
はじめに
AWS 認定 データアナリティクス – 専門知識 (DAS-C01)(AWS Certified Data Analytics - Specialty)の試験に合格することができましたので、これから受験しようとしている初学者に向けて、簡単な学習ポイントをまとめてみました。
少しでも初学時の参考になれば幸いです。
試験の出題範囲を把握する
どのような試験にも当てはまることですが、受験しようとする試験の出題範囲を確認し、これから学習する全体像を把握した上で、学習に着手した方が良いかと思います。
AWSの分析サービスについて確認する
AWSの分析サービスには、ユースケースに応じて、どのようなサービスがあるのか確認します。
参考:
[AWS でのデータレイクと分析]
(https://aws.amazon.com/jp/big-data/datalakes-and-analytics/)
試験の出題範囲のサービスを把握する
出題範囲の「各分野」に関連する「サービス」を下記の表のように定義して、試験の範囲となっているサービス群を把握します。
| 分野 | サービス(参考) |
|---|---|
| 分野1 : 収集 | Kinesis Streams, Kinesis Firehose, SQS, IoT |
| 分野2 : 格納 | S3, DynamoDB, RDS |
| 分野3 : 処理 | EMR, Glue, Lambda |
| 分野4 : 分析 | Kinesis Analytics, Redshift, Redshift Spectrum, Athena, Elasticsearch,SageMaker |
| 分野5 : 可視化 | QuickSight, Kibana |
| 分野6 : データセキュリティ | IAM, KMS, CloudHSM |
AWSのデータ分析サービスの全体像を把握する
各分野の各サービスの機能を、どのように学習していけば良いか把握するために、もう一度、データ分析サービスの全体像を把握します。
下記の資料を確認して、⼀般的なデータ蓄積・分析環境の論理的な構成を理解し、その構成の中で発生する課題をAWSの分析サービス使ってどのように解決するのかを理解して、AWSのデータ分析サービスの全体を把握します。
参考:
[AWS のデータ分析⼊⾨]
(https://d0.awsstatic.com/events/jp/2017/summit/slide/D4T3-2.pdf)
※上記資料より 抜粋
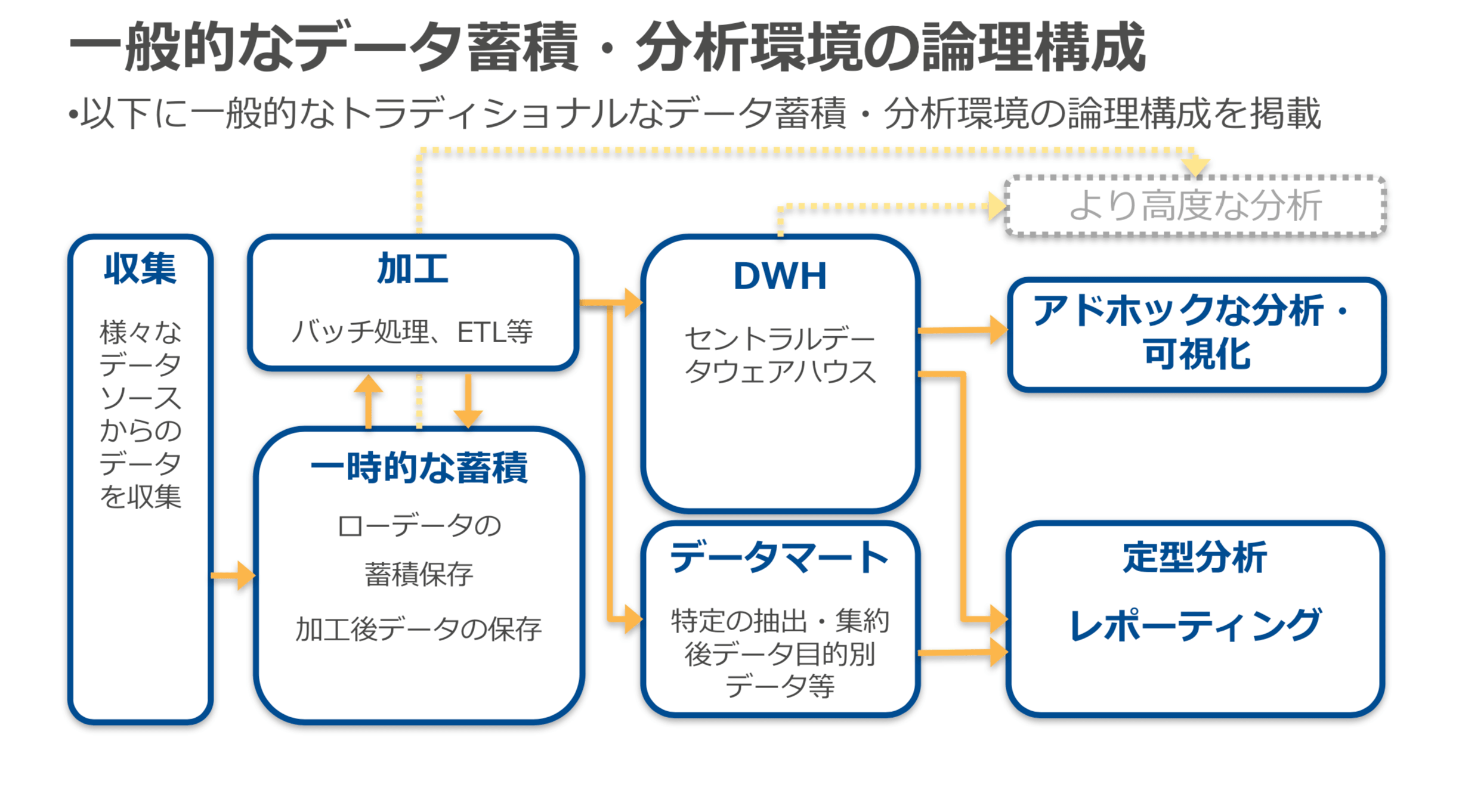
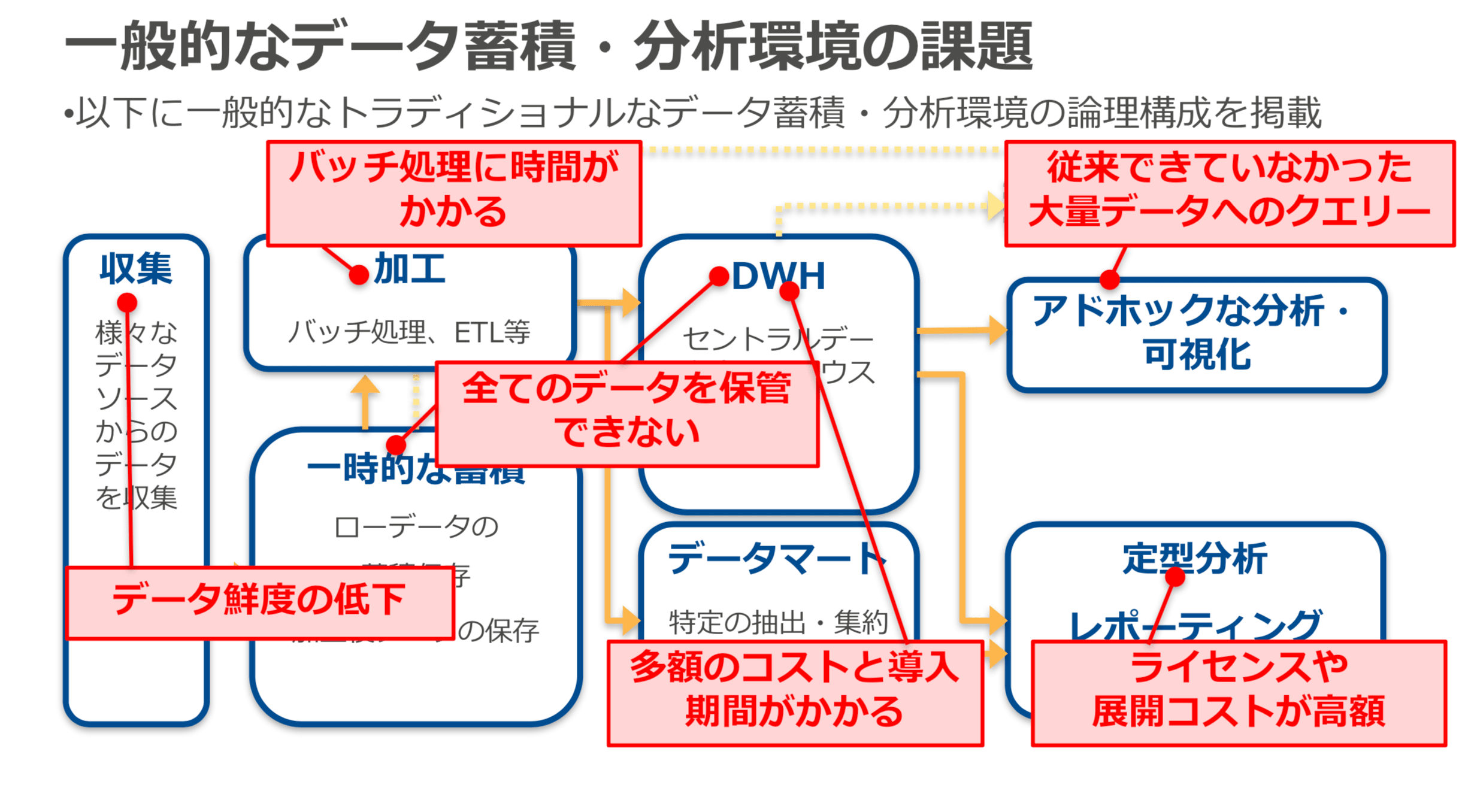
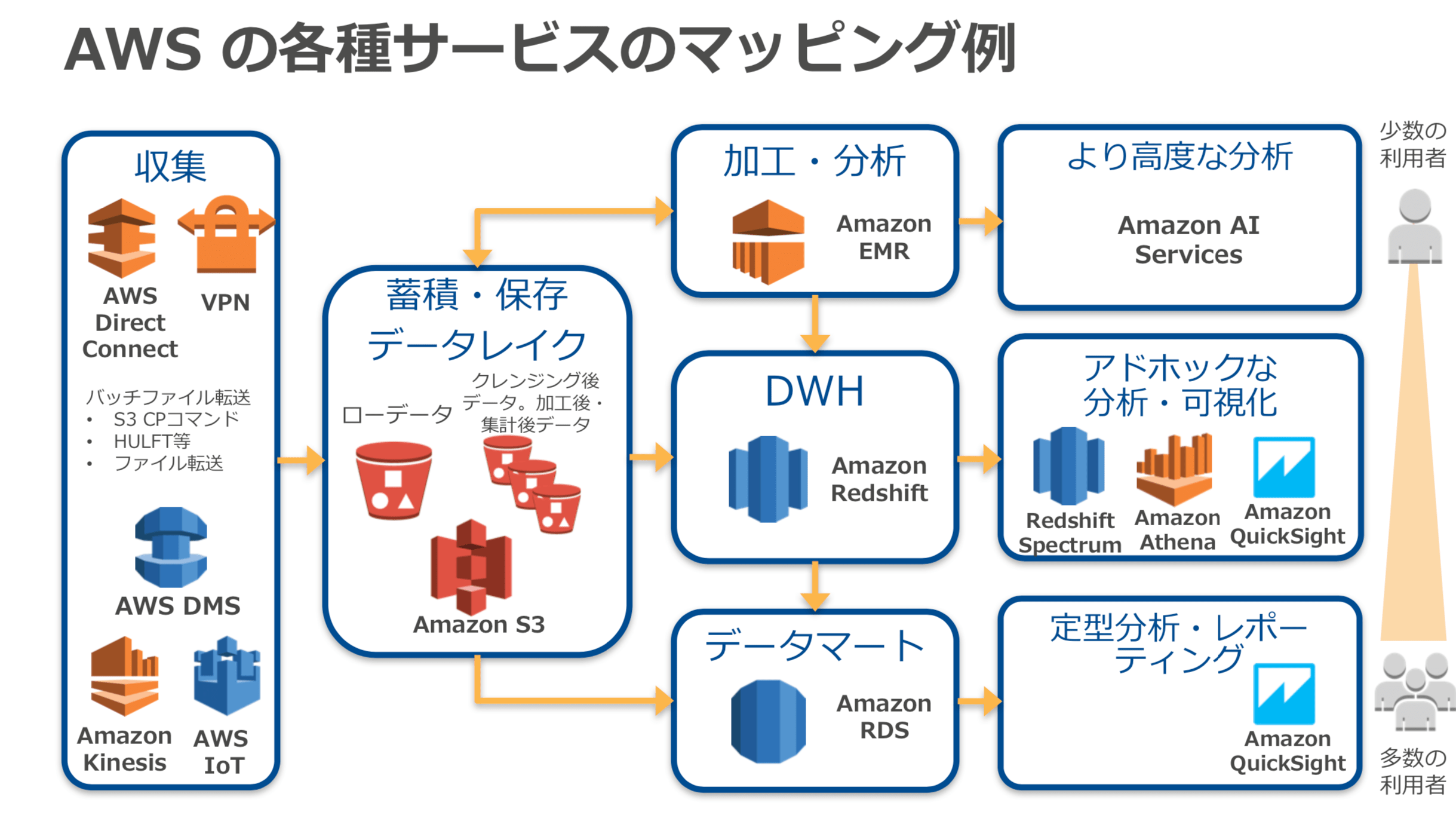
サービス単体の機能を理解する
AWSのデータ分析サービスの全体像が確認できたら、上記の表にある各分野ごとのサービスのBlackbelt を一通り読んでサービス単体の機能を理解します。
(初読の段階では、完全に理解しようとする必要はないと思います。)
各サービス間の連係を理解する
各サービスを単体で理解するだけでなく、各サービスがどのように相互に連係されるかを理解する必要があります。
試験においても、ユースケースごとに最適なサービス間の連係について問われます。
各サービス間の連係について理解するには、英語ですが、下記の資料がよくまとまっていて、理解しやすいかと思います。

Slideshare:[Big Data Analytics Architectural Patterns and Best Practices (ANT201-R1) - AWS re:Invent 2018]
(https://www.slideshare.net/AmazonWebServices/big-data-analytics-architectural-patterns-and-best-practices-ant201r1-aws-reinvent-2018)
Youtube:AWS re:Invent 2017: Big Data Architectural Patterns and Best Practices on AWS (ABD201)
※参考までに上記資料より 一部抜粋
ストリーム分析のサービス間の連係図
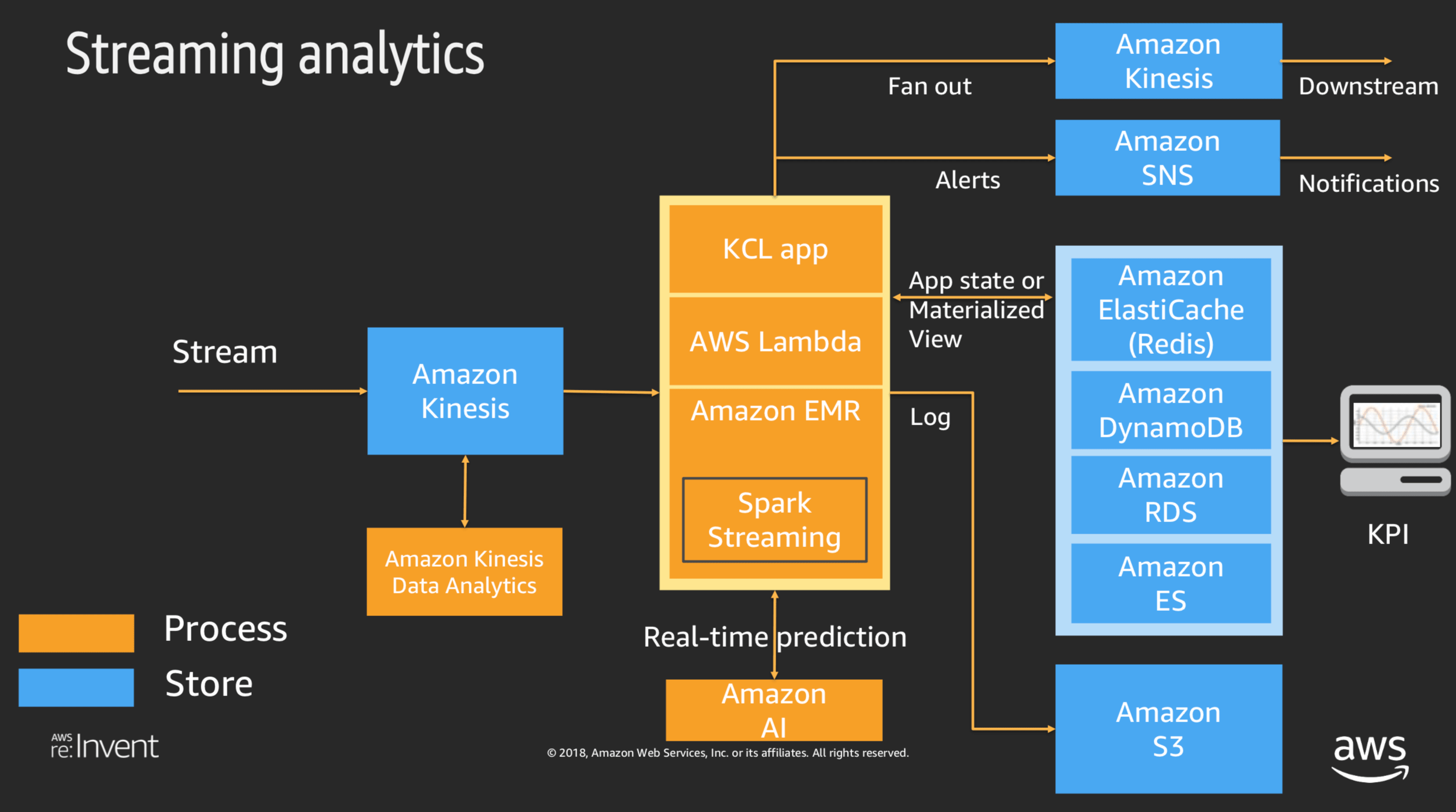
バッチ分析・インタラクティブ分析のサービス間の連係図
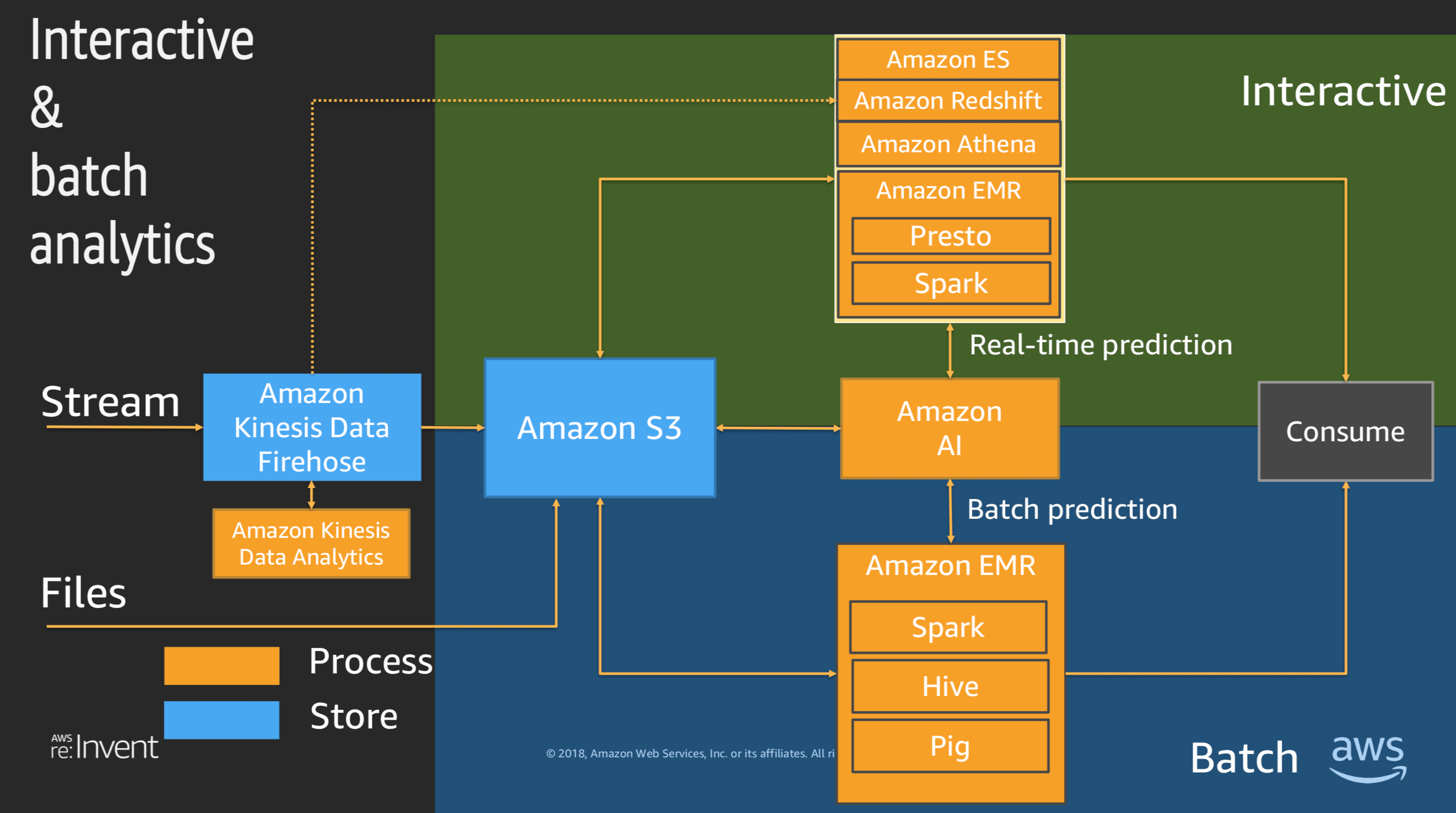
上記の資料や動画を確認して、ユースケースに応じて適切なサービスを選択し、サービス間の連係を最適に設計するとはどういうことなのか?が漠然とでも良いので気づけたなら、それこそが、この試験で評価される能力ということになるかと思います。
抜粋:試験ガイドでも下記のように記載されています。
この試験で評価する能力は次のとおりです。
• AWS の各種データ分析サービスについて定義し、これらのサービスの連係について理解
する。
• AWS のデータ分析サービスが、データライフサイクル (収集、格納、処理、および可視化)
にどのように関係しているかを説明する。
各サービスの特徴をさらに深く理解する。
ユースケースに応じて、最適なサービスを選択できるように、各サービスの特徴をさらに深く理解するようにします。
実際の試験においては、プロフェッショナルや他の専門知識の試験と同じように初見で解答を選択できることは少ないかと思います。
解答方法としては、各サービスの特徴から類推して、明らかに違う選択肢を見つけ、消去法で正解を絞り込んでいくのが手堅いと思います。
各サービスの特徴を学習する上でのポイントを一例としてあげておきますので参考にしていただければと思います。
- ストリーミングデータを収集するユースケースにおいて、Kinesis Data Streamsと Kinesis Data Firehose のどちらが選択するのが最適なのか?
- S3とDynamoDBのどちらにデータを格納するのが最適なのか?
- S3に格納されているデータは、構造化データか? それとも非構造化データなのか?
- S3に格納されているデータは、圧縮されているのか? それとも圧縮されていないのか?
- EMRで処理したデータは、HDFS と EMRFS のどちらに格納するのが最適なのか?
- EMRのクラスタにおいて、一時的クラスタ と 永続的クラスタのどちらを選択するのが最適なのか?
- S3に格納されたビッグデータをRedshift にロードする場合のパフォーマンスを向上させるにはどのような方法を選択するのが最適なのか?
- Redshift に効率よくデータを格納するにはどのような分散スタイルを選択するのが最適なのか?
- 分析データを保護する必要があるユースケースにおいて、各サービスは、どのように「通信の暗号化」や「保管データの暗号化」を実装することができるのか?
さいごに
以上が、「AWS 認定 データアナリティクス – 専門知識 (DAS-C01)」の試験の初学時の簡単な学習ポイントです。
データ分析の知識は、今後もさらに需要が見込まれる分野かと思います。
この試験の学習を通じて、その知識を生かして、活躍するエンジニアが増えていくといいなと思います。