataSetTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@Test
@DataSet(
value = "sandbox/dbrider/MergeDataSetTest/method-level-data-set.yml",
executeStatementsBefore = "insert into bar_table values (1, 'method level')"
)
void test() {
System.out.println("=== foo_table ===");
db.printTable("foo_table");
System.out.println("=== bar_table ===");
db.printTable("bar_table");
}
}
- クラスとメソッドの両方に
@DataSetアノテーションを設定している -
valueとexecuteStatementsBeforeを使って、foo_table,bar_tableの両方にデータを登録しようとしている
class-level-data-set.yml
foo_table:
- id: 10
value: class level
method-level-data-set.yml
foo_table:
- id: 1
value: method level
実行結果
=== foo_table ===
{ID=1, VALUE="method level"}
=== bar_table ===
{ID=1, VALUE="method level"}
- クラスに設定した
@DataSetアノテーションによるデータの登録は一切行われていない - クラスとメソッドの両方に
@DataSetアノテーションが設定された場合、デフォルトではメソッドに設定した@DataSetのみが使用される
マージを有効にする
dbunit.yml
mergeDataSets: true
- 設定ファイル (
dbunit.yml) で、mergeDataSets: trueを設定する
実行結果
=== foo_table ===
{ID=10, VALUE="class level"}
{ID=1, VALUE="method level"}
=== bar_table ===
{ID=10, VALUE="class level"}
{ID=1, VALUE="method level"}
- クラスに設定した
@DataSetアノテーションによるデータ登録も行われるようになった -
mergeDataSetsにtrueを設定すると、クラスとメソッドの両方に@DataSetアノテーションが設定されている場合に、その設定がマージされて実行されるようになる - なお、マージできるのは
valueやexecuteStatementsBeforeのように値を配列で指定できるものに限られる - イメージとしては、以下のような
@DataSetがメソッドに設定されるようになった感じになる
@DataSet(
value = {
"sandbox/dbrider/MergeDataSetTest/class-level-data-set.yml",
"sandbox/dbrider/MergeDataSetTest/method-level-data-set.yml"
},
executeStatementsBefore = {
"insert into bar_table values (10, 'class level')",
"insert into bar_table values (1, 'method level')"
}
)
- 配列以外の単一の設定値については、デフォルトではメソッドに設定した値が優先される
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
@DataSet(
cleanBefore = true,
executeStatementsBefore = "insert into bar_table values (10, 'class level')"
)
public class MergeDataSetTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
db.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@BeforeEach
void setUp() {
db.executeUpdate("insert into foo_table values (9, 'initial value')");
}
@Test
@DataSet(
cleanBefore = false,
executeStatementsBefore = "insert into bar_table values (1, 'method level')"
)
void test2() {
System.out.println("=== foo_table ===");
db.printTable("foo_table");
System.out.println("=== bar_table ===");
db.printTable("bar_table");
}
}
- クラスとメソッドの両方に
@DataSetを設定し、cleanBeforeとexecuteStatementsBeforeを設定している- クラスは
trueで、メソッドはfalse -
executeStatementsBeforeでbar_tableにだけデータを登録している
- クラスは
-
@BeforeEachでfoo_tableに初期データを登録している -
mergeDataSetsはtrueを設定している
実行結果
=== foo_table ===
{ID=9, VALUE="initial value"}
=== bar_table ===
{ID=10, VALUE="class level"}
{ID=1, VALUE="method level"}
-
foo_tableに初期データが残っている-
cleanBeforeが有効になっていればfoo_tableは空になっているはず - 初期データが残っているということは、メソッドに設定した
cleanBefore = falseが有効になっていることが分かる
-
-
bar_tableは、executeStatementsBeforeの設定がマージされてクラスとメソッド両方で指定したデータが登録されている - 単一の設定値についてクラスで設定した値を優先させたい場合は、
dbunit.ymlで以下のように設定する
dbunit.yml
mergeDataSets: true
mergingStrategy: CLASS
-
mergingStrategyにCLASSと指定することで、単一の設定値のマージでクラスに設定した値を優先させられるようになる- デフォルトは
METHODが設定されて、メソッドに設定した値が優先されるようになっている
- デフォルトは
mergingStrategy=CLASSでの実行結果
=== foo_table ===
=== bar_table ===
{ID=1, VALUE="method level"}
{ID=10, VALUE="class level"}
- クラスの方に設定した
cleanBefore = trueが優先されてfoo_tableがクリアされるようになる
メタデータセット
MyMetaDataSet.java
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE})
@DataSet("sandbox/dbrider/MetaDataSetTest/meta-data-set.yml")
public @interface MyMetaDataSet {
}
-
@DataSetを設定した独自のアノテーションを作成する
MetaDataSetTest.java
package sandbox.dbrider;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
@DBRider
public class MetaDataSetTest {
@RegisterExtension
static DatabaseSupport db = new DatabaseSupport();
@BeforeAll
static void beforeAll() {
db.executeUpdate("create table foo_table (id integer, value varchar(32))");
}
@Test
@MyMetaDataSet
void test() {
db.printTable("foo_table");
}
}
- テストメソッドに、先ほどの自作アノテーションを設定する
実行結果
{ID=9, VALUE="meta data set"}
-
@MyMetaDataSetに設定した@DataSetの内容が登録されている -
@DataSetを設定した独自のアノテーション(メタデータセット)を定義することで、@DataSetの設定を簡単に使いまわすことができるようになる -
@TargetにElementType.TYPEを設定しておけば、クラスに設定することも可能- その場合、データのマージは
@DataSetを使った場合と同じようになる - デフォルトはメソッドに設定した方が優先され、
mergeDataSetsにtrueを設定することでマージが行われるようになる
- その場合、データのマージは
- 同じメソッドにメタデータセットと
@DataSetを同時に設定した場合は、@DataSetの方が優先された- 試したらそうなっただけで、仕様としてそう定められているかは不明(ドキュメントには記述なし)
-
mergeDataSetsにtrueを設定していた場合でも同じ結果となった
- 同じメソッドに2つ以上の異なるメタデータセットを同時に設定した場合は、いずれか1つのメタデータセットだけが適用された
- こちらも
mergeDataSetsにtrueを設定していた場合でも同じ結果となった
- こちらも
- 同じメソッドの複数のデータセットを指定するような使われ方は想定していない様子なので、やらないのが無難っぽい
コネクションリーク防止機能
dbunit.yml
leakHunter: true
- 設定ファイル(
dbunit.yml)で、leakHunterにtrueを設定する
package sandbox.dbrider;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.Test;
import java.sql.DriverManager;
@DBRider
public class LeakHunterTest {
@Test
void test() throws Exception {
createLeak();
}
private void createLeak() throws Exception {
DriverManager.getConnection("jdbc:hsqldb:mem:test", "sa", "");
}
}
- テスト中にデータベースコネクションを新規に作成して、クローズせずに放置する
実行結果
Execution of method test left 1 open connection(s).
com.github.database.rider.core.leak.LeakHunterException: Execution of method test left 1 open connection(s).
- 例外が発生してテストは失敗する
-
leakHunterにtrueを設定すると、テスト後に JDBC 接続のコネクションリークが発生していないかどうかが検証されるようになる- テストの前後で接続数をカウントして、テスト終了後に接続数が増加していた場合にエラーとなる
複数のコネクション
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.core.dataset.DataSetExecutorImpl;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.sql.DriverManager;
@DBRider
public class MultiDataSourceTest {
@RegisterExtension
static DatabaseSupport db1 = new DatabaseSupport("jdbc:hsqldb:mem:test1");
@RegisterExtension
static DatabaseSupport db2 = new DatabaseSupport("jdbc:hsqldb:mem:test2");
@BeforeAll
static void beforeAll() {
DataSetExecutorImpl.instance("db1",
() -> DriverManager.getConnection("jdbc:hsqldb:mem:test1", "sa", ""));
DataSetExecutorImpl.instance("db2",
() -> DriverManager.getConnection("jdbc:hsqldb:mem:test2", "sa", ""));
db1.executeUpdate("create table foo_table (id integer, value varchar(32))");
db2.executeUpdate("create table bar_table (id integer, value varchar(32))");
}
@Test
@DataSet(
value = "sandbox/dbrider/MultiDataSourceTest/db1-data-set.yml",
executorId = "db1"
)
@ExpectedDataSet("sandbox/dbrider/MultiDataSourceTest/db1-expected.yml")
void test1() {}
@Test
@DataSet(
value = "sandbox/dbrider/MultiDataSourceTest/db2-data-set.yml",
executorId = "db2"
)
@ExpectedDataSet("sandbox/dbrider/MultiDataSourceTest/db2-expected.yml")
void test2() {}
}
-
test1とtest2の2つのデータベースをインメモリで作成 -
test1データベースにはfoo_tableテーブルを、test2データベースにはbar_tableテーブルを作成している -
test1メソッドではtest1データベースを使ったテストを、test2メソッドではtest2データベースを使ったテストを実施している
db1-data-set.yml
foo_table:
- id: 1
value: foo
db2-data-set.yml
bar_table:
- id: 1
value: bar
- 期待値のファイルの内容は、それぞれ
@DataSetで指定したファイルの内容と同じにしているので割愛 - このテストは成功する
説明
-
@DataSetで指定したデータセットをデータベースに登録する際、裏ではDataSetExecutorImplが使用されている -
DataSetExecutorImplは、それぞれのインスタンスがデータベースコネクションを保持している -
DataSetExecutorImplのインスタンスは、同クラスに static で定義されている各種instance()メソッドで生成できる-
instance()メソッドで生成されたインスタンスは、内部でキャッシュされて再利用される
-
-
DataSetExecutorImplには、個々のインスタンスを識別するためのID (executorId)が割り当てられている- 未指定の場合は
defaultという ID が割り当てられる -
DataSetExecutorImpl.instance()メソッドでインスタンスを生成するときに、引数で任意の ID を指定することも可能
- 未指定の場合は
- 以上の前提を踏まえて、前述の実装を見返す
DataSetExecutorImpl.instance("db1",
() -> DriverManager.getConnection("jdbc:hsqldb:mem:test1", "sa", ""));
DataSetExecutorImpl.instance("db2",
() -> DriverManager.getConnection("jdbc:hsqldb:mem:test2", "sa", ""));
- ここで、
DataSetExecutorImplのインスタンスを生成している - インスタンス生成時に、それぞれのインスタンスの ID を引数で指定している (
db1,db2)
@DataSet(
value = "sandbox/dbrider/MultiDataSourceTest/db1-data-set.yml",
executorId = "db1"
)
- 次に、
@DataSetのexecutorIdで使用するDataSetExecutorImplの ID を指定している - これにより、各テストでのデータベースコネクションを切り替えている
Spring Boot で使う
実装
フォルダ構成
|-build.gradle
`-src/
|-main/
| |-java/
| | `-sandbox/dbrider/
| | `-Main.java
| `-resources/
| `-application.yml
`-test/
|-java/
| `-sandbox/dbrider/
| `-SpringBootTest.java
`-resources/
`-sandbox/dbrider/SpringBootTest/
|-data-set.yml
`-expected.yml
build.gradle
plugins {
id "java"
id 'org.springframework.boot' version '2.7.7'
id 'io.spring.dependency-management' version '1.0.15.RELEASE'
}
sourceCompatibility = 17
targetCompatibility = 17
[compileJava, compileTestJava]*.options*.encoding = "UTF-8"
ext {
dbriderVersion = "1.35.0"
}
repositories {
mavenCentral()
}
dependencies {
runtimeOnly "org.hsqldb:hsqldb"
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
testImplementation "org.junit.jupiter:junit-jupiter:5.9.1"
testImplementation "com.github.database-rider:rider-junit5:${dbriderVersion}"
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation "com.github.database-rider:rider-spring:${dbriderVersion}"
}
test {
useJUnitPlatform()
}
Main.java
package sandbox.dbrider;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
}
application.yml
spring.datasource:
url: jdbc:hsqldb:mem:test
username: sa
password:
SpringBootTest.java
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit.jupiter.SpringExtension;
@DBRider
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = Main.class)
public class SpringBootTest {
@Autowired
JdbcTemplate jdbcTemplate;
@BeforeEach
void setUp() {
jdbcTemplate
.execute("create table if not exists foo_table (id integer, value varchar(32))");
}
@Test
@DataSet("sandbox/dbrider/SpringBootTest/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/SpringBootTest/expected.yml")
void test() {}
}
data-set.yml (expected.ymlも同じ内容)
foo_table:
- id: 1
value: foo
説明
build.gradle
dependencies {
...
testImplementation "com.github.database-rider:rider-spring:${dbriderVersion}"
}
- Spring で Database Rider を使う場合は、依存関係に com.github.database-rider:rider-spring を追加する
SpringBootTest.java
@DBRider
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = Main.class)
public class SpringBootTest {
- Spring のテストを有効にするためのアノテーションと、 Database Rider を有効にするためのアノテーションを両方とも設定する
-
@SpringBootTestは Web に依存するのでここでは使っていないが、 Web アプリな Spring Boot のテストをするのなら@SpringBootTestを使えばいい
-
- あとは Database Rider が自動的に Spring 上で実行されているかどうかを検出して、 Spring で実行されている場合は
ApplicationContextからDataSourceを取得するように裏で勝手に振るまってくれる
データソースの Bean を指定する
Main.java
package sandbox.dbrider;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@SpringBootApplication
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.primary")
public DataSourceProperties primaryDataSourceProperties() {
return new DataSourceProperties();
}
@Bean
public DataSource primaryDataSource() {
return primaryDataSourceProperties()
.initializeDataSourceBuilder()
.build();
}
@Bean
public JdbcTemplate primaryJdbcTemplate() {
return new JdbcTemplate(primaryDataSource());
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.secondary")
public DataSourceProperties secondaryDataSourceProperties() {
return new DataSourceProperties();
}
@Bean
public DataSource secondaryDataSource() {
return secondaryDataSourceProperties()
.initializeDataSourceBuilder()
.build();
}
@Bean
public JdbcTemplate secondaryJdbcTemplate() {
return new JdbcTemplate(secondaryDataSource());
}
}
-
primaryDataSourceとsecondaryDataSourceの2つのDataSourceを定義している - 複数データソースを定義する方法については、以下を参照
- Configure and Use Multiple DataSources in Spring Boot | Baeldung
- Spring Boot 2.x で
DataSourceの実装クラスが HikariCP に代わったことで、検索するとよく出てくる古いやり方(DataSourceBuilder.create().build()でDataSourceを作る方法)は利用できなくなっているので注意が必要
application.yml
spring.datasource:
primary:
url: jdbc:hsqldb:mem:test1
username: sa
password:
secondary:
url: jdbc:hsqldb:mem:test2
username: sa
password:
- 2つのデータソースを定義
SpringBootTest.java
package sandbox.dbrider;
import com.github.database.rider.core.api.dataset.DataSet;
import com.github.database.rider.core.api.dataset.ExpectedDataSet;
import com.github.database.rider.junit5.api.DBRider;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit.jupiter.SpringExtension;
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = Main.class)
public class SpringBootTest {
@Autowired
@Qualifier("primaryJdbcTemplate")
JdbcTemplate primaryJdbcTemplate;
@Autowired
@Qualifier("secondaryJdbcTemplate")
JdbcTemplate secondaryJdbcTemplate;
@BeforeEach
void setUp() {
primaryJdbcTemplate
.execute("create table if not exists foo_table (id integer, value varchar(32))");
secondaryJdbcTemplate
.execute("create table if not exists bar_table (id integer, value varchar(32))");
}
@Test
@DBRider(dataSourceBeanName = "primaryDataSource") // ★
@DataSet("sandbox/dbrider/SpringBootTest/test1/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/SpringBootTest/test1/expected.yml")
void test1() {}
@Test
@DBRider(dataSourceBeanName = "secondaryDataSource") // ★
@DataSet("sandbox/dbrider/SpringBootTest/test2/data-set.yml")
@ExpectedDataSet("sandbox/dbrider/SpringBootTest/test2/expected.yml")
void test2() {}
}
-
primaryDataSourceにはfoo_tableテーブルを作成し、secondaryDataSourceにはbar_tableテーブルを作成している -
@DBRiderアノテーションのdataSourceBeanNameで使用するDataSourceの Bean 名を指定している
test1/data-set.yml (expected は同じなので省略)
foo_table:
- id: 1
value: foo
test2/data-set.yml (expected は同じなので省略)
bar_table:
- id: 1
value: foo
- このテストは成功する
-
@DBRiderのdataSourceBeanNameに使用するDataSourceの Bean 名を指定することで、そのDataSourceを使用してデータベースアクセスが行われるようになる