Kaggleで三日間遊んで学んだことです。
自分用のためにまとめました。
- 課題:分類・回帰(NumericalとCategorical featuresのみ、画像はまだ調べていないです。)
- 流れ
- preprocessing (欠損値の処理、featuresの選択、Categorical featuresのエンコーディング)
- modeling
- CV,Ensemble
- ツール(メイン):pandas,numpy,seaborn,matplotlib,sklearn
前処理preprocessing
前処理については、hirai.meはとても参考になります。
データの確認
まずデータをチャックします。
df_train = pd.read_csv("train.csv")
df_train.head() #最初の5行を確認
df_train.info() #データの欠損値、型、columnsを確認
df.describe() #Numericalデータの統計情報
df.describe(include=['O']) #Categoricalデータの統計情報
次は図でデータの分布を確認します。
基本的には、seabornを使います。
- Catagorical features(分類)
data = df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
f, ax = plt.subplots(figsize=(6, 4))
fig = sns.barplot(x='Pclass', y='Survived', palette="Set3", data=data)
fig.axis(ymin=0, ymax=1)
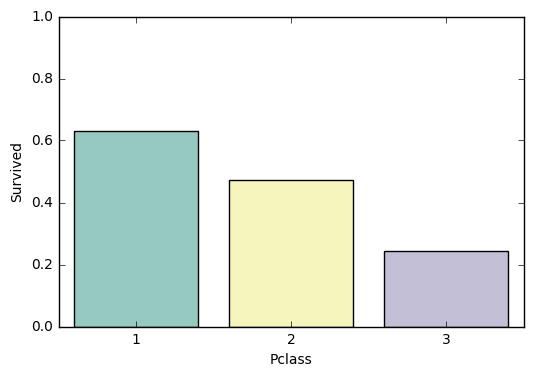
- Catagorical features(回帰)
data = pd.concat([df_train['SalePrice'], df_train["MSZoning"]], axis=1)
f, ax = plt.subplots(figsize=(6, 4))
fig = sns.boxplot(x="MSZoning", y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);
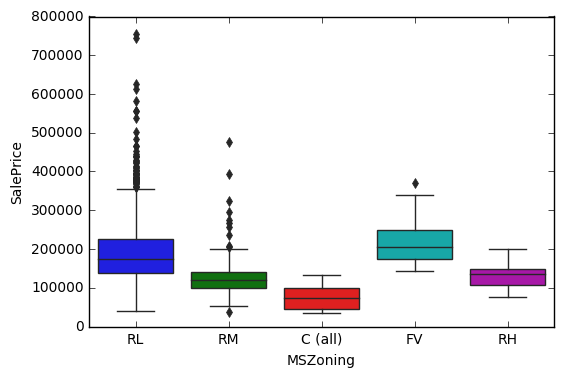
- Numerical features(分類)
g = sns.FacetGrid(df_train, col='Survived')
g.map(plt.hist, 'Age', bins=20, color="steelblue")
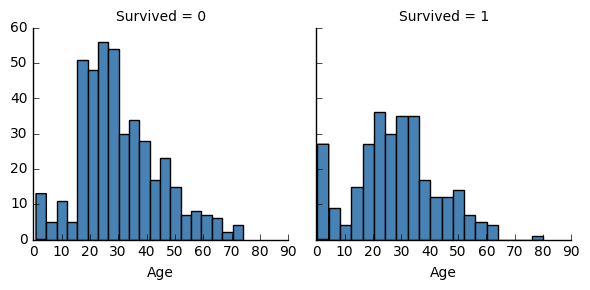
相関性を確認します
corrmat = df_train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True)
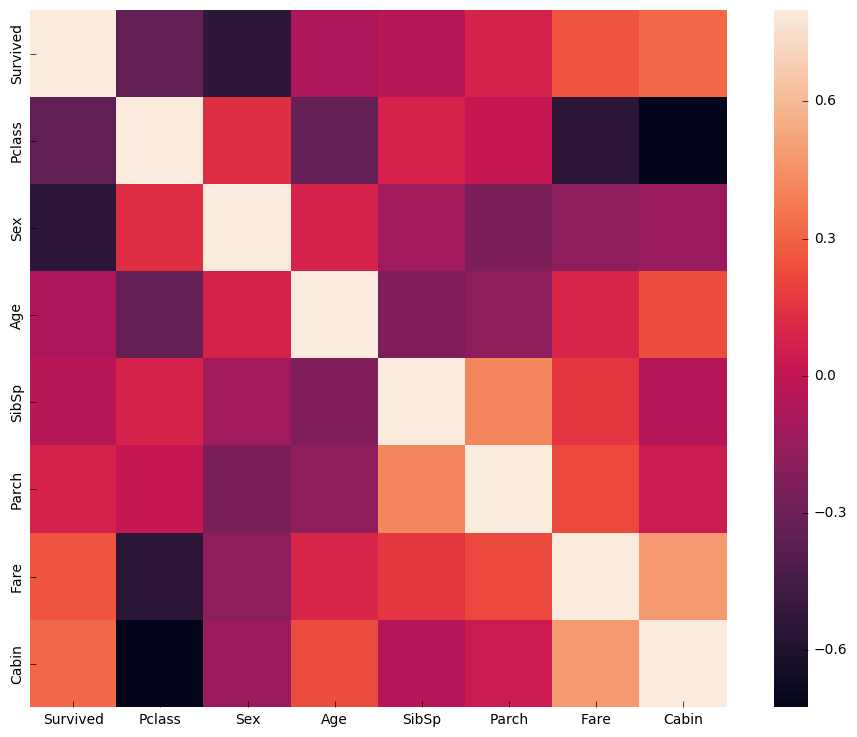
欠損値の処理
# 捨てる
df_train= df_train.dropna()
# 平均値で埋め込む
m = np.nanmean(np.concatenate([df_train["Fare"].values,df_test["Fare"].values], axis=0))
X['Fare'] = X['Fare'].fillna(m)
# ほかの処理方法...
特徴の選択
ここは職人の世界です。
まだいろいろ勉強しているんです。
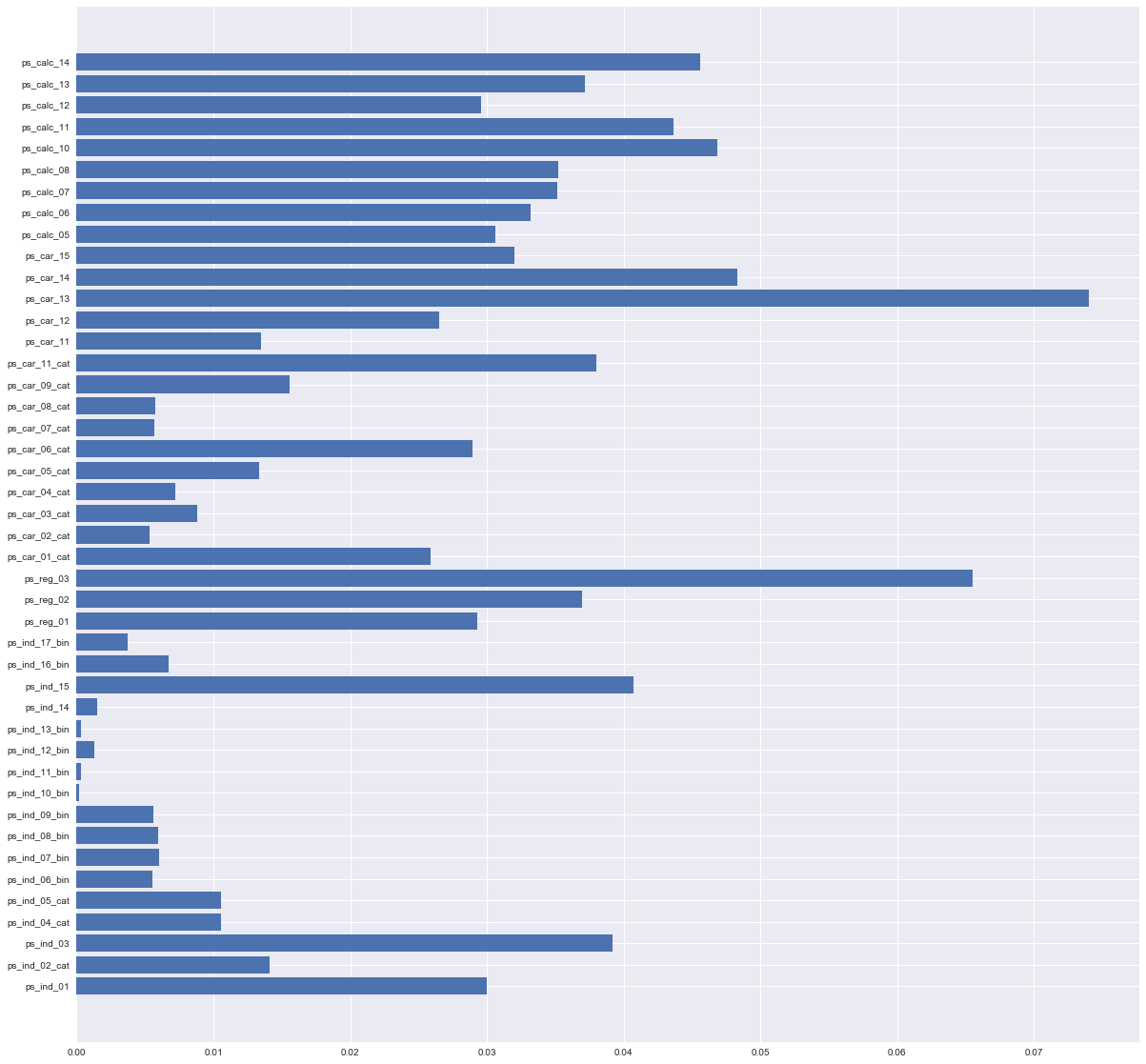
よく使われる方法は、例えば、RandomForestでfeature_importances_が小さいカラムを捨てる。
random_forest = RandomForestClassifier(n_estimators=100, class_weight='balanced')
random_forest.fit(X_train, y_train)
# 図で確認
plt.figure(figsize = ( 20 , 20 ))
plt.barh(range(44), random_forest.feature_importances_)
plt.yticks(range(44), df_train.columns.values[1:])
# drop
df_train_01 = df_train.drop(["特定の列"],axis=1)
エンコーディング
基本はone-hotで処理します。
X = pd.get_dummies(X) #一番簡単な方法
順序があるデータに対しては、マッピング処理もOK
street_mapping = {'Grvl': 2, 'Pave': 1}
df['Street'] = df['Street'].map(street_mapping)
正規化
必要がない場合もあります。
from sklearn.preprocessing import StandardScaler
mms = StandardScaler()
X_train_std = mms.fit_transform(X_train)
X_test_std = mms.transform(X_test)
以上までの一部コードはClassificationとRegressionに参考可能です。
Modeling
分類
RandomForestClassifier, KNeighborsClassifier, DecisionTreeClassifierなどいろんな手法があります。
sklearnのドキュメントで確認可能です。
例
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, y_train)
回帰
LinearRegression, RidgeCV, LassoCVなどいろんな手法があります。
sklearnのドキュメントで確認可能です。
例
lr = LinearRegression()
lr.fit(X_train, y_train)
y_train_pred = lr.predict(X_train)
GridRearch
パラメータ調整不可欠な方法です。
例
clf =xgb.XGBRegressor()
# GridSearch
clf_cv = GridSearchCV(clf, {'n_estimators':[50,100,150]})
clf_cv.fit(X_train, y_train)
clf_cv.best_params_, clf_cv.best_score_
# best_params_を適用
clf = xgb.XGBRegressor(**clf_cv.best_params_)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
xgboost
今、kaggleで一番流行っている手法?
windowsでのインストールについては、直接pip installはエラーになります。
http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost のバージョンはインストール可能です。
もしくは、HPの手順通り、mingw64を経由でインストールしてください。
使用方法は、sklearn経由か、xgboostで学習するか、どっちでもOKです
sklearnではここに参考可能です。
xgboostで学習する場合はこんな感じです。
d_train = xgb.DMatrix(X_train, y_train)
d_test = xgb.DMatrix(test.values)
watchlist = [(d_train, 'train')]
mdl = xgb.train(params, d_train, 1600, watchlist, early_stopping_rounds=70, maximize=True, verbose_eval=100)
p_test = mdl.predict(d_test, ntree_limit=mdl.best_ntree_limit)
モデリングももちろん職人の世界です。パラメータの調整、モデルの選択等々は、経験から積み重ねるしかありません。
CV,Ensemble
まだいろいろ試している途中です。
Kaggleで高い順位を獲得するため、不可欠な部分です。
交差検証Cross Validation
sklearnでは、StratifiedKFoldというメソッドがあります。
使用例
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=23)
for train_index, test_index in skf.split(X, y):
X_train = X[train_index]
y_train = y[train_index]
d_train = xgb.DMatrix(X_train, y_train)
d_test = xgb.DMatrix(test.values)
watchlist = [(d_train, 'train')]
mdl = xgb.train(params, d_train, 1600, watchlist, early_stopping_rounds=70, feval=gini_xgb, maximize=True, verbose_eval=100)
p_test = mdl.predict(d_test, ntree_limit=mdl.best_ntree_limit)
result += p_test/5
Ensemble
Wiki-Ensemble_learning
複数モデルをアンサブルする方法です。
また職人の世界です。(笑)
mlxtendというlibがあります。
これを使って、簡単にアンサブルできます。
使用例
import xgboost as xgb
from sklearn.ensemble import RandomForestRegressor,ExtraTreesRegressor,GradientBoostingRegressor
from mlxtend.regressor import StackingCVRegressor
reg1 = RandomForestRegressor(n_estimators=100, random_state=23)
reg2 = ExtraTreesRegressor(n_estimators=100, random_state=23)
reg3 = GradientBoostingRegressor(n_estimators=100, random_state=23)
reg4 = xgb.XGBRegressor(max_depth=2,n_estimators=100,objective='binary:logistic',subsample=0.5)
stregr = StackingCVRegressor(regressors=[reg1, reg2, reg3, reg4], meta_regressor=reg4)
stregr.fit(X_train_std, y_train)
y_pred = stregr.predict(X_test_std)
まだデータサイエンス世界の初心者です。kaggleという強者の集まる場から、少しでも勉強できたら幸いです。
そいえば、今参加しているコンペティションはまだ1100位ぐらいですけど、終了前には1000位に入るのは目標です。