神エクセルシリーズでたまに出てくる
昔ネタにしたこれの対応について書いていきたいと思う
https://wmfexcel.com/2019/05/13/split-cell-contents-separated-by-line-feed-into-rows-with-excel-powerquery-part-2/#more-16516
ポイントとして
列の分割のような処理は列名指定が必要でそのままだと列が多いと処理数も増え、
列数不定なデータだと対応が困難です
これを列数制限の受けにくい「ピボット解除」と「列のピボット化」を前後に使い
処理列を1列に並べ処理し復旧するという処理をします
対象
このように,セル中に個別に区切りで分けられた複数のデータが入って
複数回繰り返した場合、どのように処理していくかという話

元データ
itemとvalueが連続したデータを
| item | value | item2 | value3 |
|---|---|---|---|
| aaaa/bb/cc | 11/22/333 | dd/hh | 77/44 |
| dd/ee | 44/55 | ff/qq | 11 |
| ff/g | 66 | ss/rr | 22/33 |
| ee | 7 | nn/pp/cc | 55/99 |
| aaa/bbbb/cc | 74/35 |
①インデックス列の追加

目的は最終段のピボット化で
- 元行番号
- セル内区切り位置
で仕分けるためここで元行番号を追加します
これがないと8手目でエラーが出ます
②ピボット解除
インデックスを選択した状態で「その他の列をピボット解除」

解除列を選択してピボット解除も非選択列を使って「その他の列を~」
というコードが生成されるのでどちらでもよい、
目的が明確なので「その他の~」を使用
行追加時にピボット解除から外したい場合は
「選択した列のみピボット解除」を選択する必要がある
③列の分割
列分割で文字と数字を分割。列マージのヘッダに使います

④列分割
値列を「/」で列分割
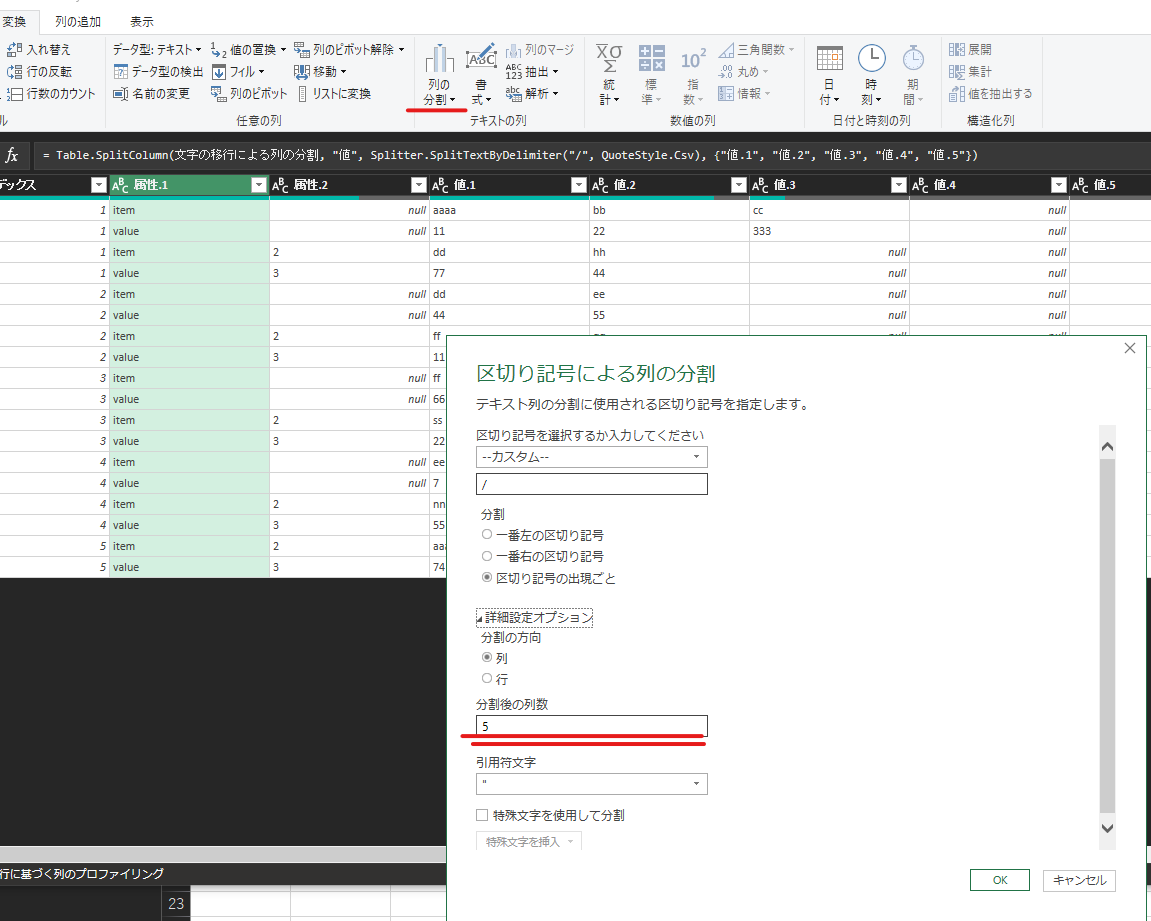
ここで列で分割を列方向指定で分割するのが今回のキモ
ヘッダの重複した列はUIが自動的に連番振ってくれるのでセル内の区切り位置記号として再利用します
分割数は大目に選択すると大きなデータが入った時消えないので推奨
使われない列は⑦のピボット解除で消えます
⑤整数除算
[属性.2]列に対して整数除算


今回のデータだと2を選択
Power Queryでヘッダ付けにしたものは1から始まるので
前段に加算で+1をつけること
⑥列マージ
元列順に合わせるために
属性.1と属性.2を列マージ

⑦ピボット解除
列マージをした行を選択し2段目のピボット解除

⑧列のピボット
⑥でできたマージ列を選択して
値列:値、詳細オプション:集計しない
で実施
値列の選択を変えると、詳細オプションの内容が変わるので注意

この後不要列を削除して終了
全クエリ(元データ入り)
詳細エディタにコピーしてください。たぶん動きます
let
// 元データ取り出し部
ソース = "VZDJDoMwDET/xWckKxsR/ZW6B5ZQKqWIpfRS8e91SkEmt0xmnuO5fuDxCk+4QMmHsKoI6xoyeJdxCSwrRag1oTGG1eTVrDYNYdftNsOK94TWwpodwOQJQaCsJXROUNqWcBwlRSlJSO93AchzEZ5nwmmS4e2bEnAa70W47wmHQa6aAM4RFoUA9EuMB2C77IR/W+e+fkXwlsbBevsC",
a1 = Binary.FromText(ソース),
a2 = Binary.Decompress(a1,Compression.Deflate),
a3= Table.FromRecords(Json.Document(a2,932)),
//
// ここから処理
//
追加されたインデックス = Table.AddIndexColumn(a3, "インデックス", 1, 1),
ピボット解除された他の列 = Table.UnpivotOtherColumns(追加されたインデックス, {"インデックス"}, "属性", "値"),
文字の移行による列の分割 = Table.SplitColumn(ピボット解除された他の列, "属性", Splitter.SplitTextByCharacterTransition((c) => not List.Contains({"0".."9"}, c), {"0".."9"}), {"属性.1", "属性.2"}),
// ここの「詳細設定>分割後の行数」を多めに指定するとよい
区切り記号による列の分割 = Table.SplitColumn(文字の移行による列の分割, "値", Splitter.SplitTextByDelimiter("/", QuoteStyle.Csv), {"値.1", "値.2", "値.3", "値.4", "値.5"}),
変更された型 = Table.TransformColumnTypes(区切り記号による列の分割,{{"属性.2", Int64.Type}}),
// 属性から分割した数字を使って列方向の位置を生成
整数除算済みの列 = Table.TransformColumns(変更された型, {{"属性.2", each Number.IntegerDivide(_, 2), Int64.Type}}),
結合された列 = Table.CombineColumns(Table.TransformColumnTypes(整数除算済みの列, {{"属性.2", type text}}, "ja-JP"),{"属性.2", "属性.1"},Combiner.CombineTextByDelimiter(":", QuoteStyle.None),"結合済み"),
ピボット解除された他の列1 = Table.UnpivotOtherColumns(結合された列, {"結合済み", "インデックス"}, "属性", "値"),
ピボットされた列 = Table.Pivot(ピボット解除された他の列1, List.Distinct(ピボット解除された他の列1[結合済み]), "結合済み", "値"),
// 削除列の意味の説明
#"名前が変更された列 " = Table.RenameColumns(ピボットされた列,{{"インデックス", "行番号"}, {"属性", "行内区切り位置"}}),
削除された列 = Table.RemoveColumns(#"名前が変更された列 ",{"行番号", "行内区切り位置"})
in
削除された列