ご挨拶
初めまして!データサイエンスビギナーのokayuhと申します。
今回が記念すべき初投稿です!
自分の備忘録も兼ねて、色々投稿していこうと思っています!
どうぞよろしくお願いします!
環境
Ubuntu 20.04 LTS
Python 3.8.5
Introduction
Kaggle初心者として「Titanic - Machine Learning from Disaster」コンペにトライ中です。
与えられたデータの中で欠損値のない「乗船客の名前(Name)」を、何かの特徴量として使えないか考えてみました。
乗船客の名前を眺めていると、敬称(Mr や Mrs など)が含まれていそうでした。
そこで、貴族やドクターのような特別な敬称を有する人は生存率が高いのではと考え、Nameに含まれる敬称に着目してみました。
Methods & Results
Kaggleのサイトからダウンロードしたtrainデータの乗客名は、以下のように含まれています。
| PassengerId | Survived | Name |
|---|---|---|
| 1 | 0 | Braund, Mr. Owen Harris |
| 2 | 1 | Cumings, Mrs. John Bradley |
| 3 | 1 | Heikkinen, Miss. Laina |
| 4 | 1 | Futrelle, Mrs. Jacques Heath |
| 5 | 0 | Allen, Mr. William Henry |
ここから、ひとまず "Mr" や "Mrs" の敬称の部分を抜き取ってきて、新しい特徴量にします。
そこでまずは、
- 文字列なのでre パッケージを使って、欲しい部分だけを抽出すること
- 敬称の前には ", "(カンマ) が来て、敬称の後には ". "(ピリオド)が来るのでこれをキーとすること
を試してみました。
コードは以下です。
import numpy as np
import pandas as pd
import re
# Kaggleからダウンロードした各種データセット
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
gender_submission = pd.read_csv('gender_submission.csv')
# trainとtestデータを統合
data = pd.concat([train, test], sort = False)
# ピリオドはメタ文字なので、バックスラッシュでエスケープ
# dataのName列から1要素ずつループ処理
honor = [re.findall(',\s.*\.', name)[0] for name in data['Name']]
# 抽出時に含まれたカンマ、半角スペース、ピリオドを削除
honor = [re.sub(',', '', h) for h in honor]
honor = [re.sub('\s', '', h) for h in honor]
honor = [re.sub('\.', '', h) for h in honor]
# dataに新しく設定したHonorificTitle列に抽出した敬称を挿入
data['HonorificTitle'] = honor
data['HonorificTitle'].value_counts()
HonorificTitleに登録されたものの一覧
| HonorificTitle | count |
|---|---|
| Mr | 757 |
| Miss | 260 |
| Mrs | 196 |
| Master | 61 |
| Rev | 8 |
| Dr | 8 |
| Col | 4 |
| Mlle | 2 |
| Ms | 2 |
| Major | 2 |
| Dona | 1 |
| theCountess | 1 |
| Don | 1 |
| Jonkheer | 1 |
| MrsMartin(ElizabethL | 1 |
| Mme | 1 |
| Capt | 1 |
| Lady | 1 |
| Sir | 1 |
| Name: HonorificTitle, dtype: int64 |
よく聞くような、Mr や Miss, Mrs が多くみられます。
Master もそれなりに多いですが、青年男性や少年に使われる敬称のようです。
男の子ということでしょうか?
さらに、Dr や Capt, Mlle のような特別な職種や階級の人も少しいるようです。
MrsMartin(ElizabethL は、Mrsの後ろのピリオドがなかったために、うまく抽出できなかったものと思われます。
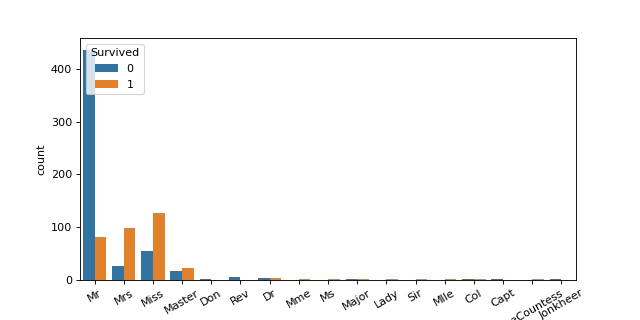
次に、これらの敬称が生存率に影響していそうか、trainデータ内のSurvivedの値をもとに可視化してみました。
# "MrsMartin(ElizabethL" の修正
data.loc[data['HonorificTitle'] == 'MrsMartin(ElizabethL', 'HonorificTitle'] = 'Mrs'
# trainデータにHonorificTitle列を追加
train['HonorificTitle'] = data['HonorificTitle'][:len(train)]
import seaborn as sns
# HonorificTitle列の生存率の可視化
plt.figure(figsize = (8, 4), dpi = 80)
ax = sns.countplot(x = 'HonorificTitle', data = train, hue = 'Survived')
ax.set_xticklabels(ax.get_xticklabels(), rotation = 30)
plt.savefig('title.png')
# "Mr", "Master", "Mrs", "Miss" の生存率を算出
pd.crosstab(train['HonorificTitle'], train['Survived'], normalize = "index").loc[["Mr", "Master", "Mrs", "Miss"]]
出力結果(下側が少し切れてしまいました)
| Survived | 0 | 1 |
|---|---|---|
| HonorificTitle | (Dead) | (Survived) |
| Mr | 0.843327 | 0.156673 |
| Master | 0.425000 | 0.575000 |
| Mrs | 0.208000 | 0.792000 |
| Miss | 0.302198 | 0.697802 |
やはり、男性(MrとMaster)の生存率が低く、女性(MrsとMiss)の生存率は低いようです。
男性の敬称の中で見てみると、MasterはMrと比較するとはるかに生存率が高いですが、女性には劣るようです。
女性の敬称の中で見てみると、Missと比べて、Mrsの生存率が高そうです。
これは少し意外で、既婚女性の方が生存率が高そうでした!
(年齢や他の因子も絡んでいそうですが、夫が助けてくれたのでしょうか。。。?)
また、その他のレアな敬称は、人数が少なすぎて比較できませんでした。
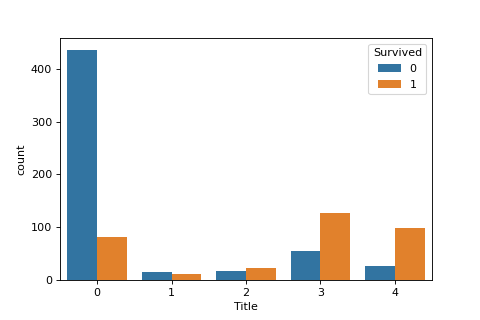
このままでは特徴量として使用できないので、ひとまず生存率の低い順
(Mr -> Other -> Master -> Miss -> Mrs)に、順位をつけてみました。
# Title列に順位を挿入
data['Title'] = 1
data.loc[data['HonorificTitle'] == 'Mr', 'Title'] = 0
data.loc[data['HonorificTitle'] == 'Master', 'Title'] = 2
data.loc[data['HonorificTitle'] == 'Miss', 'Title'] = 3
data.loc[data['HonorificTitle'] == 'Mrs', 'Title'] = 4
# trainデータにTitle列を追加
train['Title'] = data['Title'][:len(train)]
# Title列の生存率の可視化
plt.figure(figsize = (6, 4), dpi = 80)
sns.countplot(x = 'Title', data = train, hue = 'Survived')
ax.set_xticklabels(ax.get_xticklabels(), rotation = 30)
plt.savefig('title.png')
# 各順位の生存率を計算
pd.crosstab(train['Title'], train['Survived'], normalize = "index")
出力結果
| Survived | 0 | 1 |
|---|---|---|
| Title | (Dead) | (Survived) |
| 0 | 0.843327 | 0.156673 |
| 1 | 0.555556 | 0.4444440 |
| 2 | 0.425000 | 0.5750000 |
| 3 | 0.302198 | 0.697802 |
| 4 | 0.208000 | 0.792000 |
これで、敬称を生存率の順に特徴量として入れることができました。
このTitle列を新たな特徴量として追加して、LogisticRegressionでモデルを作成し、testデータの予測を実行してみました。
その結果、、、
Title列 追加前
Public Score 0.66028
Title列 追加後
Public Score 0.76315
と、10%近くスコアを改善することができました!!
Discussion
今回追加したTitle列以外に含まれていたのは、
- チケットのクラス、階級
- 性別
- 年齢
- 運賃
- 乗船地
- 家族の人数
- 1人かどうかのフラグ
の情報です。
Title列では、既婚かどうかの情報が足されているような気がしますが、
実際には女性の生存率が高いということに対してより強い傾斜がかかったのかもしれません。
今後も色々と試してみたいと思います!
Refferences
Kaggleの始め方やTitle以外の特徴量エンジニアリングは、以下の記事を参考させてもらいました。
Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~