超解像コンペの側、物体検出も勉強してみようということで、有名なYOLOモデルの最新版を動かしてみて、自作データの作成、学習までの方法を紹介します。
環境
Mac OS Monterey ver12
python: 3.8.12
PyTorch: 1.9.0
学習済みモデルの準備
普段ならJupyterやColabでモデルを構築して学習させてとやるところですが、YOLOに関してはGithub上からリポジトリを引っ張ってきて学習させます。
# 作業フォルダ作成
mkdir YOLOv5
cd YOLOv5
# リポジトリをコピー,移動
git clone https://github.com/ultralytics/yolov5
cd yolov5
以降このリポジトリ内のフォルダやファイルを編集していきます。
自作データの作成
物体検出タスクでの自作データセットを作るには
- 画像データ
- 画像データに対するアノテーションデータ
の2つが必要になります。
アノテーションデータとは、画像のどこに物体があるかを示すデータのことで
1.物体のラベル
2.物体を囲む矩形の左上のx座標
3.物体を囲む矩形の左上のy座標
4.矩形の高さ
5.矩形の幅
の5つの情報で構成されています。
ではこの2つを作成していきます。
画像データ
今回は顔検出をしたいので、顔が写っている画像ならなんでもいいと思います。
コチラでスクレイピングして集めた櫻坂メンバーの画像フォルダから30枚ほど使います。
ただ理想は300枚ほど欲しいです。ただその分アノテーションデータの作成が苦行になります。
アノテーションデータ
アノテーションデータ作成には、アノテーションツールを使います。
今回はVoTTというツールを使います。ダウンロードはコチラ。

macならdmgファイルを、windowsならexeファイルをダウンロードしてインストールしてください。
インストールして起動すると以下の画面が開かれるはずです。

新規プロジェクトをクリック。

ソース接続の横のAdd Connectionをクリック。
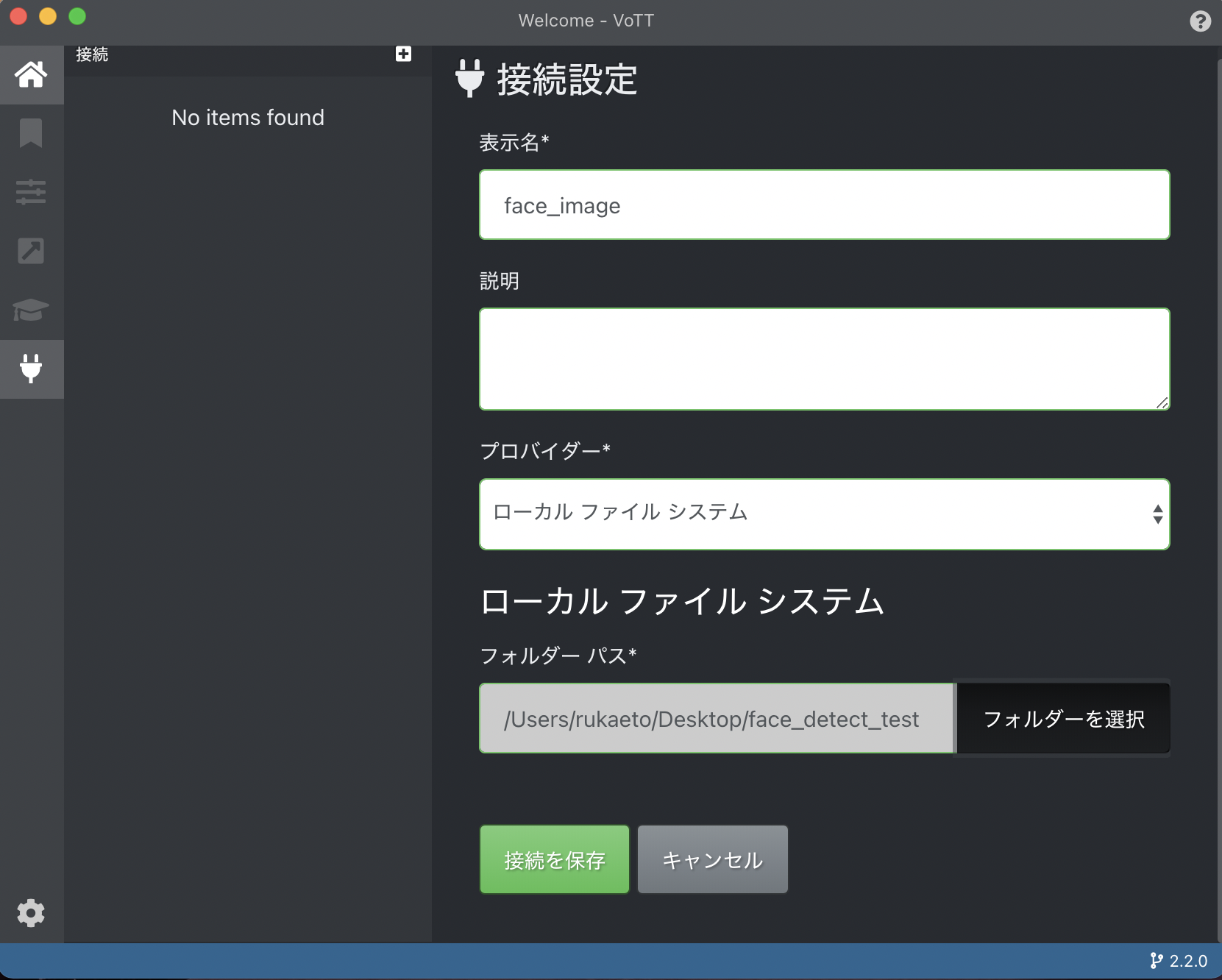
表示名、説明は自由
プロバイダーはローカルファイルシステムを選択してフォルダーパスのフォルダーを選択をクリックしたら、アノテーション付けする画像が格納されたフォルダを選択します。
最後に接続を保存をクリック。

そうしたらソース接続がさっき設定したフォルダになっているはずです。
今回はフォルダ分けするのがめんどくさいのでターゲット接続も同じフォルダにします。
このターゲット接続に設定したフォルダにアノテーションデータ等必要なものが保存されるので自分の好きなとこでいいと思います。
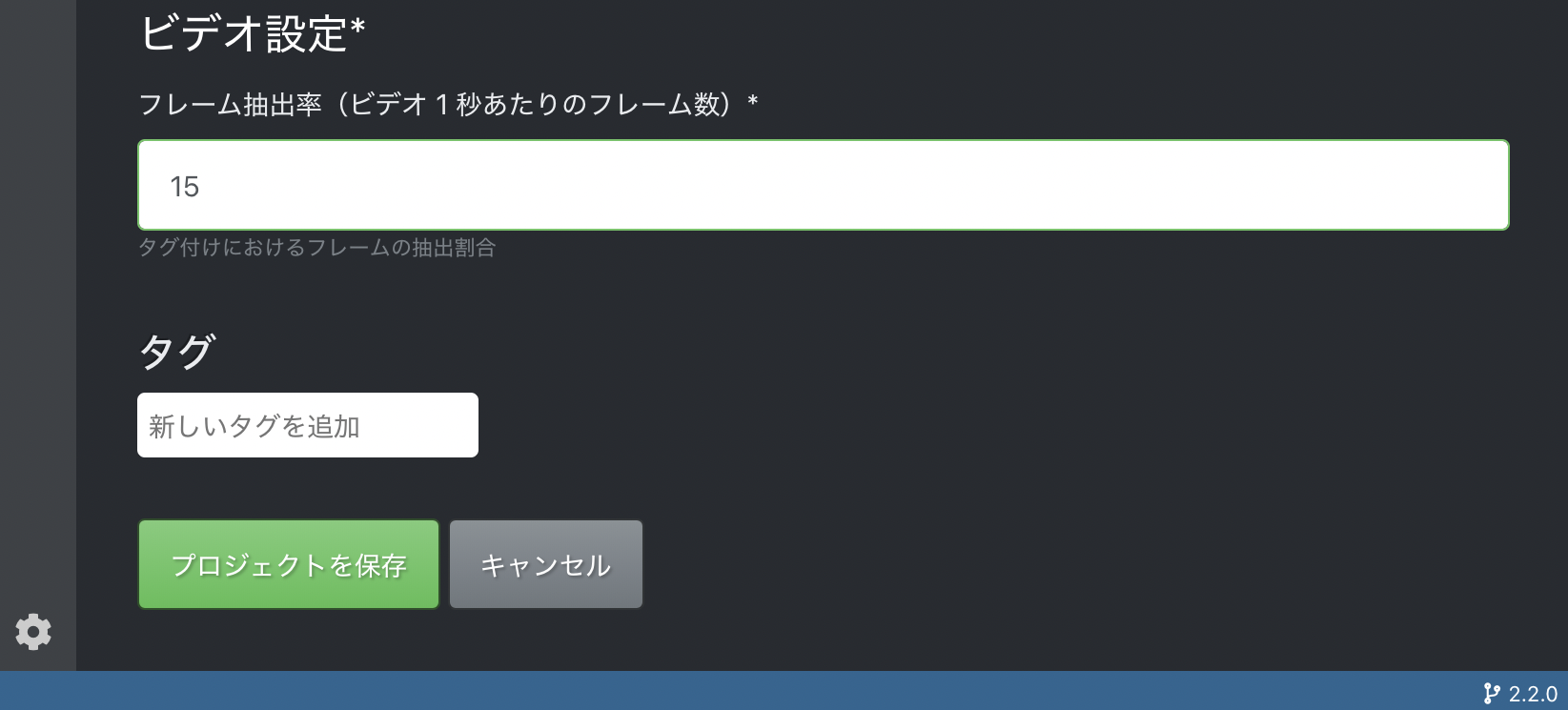
問題なければ一番下のプロジェクトを保存をクリック。
そうすると以下のように編集画面が開くはずです。

使い方は
右のTAGSの+を押して矩形領域につけるラベル名を作成、画像の領域をドラッグして囲って、ラベルを適用する
という流れになります。
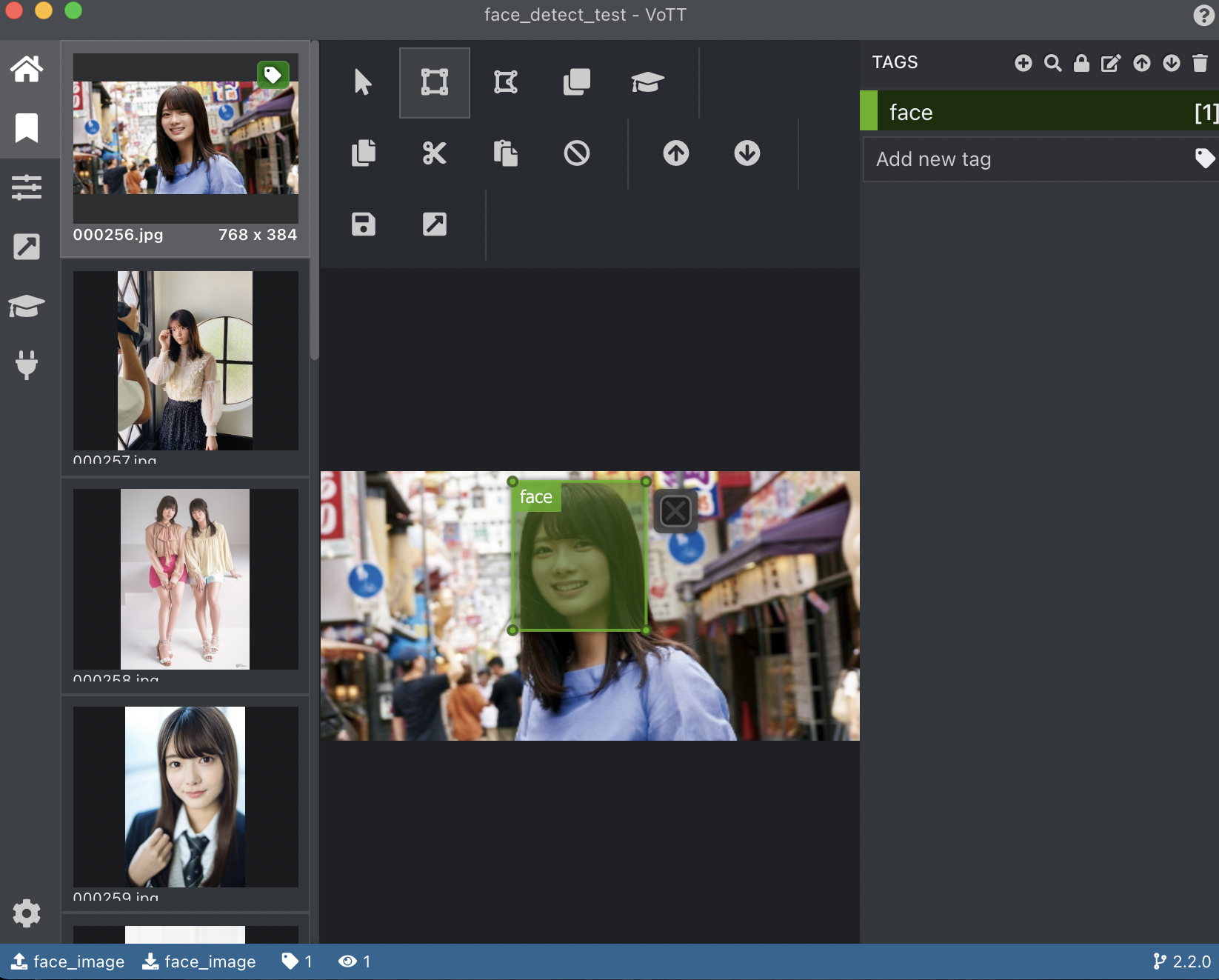
上記のように顔の部分を囲って、右のfaceタグをクリックするだけで囲った矩形領域にfaceというラベルをつけることができます。
操作自体はシンプルで簡単なので、問題ないと思いますがこれを何百枚もやるというのは大変ですね、、、
また複数ラベルだったりすると、1枚アノテーション付けするのに時間がかかっちゃうので、、、(想像もしたくない)
今回は30枚で妥協させてください。
全部アノテーション付けが終わったら、中央のアイコン群のプロジェクトをエクスポートをクリックします。

そうすると先ほどターゲット接続に設定したフォルダ内に

こうしたフォルダが作成されているはずです。この中に画像データとそれに対するアノテーションデータがひとまとめになって入っています。
さてこれで完了!学習と行きたいところですが、このままでは学習には使えません。
作成したデータをYOLOv5でも使える形式に変換する必要があります。
アノテーションデータを変換
VoTTで作成したアノテーションデータをYOLOv5でも使えるようにroboflowというツールを使って変換します。
アカウントを作成してログインすると以下のような画面になるはず(個人情報部分黒くしてます)

初めてログインするとプロジェクトの種類を選ばされるはずなので、Public Projectsでいいと思います。
Create New Projectをクリック。
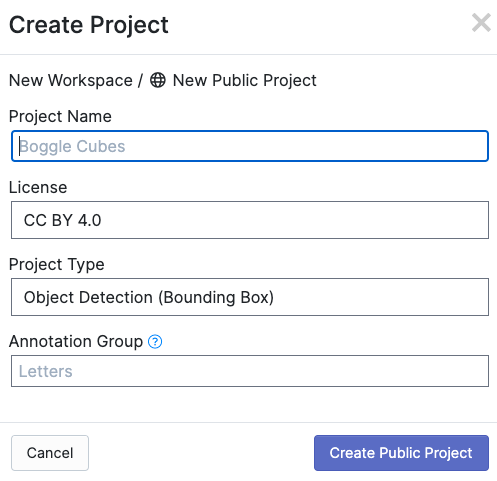
Project Name, Licenseは自由
Project Typeは物体検知なのでObject Detection(Bounding Box)を選択
Annotation Groupは何でもいいですが、アノテーション付けするグループ名(動物、乗り物、人とか)をつけとくといいのではと思います。
僕は以下のようにしました。

これでCreate Public Projectを押すと以下の画面に。

ここに先ほどのvott-json-exportフォルダを丸ごとアップロードします。

All ImagesとAnnotatedの数が一緒なら画像とアノテーションデータが一致して正しく読み込まれています。
大丈夫そうなら右上のFinish Uploadingをクリック。

そうするとTrain, Valid, Testに分割する割合を選択できるので好きなように選択。
別に後で変更もできるので適当で大丈夫です。
Continueをクリック。
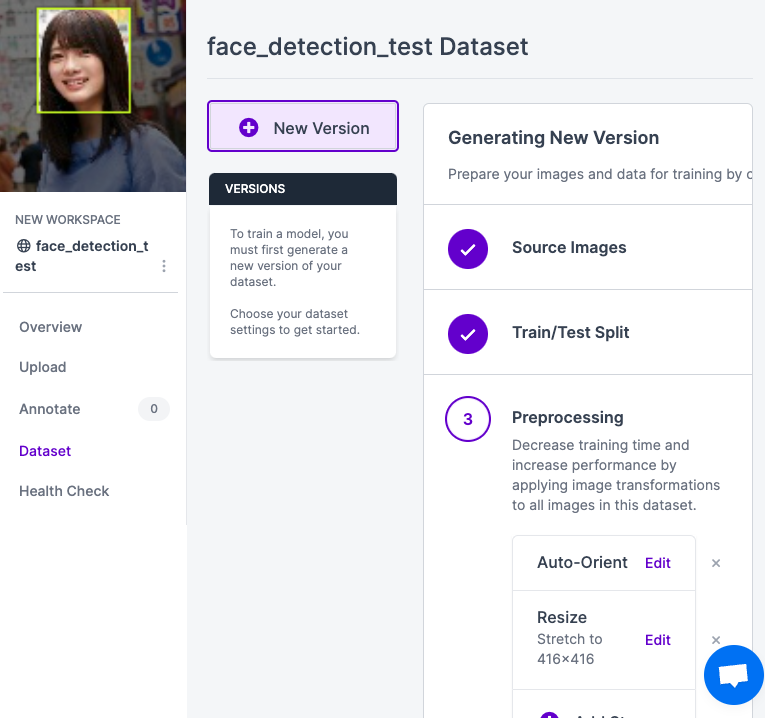
そうしたら、ここまでで右のSource Images, Train/Test Splitまでの工程が完了しています。PreprocessingはデフォルトでAuto-OrientとResizeが設定されています。
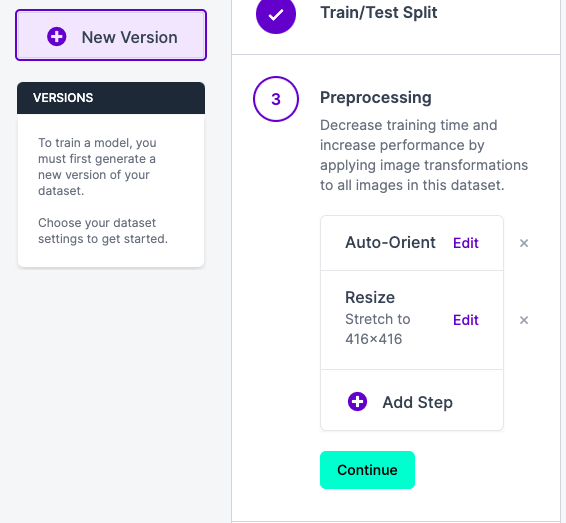
Add Stepをクリックすると

前処理のオプションを選択できるので、もし追加したい場合はここから好きなものを追加しましょう。
今回はデフォルトで行きます。Continueをクリックすると次はAugmentationの設定に移ります。
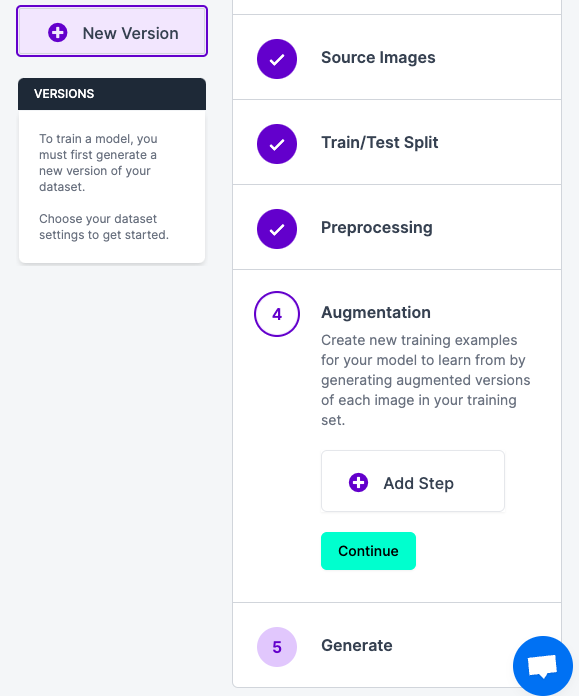
これもAdd Stepをクリックすると

こんな感じでたくさん選択できます。今回はさすがに30枚は少なすぎるので

上記のような水増しで行きます。Continueを押して

Maximux Version Sizeを選択して、Generateをクリックします。無料枠だと3倍までしか選択できません。
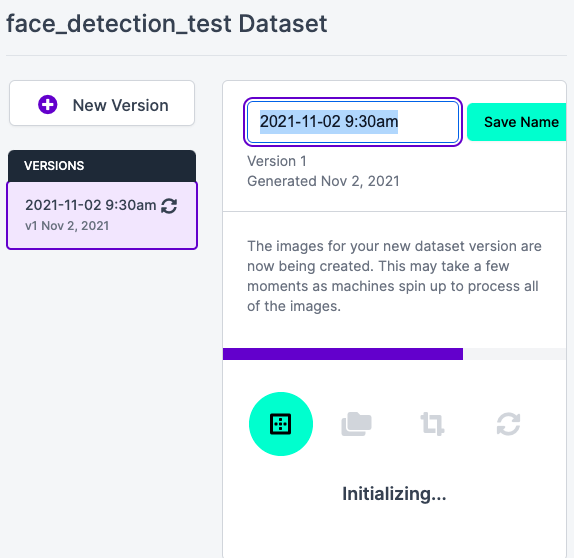

こんな画面になるはずです。
もし新しい水増しを適用させたい場合は左のNew Versionをクリックすれば大丈夫です。
Exportをクリックして

Formatは今回はYOLOv5を使うのでYOLO v5 PyTorchをダウンロード方法は好きな方を選択してContinue。
今回はzipでダウンロードしたので解凍すると

こんな中身になってるはず。
そしたらまずは、train,valid,testフォルダを丸ごと、先ほどコピーしたリポジトリ内のdataディレクトリに移動させます。Jupyter Labで見るとこんな感じ。

次にdata.yamlファイルをyolov5ディレクトリ直下にあるdata.yamlファイルと置き換えます。

このままだとディレクトリを読み込んでくれないのでdata.yamlを以下のように編集します。
train: ./data/train/images
val: ./data/valid/images
test: ./data/test/images
nc: 1
names: ['face']
別にtestの記載はなくてもいいです。
これで学習の準備は整いました。
いざ学習
以下のコマンドをターミナルで実行します。
python train.py --img 416 --data data.yaml --weights yolov5s.pt --batch-size 16
引数の詳細
--img で画像の入力サイズ
--dataで学習用データの詳細を読み込むファイルを指定
--weightsで使用する学習済みモデルの重みを選択
今回は一番小さいyolov5sを使います。
うまくいくとruns/train/expディレクトリに学習の詳細情報が保存されていきます。
result.csvなんかは各種lossの値などがcsv形式で確認できて便利です。
推論
正直データ枚数も少ないので精度は微妙です。
評価データの結果は、学習が終わった時に保存されるval_batch0_pred.jpgに表示されていて、今回はこんな感じになりました。

testデータの画像を推論したい場合は以下のコマンドを実行します。
python detect.py --source data/test/images --weights runs/train/exp/weights/best.pt --conf 0.1
引数の説明
--sourceは推論したい画像の格納先を指定
--weightsは推論時のモデルの重みを選択
--confはある物体が存在する確率がここに設定した確率値以上のものだけを矩形で囲む
学習した重みはruns/train/exp/weightsディレクトリの中にbest.ptとlast.ptの2つが保存されているのでbest.ptで推論します。
実行するとruns/detect/expディレクトリ内に結果画像が保存されています。



まぁ精度はダメダメですね、、、
30枚は少なすぎるので、データ枚数もっと増やす必要がありますね。もしくはエポック数増やすか、モデルを大きいものにするか。
まとめ
YOLOv5を使って物体検知をやる流れを説明しました。
物体検知タスクへのハードルが下がれば幸いです。
知見が深まったら、物体検知の精度アップへの記事も書こうと思います。