本記事はのFinTech Advent Calendar 2018の12/24の記事になります。
こんにちは、現在、金融工学系のベンチャー企業でデータ分析の仕事をしている@onhrsです。
前職はweb系のデータサイエンティストとして働いておりましたが、華麗な転身(?)をし、金融データの分析をするようになりました。
金融、特に金融工学は物理、数学、統計学との関わりもあり非常に興味深かったので、業務を通して日々楽しく過ごしております。(まだ金融の一般知識や金融工学については勉強中です)
今回は金融領域でホットトピックになりつつある高頻度取引データや、板情報についての記事を書きたいです。ちなみに株はやったことがありません。(笑)
なお、本記事の内容は2018年12月15日にMarketTech Meetup #01にて、自身が発表したライトニングトークの内容に沿っております。
基礎編
株価と機械学習の関係について
機械学習、特に時系列データで強烈なインパクトを残したLSTMのようなアルゴリズムを用いて株価を当てることはできるのでしょうか?
「一般に公開されているデータにしかアクセスできないのでしたら、機械学習を使って株式市場の勝者になるのは難しい試みです」
「PythonとKerasによるディープラーニング」 Francois Chollet(フランソワ・ショレー) により抜粋
一般に株価はランダムウォークしているために、上下にランダムに動いているデータを学習データにしてしまうために予測が困難であるということが考えられます。
# 株価はランダムな動きをする
# https://www.kaisataipale.net/blog/2015/12/15/random-walks-in-python/
from math import sqrt
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def RandomWalk(N):
walk = np.cumsum(2*np.random.binomial(1,0.5,N)-1)
return walk
for i in range(10):
plt.plot(np.arange(365),RandomWalk(365))
ランダムウォークイメージ
また株価の予測は常に変動するために、過去のデータが予測には使えないという効率的市場仮説がそれ自身を後押ししていると考えられます。
株価予測のアプローチについて
株価はランダムウォークするために予測が難しいという話をしましたが、株価予測をするために様々なアプローチが考えられます。いくつかの方法について考えたいと思います。
テクニカル分析的な手法を利用
テクニカル分析的な手法としては有名な手法としてゴールデンクロス/デッドクロスによる解析が一般的に知られております。こちらは株価について2つの移動平均線を引き、それぞれの移動平均線のどちらが上or下にあるか株価を予想するという方法です。日足の場合、短期が25日、長期が75日の移動平均線を使うことが多いらしいです。
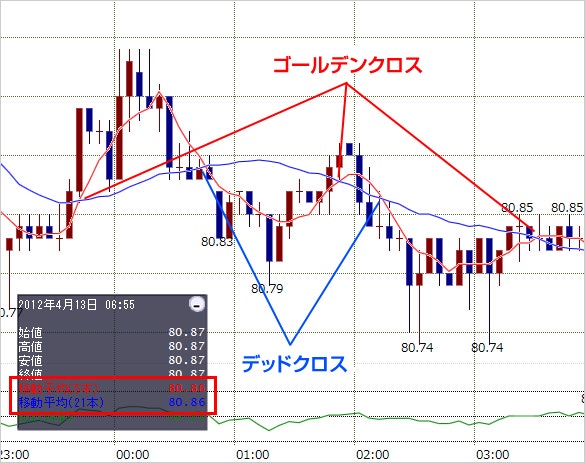
上の図のように短期の移動平均が長期の移動平均より上にあるときに株価が上昇し、買いのサインを示し(ゴールデンクロス)、その逆で長期の移動平均が短期の移動平均より上にあるとき株価は下落して売りのサインを示します(デッドクロス)。
参考1:ゴールデンクロスとデッドクロスについて | FX超初心者入門
内部の人だけが知る情報を使って、株価を予測
決算前などに内部の人しか知らない情報から株価を予想しに行く方法です。こちらはある意味、限りなく高い精度で予測が可能ですが、警察に捕まってしまいますので実質やることができません。
ニュースやtwitterなどを自然言語処理で予測
こちらは近年の自然言語処理の発展や、SNSやデータ取得のプラットフォームの進化で積極的にやられている方法だと思います。two sigmaのkaggleのコンペにもニュースデータの情報などが入っています。
アルゴリズムのやデータ加工などにまだまだ発展途上ですので、この手法は有望であると考えられます。
板情報について
テキストデータも有用ですが、本記事では板情報に注目したいと思いました。
株をやっている人はご存知かもしれませんが、板情報は、「この値段で売りたい」、「この値段で買いたい」という人がどのくらいいるのか示したものです。株の売買はある値段で売りたい人と買いたい人がいた場合にのみ、その取引が成立します(約定といいます)。売り気配値のもっとも低いもの、買い気配のもっとも高いものから順に気配1から気配n(図は気配5まで)と表記します。
このようなデータを用いることで単純な株価の推移だけでは見えなかったより細やかなデータを取得することができるようになります。

この板情報は$\text{1}\mu \text{s} (10^{-6}\text{s})$単位で変わる非常に高頻度で更新されるデータであります。上記のような板情報も含め株価の注文に関するデータをコンピューターで自動で売買戦略を実施するシステムのことを **HFT(High frequency trading)**と言います。
この高頻度取引の情報は取引量が多い銘柄で数十万件にもなるようで、参考3によると、
高頻度取引情報はμsという単位で取引のされるデータで、そのデータの膨大さから日本では調べられていない未知の領域である
ゆえに、これらの情報を用いることで、一般に困難だった市場の予測に対するアプローチになると考えられます。
参考3:実践 金融データサイエンス 隠れた構造をあぶり出す6つのアプローチ 三菱UFJトラスト投資工学研究所
データ取得
これから実際に板のデータを取得して解析してみたいと思います。
今回は実際の株価の板情報より手軽に入手できるビットコインの板情報のデータを取得して実際に解析しようと思います。
実際のリアルタイム情報は東証から入手することができます。
https://www.jpx.co.jp/markets/paid-info-equities/realtime/index.html
板情報を実際に取得(ビットコイン(BTC))
取得方法は参考4にしたがって作成しました。
参考4 : PythonでBitflyerの板情報をAPIで取得してみよう(仮想通貨の自動売買ツール(bot)制作) - ビットコイン情報局
この資料と本質的にはほとんど変わりませんが、1sごとにビットコインの板情報をデータフレーム化し1時間経過したらcsvにして保存するコードにしました。
ビットコインの場合注文ごとのデータは取得することができなかったために、任意の時間ずつ(今回は1sずつ)データを取得しました。取得するデータは、買い気配、売り気配それぞれ10本ずつで、1時間ごとにcsvに吐き出すようにしました。
import requests
import json
from datetime import datetime
import time
import pandas as pd
import os
base_url = "https://api.bitflyer.jp"
endpoint = "/v1/board?product_code="
pair = "BTC_JPY"
data = requests.get(base_url + endpoint + pair, timeout=5)
# スリープ秒数
SLEEP_T = 1
# データ保存の時間[s]
DATA_T = 3600
# boardデータ取得関数
base_url = "https://api.bitflyer.jp"
endpoint = "/v1/board?product_code="
# 対象
pair = "BTC_JPY"
def get_board():
# board = api.board(product_code=source)
data = requests.get(base_url + endpoint + pair, timeout=5)
board = json.loads(data.text)
dict_data = {}
dict_data['time'] = datetime.now()
mid_price = {'mid_price': board['mid_price']}
dict_data.update(mid_price)
asks_price = {'asks_price_{}'.format(i): board["asks"][i]["price"] for i in range(10)}
dict_data.update(asks_price)
asks_size = {'asks_size_{}'.format(i): board["asks"][i]["size"] for i in range(10)}
dict_data.update(asks_size)
bids_price = {'bids_price_{}'.format(i): board["bids"][i]["price"] for i in range(10)}
dict_data.update(bids_price)
bids_size = {'bids_size_{}'.format(i): board["bids"][i]["size"] for i in range(10)}
dict_data.update(bids_size)
return pd.Series(dict_data)
def get_btc_board():
# 1秒待ってのループ処理
print("start")
init_time = datetime.now()
end_time = datetime.now()
main_list = []
# 1hで1つのdfを作成
while (end_time - init_time).seconds < DATA_T:
try:
dict_data = get_board()
main_list.append(dict_data)
except Exception as e:
print("exception: ", e.args)
# sleep
time.sleep(SLEEP_T)
end_time = datetime.now()
df_data = pd.concat(main_list, axis=1).T
# 何時から何時までの板情報かを記載した
df_data.to_csv('./data/hour_bitcoin_day_{}_init_{}_{}_end_{}_{}.csv'.format(init_time.day, init_time.hour, init_time.minute,
end_time.hour, init_time.minute))
print("end")
if __name__ == '__main__':
# カレントディレクトリー以下にdataを作成
if not os.path.exists('./data'):
os.mkdir('./data')
# ループ処理
while True:
try:
get_btc_board()
except Exception as e:
print("exception: ", e.args)
実際はprintではなくloggingを使ったり、csvではなくDBに入れたりする方がいいと思いますが、requests、pandasがインストールされていれば、誰でも簡単に動かせるコードになっております。
解析
ここまできたら解析です。
クレンジング方法
ビットコインの価格の場合は1s間隔でデータを取得するようにしましたが、厳密にはtimeoutエラーやその他の要因で1s間隔になっておりません。実際の市場データについても、注文のたびにデータが更新されるので等間隔のデータではありません。
単にデータが等間隔になるようにリサンプリングすることが考えられますが少し注意が必要です。

しかし、この方法だとデータが密なところと疎なところで同じように評価されてしまうことになってしまいます。実際の取引のデータでは銘柄によりますが~$\mu\text{s}$間隔で取引がされるケースや、逆に数分間取引がされないケースもあります。
ゆえにデータを等間隔にする場合は取引回数も特徴量に残るようにしようと考えました。同じような理由で、取引回数だけでなく、その時間内の最大値、最小値、中央値、標準偏差なども取得するようにします。
10s間隔でデータをresamplingするためには以下のように行いました。
# リサンプリング間隔
interval = '10S'
# dfは上記で取得したcsvのデータだと思ってください
df_resampling = df.resample(interval).agg([np.max, np.mean, np.sum,np.min, np.std])
df_resampling.loc[:, 'count'] = df_resampling.resample(interval).count().time
教師データ作成方法
一般には株価を当てに行くので、以下のような回帰問題や、閾値を超える/超えないなどと定義して機械学習させることが考えられます。
- 回帰問題(MSE、MAE)
- 現在の価格より上がったら1(up)、下がったら-1(down)
- ある閾値より上がったら1(up)、下がったら-1(down)、その閾値を超えなかったら0(stay)
また、実際の教師データには株価ではなく、利益率で考えらなければいけないようです。(詳しくは以下を参照)
今回は簡単なデモなので平均絶対誤差(MAE)で評価しました。
アルゴリズム選定
アルゴリズムについては機械学習コンペで有名なXGBoostなどの勾配ブースティング系のアルゴリズムから、時系列データなのでLSTM、状態空間モデルなどが考えられます。
-
勾配ブースティング決定木
- XGBoost
- LigthGBM
- CatBoost
-
LSTM
-
状態空間モデル
この他にも興味深い分析として、板情報を画像データとして扱い、それをCNNする手法などが提案されております。
高頻度板情報の時空間パターン分析による株価動向推定
今回は手軽に試せて(計算が軽い)、精度も高いと言われているXGBoostで行いました。
解析demo
今回は簡単なdemoをしたいので、教師データの目的変数は1つ先の株価にしたいと思います。anaconda + jupyterでコーディングしました。
検証条件として
- 取得したデータは12/21〜12/23の3日間
- リサンプリングする間隔は10sec
- 検証は前半の7.5割を学習データ、後半2.5割を検証データにしました。
import pandas as pd
import numpy as np
import os
import glob
import matplotlib.pyplot as plt
import datetime
import xgboost as xgb
from sklearn.metrics import mean_absolute_error
%matplotlib inline
# 取得したデータのあるpathに設定
data_path = os.getcwd()+'/data/*.csv'
data_path_list = glob.glob(data_path)
df_bitcoin_list = []
for i in data_path_list:
df_bitcoin = pd.read_csv(i, index_col=0)
df_bitcoin['time'] = pd.to_datetime(df_bitcoin['time'] )
df_bitcoin_list.append(df_bitcoin)
df_bitcoin = pd.concat(df_bitcoin_list)
df_bitcoin.index= df_bitcoin.time
# リサンプリングする間隔
interval = '10S'
df_bitcoin_resampling = df_bitcoin.resample(interval).agg([np.max, np.mean, np.sum,np.min, np.std])
df_bitcoin_resampling['count'] = df_bitcoin.resample(interval).count().time
df_bitcoin_resampling_flat = pd.DataFrame(df_bitcoin_resampling.to_records())
df_bitcoin_resampling.columns= [''.join(col_name) for col_name in df_bitcoin_resampling.columns]
y = df_bitcoin.resample(interval).last()['mid_price'].tolist()
x_data = df_bitcoin_resampling.iloc[:-1]
y_data = y[1:]
# 検証データと学習データ分ける
t_size = int(len(x_data)*0.75)
X_train = x_data[:t_size]
y_train = y_data[:t_size]
X_test = x_data[t_size:]
y_test = y_data[t_size:]
# 計算モデル定義、学習
model = xgb.XGBRegressor()
model.fit(X_train,y_train,
early_stopping_rounds=10,
eval_metric = 'mae',
eval_set=[[X_test, y_test]])
# 予測
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# MAEで評価
print('from sklearn.metrics import mean_absolute_error train : %.3f, test : %.3f' % (mean_absolute_error(y_train, y_train_pred), mean_absolute_error(y_test, y_test_pred)) )
# 可視化
plt.plot(y_test_pred, label="predict")
plt.plot(y_test, label="true")
plt.xlabel("time(/10s)")
plt.ylabel("values(BTC)")
plt.legend()
plt.show()
私の環境では
MSE train : 201.592, test : 253.587
図示したら

timeは単なる時間ではなく、等間隔に集約した際の値です。
BTCの価格だけでやった場合よりも優位な差が出ればよかったのですが、今回の検証では優位な結果が得られませんでした。時系列データのアルゴリズムを変えたり、検証データを増やすことで変わってくれればと思いました。
また、各気配値や注文数などの基礎統計量を取ることで何かしら見えてくるかもと思いました。
実際のHFTの取り扱うデータについて
今回は手軽に手に入るビットコインで行いましたが、実際のデータはもっと色々なデータがあります。
成行注文
値段を指定せずに売買すること。
ざっくり言えば、値段に関係なく、この株の何株買いたいor売りたいときに出す注文のこと
条件付き注文
条件を指定して注文することで、寄付注文であればオープン時(9:00)に有効となり、引け注文であれば15:00に有効となります。(前場、後場については省略)
出来高の加重平均(VWAP)
売買された取引量の加重平均で、取引している人はこの値を結構みているらしいです。
キャンセル情報
注文したが途中でキャンセルすること。
見せ玉
キャンセルを利用したテクニックで、
約定の意図なく特定の株式等の売買状況に関し、大量の注文を発注・取消・訂正を行いあたかも取引が活発であると見せかけ第三者の取引を誘因する注文。 見せ板(みせいた)とも言う。(wikiより)
見せ玉などの高度なイタズラ(??)的な行為で、マーケットに与える影響力などもデータとして取り扱って、分析することで様々なものが見えてくると考えられます。
まとめ
今回は株価の機械学習による予測がランダムウォークや効率的市場仮説により困難であることや、高頻度取引のデータの可能性について議論、検証しました。HFTにより$\mu\text{s}$単位の取引が行われるようになったので、その扱う量も膨大になりましたが、これらの超高頻度なデータを分析することは大変興味深い分野になるのではないのかと考えました。
高頻度取引の情報を解析すればランダムウォークや効率的市場仮説を打ち砕くものにはならないかもしれませんが、まだまだ調べ尽くされていない現状や、昨今の機械学習の進展や、データを効率的に扱う手法が新たな知見が得られることはあるはずだと考えております。