本記事は Go Advent Calendar 2021 - カレンダー1 11日目の記事になります。
Advent Calendar参加2年目です。
今年も超絶ギリギリで準備していました。
(そういう運命なのか?)
はじめに
私事ではございますが、最近転職をいたしました。
入社して最初にDB操作研修とAngular研修があったのですが、私はインフラ要員として入社したので、Angular研修はありませんでした。
Angular研修用の資料等を覗き見して、だいたいのことは今ある知識だけできそうだなと思いました。
ですのでAdvent Calendarに合わせてAngularでアプリを作って、勝手に一人研修を実施することにしました。
作成したアプリの話が気になる方は以下の記事をお読みください(読んでくださると嬉しいです![]() )。
)。
そこで、バックエンドは例のごとくGo言語を採用することにしました。
久々にDBも使うアプリにしようかなと思い開発をはじめました。
こちらの記事での要旨はアプリを作って大変だったといった話ではなく、プログラミング言語とDB間の連携部分について話をしたいと思います。
開発した成果だけを読みたい方は5.章からお読みください。
筆者環境
- OS: Arch Linux
- Go: 1.17.5 linux/amd64
- DB: MariaDB 10.3.31
- Editor: code-server 3.12.0 / vim 8.2
- パッケージ管理: Go Modules
- サービス管理: systemd 249 (249.7-2-arch)
- ビルドツール: Gnu Make 4.3
今年の初めまでは、Google Cloud Shell Editorを使っていたのですが、デバッグがローカル環境でできないのは難点でした。
(もちろん、Googleの力を使ってローカル環境と遜色なくデバッグできるようになっていますよ。)
そこで、ブラウザで実行できるOSSなクラウドIDEであるcode-serverに乗り換えました。
自宅にいるときは実質ローカル環境ですし、外出先でもVPN越しで簡単にローカル環境のようにデバッグができますし。
もはやローカルPCにインストールするVS Codeには戻れないですね。
1.SQLクエリをコード内に書くか否か
DBを使用するアプリでは、DBのテーブル構造やデータの型、jsonでやり取りするパラメータ等のAPI周りのことを設計で決めていくと思います。
DBからデータを取得し、APIに引き渡す過程は当然コードとしてプログラムに記載しなければなりません。
その中で、私は以前からSQLクエリをコードの中に記載してきました。
SQLクエリをコード内に記載するメリットは以下だと思っております。
- 変数等で簡単に呼び出せる、あるいはstringとしてDBからのデータ取得用関数・メソッドにベタ書きできる
- コンパイル言語であれば、バイナリの中にインクルードされる
- プレースホルダの近くで値を埋め込むこともでき、あっちを見たりこっちを見たりする必要がない
ただ、デメリットも孕んでいます。
- SQLクエリを修正する際に、コードそのものの変更が発生することになる(リビルド等も当然行う)
- SQLクエリの修正によって、取得するデータ構造が変化する可能性もあり、バグの温床になる
- SQLクエリに関するバグの発見が遅れる(ただの文字列なので、Lint等も効果がない)
- テストコードでのバグのあぶり出しが難しい
- 単純に汚い
私が思うデメリットはこれらになるかなと思います。
私が最初にコードを書き始めた頃は本当にベタ書きでした。
// ※「PDO_connect」はDB名を指定すると、DB接続のためのPDOインスタンスを返してくれる自作メソッドです
$pdo = PDO_connect('game');
$stmt = $pdo->prepare("SELECT * FROM `GameList` WHERE `title` = :title"); //クエリの発行
$stmt->bindValue(':title', "{$title}"); // Formからの流入値
$stmt->execute();
$dataArray = $stmt->fetchAll(); // 結果の行全てを連想配列で取得
私が趣味でコードを書き始めた最初期のPHPコードを記載してみました。
今見返してみると、何でもいいからデータを取得できればそれで良い、みたいな感じがしますね。
(最初の※のコメント以外原文ママです。)
業務でプログラムを書くようになっても、SQLクエリはコード内にまとめて定数として書くようにしていました。
コード規約上は特に何も記載されていなかった上に、先輩や上司がそう書いていたのでそうしていました。
2.SQLクエリはコード内に書くべきではない
しかし、業務でプログラムをあまり書かなくなってからになりますが、SQLクエリは分離すべきだという思いが強くなってきました。
とにかく最も許せないことが、データ構造・SQLクエリに変更点があった際に変更すべきスコープが明確にならないことです。
今回の話とは少し違いますが、SQLクエリをコード内にベタ書きして、わざわざその結果に対する対応した構造体等の専用オブジェクトを用意することは、少ないのではないのかなと感じています。
私の偏見かもしれませんが。。。
先述したSQLクエリはコード内にまとめて定数として書いていたプロジェクトでは、.NETを利用していたのですが、SQLクエリの結果は全て DataTable か DataSet に詰め込んでいました。
.NETを知らない人向けに補足しますと、Microsoftが公式に提供してくれている、SQLの型を .NETの型としてデータ表現してくれる機能です。
(変換は内部のクラスに紐づくメソッドで実施されているので、.NETのソースをわざわざ読むエンジニアでない限り、ブラックボックスのように見えます。)
そして、これらクラスの目的はDBから取得したデータをまるごとメモリ内にキャッシュすることです。
なので、このプロジェクトで我々が作ったコードはアホみたいにメモリを食っていました。
100MBなんて生易しい方です。
DBへの問い合わせが走るごとにGCで削除されるまでメモリ内で保管されるのですから。
少し話が脱線しましたが、これらオブジェクトからデータを取り出すために、わざわざDBのテーブル定義書を見てどれだどれだと探さなくてはならないのです。
その上、連想配列のようなものなので、タイポしただけで値が取得できません。
SQLクエリが変更されると DBNull(SQLとしてのNull)か null がよく返ってきて 、nullチェックを忘れていた場合は即座にバグになっていました。
nullチェックをしていない方も悪いのですが、nullが流れ込んでくるわけがないと考えていたかもしれません。
SQLクエリの変更によって「こんなところにも影響が!」という可能性は当たり前にあるという考えがなければ、確かにこうなりますよね。
そういう経験があったからこそSQLクエリはコード内に書くべきではないと思うようになりました。
3.では、どうするべきなのか?
手法は2つあると思っております。
- O/Rマッパー(以下、ORM)を使ってSQLクエリを擬似的に隠匿化する
- SQLクエリをテンプレートファイル化して外出しにする
今回私が選択したのは2番です。
なぜなら、個人的な思いからですが、ORMが嫌いだからです。
なぜ嫌いなのかと申しますと、様々理由がありますが、一番大きな理由は構築されるSQLクエリが簡単にわからないからです。
そのORMに精通していれば、すぐに分かるかもしれません。
例えば、Ruby on Railsを長年やっている人ならActiveRecordが用意するSQLクエリがすぐに分かるかもしれません。
しかし、自分でSQLクエリを組まずに望んだ結果を得るのは危険だと考えます。
なぜなら、ORMを開発している人たちのさじ加減ひとつで、生成されるSQLクエリが破壊的に変わる可能性がゼロではないからです。
だからこそ、私は自分でSQLクエリを生成して制御可能な状態にしておきたいのです。
よって私は「SQLクエリをテンプレートファイル化して外出しにする」を選択しました。
4.でも、INSERT・UPDATE・DELETEを書くのは面倒
みなさんもプログラマの三大美徳を聞いたことがあるかもしれません。
1.怠慢 (Laziness)
2.短気 (Impatience)
3.傲慢 (Hubris)
ここで、怠慢さと傲慢さが私の中に満ちました。
私が制御をしたいのは**SELECTだけ**なのです。
INSERT・UPDATE・DELETE をテンプレートファイルにわざわざ書きたくはありません。
なぜなら、複数レコードを更新したい・削除したいといった特殊な要件ではない限り、1レコードずつ処理するからです。
特殊な INSERT・UPDATE・DELETE クエリはあまり頻繁に登場するものではないと思っています。
なので、INSERT・UPDATE・DELETE クエリはいい感じに処理してほしいところです。
SQLクエリは自動生成しない、でも INSERT・UPDATE・DELETE クエリはいい感じに処理してほしい、そしてあわよくば構造体へのマッピングは自動でやってほしい1という願いを叶えてくれるORMライクなツールがないかと探したところ、あるもんですね。
Introductionの最初の文で気に入りました。
I hesitate to call gorp an ORM.
(筆者訳:gorpをORMと呼ぶには憚られる。)
開発者の人たちも、「これはORMではない」という思いで開発しているということがわかったので、これを使うことにしました。
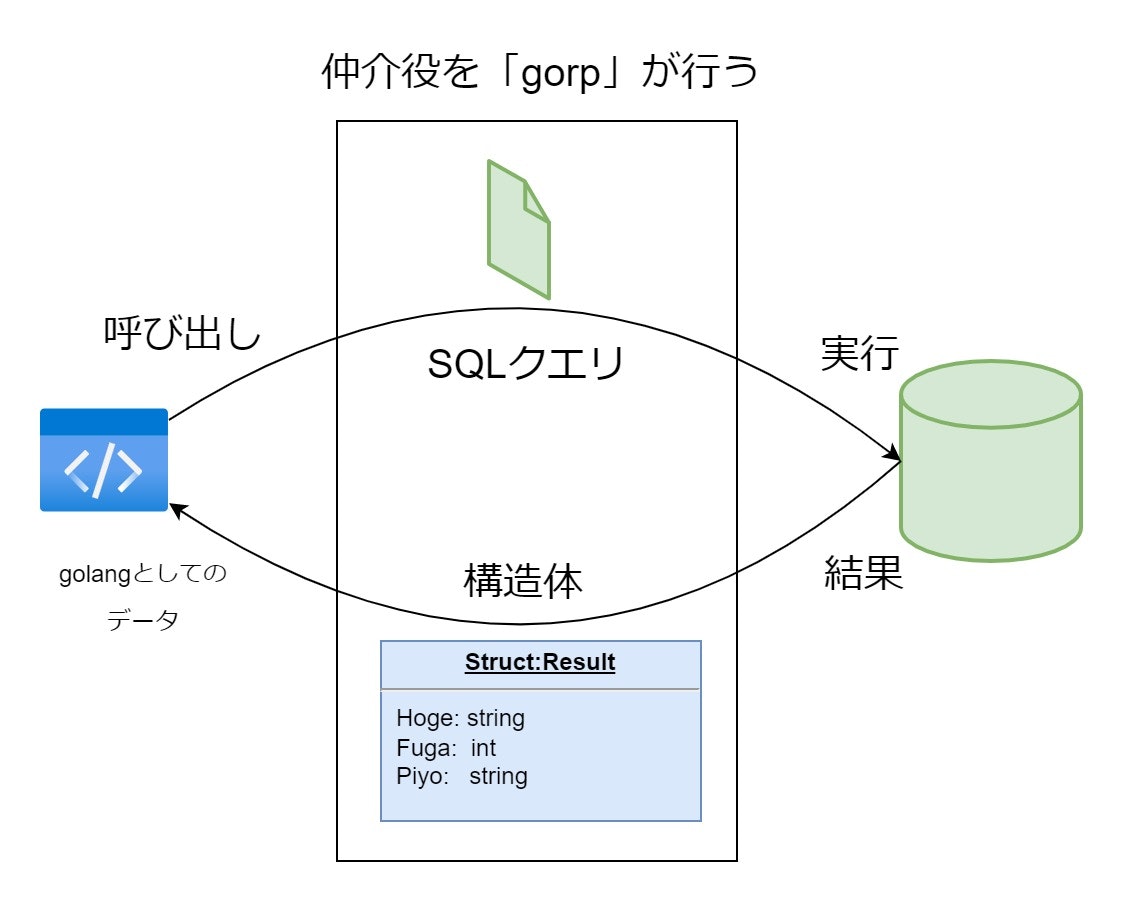
5.実際に作ったもの
さて、ここまではポエムっぽく語ってきましたが、ここからは今回開発したものを交えて説明していきます。
gorpが行ってくれることは非常にシンプルです。
SELECT に関するSQLクエリはクエリで直接実行し、構造体にマッピングして結果を返してくれます。
INSERT・UPDATE・DELETE クエリは構造体を渡してあげると、該当レコードを挿入・更新・削除します。
もちろん、SQLクエリを直接実行する機能はgorpにも備わっていますので、特殊な INSERT・UPDATE・DELETE クエリであっても問題ありません。
今回例で説明するテーブルの構造は以下のようになっています。
テーブル名:【T_ID】
| カラム名 | 型 | 制約等 |
|---|---|---|
| id | VARCHAR(36) | NOT NULL, PRIMARY KEY |
| total | TINYINT UNSIGNED | NOT NULL, DEFAULT '0' |
| is_end | BIT(1) | NOT NULL, DEFAULT b'0' |
| expire | VARCHAR(19) | NOT NULL, DEFAULT '1970-01-01T09:00:00' |
このテーブルに対応する構造体を以下のように定義しています。
import (
"github.com/go-gorp/gorp"
)
type TranID struct {
Id string `db:"id, primarykey" json:"id"`
Total int `db:"total" json:"total"`
IsEnd int `db:"is_end" json:"is_end"`
Expire string `db:"expire" json:"expire"`
}
// MapStructsToTables 構造体と物理テーブルの紐付け
func MapStructsToTables(dbmap *gorp.DbMap) {
dbmap.AddTableWithName(TranID{}, "T_ID").SetKeys(false, "Id")
}
MapStructsToTables については後で説明します。
SELECT について
SQLクエリの呼び出し
まずはSQLクエリをテンプレートファイルとして、完全に分離させました。
SELECT
`id`,
`total`,
CAST(`is_end` AS UNSIGNED) AS `is_end`,
`expire`
FROM T_ID
WHERE `id` = :id;
:id についてはプリペアードステートメントです。
後ほど使います。
次に、このテンプレートファイルをコード内部へと持ち込みます。
package db
import (
"bytes"
"fmt"
"os"
"path/filepath"
"text/template"
)
func GetSQL(name string, req interface{}) string {
dir := getDirName()
if dir == "" {
return ""
}
var buf bytes.Buffer
filename := filepath.Join(dir, fmt.Sprintf("%s.sql", name))
t := template.Must(template.ParseFiles(filename))
t.Execute(&buf, req)
return buf.String()
}
func getDirName() string {
exe, err := os.Executable()
if err != nil {
return ""
}
return filepath.Base(exe) + ".sql"
}
必要な部分のみ切り出してあります。
やっていることとしては、実行ファイルと同階層の実行ファイルの名称に .sql とついたフォルダ(実行ファイルが test なら test.sql というフォルダ)からsqlファイルを探します。
引数で探すべきファイルの名称が渡されますので、対象ファイルから text/template を通して string としてレンダリングします。
text/template を利用している理由は、今回は使用しませんでしたが、複雑なSQLクエリでもテンプレート機能を用いて場合分け等を行えるようにするためです。
これでSQLクエリが呼び出せるようになりました。
gorpの役割
続いて、SQLクエリを用いてgorpに結果を取ってきてもらう処理です。
package db
import (
"github.com/go-gorp/gorp"
"ip-calc-api/models"
)
type IpRepository struct {
*gorp.DbMap
}
func NewIpRepository(dm *gorp.DbMap) *IpRepository {
return &IpRepository{dm}
}
func (r *IpRepository) GetID(id string) (models.TranID, error) {
var result models.TranID
query := GetSQL("get-id", "")
val := map[string]interface{}{"id": id}
if err := r.SelectOne(&result, query, val); err != nil {
return models.TranID{}, err
}
return result, nil
}
IpRepository は関数レシーバ用に、定義しています。
Go言語ではプリミティブ型や他のモジュールで定義された型を直接関数レシーバにすることはできません2。
query := GetSQL("get-id", "")
まずはSQLクエリを string として呼び出します。
val := map[string]interface{}{"id": id}
プリペアードステートメントへと値を埋め込みます。
if err := r.SelectOne(&result, query, val); err != nil {
return models.TranID{}, err
}
そして、問い合わせとエラー処理を実施します。
成功するとポインタとして渡している result に結果が変換されて詰め込まれます。
簡単ですね。
それに、SQLクエリを変更して取得する結果が変わった際には、ここで必ずエラーになります。
なぜなら、紐付けに失敗するからです。
こうして分離していると、エラー解決までの速度も変わってくると思います。
実際の呼び出し部分
package main
import (
"database/sql"
"fmt"
"github.com/go-gorp/gorp"
_ "github.com/go-sql-driver/mysql"
"ip-calc-api/db"
"ip-calc-api/models"
)
var repo *db.IpRepository
func main() {
repo = initDB()
if repo == nil {
panic("DB接続失敗!!")
}
tid, err := repo.GetID("これが本当のidです")
if err != nil {
//エラー処理
}
// tidを用いた処理・・・
}
func initDb() *gorp.DbMap {
db, _ := sql.Open("mysql", "usr:pw@tcp(mysql:3306)/db")
dial := gorp.MySQLDialect{Engine: "InnoDB", Encoding: "utf8mb4"}
dbmap := &gorp.DbMap{Db: db, Dialect: dial, ExpandSliceArgs: true}
models.MapStructsToTables(dbmap)
return db.NewIpRepository(dbmap)
}
※わかりやすくするために、開発したソースと変更しています。
まずは initDB でDBと接続します。
DBの接続先をOpenして、利用するエンジンやエンコーディングを設定します。
dbmap := &gorp.DbMap{Db: db, Dialect: dial, ExpandSliceArgs: true}
そして、DBMapオブジェクトを生成するのですが、ExpandSliceArgs が何か気になるかもしれません。
これは WHERE 句において IN 句を利用して検索するときに効果を発揮します。
SELECT * FROM table WHERE id IN (:ids);
上記のようなSQLクエリに対して、
val := map[string]interface{}{"ids": []int{1,2,4,8}}
スライスや配列をプリペアードステートメントに渡すことができるようになります。
内部的には、クエリ文字列を
SELECT * FROM table WHERE id IN (:ids0, :ids1, :ids2, :ids3)
と展開して処理してくれているようです。
この使い方に関連した日本語の記事がほぼなくて結構苦労しました。
(実は公式のドキュメントに結構詳細に書いてあるのですが![]() )
)
models.MapStructsToTables(dbmap)
/*
↓↓中の処理↓↓
func MapStructsToTables(dbmap *gorp.DbMap) {
dbmap.AddTableWithName(TranID{}, "T_ID").SetKeys(false, "Id")
}
*/
最後に MapStructsToTables です。
先述したのですが、戻ってもらうのも遠いので再度記載しておきます。
この関数は、DBのテーブルに対してどの構造体を紐付けておくのかということを定義するために呼び出します。
また、Key情報やAuto Incrementの設定をしておくと、Insertするとき等によしなにやってくれます。
DBと接続したら、nullチェックをして使うだけです。
あとはコードの中で得た結果をゴニョゴニョしてください。
INSERT・UPDATE・DELETE について
INSERT・UPDATE・DELETE についてはSQLクエリがなくても使えるのでいきなりgorpの役割から説明します。
gorpの役割
func (r *IpRepository) UpdateID(tid models.TranID) error {
tx, err := r.Begin()
if err != nil {
return err
}
if _, err := tx.Update(&tid); err != nil {
tx.Rollback()
return err
}
if err := tx.Commit(); err != nil {
tx.Rollback()
return err
}
return nil
}
SELECT の節で説明したので、多くは語りません。
引数に構造体を渡して、トランザクションのもとでレコードに対して更新をかけているだけです。
何も難しくはないと思います。
実際の呼び出し部分
SELECT のところで用いたコードにおいて、以下のように変えるだけで利用できます。
tid, err := repo.GetID("これが本当のidです")
if err != nil {
//エラー処理
}
![]() を
を ![]() にするだけです。
にするだけです。
if err := repo.UpdateID(tid); err != nil {
//エラー処理
}
簡単ですね。
最後に
長文をお読みくださり、ありがとうございました&お疲れさまでした。
今回一番伝えたかったことは お互いに責任点を切り離して、疎な関係にすることはやはり大切だと思う ということです。
責任境界が曖昧な密な関係にしてしてしまうと、バグの温床にもなりやすいですしコードレビューや保守の際にコードを読み直す時も何をやっているのかわからなくなりがちです。
そういったことはやめるべきだと思います、と啓蒙できていれば幸いです。
今回の開発物は以下のgithubから閲覧することもできます。
(コメントが少ないのは時間がなかったからです、頑張ってつけていきます。)
MIT LICENSEですので、ある程度好きにしてもらって構わないです。
また、今回は記載しませんでしたが、SQLクエリのファイルをバイナリの中に閉じ込めることも可能なようです。
それでは良いエンジニアライフを!
参考文献