オミータです。ツイッターで人工知能のことや他媒体で書いている記事など を紹介していますので、人工知能のことをもっと知りたい方などは気軽に@omiita_atiimoをフォローしてください!
1. 教えてはいるが、説明はしていない
安倍首相の 「募ってはいるが、募集はしていない」 という発言にインスパイアされて、入力された文を「募ってはいるが、募集はしていない」な文に自動で変換してくれるプログラムを作りました!
「人を募る」と入力すると「人を募ってはいるが、募集はしていない」という文章に変換してくれます。
桜を見る例
$ python abe.py "桜を見る"
桜を見てはいるが、拝見はしていない
2. 使ってはいるが、使用はしていない
| 使ったもの | 用途 |
|---|---|
| Python 3.7.0 | コード |
| COTOHA API | 形態素解析および類似度計算 |
| WordNet | 類義語 |
| IPA辞書 | 動詞活用形 |
3. 仕組みについて詳しく教えてはいるが、詳解はしていない

3.1 名詞と動詞を抽出

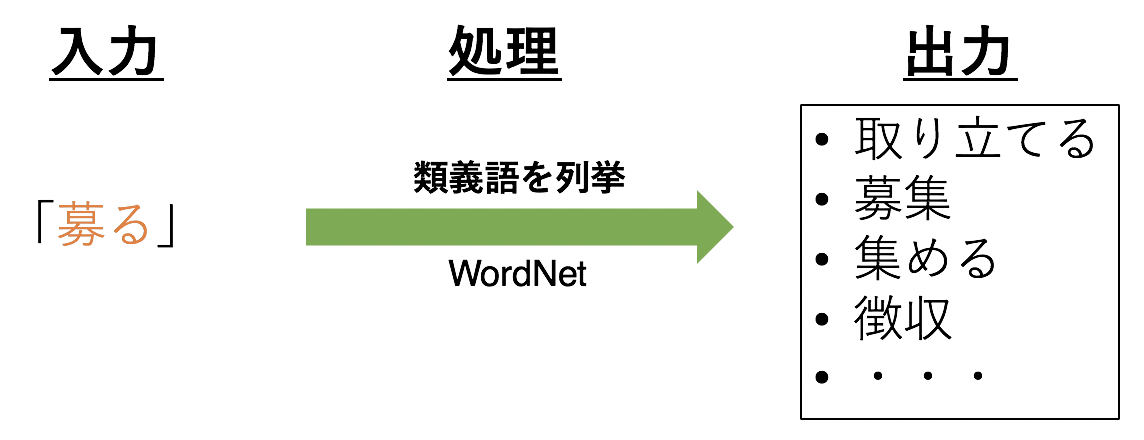
3.2 類義語を列挙
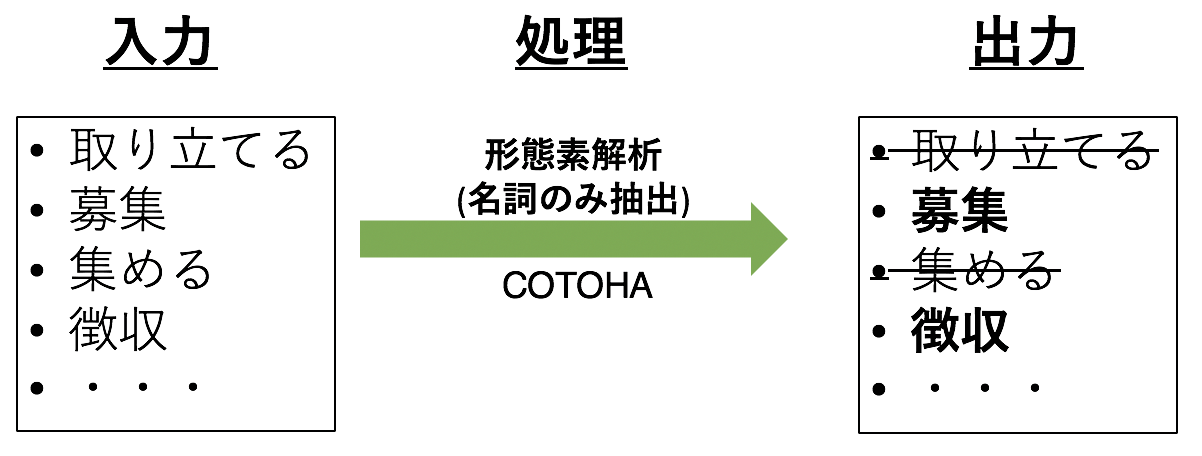
3.3 名詞のみを抽出
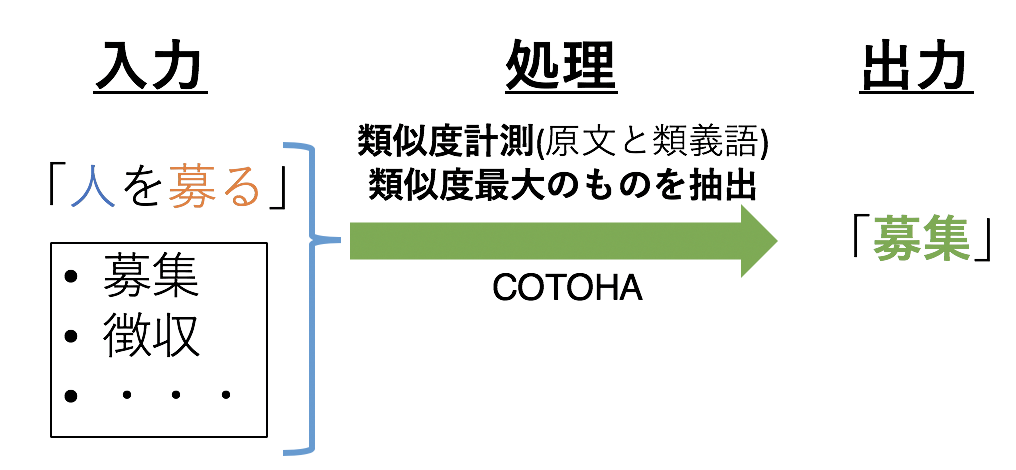
3.4 原文と類義語の類似度計測
3.5 連用タ接続へ変換

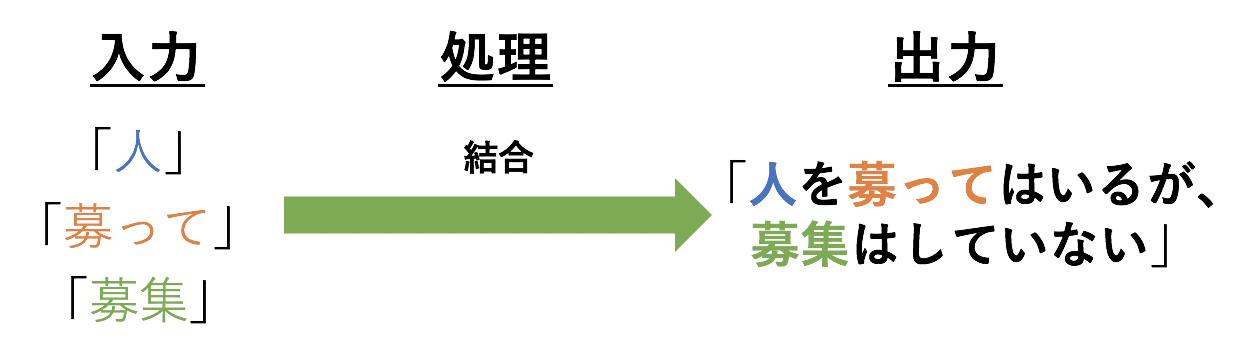
3.6 結合
4. コードを示しているが、表示はしていない
コード(クリック)
Import
abe.py
# -*- coding:utf-8 -*-
import os
import urllib.request
import json
import configparser
import codecs
import csv
import sys
import sqlite3
from collections import namedtuple
import types
COTOHA
abe.py
# /_/_/_/_/_/_/_/_/_/_/_/_/COTOHA_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
# ここの部分のコードはこちらから取ってきています。
# https://qiita.com/gossy5454/items/83072418fb0c5f3e269f
class CotohaApi:
# 初期化
def __init__(self, client_id, client_secret, developer_api_base_url, access_token_publish_url):
self.client_id = client_id
self.client_secret = client_secret
self.developer_api_base_url = developer_api_base_url
self.access_token_publish_url = access_token_publish_url
self.getAccessToken()
# アクセストークン取得
def getAccessToken(self):
# アクセストークン取得URL指定
url = self.access_token_publish_url
# ヘッダ指定
headers={
"Content-Type": "application/json;charset=UTF-8"
}
# リクエストボディ指定
data = {
"grantType": "client_credentials",
"clientId": self.client_id,
"clientSecret": self.client_secret
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
res = urllib.request.urlopen(req)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディからアクセストークンを取得
self.access_token = res_body["access_token"]
# 構文解析API
def parse(self, sentence):
# 構文解析API URL指定
url = self.developer_api_base_url + "v1/parse"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"sentence": sentence
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
# 類似度算出API
def similarity(self, s1, s2):
# 類似度算出API URL指定
url = self.developer_api_base_url + "v1/similarity"
# ヘッダ指定
headers={
"Authorization": "Bearer " + self.access_token,
"Content-Type": "application/json;charset=UTF-8",
}
# リクエストボディ指定
data = {
"s1": s1,
"s2": s2
}
# リクエストボディ指定をJSONにエンコード
data = json.dumps(data).encode()
# リクエスト生成
req = urllib.request.Request(url, data, headers)
# リクエストを送信し、レスポンスを受信
try:
res = urllib.request.urlopen(req)
# リクエストでエラーが発生した場合の処理
except urllib.request.HTTPError as e:
# ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト
if e.code == 401:
print ("get access token")
self.access_token = getAccessToken(self.client_id, self.client_secret)
headers["Authorization"] = "Bearer " + self.access_token
req = urllib.request.Request(url, data, headers)
res = urllib.request.urlopen(req)
# 401以外のエラーなら原因を表示
else:
print ("<Error> " + e.reason)
# レスポンスボディ取得
res_body = res.read()
# レスポンスボディをJSONからデコード
res_body = json.loads(res_body)
# レスポンスボディから解析結果を取得
return res_body
連用タ接続に変換
abe.py
# /_/_/_/_/_/_/_/_/_/_/_/_/CONVERSION_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
def convert(word):
file_name = "./data/Verb.csv"
with open(file_name,"r") as f:
handler = csv.reader(f)
for row in handler:
if word == row[10]: #品詞発見
if "連用タ接続" in row[9]: #活用発見
return row[0]
return None
類義語
abe.py
# /_/_/_/_/_/_/_/_/_/_/_/_/SYNONYM_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
# ここの部分のコードはこちらから取ってきています。
# https://www.yoheim.net/blog.php?q=20160201
conn = sqlite3.connect("./data/wnjpn.db")
Word = namedtuple('Word', 'wordid lang lemma pron pos')
def getWords(lemma):
cur = conn.execute("select * from word where lemma=?", (lemma,))
return [Word(*row) for row in cur]
Sense = namedtuple('Sense', 'synset wordid lang rank lexid freq src')
def getSenses(word):
cur = conn.execute("select * from sense where wordid=?", (word.wordid,))
return [Sense(*row) for row in cur]
Synset = namedtuple('Synset', 'synset pos name src')
def getSynset(synset):
cur = conn.execute("select * from synset where synset=?", (synset,))
return Synset(*cur.fetchone())
def getWordsFromSynset(synset, lang):
cur = conn.execute("select word.* from sense, word where synset=? and word.lang=? and sense.wordid = word.wordid;", (synset,lang))
return [Word(*row) for row in cur]
def getWordsFromSenses(sense, lang="jpn"):
synonym = {}
for s in sense:
lemmas = []
syns = getWordsFromSynset(s.synset, lang)
for sy in syns:
lemmas.append(sy.lemma)
synonym[getSynset(s.synset).name] = lemmas
return synonym
def getSynonym (word):
synonym = {}
words = getWords(word)
if words:
for w in words:
sense = getSenses(w)
s = getWordsFromSenses(sense)
synonym = dict(list(synonym.items()) + list(s.items()))
return synonym
Main
abe.py
# /_/_/_/_/_/_/_/_/_/_/_/_/MAIN_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/
if __name__ == '__main__':
# ソースファイルの場所取得
APP_ROOT = os.path.dirname(os.path.abspath( __file__)) + "/"
# 設定値取得
config = configparser.ConfigParser()
config.read(APP_ROOT + "config.ini")
CLIENT_ID = config.get("COTOHA API", "Developer Client id")
CLIENT_SECRET = config.get("COTOHA API", "Developer Client secret")
DEVELOPER_API_BASE_URL = config.get("COTOHA API", "Developer API Base URL")
ACCESS_TOKEN_PUBLISH_URL = config.get("COTOHA API", "Access Token Publish URL")
# COTOHA APIインスタンス生成
cotoha_api = CotohaApi(CLIENT_ID, CLIENT_SECRET, DEVELOPER_API_BASE_URL, ACCESS_TOKEN_PUBLISH_URL)
# 解析対象文
if len(sys.argv) >= 2:
sentence = sys.argv[1]
else:
raise TypeError
# 元の文から動詞をとって連用形タ接続に変換
result = cotoha_api.parse(sentence)
ret = ""
verb = ""
for chunk in result["result"]:
for token in chunk["tokens"]:
if token["pos"] == "動詞語幹":
verb = token["lemma"]
form = token["form"]
conv_verb = convert(verb)
if conv_verb==None:
ret += form
else:
ret += conv_verb
if ret[-1] == "ん":
ret += "ではいるが、"
else:
ret += "てはいるが、"
break
else:
ret += token["form"]
# 動詞の類義語をとる
synonym = getSynonym(verb)
noun = ""
sim = 0.
# 一番似ている名詞の類義語を抽出する
for syns in synonym.values():
for syn in syns:
result = cotoha_api.parse(syn)['result'][0]['tokens'][0]
if result['pos'] == '名詞':
cand = result['form']
cand_sim = cotoha_api.similarity(sentence, cand+'する')['result']['score']
if cand_sim > sim:
noun = result['form']
sim = cand_sim
ret += noun
ret += "はしていない"
# 最終出力
print(ret)
config.ini
config.ini
# COTOHA APIを使うためにCOTOHA APIに登録してIDとSECRETを取得し、
# config.iniファイルを作成する必要があります。
# https://api.ce-cotoha.com/contents/index.html
[COTOHA API]
Developer API Base URL: https://api.ce-cotoha.com/api/dev/nlp/
Developer Client id: IDIDIDIDIDIDIDIDIDIDIDIDIDIDIDI
Developer Client secret: SECRETSECRETSECRETSECRET
Access Token Publish URL: https://api.ce-cotoha.com/v1/oauth/accesstokens
5. 試してはいるが、試行はしていない
$ python abe.py "お酒を飲む"
お酒を飲んではいるが、飲酒はしていない
$ python abe.py "家に帰る"
家に帰ってはいるが、帰宅はしていない
$ python abe.py "桜を見る"
桜を見てはいるが、拝見はしていない
$ python abe.py "おすしを食べる"
おすしを食べてはいるが、食事はしていない
$ python abe.py "前夜祭に招く"
前夜祭に招いてはいるが、招来はしていない
**その他試したもの**(クリック)
$ python abe.py "ホテルに泊まる"
ホテルに泊まってはいるが、宿泊はしていない
$ python abe.py "質問に答える"
質問に答えてはいるが、返答はしていない
$ python abe.py "夜は寝る"
夜は寝てはいるが、就寝はしていない
$ python abe.py "外を歩く"
外を歩いてはいるが、散策はしていない
$ python abe.py "ネットを見る"
ネットを見てはいるが、チェックはしていない
$ python abe.py "肉を買う"
肉を買ってはいるが、購入はしていない
$ python abe.py "火を焚く"
火を焚いてはいるが、燃焼はしていない
6. <番外編>小泉進次郎構文
小泉進次郎氏の 「反省をしていると申し上げましたが、反省しているんです。」 という発言にインスパイアされて、入力された文を小泉進次郎構文に自動で変換してくれるプログラムを作りました!
上記までのものを安倍晋三構文 と呼ぶことにすると、安倍晋三構文では「肯定文+類似の否定文」とかけます。

一方で 小泉進次郎構文は単に「肯定文+類似の肯定文」 となっており、安倍晋三構文と似ていると申し上げましたが、類似しているんです。(手順3.6の結合のやり方を変えているだけです。)

6.1 試していると申し上げましたが、試行しているんです
$ python sexy.py '約束を守る'
約束を守っていると申し上げましたが、遵守しているんです。
$ python sexy.py '外国人をもてなす'
外国人をもてなしていると申し上げましたが、歓迎しているんです。
$ python sexy.py '会社を休む'
会社を休んでいると申し上げましたが、静養しているんです。
$ python sexy.py '環境問題に取り組む'
環境問題に取り組んでいると申し上げましたが、直面しているんです。
$ python sexy.py 'NHKをぶっ壊す'
nhkをぶっ壊していると申し上げましたが、破壊しているんです。
7. まとめてはいるが、要約はしていない
ある文を「募ってはいるが、募集はしていない」な文に自動で変換してくれるプログラムを作りました!
「いいね」や「コメント」 を募ってはいますが、募集はしていません。
(出力がどうなるか気になる文章があれば試しますので気軽にコメントしてください!)