はじめに
**フォルダにある大量のテキストファイルから特定の数値を自動で抜き出すプログラムを作った方法についてご紹介いたします。**この投稿は以前の私のこちらの投稿を参考に作りました。
※プログラミング関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
やりたいこと
以下のようなテキストファイルの考えます。計算プログラムの実行結果をイメージしています。
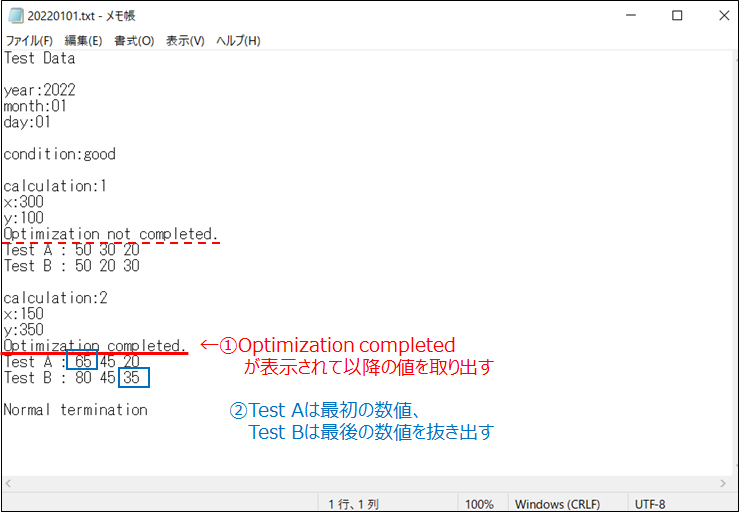
このテキストファイルから取り出したい値を次の2つとします。
- Optimization completedが表示された直下にあるTets Aの最初の値
- Optimization completedが表示された直下にあるTets Bの最後の値
このテキストファイルがフォルダ内にいくつもあって、全てのテキストファイルから上記の値を取り出す方法を考えていきます。ただし、calculationの数はテキストファイルごとに異なるとします。最終的には以下にフォルダ内の全てのテキストファイルの同様の処理をして、自動で値を取り出すことを目的とします。
アウトプットのイメージはこんな感じです!

環境
- windows10
- conda 4.10.3
- python 3.7.10
- pandas 1.3.2
今回の検討例
次の3つのテキストファイルがフォルダに入っているとして、プログラムを検討していきます。
20220101.txt
Test Data
year:2022
month:01
day:01
condition:good
calculation:1
x:300
y:100
Optimization not completed.
Test A : 50 30 20
Test B : 50 20 30
calculation:2
x:150
y:350
Optimization completed.
Test A : 65 45 20
Test B : 80 45 35
Normal termination
20220201.txt
Test Data
year:2022
month:02
day:01
condition:good
calculation:1
x:300
y:100
Optimization not completed.
Test A : 50 30 20
Test B : 50 20 30
calculation:2
x:200
y:200
Optimization not completed.
Test A : 55 35 20
Test B : 50 20 30
calculation:3
x:100
y:300
Optimization completed.
Test A : 60 40 20
Test B : 70 40 30
Normal termination
20220301.txt
Test Data
year:2022
month:03
day:01
condition:good
calculation:1
x:300
y:100
Optimization not completed.
Test A : 10 5 5
Test B : 20 10 10
calculation:2
x:250
y:150
Optimization not completed.
Test A : 25 15 10
Test B : 40 20 20
calculation:3
x:200
y:200
Optimization not completed.
Test A : 55 45 10
Test B : 50 30 20
calculation:4
x:100
y:300
Optimization completed.
Test A : 90 45 45
Test B : 70 40 30
Normal termination
最終行のNormal terminationは計算が正常に実行したことを表すイメージで記載しています。
完成したコード
# ライブラリーのインポート
import glob
import os
from pathlib import Path
# ファイル名と抜き出した値を格納するリストをつくる
labels = []
TestAs = []
TestBs = []
# 現在参照しているフォルダ内にあるすべてのtxtファイルを順番に読み込んでいく
for i in glob.glob(os.getcwd()+"/*.txt"):
file = open(i, 'r', encoding='UTF-8')
data = file.readlines()
file.close()
label = Path(i).stem # 取得したファイル名をlabelで定義しておく
labels.append(label)
print(label)
# 計算が正常に終了しているか確認する(異常時はErrorを返す)
E = "Normal termination" in data[-1]
if E == True:
print("Normal termination")
else:
print("Error!!")
TestA = "Error" # 値に"Error"が入力されるようにしておく
TestAs.append(TestA)
TestB = "Error" # 値に"Error"が入力されるようにしておく
TestBs.append(TestB)
# TestA,TestBの値を抜き出していく
# Optimization completed.を検索する
# Optimization completedが記載されている行数を格納するリストを作る
list_Oc = []
for j in range(len(data)):
Oc = "Optimization completed" in data[j] # Optimization completedが文字列に含まれるか判定する
if Oc == True:
list_Oc.append(j)
# TestA, TestBが記載されている箇所を検索する
# Optimization completedが初めて現れた行より下でTestAが初めて現れる行に抜き出したいTestAの値が記載されている
list_TA = []
for k in range(list_Oc[0], len(data)):
TA = "Test A" in data[k]
if TA == True:
list_TA.append(k)
# TestA,TestBが記載されている行数を定義しておく
TestA_row = list_TA[0]
TestB_row = list_TA[0]+1
# TestAを求める(data[TestA_row]はlistで与えられ一番最後は改行の"\n"
# TestAを求める(TestAはsplitしたlistデータの4番目)
TestA = data[TestA_row][:-1].split(' ')[3]
TestAs.append(TestA)
# TestBはsplitしたlistの最後尾の数値
TestB = data[TestB_row][:-1].split(' ')[-1]
TestBs.append(TestB)
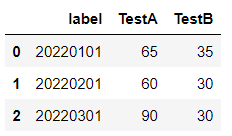
取得した値をデータフレームとして表示してみます。
# データフレームを作る
import pandas as pd
df_label = pd.DataFrame(labels)
df_TestA = pd.DataFrame(TestAs)
df_TestB = pd.DataFrame(TestBs)
column_list = ["label", "TestA", "TestB"] # 列名を定義する
df = pd.concat([df_label, df_TestA, df_TestB], axis=1) # 横方向に結合するのでaxis=1を指定
df.columns = column_list
df
行と列を入れ替える際は転置して表示します。
df.T
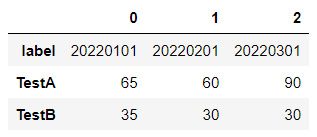
これでイメージ通りですね!最後にcsvファイルに結果を保存して出力しておきます。
df.T.to_csv("TestA_TestB.csv")
プログラムの解説
- Test Aの値はいくつかあるので、Optimization completedが表示される行数を取得し、その行以下を調べることで抜き出したいTest Aを特定しました
- 自動化すると中には計算が上手くいっていないファイルも混じっている場合を想定して、計算が正常に終了していないファイル(Normal terminationが最終行にないファイル)についてはErrorの値が返ってくるように工夫しました
まとめ
フォルダにある大量のテキストファイルから特定の数値を自動で抜き出すプログラムを作った方法についてご紹介致しました。ルーティーンかつ面倒な作業はなるべく効率化できればなと思っています。
ココもっとこうしたらプログラムが楽or綺麗などございましたらコメントください。