はじめに
PyTorchの学習コードを簡潔にするためのフレームワークはいくつもありますが、この記事では最も入門しやすいCatalystを紹介します。手始めに、コンピュータビジョンのデータセットのショウジョウバエ(MNIST)を使って、シンプルな全結合ニューラルネットワークをトレーニングしてみます。
対象読者
- Catalyst(PyTorch)を使用したことがない方
- 深層学習については入門以上の知識があり、Kerasなどの深層学習フレームワークを触った経験がある方
Catalystって何?
PyTorchはDefine by Runによるデバッグの容易さ、Pythonicなコードを書けるという意味で、最近ではTensorFlowと並ぶほどの人気があります。しかしながら、TensorFlowのtf.kerasのようにPyTorchには学習コードを簡略化するフレームワークが備わっていないため、PyTorchだけでは学習コードは煩雑になりがちです。Catalystを使用するとそんな問題も解消されます。
使用環境
- Google Colab(GPU使用)
- torch: 1.7.0+cu101
- torchvision: 0.8.1+cu101
- catalyst: 20.12
- torchviz: 0.0.1
ソースコード
解説
ここからはソースコードの解説をします。
準備
Google Colabにはcatalystがインストールされていないので、インストールしましょう。計算グラフの可視化に使用するtorchvizもついでにインストールしておきます。
!pip install catalyst==20.12 torchviz==0.0.1
必要なものをインポートして、
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
from torchvision.transforms import transforms
from catalyst.dl import SupervisedRunner
from catalyst.dl.callbacks import AccuracyCallback
from catalyst.utils import get_device
from torchviz import make_dot
後で使用するハイパーパラメータの一部も設定しておきましょう。
# class数
num_class = 10
# 学習のepoch数
epochs = 30
# モデルやログファイルなどの保存先
logdir = "output/"
# random seed
seed = 1988
# バッチサイズ
batch_size=128
# データローダに使用するプロセス数
num_workers=2
使用するモデル
使用するモデルは、昔なじみの隠れ層が1つの全結合ニューラルネットです。
モデルは隠れ層が1つのシンプルな全結合ネットワークとして定義します。各ユニットの数は以下のとおりです。
- 入力ユニット: 784
- MNISTの入力次元
- 隠れユニット: 2048
- 任意
- 出力ユニット: 10
- クラス数[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
in_unit, hidden_unit, out_unit = 784, 2048, 10
model = nn.Sequential(*[
nn.Linear(in_features=in_unit, out_features=hidden_unit),
nn.ReLU(),
nn.Linear(in_features=hidden_unit, out_features=out_unit),
nn.Softmax(dim=1)
])
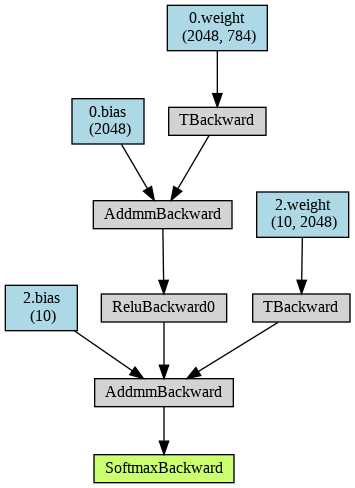
また、このモデルの計算グラフを可視化してみましょう。
x = torch.zeros(1, 784, dtype=torch.float, requires_grad=False)
model.eval()
y = model(x)
make_dot(y, params=dict(model.named_
parameters()))
データローダ
さて、MNISTのデータを読み込むためにデータローダを作っていきます。PyTorchのデータローダは、データセットからミニバッチを取り出すときに使用します。ざっくりですが次のようなイメージです。
- データセット: データ全部のオブジェクト
- データローダ: データセットから所定サイズのミニバッチを取り出せるオブジェクト
例えば、データローダのオブジェクトを適当に作ったとしましょう。
dataloader = Dataloader(hoge)
データローダはジェネレーターなので、データそのものではないですが、for文に使用できます。PyTorchのみだと、このようにして学習の処理などをすべて自分で書く必要がありますが、Catalystで平凡な分類を行う場合は、こんなことを意識する必要はありません。
for batch in dataloader:
# 学習など、何らかの処理 #
前処理
torchvisionで用意されているデータセットのオブジェクトには、コンストラクタで前処理を行うtransformを渡すことで、前処理されたデータを取得することができるようになります。我々は畳み込みではなく全結合ニューラルネットの学習をしようとしているため、MNISTの画像データをただの784次元のベクトルとして扱う必要があるわけです。それで前処理の中でテンソルをreshapeして(3, 28, 28)の形状を(784,)に直してしまいます。そのための簡単なクラスを用意します。
class Reshape:
def __init__(self, size=-1):
self.size = size
def __call__(self, image):
return image.view(self.size)
これに加えて、ToTensor, Normalizeというクラスを使って、前処理を行いましょう。
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
Reshape(),
])
ToTensorは画像オブジェクトをPyTorchのTensorオブジェクトに変換しています。その際に、[0, 255]から[0, 1]の範囲のデータに変換されます。Normalizeでは与えた平均(第1引数), 分散(第2引数)を使用して正規化します。それから、先程定義したReshapeを行って、784次元のベクトルができるわけですね。Composeはこれらの処理をまとめてできるようにしてくれるます。
データセット
MNISTはtorchvisionで用意されているため、特別なことはする必要はなく、すぐに使えます。
train=Trueを与えれば学習データセットを使えますし、train=Falseを与えればテストデータセットを使用できます。
download=Trueを与えれば、ダウンロードもしてくれるので楽ちんですね。
transformも渡して、先程定義した前処理も行ってくれます。
train_dataset = MNIST(
root='./data', # データ保存先
train=True, # trainデータセットの場合はTrue, testデータセットの場合はFalseを指定する
download=True,
transform=transform
)
val_dataset = MNIST(
root='./test',
train=False,
download=True,
transform=transform
)
データローダ
データローダはデータセットのデータをミニバッチにして読み込むときに使用します。
CatalystのRunnerクラスのインスタンスにデータローダを渡すときは、辞書にする必要があります。なので予め辞書にしておくと楽です。
'train'に学習用のデータローダ、'valid'に検証用のデータローダを設定します。
変えることもできるのですが、デフォルトの設定に合わせていますし、命名もわかりやすいので問題ないですね。
他には事前に定義していたバッチサイズ(128)、ロード時に使用するプロセス数(2)などを与えています。
引数shuffleはロード順をランダムに規定の順番にするか選べますが、検証データセットはシャッフルしてもしなくても変わらないためFalseに設定しています。
dataloaders = {
'train': DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
),
'valid': DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers
),
}
PyTorchのtransform・データセット・データローダについて取り上げました。このトピックは本題ではないのでこれ以上深入りはりませんが、興味がある方は以下の記事がわかりやすいので、参考にしてみてください。
・PyTorch transforms/Dataset/DataLoaderの基本動作を確認する - Qiita
目的関数やオプティマイザ
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-7, weight_decay=1e-5)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
分類ですので、criterionには目的関数として、クロスエントロピーのオブジェクトを設定し、
オプティマイザにはAdamを、よくあるハイパーパラメータで設定しています。
スケジューラーも使用できるため、使ってみました。StepLRはstep_sizeごとに、学習率がgamma倍減衰します。
つまり、以下の対応関係となります。
| epoch | 学習率 |
|---|---|
| 1-10 | $10^{-3}$ |
| 11-20 | $10^{-4}$ |
| 21-30 | $10^{-5}$ |
学習
さて、学習です。ここまできてようやくCatalystを使います。今回のような単純な分類タスクではSupervisedRunnerを使うと簡単です。タスクによっては複雑なことをする必要があるので、その場合はRunnerクラスをオーバーライドして細かいこともできます。最初の記事ですので、このトピックはすっ飛ばして、後々の記事で紹介していこうと思います。
runner = SupervisedRunner(device=get_device())
get_device()ではGPUデバイスのオブジェクトを取得しています。
通常のPyTorchの場合torch.device("cuda" if torch.cuda.is_available() else "cpu")をおまじないのように書かないといけないのですが、随分わかりやすくなっていますね。
あとはtrain()を呼び出せば学習ができます。ほとんどがこれまで定義したものを渡すだけです。
注意点として補足しておくと、
- valid_loaderにはデータローダの辞書で、検証用データセットを示すkeyを与えます。"valid"はデフォルトですし、dataloadersにもそのように記載しているため、この場合、わざわざ書く必要はありません。
- callbacksにはコールバックを渡せます。ここではAccuracyCallbackを与えて、正解率のメトリックを追加しています。accuracy_argsを整数nのリストを指定して渡すことで、正解が推論結果のn位以内に含まれている割合を計算します。ここでは[1, 5]を指定しているため、通常の意味の正解率(accuracy01)と、推論結果の5位以内に含まれている割合(accuracy05)がメトリックとして追加されます。
- main_metricには監視するメトリックを指定します。このメトリックが最善のモデルは保存されます。デフォルトはlossですが、accuracy01とかを与えてもいいわけですね。
- minimize_metricはmain_metricで与えたメトリックが小さいほどよいか、そうでないかです。クロスエントロピー(loss)のように小さいほどよいような指標の場合はTrueを、正解率(accuracy01)のように大きいほどよいような指標の場合はFalseを設定します。
- load_best_on_endをTrueに設定すると、学習後に最善の重みをrunnerにロードします。直後に推論したい場合などはTrueにしておくと吉です。
runner.train(
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
loaders=dataloaders,
valid_loader="valid", # default
logdir=logdir,
callbacks=[AccuracyCallback(num_classes=num_class, accuracy_args=[1, 5])],
num_epochs=epochs,
main_metric="loss", # default
minimize_metric=True, # default
initial_seed=seed,
verbose=False,
load_best_on_end=True,
)
次のように学習が進んで、
[2021-02-05 14:52:11,106]
1/30 * Epoch 1 (_base): lr=0.0010 | momentum=0.9000
1/30 * Epoch 1 (train): accuracy01=0.7951 | accuracy05=0.8956 | loss=1.6709
1/30 * Epoch 1 (valid): accuracy01=0.9375 | accuracy05=0.9958 | loss=1.5274
最終的には
[2021-02-05 14:57:52,890]
30/30 * Epoch 30 (_base): lr=1.000e-06 | momentum=0.9000
30/30 * Epoch 30 (train): accuracy01=0.9922 | accuracy05=0.9994 | loss=1.4698
30/30 * Epoch 30 (valid): accuracy01=0.9811 | accuracy05=0.9996 | loss=1.4807
Top best models:
output/checkpoints/train.30.pth 1.4807
=> Loading checkpoint output/checkpoints/best_full.pth
loaded state checkpoint output/checkpoints/best_full.pth (global epoch 30, epoch 30, stage train)
このように出力されて、最も良かった最終エポックの結果が保存されました。
試しにvalidの少しデータを取り出して、推論してみます。
predictions = next(runner.predict_loader(loader=dataloaders["valid"]))
for i, prediction in enumerate(predictions["logits"]):
prediction = prediction.detach().cpu()
key = torch.argmax(prediction).item()
print(f"推論結果: {key}, 確信度: {prediction[key]:.3f}")
if i > 10:
break
結果を見てみるとこんな感じで推論ができていることがわかります。
推論結果: 7, 確信度: 1.000
推論結果: 2, 確信度: 1.000
推論結果: 1, 確信度: 1.000
推論結果: 0, 確信度: 1.000
推論結果: 4, 確信度: 1.000
推論結果: 1, 確信度: 1.000
推論結果: 4, 確信度: 1.000
推論結果: 9, 確信度: 1.000
推論結果: 6, 確信度: 0.598
推論結果: 9, 確信度: 1.000
推論結果: 0, 確信度: 1.000
推論結果: 6, 確信度: 1.000
predict_loader()はデータローダを与えれば、ミニバッチごとに推論結果を返してくれるイテレータを生成できるメソッドです。
辞書が取り出されて、'logits'を参照すると、実際の推論結果のテンソルが入っています。こちらをデタッチしてからCPUに移動しています。最後にargmaxで最も確信度が高いラベルを取り出しています。これはNumpy等でもおなじみの処理ですね。
参考
・01_MNIST_FCN.ipynb
・Catalyst — Catalyst 20.12.1 documentation
・PytorchのDataloaderとSamplerの使い方 - Qiita
・PyTorch 三国志(Ignite・Catalyst・Lightning) - Qiita
・pytorch超入門 - Qiita