はじめに
Pycaretとは数行のコードで機械学習モデルを構築・比較してくれるAutoMLライブラリです。
この投稿では分類問題(2分類)を取り扱い、結果の解釈やコードの詳細を説明します。
分類問題用のデータセットの作成
分類問題用にデータセットにラベルづけを行います。今回はこちらのページで紹介した"df.csv"というデータを用いていきます。csvファイルはGitHunにも保存しております。
# データの読み込み
import pandas as pd
df = pd.read_csv("df.csv")
print("Datasize: " + str(df.shape))
df.head()
Datasize: (707, 10)
このデータセットのyの値に対して、以下のルールに基づきラベル付を行います。
- y ≦ 150は"NG"
- y > 150は"OK"
# y列をラベルに置き換えます
df.loc[df["y"] > 150, "y_label"] = "OK"
df.loc[df["y"] <= 150, "y_label"] = "NG"
df.head()
0. データの読込みと前処理
# ライブラリのインポート
# 不要な警告文を非表示にする
import warnings
warnings.filterwarnings("ignore")
from pycaret.classification import *
# pycaretのバージョンを確認
import pycaret
print("pycaret version: ", pycaret.__version__)
pycaret version: 3.0.4
次にデータの前処理を行っていきます。今回はyを無視して、x1~x9を説明変数としてy_labelを予測していくことにします。
# データの前処理
clf = setup(df, target ="y_label", fold = 5,
ignore_features = ["y"],
fold_shuffle=True, session_id = 123)

3.Label Encoded にラベル付の方法が記載されている
参考サイト(引数の参考)
1. モデルの比較
この段階ではハイパーパラメータの最適化までは実行されていない。
# 各種モデルの比較
best_model = compare_models()
best_model
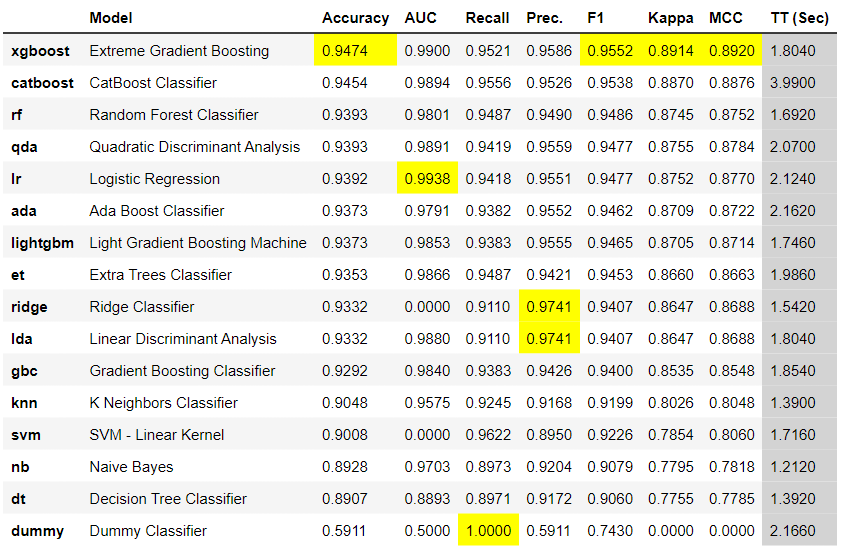
- Accuracy:正解率(正例、負例を問わず正解した割合)
- AUC:ROC曲線で囲まれた面積
- Recall:再現率、実際に陽性であるもののうち陽性と予測できた割合
- Prec.:適合率、陽性と予測したうちで実際に陽性だった割合
- F1:F値、再現率と適合率の調和平均
2. モデルの確認
# create_modelの引数に確認するモデル名を記載
model = create_model('lightgbm')
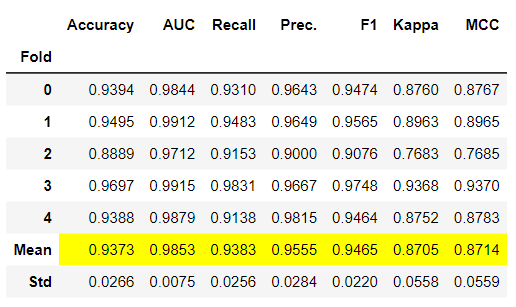
このMeanの値が上記のモデル比較のスコアとなっている
3. ハイパーパラメータの最適化
選択したモデルのハイパーパラメータの最適化を行う(問題なければこれが最終モデルとなる)
# ハイパーパラメータの最適化を行う
final_model = tune_model(model, n_iter = 500, optimize = 'Accuracy')
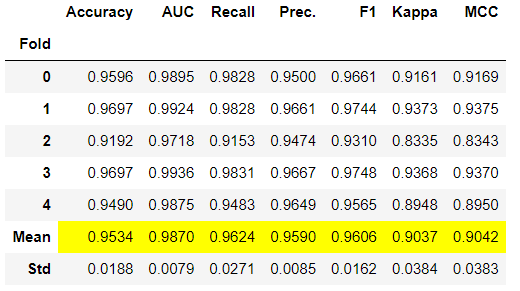
モデルのチューニングが上手くいっていれば、Accuracyなどのスコアが上がる。
次に最適化したモデルで結果を可視化していく(公式: https://pycaret.readthedocs.io/en/latest/api/classification.html)
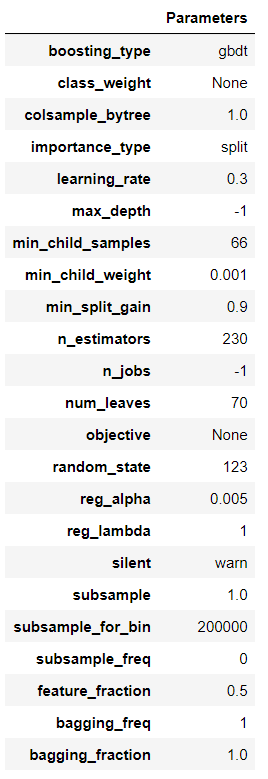
4. モデルのハイパーパラメータの確認
plot_model(final_model, plot = 'parameter')
5. ROC曲線
# 可視化 ROC曲線(デフォルトなので引数は指定なしでよい)
plot_model(final_model, plot="auc")
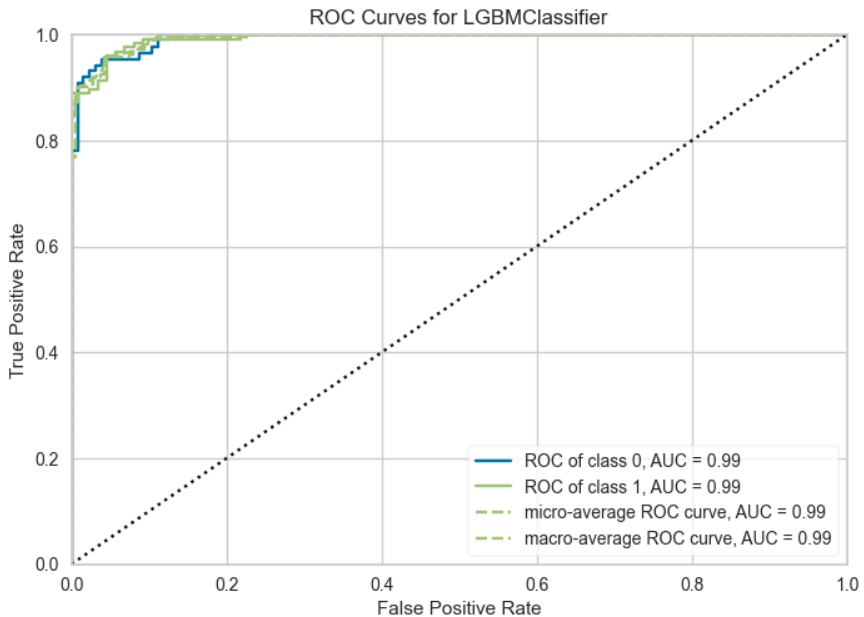
真横軸に偽陽性率、縦軸に真陽性率をプロットした曲線がROC(Receiver Operating Characteristic))曲線である。ROC曲線の下の面積をAUC(Area Under the Curve)と呼び、最大で1で完全にあてずっぽうの時で0.5になる。
6. 混同行列
plot_model(final_model, plot="confusion_matrix")
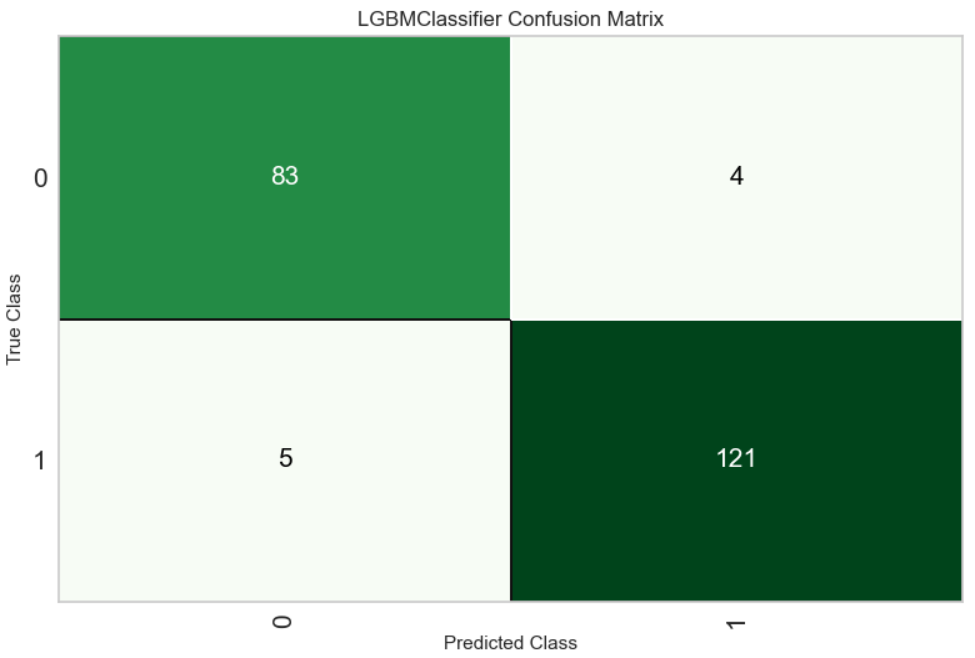
ラベルのつけ方(何が0で何が1か)はデータ読み込み時の"Label Encoded"に記載あり。
7. 予測エラー
plot_model(final_model, plot = 'error')
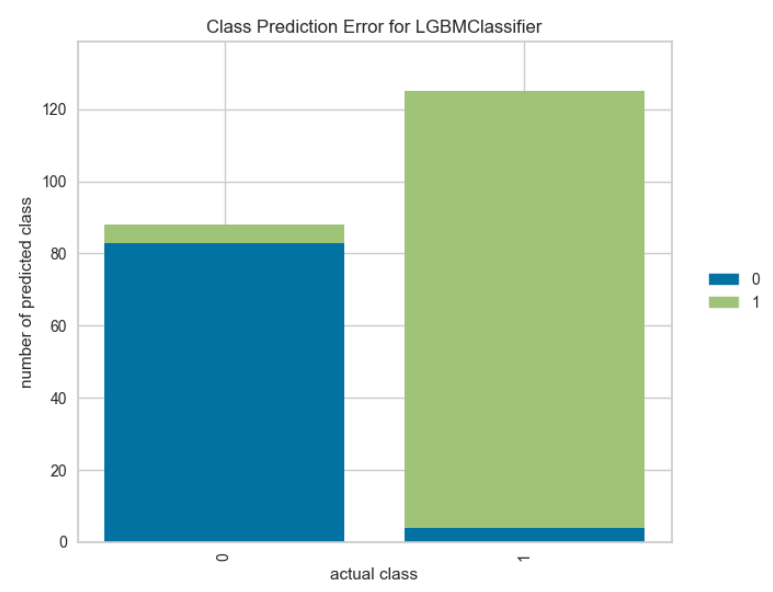
8. クラスレポート
plot_model(final_model, plot = "class_report")
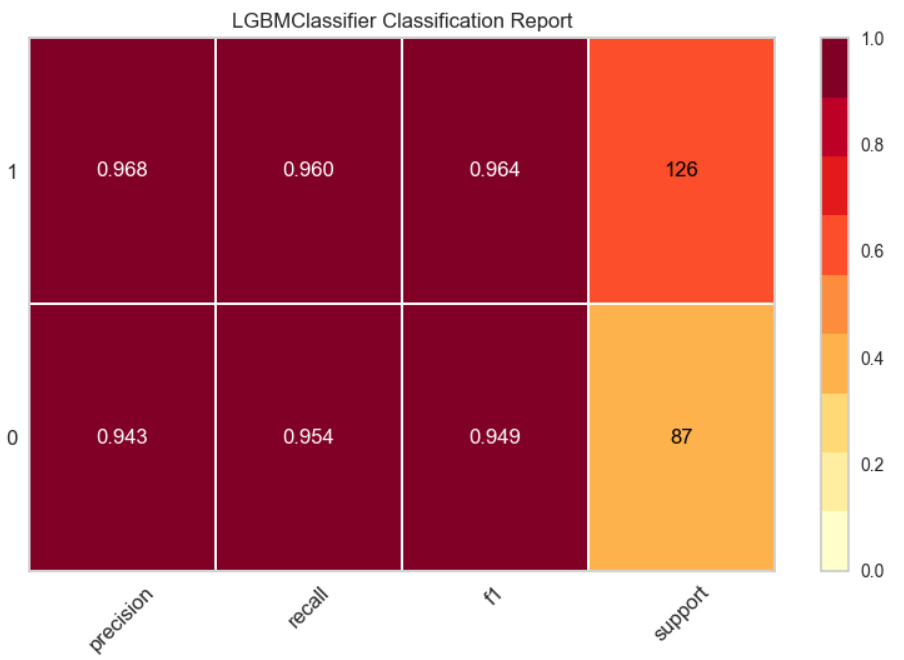
それぞれのクラスのスコアが表示される。
9. 閾値プロット(これは2分類のみの機能)
plot_model(final_model, plot="threshold")
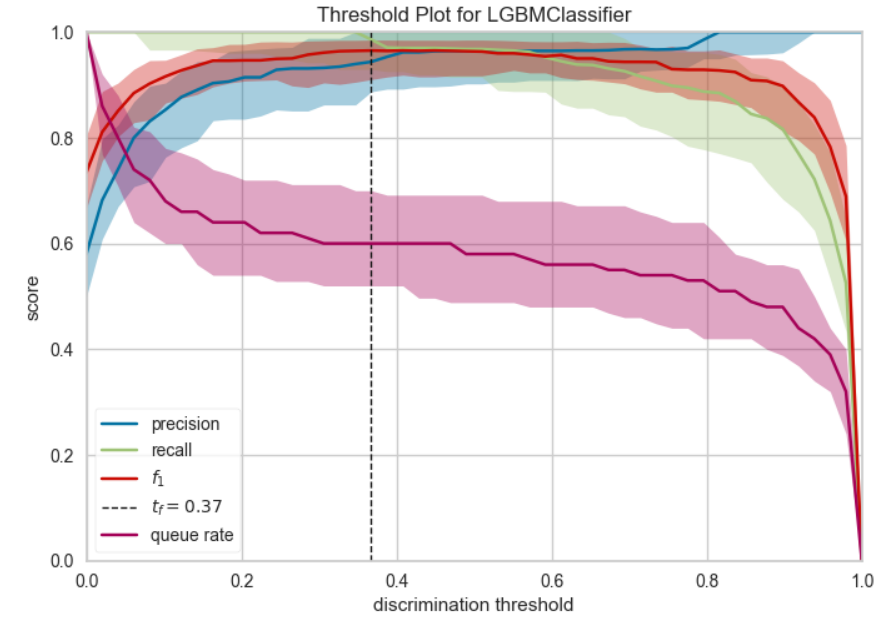
しきい値毎の適合率(Precision)、再現率(Recall)、F1が出力される。最適なF1は垂直の破線としてプロットに表示される(その際の値はtとして表示される)
10. Precision Recallプロット(これは2分類のみの機能)
plot_model(final_model, plot="pr")
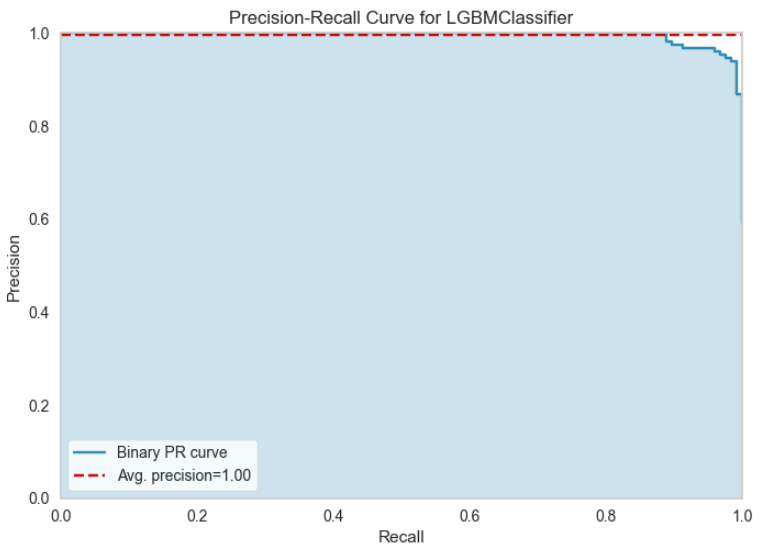
横軸の再現率(Recall)に対して縦軸にプロットされた適合率(Precision)を確認できる。塗りつぶされた領域が大きいほど、分類子は強力になりる。赤い線は平均適合率を示してる。適合率(Precision)と再現率(Recall)共に、どの程度のしきい値であれば予測特性を満たすかの検討に利用できる。再現率と適合率はトレードオフの関係にあるので再現率(横軸)が大きくなると適合率(再現性)は低下傾向にある。
11. 特徴量の選択(これは2分類のみの機能)
plot_model(final_model, plot = 'rfe')
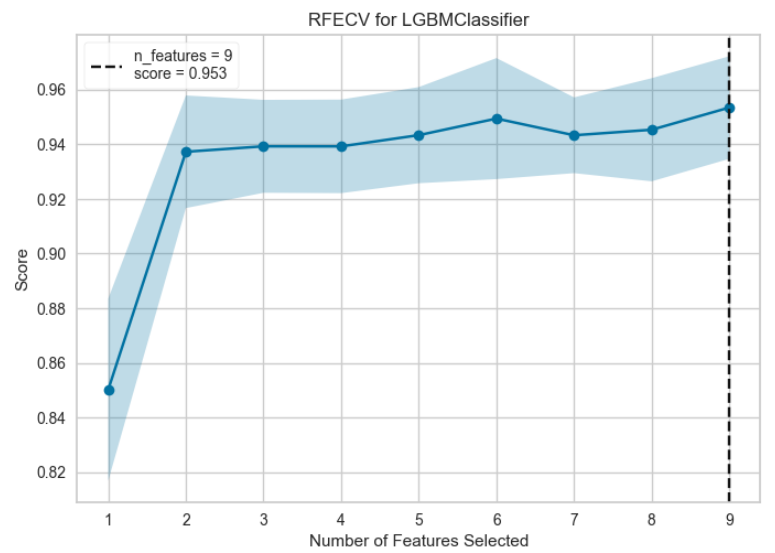
モデルに使う特徴量の数とモデルのスコアの関係を表している。黒の点線で示す特徴量数でモデルのスコアが最大となる。特徴量はのちで計算するFeature Importanceに基づいて順位が高いものから選択される
12. 学習曲線
# 可視化 引数plot = learning で 学習曲線
plot_model(final_model, plot = 'learning')
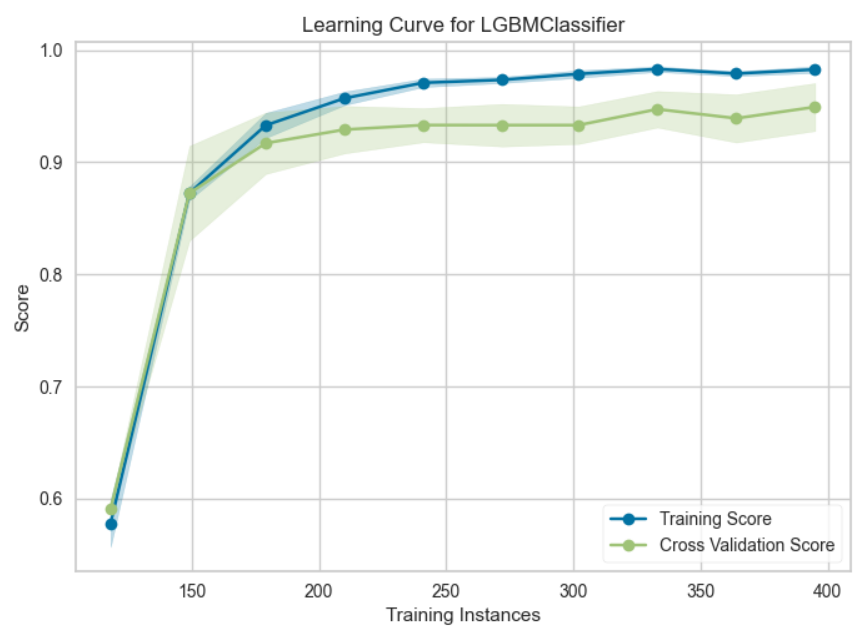
横軸に訓練データのデータ数、縦軸に予測精度をプロットしている。理想的なモデルではサンプルサイズを大きくした時にTrainig Scoreが下がり、CV Scoreが上がっていき、両者が漸近する。漸近する値があらかじめ設定した値よりも大きいとモデルが上手く作られていると考えられる。両者ともにスコアが低い場合は学習不足なのでパラメータを増やす、学習データのスコアだけが高い場合は過学習気味なのでパラメータ数を減らすなどの対策が必要である。両者の差が大きい場合はデータ数を増やしてモデルの精度を上げるなどの対策が必要。
13. 多様体学習(これは2分類のみの機能)
# 可視化 引数plot = manifold で 次元削減を行い、特徴を2次現に射影
plot_model(final_model, plot = 'manifold')
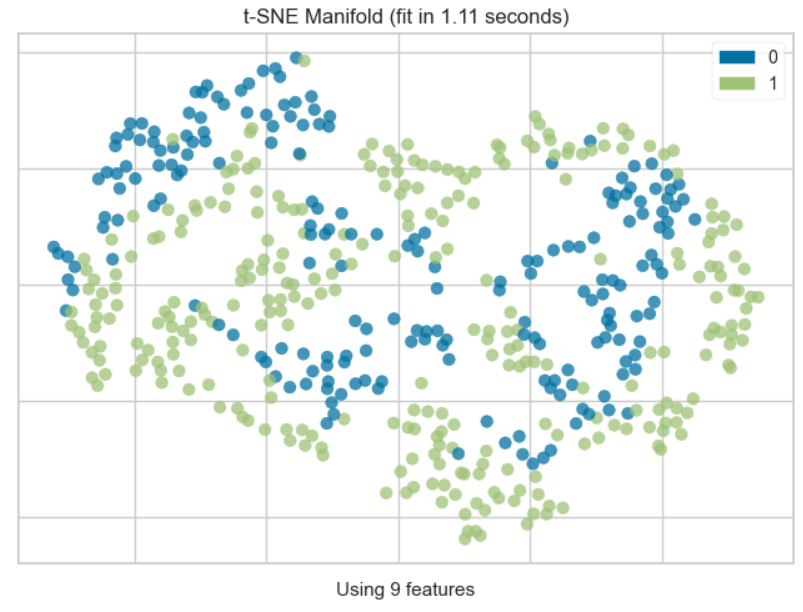
t-SNE(t-Distributed Stochastic Neighbor Embedding:t分布型確率的近傍埋め込み法)によって高次元データを2次元に落としてプロットしたグラフ。ここで上手く傾向が見えるようであれば次元削減を行ってモデル解釈性を上げることも可能である。
14. 検証曲線
# 可視化 引数plot = vc で 検証曲線
plot_model(final_model, plot = 'vc')
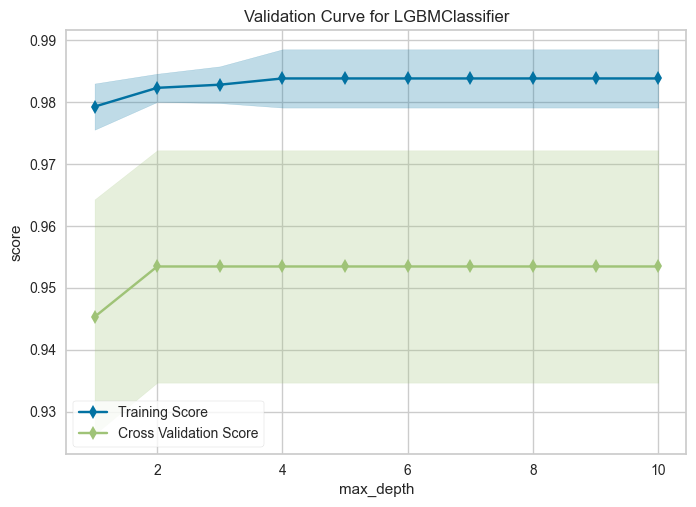
15. ディメンジョン
plot_model(final_model, plot = 'dimension')
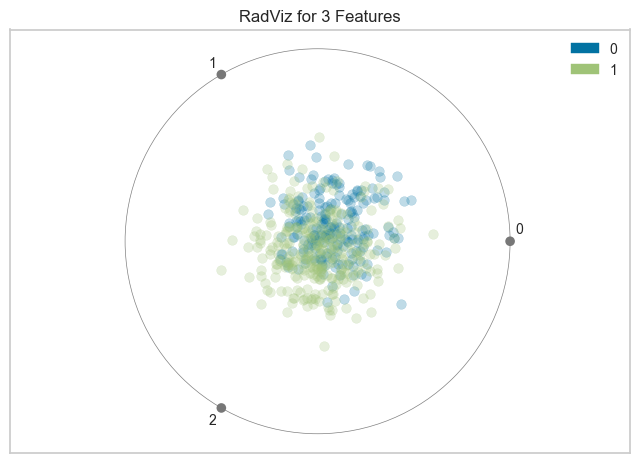
多変量データ可視化アルゴリズム。円周上に各特徴次元を一様に配置し、各特徴量を正規化して、中心から各円弧までの軸上に点をプロットします。このメカニズムにより、たくさんの次元を持つデータを円内に簡単に描画しすることができます。
https://www.scikit-yb.org/en/latest/api/features/radviz.html
16. 特徴量の重要度
# 可視化 引数plot = feature で特徴重要度プロット
plot_model(final_model, plot = 'feature')
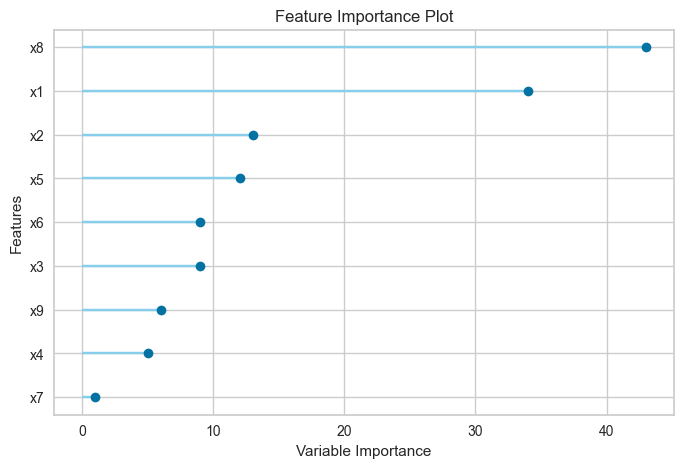
# 以下のコードで全ての特徴量に対して重要度を算出することも可能
plot_model(final_model, plot = 'feature_all')
17. 決定境界
plot_model(final_model, plot = 'boundary')
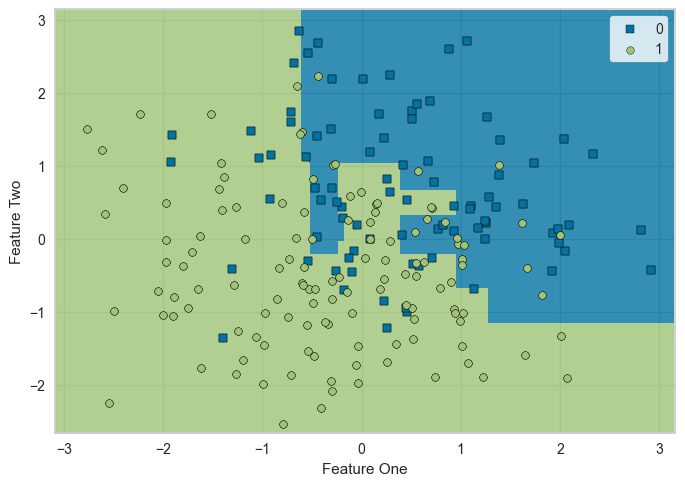
クラスを分類する決定境界
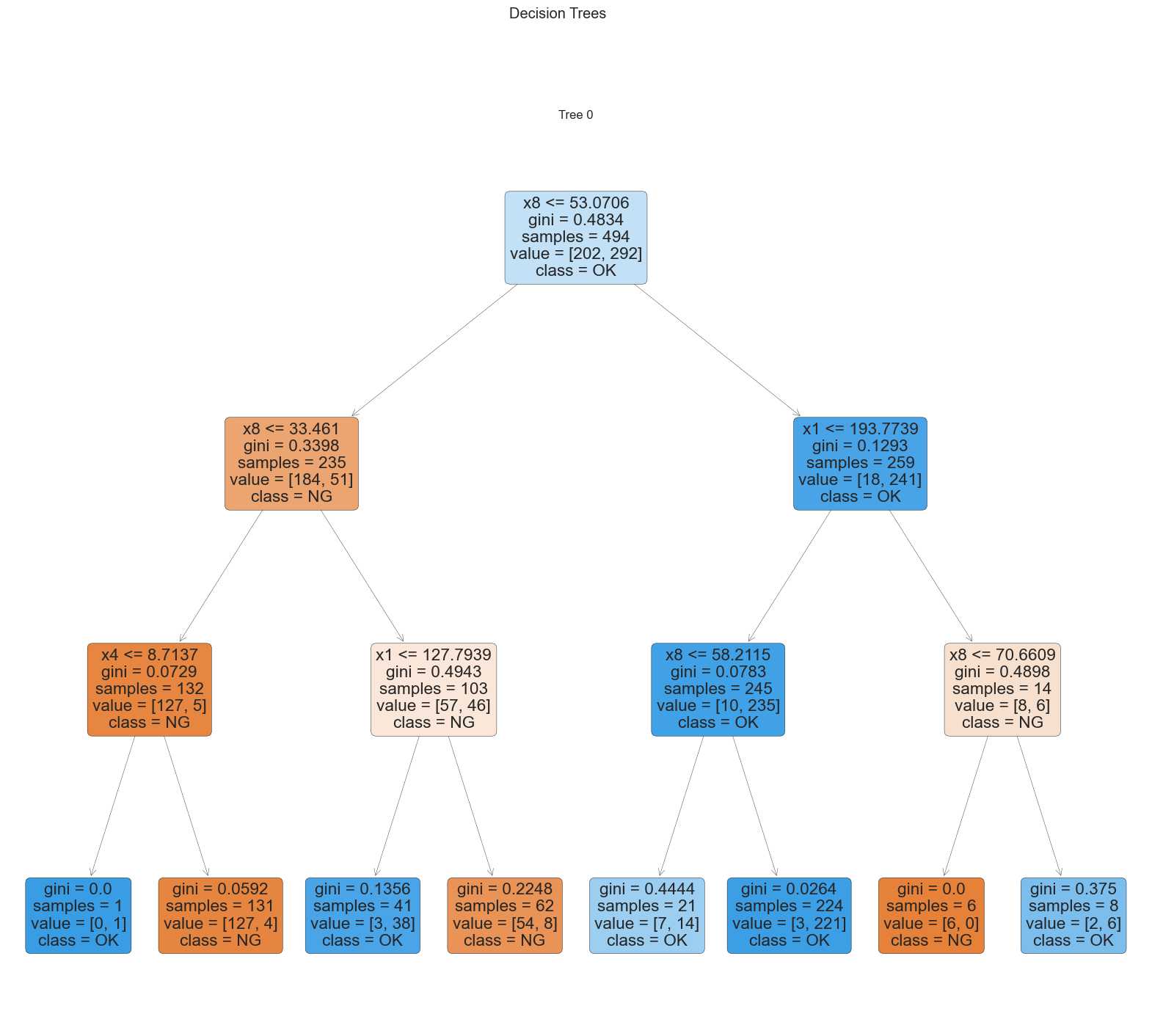
18. 決定木
# 小さな決定木のモデルを作って、特徴量の関係を可視化する
dt = create_model('dt', max_depth=3)
plot_model(dt, plot = 'tree')
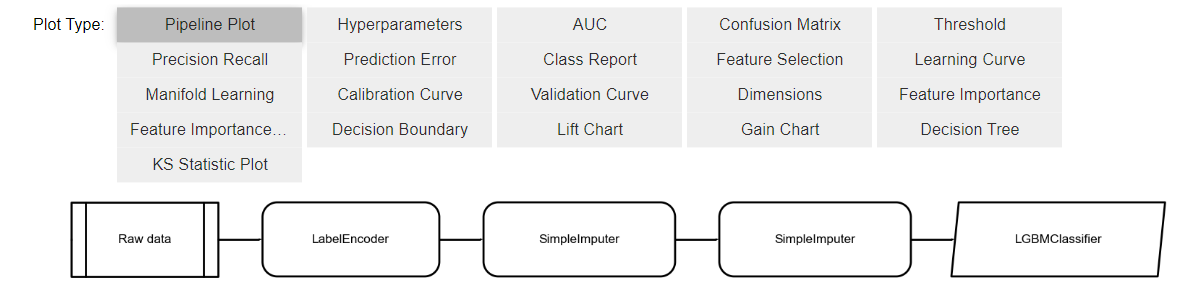
19. plot_model一覧
# これまでに出力したplot_modelを確認できる
evaluate_model(final_model)
20. モデルの確定
final_model = finalize_model(final_model)
print(final_model)
Pipeline(memory=FastMemory(location=C:\Users\*ユーザー名に基づくディレクトリ*\AppData\Local\Temp\joblib),
steps=[('label_encoding',
TransformerWrapperWithInverse(exclude=None, include=None,
transformer=LabelEncoder())),
('numerical_imputer',
TransformerWrapper(exclude=None,
include=['x1', 'x2', 'x3', 'x4', 'x5', 'x6',
'x7', 'x8', 'x9'],
transformer=SimpleImputer(add_indicator=False,
copy...
boosting_type='gbdt', class_weight=None,
colsample_bytree=1.0, feature_fraction=0.5,
importance_type='split', learning_rate=0.3,
max_depth=-1, min_child_samples=66,
min_child_weight=0.001, min_split_gain=0.9,
n_estimators=230, n_jobs=-1, num_leaves=70,
objective=None, random_state=123,
reg_alpha=0.005, reg_lambda=1, silent='warn',
subsample=1.0, subsample_for_bin=200000,
subsample_freq=0))],
verbose=False)
# モデルの保存( ''の中は保存したいファイル名)
save_model(final_model,"Final_Model")
21. 予測の実行
今回作成した予測モデルを使って以下のcsvファイルのデータを予測していきます。
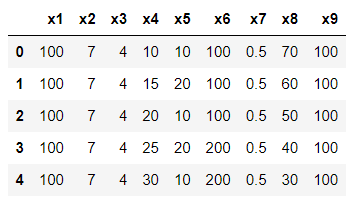
# 予測するデータを読み込む
data_unseen = pd.read_csv("df_new.csv")
data_unseen.head()
読み込んだデータとモデルを組むために使ったデータの説明変数は一致させておく必要があるので注意
# 最終化したモデルで未知データを予測
unseen_predictions = predict_model(final_model, data=data_unseen)
pd.DataFrame(unseen_predictions)
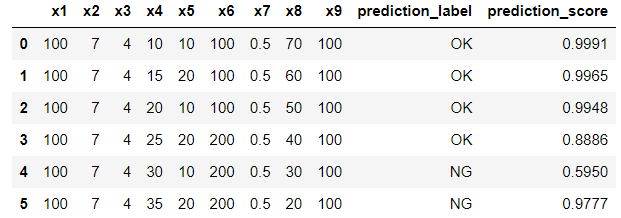
未知データに対して、LabelとScoreを返してくれる。LabelはOK/NGなど最初のデータセットに対してのラベルが返ってきて、Scoreはその予測に対する確率が返ってくる。