オミータです。ツイッターで人工知能のことや他媒体の記事など を紹介しています。 @omiita_atiimoもご覧ください!
話題爆発中のAI「ChatGPT」の仕組みにせまる!
注意:ChatGPTはまだ論文が出ていないため、細かい箇所は不明です。本記事では公式から出た記事およびInstructGPTの論文をもとにChatGPTの仕組みを探っていきます
本記事の流れ:
- 忙しい方へ
- ChatGPTとは
- GPT-3
- InstructGPT
- ChatGPT
- まとめと所感
- 参考
0. 忙しい方へ
- ChatGPTは、InstructGPTをベースとしたモデルだよ
- InstructGPTは、「人間の好みに合った文を出力するように微調整したGPT-3」だよ
- InstructGPTの学習では、以下の3つが重要だよ
- GPT-3の教師ありファインチューニング
- Reward Modelの学習
- RLHF(=Reinforcement Learning from Human Feedback、人間のフィードバックに基づいた強化学習)
- ChatGPTはさらに以下の2点が特徴だよ
- GPT-3.5: 2022年初期に学習が終わったモデル
- 会話データ
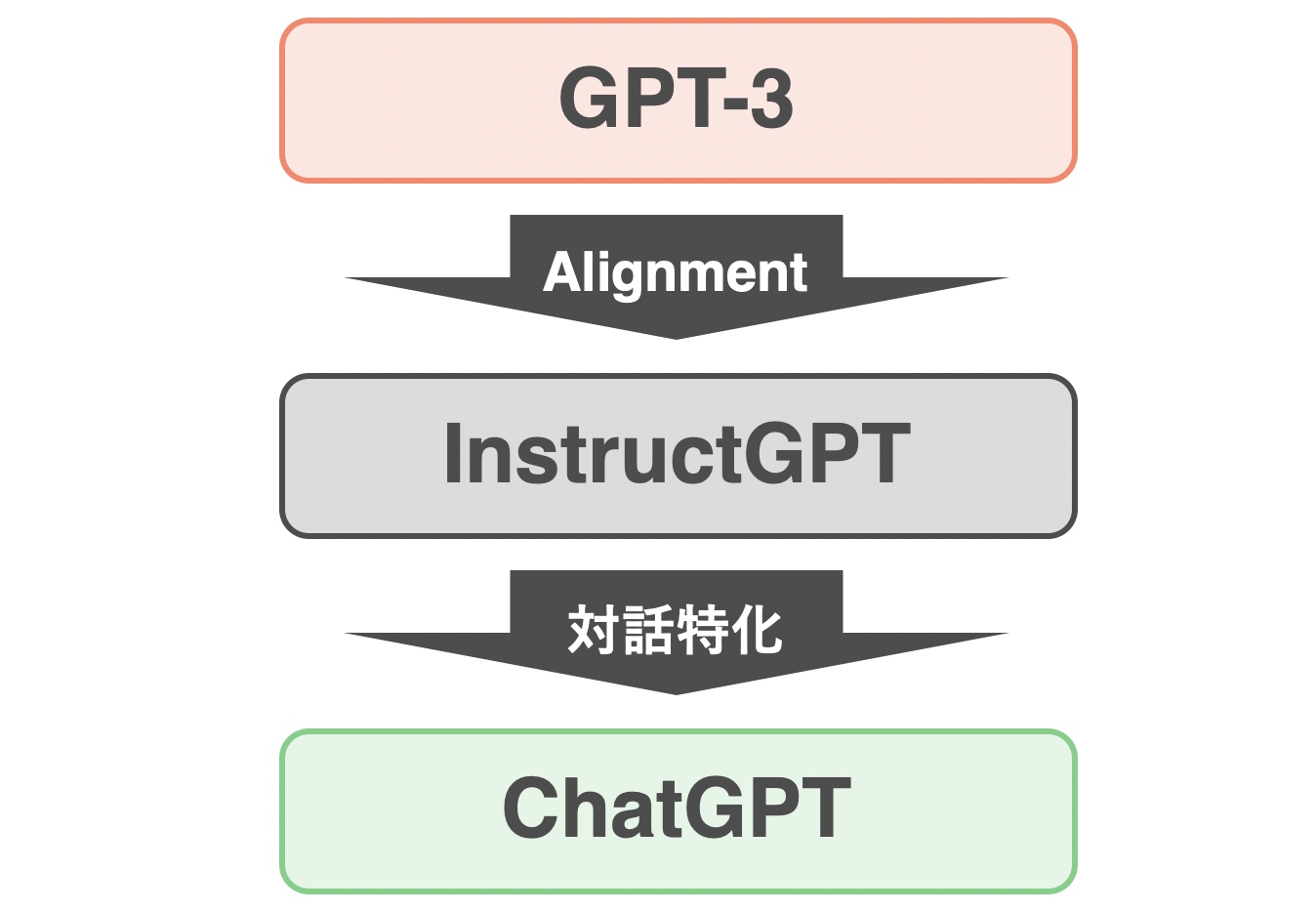
本記事の流れ
1. ChatGPTとは
ChatGPTは、対話をおこなうモデル
2022年12月12日現在、ChatGPTがかなり話題ですね。ChatGPTは、人間のように自然に対話をおこなってくれるAIです。入力にテキストを受け取ると、それに対応するテキストを出力してくれます。使い方によっては、コードを出力させたり、要件定義を出力させたり、さらにはLinuxを埋め込んだりすることもできます。ChatGPTの論文は出ていないため、詳細はまだ不明ですが、ChatGPTの公式記事にはこんな記載があります。
We trained this model using Reinforcement Learning from Human Feedback (RLHF),
using the same methods as InstructGPT,
but with slight differences in the data collection setup.
日本語に訳すと、以下です。
このモデル(=ChatGPT)は、RLHFで学習されている。
学習手法はInstructGPTと同じだが、
データ集めの工程がわずかに異なる。
つまり、InstructGPTの学習手法さえわかれば、ChatGPTもだいたい掴めるということです。本記事では以下の図のような流れで進めます。まずは、GPT-3から説明します。そのあとGPT-3の問題点を対処するために誕生したInstructGPTの仕組みを解説します。そして最後にChatGPTの仕組みについて見ていきます。
本記事の流れ
2. GPT-3
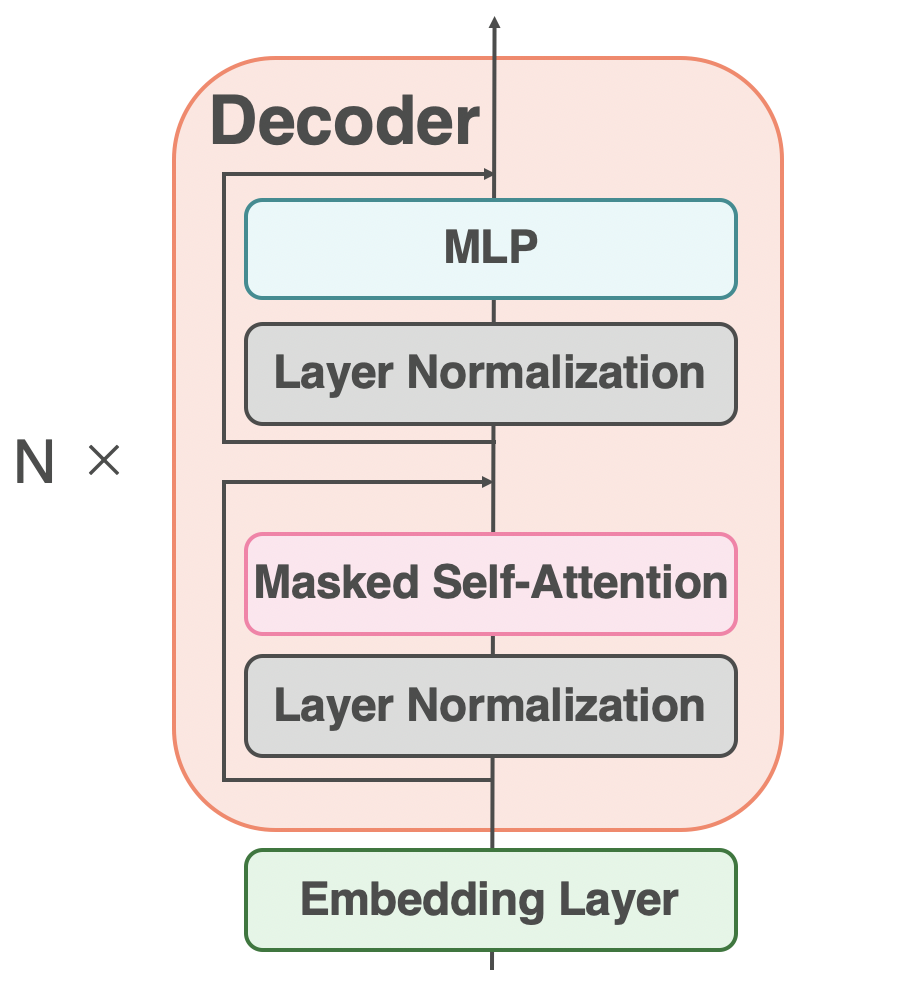
GPT-3の概略図
GPT-3[Brown, T. (NeurIPS'20)]は、TransformerにおけるDecoderのみで構成された言語モデルです。上図のようなDecoder1のモジュールを$N=96$個重ねると、GPT-3となります。言語モデルとは、「入力文に続きそうな単語を出力する」モデルのことです2。たとえば、「日本の首都は東京である」という文があるとします。言語モデルに「日本の首都は」と入力したら、その出力は「東京」となるように学習させます。続けて「日本の首都は東京」と入力したら「である」と出力するように学習させます。この例のように、言語モデルの利点は、「教師なし学習」であるということです。つまり、言語モデルでは人間によるアノテーションが必要にならないので、大量の文さえ集められればあとはそれで大量に学習を回せば、入力文に続く文を予測してくれるモデルが手に入ります。
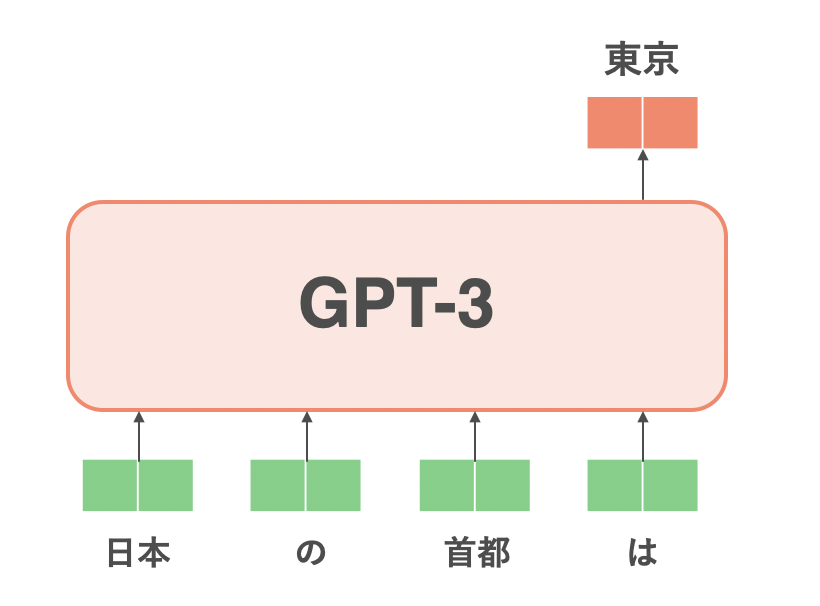
「日本の首都は」に続く単語「東京」を予測する言語モデルの例
GPT-3の特筆すべき点はそのパラメータ数と学習に用いたデータ量です。GPT-3は1,750億個ものパラメータを有し、学習には570GB以上もの文章(コーパス) が使われています。これらの文章はおもにCommon Crawlと呼ばれるデータセットから取ってきています。Common Crawlとは、「インターネット上のありとあらゆる文章をあつめてきたコーパス」であり、2016年から2019年にクローリングされた文章(45TB!)がGPT-3の学習の対象になっています。ただ、Common Crawlは、インターネット上をクローリングしているだけなので学習データとしては汚い文ばかりです。そのため、これをフィルタリングして残った570GBの文たちがGPT-3の学習に用いられています。
GPT-3はその汎用性の高さから大規模言語モデル(Large Language Model, LLM)ブームの火付け役となりましたが、いくつか問題もはらんでいます。そのうちのひとつに、GPT-3が不正確なことや非道徳的な文を出力してしまうという問題があります3。GPT-3はあたかも人間が書いたような文を生成しますが、人間が好む文ばかりを生成してくれるわけではないのです。このことは、GPT-3による生成文が人間の好みとalignして(=一致して)いないと言われます。非道徳的なことを吐かれてしまうと、大規模言語モデルを何かしらのサービスへと組み込む際に問題になってきます。そのため、アラインメント問題を対処しようというモチベーションのもとInstructGPTが誕生しました。
3. InstructGPT
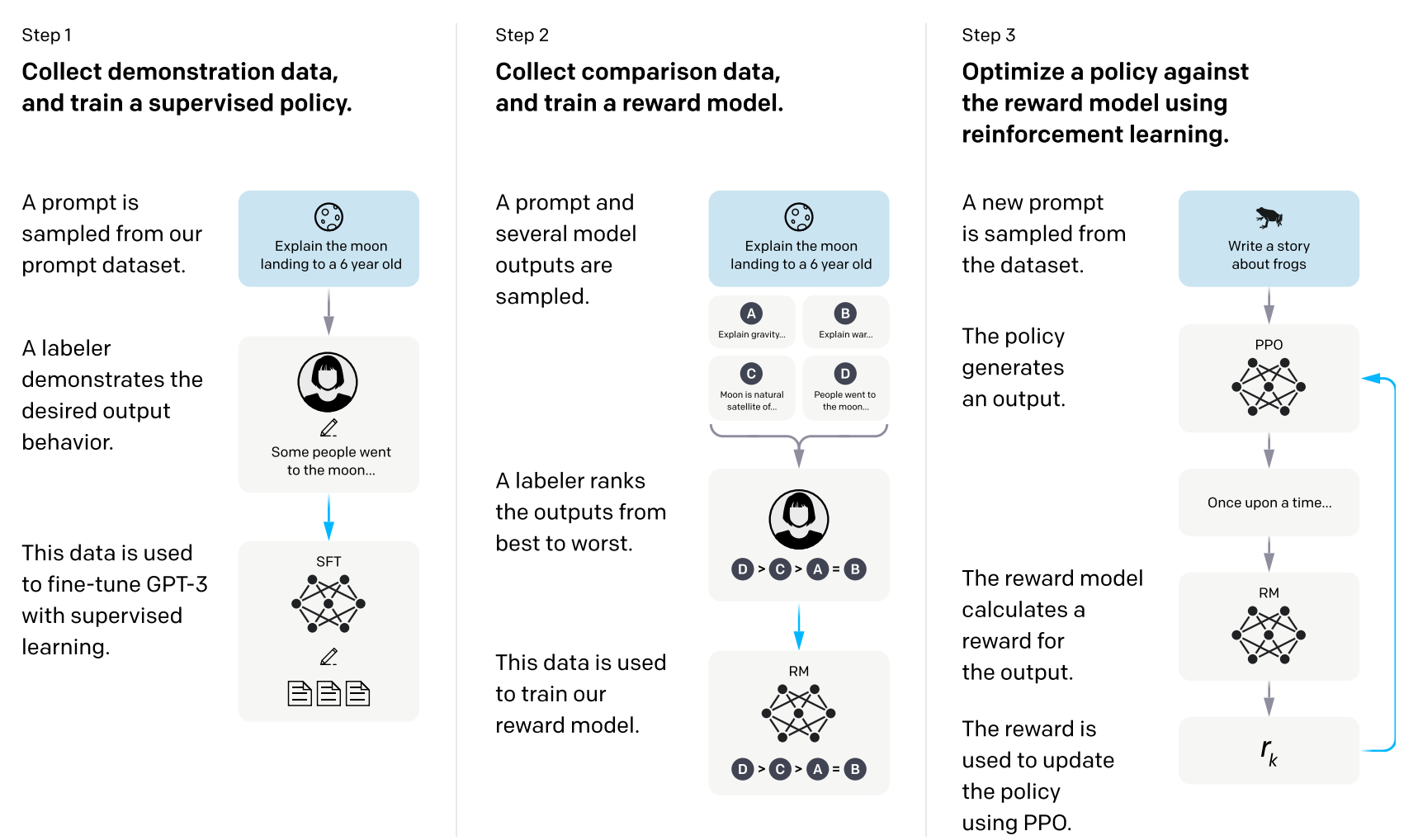
InstructGPTの学習は3ステップで構成される(InstructGPTの論文[Ouyang, L. et al., (2022)]図1)
GPT-3をはじめとした大規模言語モデルには、生成する文が人間が好む文とは異なるという問題がありました。InstructGPT[Ouyang, L. et al., (2022)]ではこのアラインメント問題に立ち向かいます。ただ人間が好む文を大規模言語モデルに生成させたいと言っても、「人間が好む」というのを損失関数などで表現するのは難しそうです。それであれば、人間が判断する「良い悪い」というフィードバックを直接学習に組み込めれば最高です。InstructGPTの最大の特徴は、「人間のフィードバックをもとにモデルを学習させる」ことです。これは、RLHF(=Reinforcement Learning from Human Feedback) という手法を用いることで実現できます。
InstructGPTの学習の流れは、以下のようになっています。
- 教師ありファインチューニング
- Reward Modelの獲得
- RLHF
ステップ3が終わったらふたたびステップ2に戻ってさらに良いReward Modelを手に入れてまたステップ3を行い・・・というふうにループすることが可能です。それではまずステップ1の教師ありファインチューニングを見ていきましょう。
3.1 教師ありファインチューニング
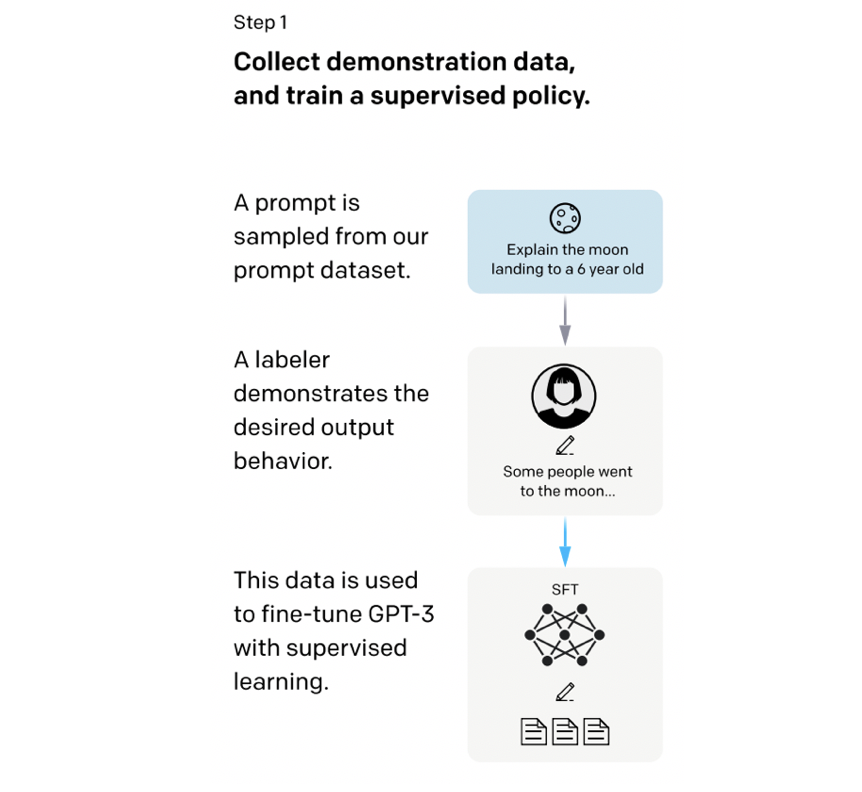
InstructGPTの学習のステップ1(InstructGPTの論文[Ouyang, L. et al., (2022)] Fig.2)
ステップ1では、GPT-3に対して教師ありファインチューニング(Supervised Fine-Tuning, SFT)をします。特に難しいことはなく、純粋な教師あり学習です。このとき、GPT-3の初期値としてすでに教師なし事前学習をおこなったもの(=言語モデル)を用います。GPT-3は前述した通り、インターネット上のありとあらゆる文章で学習されています。このGPT-3を人間の好みにアラインメントさせたいので、人間好みの文章でGPT-3をファインチューニングしてあげます。そのため、訓練済みのラベル付け職人たち(Trained Labeler)が入力プロンプトとそれに対する所望の出力文を用意してあげます4。あとはこのデータでGPT-3をファインチューニングすればステップ1は終わりです。InstructGPTではこのペアを1万3千文ほど用意し教師ありファインチューニングをおこなっています。こうして出来上がったモデルを論文中ではSFTモデルと呼んでいます。そのため、本記事においてもこのステップで学習されたモデルをSFTモデルと呼ぶことにします。
3.2 Reward Modelの学習
ステップ2の目的は、Reward Modelを用意することです。Reward Modelは、人間の代わりに「文の良さ」を評価してくれるモデルになります5。つまり、Reward Modelは入力として文を受け取り、出力として文の良さを表したスコアのようなもの(スカラー)を吐き出します。InstructGPTでは「文の良さ」として次のようなものを評価軸としています。
- Truthfullness(真実性):デマやミスリードの情報ではないか
- Harmlessness(無害性):人や環境を物理的・精神的に傷つけていないか
- Helpfulness(有益性):ユーザーのタスクを解決してくれるか
そして、Reward Modelのアーキテクチャはパラメータ数60億のGPT-3です。また、Reward Modelはあらかじめ質問応答や自然言語推論などの複数のタスクでファインチューニングされています。ただ、Reward Modelにはスカラーを吐き出して欲しいので、GPT-3の単語を出力する最終層6をスカラー値を出力する層に取り替えています。Reward Modelの初期値はSFTモデルを用います。次のステップ3では、このReward Modelを人間の代わりに使いながらInstuctGPTを学習させるイメージです。
つづいて、文の良し悪しを評価してくれるReward Model $r_\theta$の学習方法を見ていきましょう。ここで$\theta$をReward Modelの重みとし、プロンプトを$x$、$x$に対する言語モデル(SFTモデルなど)の出力文を$y$とします。Reward Modelは入力としてプロンプト$x$およびそれに続く$y$を受け取り、出力としてその良し悪しを表したスカラー値$r_\theta (x, y)$を吐き出します7。
それでは、Reward Modelの学習方法としてどういった方法が考えられるでしょうか。一番単純な方法だと、$(x,y)$に対して、人間がその良し悪しを表したスカラーを付与し、その値をReward Modelに当てさせる回帰問題に持っていくことが考えられます。この方法でも良さそうですが、どの文にどのくらいの値をラベル付けしとけば良いかがわかりません。「あの文にはスコア10を付与したからこの文はスコア5にしとくか。いやでもこっちの文をスコア5にするんだったらそっちの文は8にしとくか。あ、でもそうすると・・・」という感じでどの文になんのスコアを与えればいいかよくわかりません。 そのため、InstructGPTではReward Modelにスコアの代わりに文の良し悪しに基づいたランキングを学習させる、という方法を取ります。
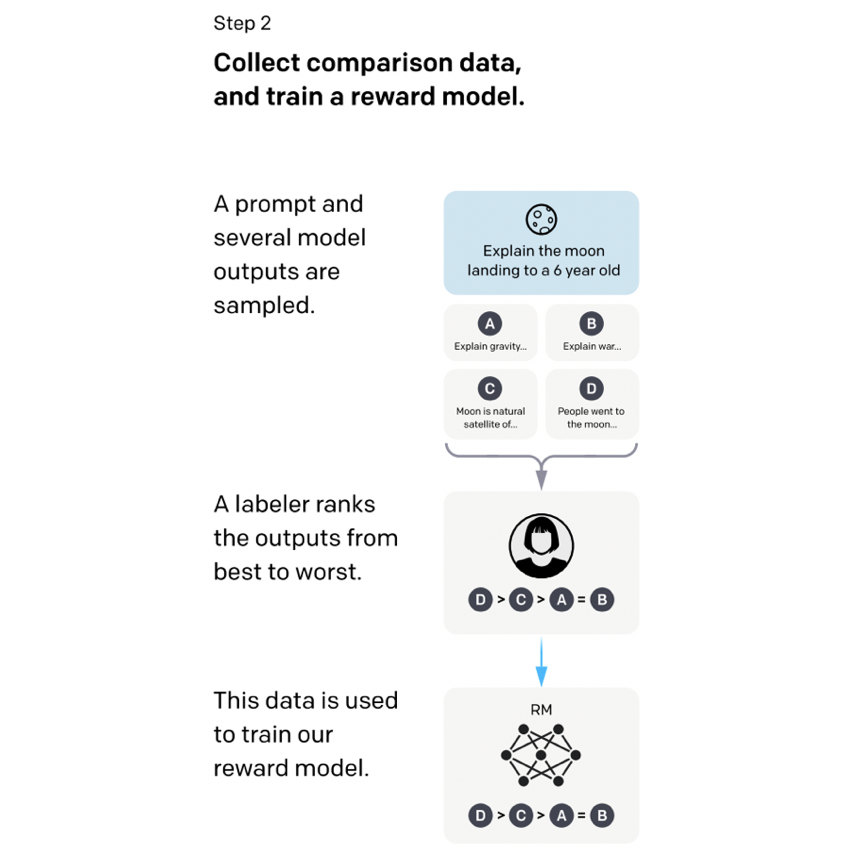
InstructGPTの学習のステップ2(InstructGPTの論文[Ouyang, L. et al., (2022)] Fig.2)
この方法について説明します。大まかな流れは下のようになっています。
- プロンプトに対する複数の出力文を用意
- 人間がランク付け
- ランキングをReward Model(RM)に学習させる
まず、入力プロンプト$x$に対するモデルの出力文を$K$個用意します。$K$は$4\sim 9$の整数値を取ります。ここでは例として$K=4$とし、それぞれの出力文を$y_A, y_B, y_C, y_D$とします。つづいて人間(=訓練済みのラベル付け職人)がこれらの文にランク付けします。たとえば、人間が見たところ、$y_D \gt y_C \gt y_A = y_B$という結果になったとします。あとは、この序列をReward Modelに学習させます。例えば$y_D$と$y_C$の序列をReward Modelに覚えさせるとします。ランキング付けをした人間によると、$y_D$が$y_C$よりも良いので、Reward Modelの出力も$r_\theta(x, y_D) \gt r_\theta(x, y_C)$となって欲しいです。つまり、$r_\theta(x, y_D) - r_\theta(x, y_C)$が最大化されるようにReward Modelを学習させれば良さそうです。これにシグモイド関数$\sigma(\cdot)$および対数を適用しても同様です。あとはこれを損失(=最小化させる対象)にしたいので、全体の負をとって下の式が最小化すべき対象であることがわかります。
- \log (\ \sigma (\ r_\theta(x, y_D)-r_\theta(x, y_C)\ )\ )
ここまでは$y_D$と$y_C$に焦点を当てましたが、同様の損失を$y_A, y_B, y_C, y_D$のすべてのペア${4 \choose 2} = 6$通りに対して定義します。任意のペアにおいてランキングが高い方を$y_w$、ランキングが低い方を$y_l$とします。$y_C$と$y_D$のペアの例では$y_w=y_D$、$y_l=y_C$となります。あとは、$y_w, y_l$を用いて上式の期待値(=平均値)をとるだけです。$\mathcal{D}$は人間によってランキング付けされたデータになります。
-\frac{1}{6} \mathbb{E}_{(x, y_w, y_l)\sim \mathcal{D} }[\log (\ \sigma (\ r_\theta(x, y_w)-r_\theta(x, y_l)\ )\ )]
最後に、この関数を任意の$K$に対応させたいので、最終的な損失関数は以下の式になります。これがまさにReward Modelの損失関数になります。
\begin{align}
\text{loss}(\theta) := -\frac{1}{K \choose 2} \mathbb{E}_{(x, y_w, y_l)\sim \mathcal{D} }[\log (\ \sigma (\ r_\theta(x, y_w)-r_\theta(x, y_l)\ )\ )]
\end{align}
これによって、人間のフィードバック(=文の良さ)をスカラーで出力してくれるReward Modelが獲得できました。ちなみに、ステップでは3万3千文のプロンプトを用いています。次のステップでは、獲得したReward Modelを最大化するように言語モデルを学習させていきます。
3.3 Renfiorcement Learning from Human Feedback
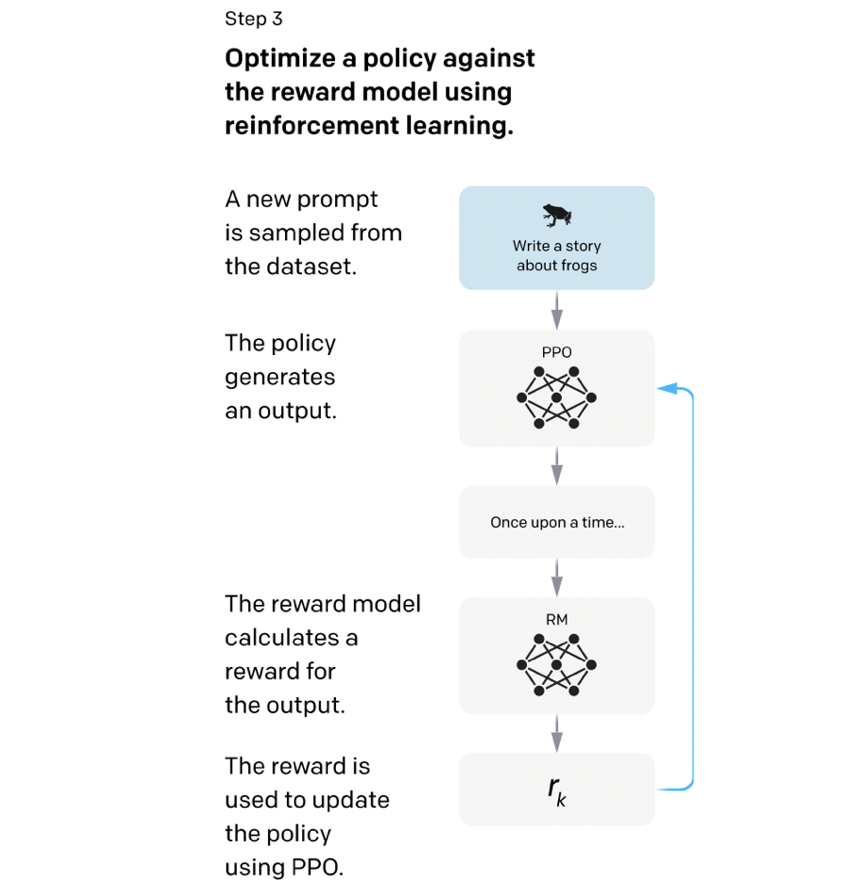
InstructGPTの学習のステップ3(InstructGPTの論文[Ouyang, L. et al., (2022)] Fig.2)
強化学習を用いてSFTモデルを人間好みにしていきます。仕組みは非常に単純で、前ステップで獲得したReward Modelを最大化するようにSFTモデルを学習させます。強化学習の枠組みでSFTモデルをファインチューニングするので、学習対象のSFTモデルをPolicyと呼びます(上図のPPOと書かれたモデル)。学習アルゴリズムには、OpenAIの伝家の宝刀、PPO(Proximal Policy Optimization)[Schulman, J. (2017)]を用います。PPOは、ポリシーの大きな更新を抑えながら最適化していくような手法で、その安定性から強化学習ではかなり幅広く用いられています8。
それではPPOを通して最大化していく目的関数についてです。最初は単純なものから始めて徐々にInstructGPTで用いられている目的関数を完成させていきます。まずは、RLHFの一番の目的である「Reward Modelの出力の最大化」についてです。学習対象であるPolicyを$\pi_\phi^\text{RL}$とすると、Reward Model $r_\theta$を最大化すればいいので以下のように書けます。
\mathbb{E}_{(x,y)\sim \mathcal{D}_{ \pi_\phi^\text{RL} } }[r_\theta(x,y)]
これによってReward Modelの出力の最大化は実現できていますが、これだけでは問題があります。それは、PolicyがReward Modelをハックするような文を出してしまう、という問題です。上述の目的関数だけだと、Reward Modelの値さえ最大化してしまえば良いです。そのため、Policyの出力がはちゃめちゃな文になってしまう可能性があります9。そこで、Policyの出力文が、元々のSFTの出力文から大きく変化しすぎないように、KL正則化項を追加します。KLダイバージェンスは2つの確率分布間の距離(的なもの)を測ってくれるものであり、2つの確率分布が異なっていると値が大きくなります。SFTを$\pi^\text{SFT}$、KL正則化項の係数を$\beta$とすると、KL項を組み込んだ目的関数は下の式のように書けます。ここでInstructGPTでは$\beta=0.02$を用いており、SFTは固定されています。期待値$\mathbb{E}[\cdot]$内の$\log \left( \pi_{\phi}^\text{RL}(y|x)/\pi^\text{SFT}(y|x) \right)$がKL項になります。このKL項が大きくなってしまうと、その分Reward Modelから引き算されてしまうので、全体の値が小さくなってしまうことがわかります。そのため、Policyの学習は、KL項をなるべく小さく抑えたまま(=PolicyとSFTの出力をなるべく同じようにしたまま)進んでいくことがわかります。10
\begin{align}
\text{objective}_\text{PPO}(\phi) := \mathbb{E}_{(x,y)\sim \mathcal{D}_{ \pi_\phi^\text{RL} } }\left[ r_\theta(x,y) - \beta \log \left( \frac{\pi_{\phi}^\text{RL}(y|x)}{\pi^\text{SFT}(y|x)} \right) \right]
\end{align}
目的関数にKL項を追加する、というのは[Jaques, N. (2019)]や[Stiennon, N. (NeurIPS'20)]ですでに使われていました。InstructGPTではさらに、言語モデルの対数尤度を表す項も追加しています。これは$\text{objective}_\text{PPO}(\phi)$で学習したモデルがNLPのベンチマークに対しての性能が劣化してしまったことに起因しています。このように、Policyの汎化性能が低下するのを避けるために対数尤度が目的関数に追加されています11。よって、InstructGPTのステップ3における最終的な目的関数は以下の式になります。$\mathcal{D}_{\text{pretrain} }$は、GPT-3の事前学習に使われたデータセットからサンプリングされたデータです。また、$\gamma=27.8$であり、割と大きな値が設定されています。
\begin{align}
\text{objective}_\text{PPO-ptx}(\phi) :=
&\mathbb{E}_{(x,y)\sim \mathcal{D}_{ \pi_\phi^\text{RL} } }\left[ r_\theta(x,y) - \beta \log \left( \frac{\pi_{\phi}^\text{RL}(y|x)}{\pi^\text{SFT}(y|x)} \right) \right] \nonumber \\
&+ \gamma\mathbb{E}_{x\sim\mathcal{D}_{\text{pretrain} } }\left[\log (\pi_\phi^\text{RL}(x))\right]
\end{align}
ステップ3が終わったらまたステップ2に戻って再びReward Modelを獲得します。これを繰り返すことでさらに良い言語モデルが手に入ります。ステップ3では3万1千文のプロンプトが使用されています。こうして得られたInstructGPTの出力文が本当に人間に好まれる文なのかどうか、その実験結果を見ていきましょう。
3.4 InstructGPTの実験結果
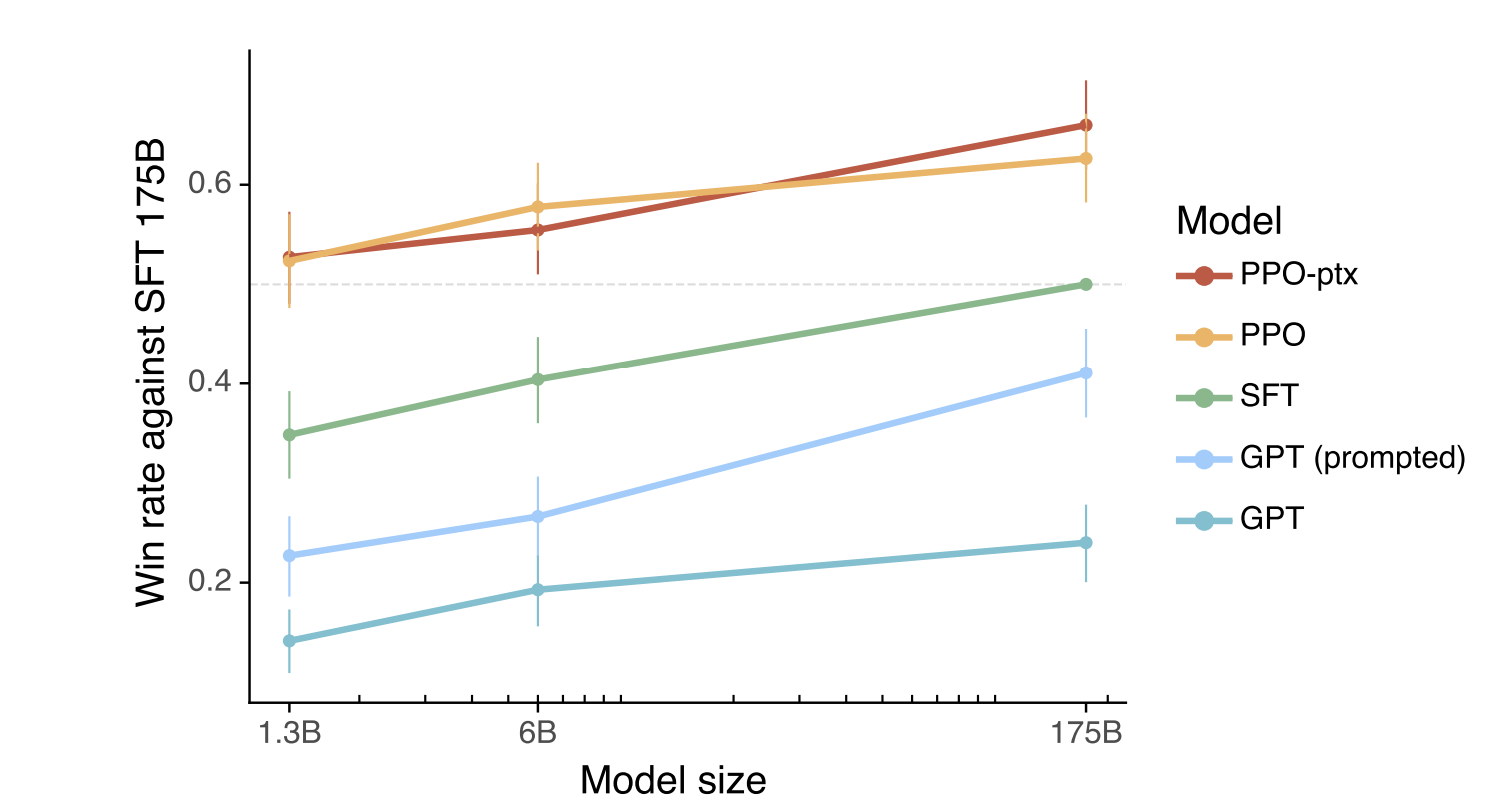
InstructGPTの実験結果(InstructGPTの論文[Ouyang, L. et al., (2022)] Fig.2)
それでは、InstructGPTの実験結果を見てみましょう。まず評価方法について説明します。メトリクスを設定するのは難しいので、人間に直接評価をしてもらいます。このとき、評価する人には2つのモデルの出力を提示し、どちらがより好ましいかというのを選んでもらいます。このとき2つのうち1つは1,750億パラメータのSFTで固定しているため、これはいわば「1,750億パラメータのSFTとの一騎討ち」となっています。上図の縦軸が一騎討ちの勝率、横軸がモデルのサイズ(10億、60億、1,750億)を表しています。モデルとしては、GPT、Few-shotを行ったGPT、SFTモデル、PPOモデル、PPO-ptxモデルを比較しています。基準となる1,750億パラメータのSFTは勝率が0.5となっています。この結果から、13億パラメータのPPO-ptx(およびPPO)が1,750億パラメータのGPTよりもはるかに人間好みの文を出力していることがわかります。また、SFTモデルよりもPPOモデルの勝率が高いことから、アラインメント問題の解決においてRLHFがかなり効果的であることがわかります。
4. ChatGPT
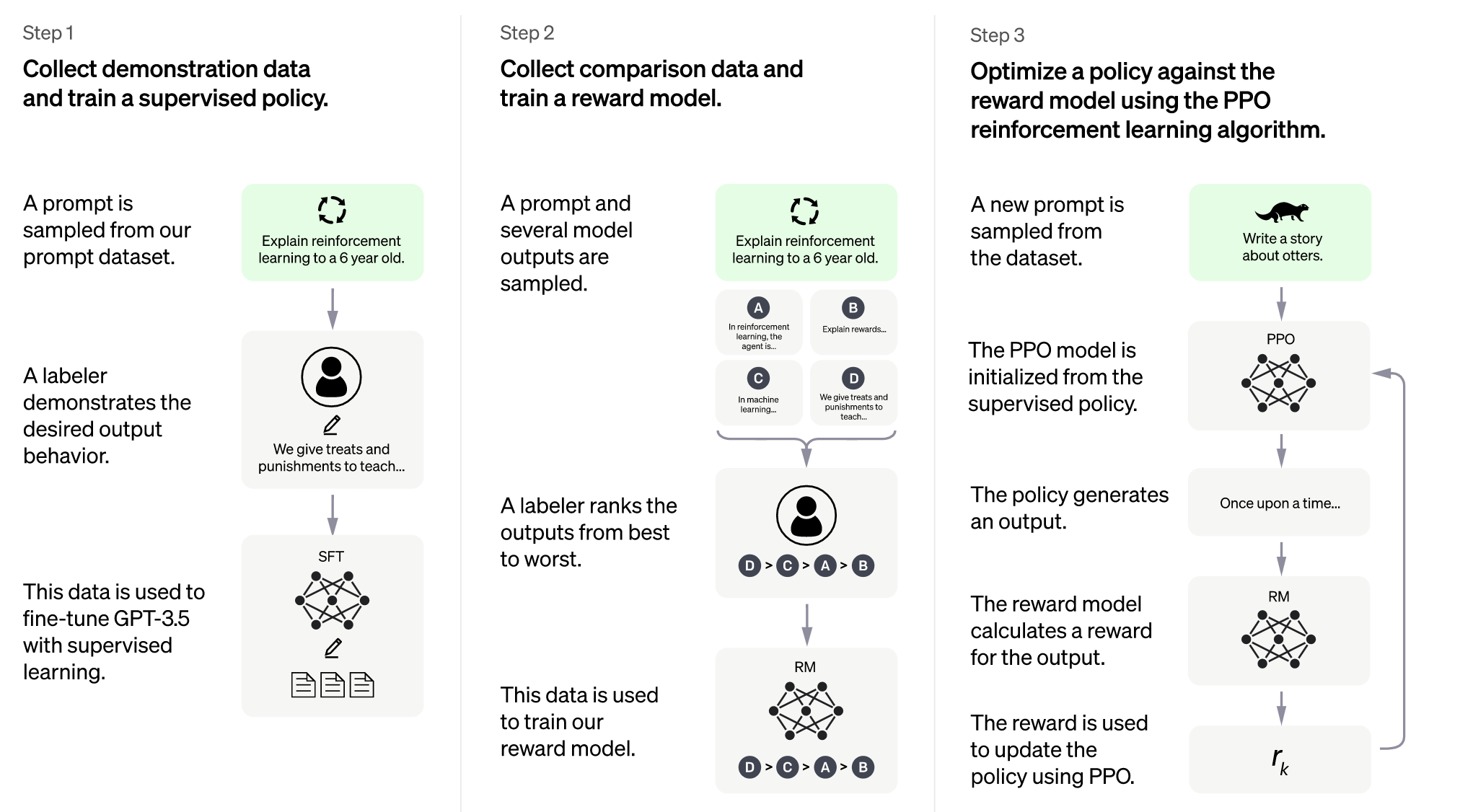
ChatGPTの学習方法。InstructGPTの学習方法とほぼ同じであることがわかる。(ChatGPTのブログ記事より)
上図の学習方法を見てもChatGPTはInstructGPTとほとんど同じであることがわかります。このことから、ChatGPTは対話特化型InstructGPTと言ってもいいかもしれません。ブログ記事で言及されている、ChatGPTとInstructGPTの違いは大きく以下の2点です。
- モデル:GPT-3.5
- データ:会話データ
まず、GPT-3.5についてです。ブログ記事によると、ChatGPTで用いているGPT-3.5とは2022年の始めごろに学習が終了したモデルのことを指しているようです。また、公式のドキュメントによると、GPT-3.5の学習データにはテキストだけでなく、コードも含まれていそうなことがわかります。
続いて会話データについてです。ブログ記事によると、人間が「ユーザーとAI同士の会話」というデータを作っているようです。InstructGPTではここがただのプロンプトとその出力ということだったので、ChatGPTで対話に特化していることがわかります。学習の流れはInstructGPTと同様で、①会話データによるSFTモデルの学習、②SFTモデルの出力を人がランク付けしReward Modelを学習、③Reward Modelを最大化するようにSFTモデルをPPOでファインチューニング、の3ステップになっています。プロンプトの形式(会話をすべてプロンプトとして入力しているかどうか)やステップ3の目的関数への正則化項など、細かい箇所は今後出てくるであろう論文を楽しみに待ちましょう!
5. まとめと所感
本記事では、GPT-3からInstructGPTそしてChatGPTまでの流れを見てきました。GPT-3によって自然な文は出力できるものの人間の好みとはずれてしまう「アラインメント問題」が生じることを言及しました。この問題を解決するために登場したInstructGPTでは、RLHFを通してうまく「ヒトのフィードバック」を元にしたファインチューニングをおこなっていました。そしてInstructGPTをさらに対話特化にすることで、ChatGPTが誕生しています。RLHFのさらなる発展が気になりますね。ChatGPTは、2022年12月12日現在であれば無料で使い放題なのでぜひ使ってみてください!
Twitterで人工知能のことや他媒体の記事などを紹介していますので@omiita_atiimoもご覧ください。
6. 参考
-
ChatGPT: Optimizing Language Models for Dialogue
- ChatGPTのブログ記事
-
ChatGPT
- ChatGPTのデモサイト(無料、12/12/2022 時点)
-
"Language Models are Few-Shot Learners" (Brown, T. et al., NeurIPS'20)
- GPT-3の論文
-
"Training language models to follow instructions with human feedback" (Ouyang, L. et al., 2022)
- InstructGPTの論文
-
Illustrating Reinforcement Learning from Human Feedback (RLHF)
- Hugging Faceから出ているRLHFに関してのブログ記事。非常にわかりやすいです。
-
"Proximal Policy Optimization Algorithms" (Schulman, J. et al., 2017)
- PPOの論文
-
ChatGPTはどのように学習を行なっているのか
- ChatGPTの学習についての日本語記事。
-
Decoderの特徴は、Masked Self-Attentionを用いている点です。各単語が自分および自分より左にある単語のみ見れるSelf-Attentionのことです。 ↩
-
初代GPTもGPT-2も言語モデルです。 ↩
-
本記事では取り扱いませんが、大規模言語モデルは大量の学習が必要となるため、学習時の「CO2排出問題」などもあります。 ↩
-
ちなみに、Trained Labelerはあらかじめスクリーニングテストを通過した40人が雇われています。スクリーニングテストでは、「とある文に危険性があるかどうか」などを判断させるタスクが用いられたようです。 ↩
-
人間の代わりにアノテーションを行っているように捉えてもいいのかもしれないです。 ↩
-
InstructGPTの論文中では、置き換える前の層のことを「unembedding layer」と呼んでいます。 ↩
-
論文中では言及がありませんが、Reward Modelへの入力の形はおそらく$x$と$y$を結合させた文$[x;y]$かと思われます。 ↩
-
PPOの解説記事はこちらがわかりやすかったです。https://horomary.hatenablog.com/entry/2020/10/18/225833 ↩
-
たとえば「happy funny pleasant yay」みたいな耳障りの良い単語を羅列しただけの文がReward Modelで高いスコアになってしまうのかな、と予想しています。 ↩
-
InstructGPTの論文中では、$\text{objective}\text{PPO}(\phi)$で学習したPolicyを"PPOモデル"、$\text{objective}\text{PPO-ptx}(\phi)$で学習したPolicyを"PPO-ptxモデル"と呼んでいます。 ↩
-
InstructGPTの論文中では、この汎化性能の劣化のことを"alignment tax(アラインメント税)"と呼んでいます。 ↩