注意
サンプルデータなどはみどりぼん筆者のサイトを参照
(みどりぼん=データ解析のための統計モデリング入門:久保拓弥著)
目的
- R初心者が、みどりぼんに書いてあるRのサンプルを理解する。
- 統計の内容については対象外、あくまでR
内容
データのロード:load()(と作業ディレクトリの取得、移動)
みどりぼん本文中には
load("data.RData")
と書いてあったが、現在の作業ディレクトリもわからないので、
getwd()
を実行すると[1]、現在のディレクトリが表示される。ディレクトリの移動は
setwd("移動したいパス")
で可能。
あとは先述の通りロードするだけ。
コマンドライン出力:print(data), 配列の長さ出力:length(data), (脱線:Rにおける型)
本文通り
>print(data)
[1] 2 2 ...
[26] 3 7 ...
となる。なんとなく分かりづらい(と私は思った)。
しかしただ単にdataは50個の要素が入っている一次元のデータ。
以下を実行するとまあまあわかる。
>print(data[0])
numeric(0)
>print(data[1])
[1] 2
>print(data[50])
[1] 3
>print(data[51])
[1] NA
一番はじめのdata[0]については、[2]に書いてあるように
要素番号として 0 を指定すると,長さ 0 で元のベクトルと同じ型のベクトルが返る
とのこと。numericは実数らしい。Rにおける型は[3]を参照。
かなり脱線したが話を戻して、dataが50個だと確かめるためには、
>length(data)
[1] 50
となる。
データの概要を出力:summary()
dataにおける特徴を手っ取り早く知るためにsummary()を使う。
>summary(data)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.00 2.00 3.00 3.56 4.75 7.00
Min:最小値
1st Qu.:いわゆる、第一四分位数
Median:中央値(=第二四分位数)
Mean:平均値
3rd Qu.:第三四分位数
Max:最大値
度数分布を出力:table()
度数分布を得るためにはtable()を用いる。
>table(data)
data
0 1 2 3 4 5 6 7
1 3 11 12 10 5 4 4
言うまでもないが、dataの要素のうち、0のものが1つ、1のものが3つ、2のものが11個…ということ。
ヒストグラムを出力:hist()
ヒストグラムを得るためにはhist()を使う。
まず、本文とは違う方法、
hist(data)
を試すと以下を得る。
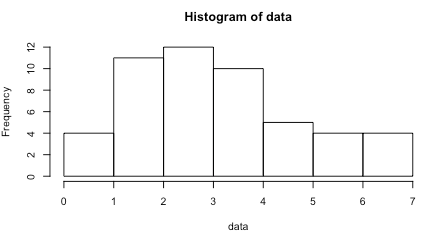
0から1のデータの頻度(frequency)が4になっている。table(data)の結果を見れば、これは要素が0のもの(1)と1のもの(3)を足して4が出ていることが予測できる。他の1から2の頻度(=11)は要素が2である要素数、2から3の頻度(=12)は要素が3である要素数…となっていることがわかる。つまり、この方法でプロットすると、惜しいものは出るが、要素が0,1のものが区別できなくなる。(後、わかりづらい)
そこでhist()の第二引数で横軸を設定する。-0.5から0.5のところに要素が0の要素数、0.5から1.5に要素が1の要素数…とすればちょうど良い。
これを実現するために本文中では、(-0.5, 0.5, 1.5, 2.5, ... 9.5)となる配列を作っている。
これは
seq(-0.5, 9.5 1)
で実現できる。-0.5から9.5まで、1飛びで配列を作ってね、ぐらいの意味(だと思う)。
この配列で、ヒストグラムを分割してほしい(だから break?)ので、breakコマンドでこの配列を指定する。
つまり
hist(data, breaks = seq(-0.5, 9.5 1))
とすれば、欲しいものが得られる(図は省略)
データの標本分散を出力:var()
(統計の話はしないと言ったけど…)var(data)で出力されるのは以下で与えられる標本分散、$s^2$(ただし$\bar{x}$は平均値、$n$はデータ総数)
s^2 = \frac{1}{n}\sum_{i=1}^{n}(x_i-\bar{x})^2
標本標準偏差、$s$を得るためには、sd(data)とするか、sqrt(var(data))とすれば良い。
変数への代入: <-
いちいち書く必要ないかもしれないが…
Rでは代入を<-を使って行うらしい[4](まとめていてはじめてわかった)。
> y <- 0:9
> print(y)
[1] 0 1 2 3 4 5 6 7 8 9
上記の本文中の例ではyについて0から9までを代入している。その後のprint(y)の結果を見れば、このことはよくわかる。
ポアソン分布: dpois(x, lambda)
[5]によれば、dpois(x, lambda)でポアソン分布が定義されている。みどりぼん本文中では
prob <- dpois(y, lambda = 3.56)
としている。これは変数probに、yの各要素における、平均3.56のポアソン分布における値を代入する、という意味になるようだ。
プロット:plot(x, y)
plot(x, y)でプロット。みどりぼん本文中では
plot(y, prob, type="b", lty = 2)
となっており、type,およびltyでプロットの種類および線種を設定。type="b"で折れ線かつ点をプロット、lty = 2で破線にする。詳しくは[6]を参照。
列ベクトル、行ベクトルの結合:cbind(), rbind()
みどりぼん本文中では、以下でyとprobを見比べている。
> cbind(y, prob)
y prob
[1,] 0 0.02843882
[2,] 1 0.10124222
[3,] 2 0.18021114
[4,] 3 0.21385056
[5,] 4 0.19032700
[6,] 5 0.13551282
[7,] 6 0.08040427
[8,] 7 0.04089132
[9,] 8 0.01819664
[10,] 9 0.00719778
だが、cbind()は列ベクトル単位で結合するコマンド[7]。もちろん以下のようにすれば結合した結果の行列を保持できる。
newy <- cbind(y, prob)
行ベクトル単位で結合させるコマンドはrbind()。
ヒストグラムとポアソン分布を重ねてプロット
みどりぼん中ではさらっとしか書いてありませんが、ヒストグラムとポアソン分布を重ねてプロットするためには以下のようにすれば良い[8]。
hist(data, breaks = seq(-0.5, 9.5, 1))
points(y, prob * 50)
lines(y, prob * 50, lty = 2)
一行ずつ丁寧に見る。
hist(data, breaks = seq(-0.5, 9.5, 1))
これは先述の通りヒストグラムを作成
points(y, prob * 50)
これ単体で実行すればわかるが、(y, prob*50)について、点でプロットする。
prob * 50としているのは、(みどりぼん中にも書いてあるが)、prob自体はポアソン分布であり、確率である。ヒストグラムと同じ軸で比較するためには、データの個数、つまり50でかけなければならない。
lines(y, prob* 50)
これも単体で実行すればわかるが、(y, prob*50)について、破線でプロットする。
以上まとめると、まずヒストグラム、次に点、最後に折れ線の順にプロットすることで、グラフを重ねることが可能である。
同一グラフに複数データプロットおよび凡例
別記事にしました。
https://qiita.com/okd46/items/207ebba11d1530b30f06
ただし、
labels <- c(3.5, 7.7, 15.1)
等とすれば、labelsは(3.5, 7.7, 15.1)という3つの要素を持つベクトルになる[9]。
レイアウトを変更して、複数のグラフを条件を変えながらプロット
これも別記事にしました。
https://qiita.com/okd46/items/bd8ff67c39016d4a3dd7
横軸変数、縦軸関数に変数値を代入した結果をプロット[8]
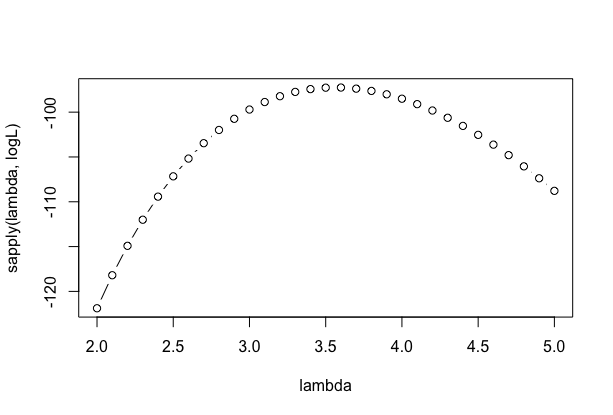
横軸$\lambda$、縦軸対数尤度のグラフ。
上の記事ので紹介したsapplyを使えば可能。
logL <- function(m) sum(dpois(data, m, log = TRUE))
lambda <- seq(2, 5, 0.1)
plot(lambda, sapply(lambda, logL), type = "b")
sapplyはリストに対して関数を実行する。
今回はlambda = (2, 2.1, 2.2, ..., 5)に対してlogLを実行する。
確認のためsapplyでの戻り値を出力してみると以下のようになり、対数尤度が各lambdaに対してベクトルとして格納されていることがわかる。
> print(cbind(lambda, sapply(lambda,logL)))
lambda
[1,] 2.0 -121.88118
[2,] 2.1 -118.19653
[3,] 2.2 -114.91597
#(長いので略)
[31,] 5.0 -108.78143
蛇足(もっとみどりぼんに合わせる)
ここまでは[8]のものをそのまま引用した。
もっとみどりぼんに載っているものに合わせようとすると、以下の記事のようになる。
https://qiita.com/okd46/items/7a98dd9b3a31dc0b502f
参考文献
[1] https://qiita.com/d-cassette/items/59bb6e4b9bbf8e53d2a9
[2] http://cse.naro.affrc.go.jp/takezawa/r-tips/r/13.html
[3] http://cse.naro.affrc.go.jp/takezawa/r-tips/r/25.html
[4] https://qiita.com/stkdev/items/6aba2c1db2fa056170ae
[5] http://www.okadajp.org/RWiki/?R%E3%81%AE%E5%9F%BA%E6%9C%AC%E3%83%91%E3%83%83%E3%82%B1%E3%83%BC%E3%82%B8%E4%B8%AD%E3%81%AE%E7%A2%BA%E7%8E%87%E5%88%86%E5%B8%83%E3%80%81%E4%B9%B1%E6%95%B0%E9%96%A2%E6%95%B0%E4%B8%80%E8%A6%A7#j142252b
[6] http://cse.naro.affrc.go.jp/takezawa/r-tips/r/53.html
[7] http://cse.naro.affrc.go.jp/takezawa/r-tips/r/19.html
[8] http://rpubs.com/kaz_yos/kubobook2
[9] http://cse.naro.affrc.go.jp/takezawa/r-tips/r/12.html