Dataloaderとは
datasetsからバッチごとに取り出すことを目的に使われます。
基本的にtorch.utils.data.DataLoaderを使います。
イメージとしてはdatasetsはデータすべてのリスト、Dataloaderはそのdatasetsの中身をミニバッチごとに固めた集合のような感じだと自分で勝手に思ってます。
datsets = [データセット全て]
Dataloader = [[batch_1], [batch_2], ... [batch_n]]
ですので
len(datasets)="すべてのデータの数"
len(Dataloader)="イテレーションの数"
となります。
(もちろんイテレータなのですべてのデータがそのまま入っているわけではありません。あくまでイメージです。あとスライス[:x]で取り出すこともできません。)
Dataloaderは__iter__と__next__が定義されているので、
iter(Dataloader).__next__() としてあげれば最初から1バッチずつ取り出すことができます。
デバッグする時等に便利です。
datasetsやdataloaderの挙動はPyTorch transforms/Dataset/DataLoaderの基本動作を確認するがわかりやすいです。
samplerとは
samplerとはDataloaderの引数で、datasetsのバッチの固め方を決める事のできる設定のようなものです。
基本的にsamplerはデータのインデックスを1つづつ返すようクラスになっています。
通常の学習ではtestloader = torch.utils.data.DataLoader(testset, batch_size=n,shuffle=True)で事足りると思います。
しかし訓練画像がクラスごとに大きく偏りがあって同じ割合で提供したいときや、距離学習などでそれぞれのクラスから同じ数だけ取り出してネットワークに入れるときなど、少し特殊なミニバッチを作りたいときにsamplerが役に立ちます。
torch.utils.dataに4つほどsamplerが用意されていますが、あまり使いそうなものはないので今回は自作してみたいと思います。
ただし作るのはsamplerではなくbatch_samplerになります。batch_samplerもDataloaderの引数の一つで、1つずつではなく複数のデータのインデックスを返します。
今回の想定として、先程例に出したようなすべてのクラスから何個か選んで、そのそれぞれのクラスから同じ数だけ取り出すことを考えます。選ぶクラスの数をn_classes、1つのクラスから取り出す数をn_samplesとします。すべてのデータの数はn_classes*n_samplesになります。
今回のコードはこちらを参考にしました。
import numpy as np
import torch
from torch.utils.data import DataLoader
from torch.utils.data.sampler import BatchSampler
class BalancedBatchSampler(BatchSampler):
"""
BatchSampler - from a MNIST-like dataset, samples n_classes and within these classes samples n_samples.
Returns batches of size n_classes * n_samples
"""
def __init__(self, dataset, n_classes, n_samples):
loader = DataLoader(dataset)
self.labels_list = []
for _, label in loader:
self.labels_list.append(label)
self.labels = torch.LongTensor(self.labels_list)
self.labels_set = list(set(self.labels.numpy()))
self.label_to_indices = {label: np.where(self.labels.numpy() == label)[0]
for label in self.labels_set}
for l in self.labels_set:
np.random.shuffle(self.label_to_indices[l])
self.used_label_indices_count = {label: 0 for label in self.labels_set}
self.count = 0
self.n_classes = n_classes
self.n_samples = n_samples
self.dataset = dataset
self.batch_size = self.n_samples * self.n_classes
def __iter__(self):
self.count = 0
while self.count + self.batch_size < len(self.dataset):
classes = np.random.choice(self.labels_set, self.n_classes, replace=False)
indices = []
for class_ in classes:
indices.extend(self.label_to_indices[class_][
self.used_label_indices_count[class_]:self.used_label_indices_count[
class_] + self.n_samples])
self.used_label_indices_count[class_] += self.n_samples
if self.used_label_indices_count[class_] + self.n_samples > len(self.label_to_indices[class_]):
np.random.shuffle(self.label_to_indices[class_])
self.used_label_indices_count[class_] = 0
yield indices
self.count += self.n_classes * self.n_samples
def __len__(self):
return len(self.dataset) // self.batch_size
samplerもbatch_samplerも__iter__を定義する必要があります。
__iter__ではn_classes*n_samples個のインデックスを返しています。
__len__はデータセットの数//バッチサイズなのでlen(batch_sampler)="イテレーションの数"です。
実際にどのように取り出されているか確かめてみましょう。今回はmnistで実験してみたいと思います。
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
n_classes = 5
n_samples = 8
mnist_train = torchvision.datasets.MNIST(root="mnist/mnist_train", train=True, download=True, transform=transforms.Compose([transforms.ToTensor(),]))
balanced_batch_sampler = BalancedBatchSampler(mnist_train, n_classes, n_samples)
dataloader = torch.utils.data.DataLoader(mnist_train, batch_sampler=balanced_batch_sampler)
my_testiter = iter(dataloader)
images, target = my_testiter.next()
def imshow(img):
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
imshow(torchvision.utils.make_grid(images))
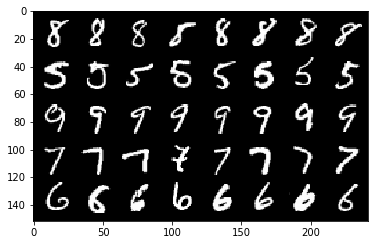
0から9の内5種類が選ばれ、8枚ずつ取り出されているのがわかると思います。
参考
PyTorch transforms/Dataset/DataLoaderの基本動作を確認する
【詳細(?)】pytorch入門 〜CIFAR10をCNNする〜
pytorh公式サイトのsampler