はじめに
この記事はNew Relic Advent Calendar 2023 シリーズ1の13日目です。
New Relicの分散トレーシングを確認してElastiCache for Redisが帯域限界まで使用されていることに気づいた話をします。
New Relicでの確認
New Relicの分散トレーシングによってあるトランザクション内で行われる処理の内訳がタイムラインで分析できます。
これはあるトランザクションのスパンです。

弊社の朝日新聞デジタルの記事ページ(例: https://www.asahi.com/articles/ASRDF3R1GRDFUTFK003.html ) についてのトランザクションです。
New Relicでトランザクションを眺めていると、こうしたスパンがいくつか再現していることに気がつきました。
課題
問題はRedisのレスポンス速度が遅すぎることです。
いくら並行処理になってるとはいえ、Redisからのレスポンスが6ミリ秒、5ミリ秒というのは想定外に感じます。
Redisのスロークエリログのデフォルト値がマイクロ秒のオーダーを期待します。
Redisが公式でオプティマイズを案内している資料からも、良い状態とはいえなさそうです。
https://redis.io/docs/management/optimization/latency/
調査
まず、CPUとメモリの使用率を確認しました。
AWSのメトリクスはまだNew Relicに未連携だったのでどちらもCloudwatch Metricsで確認しました。

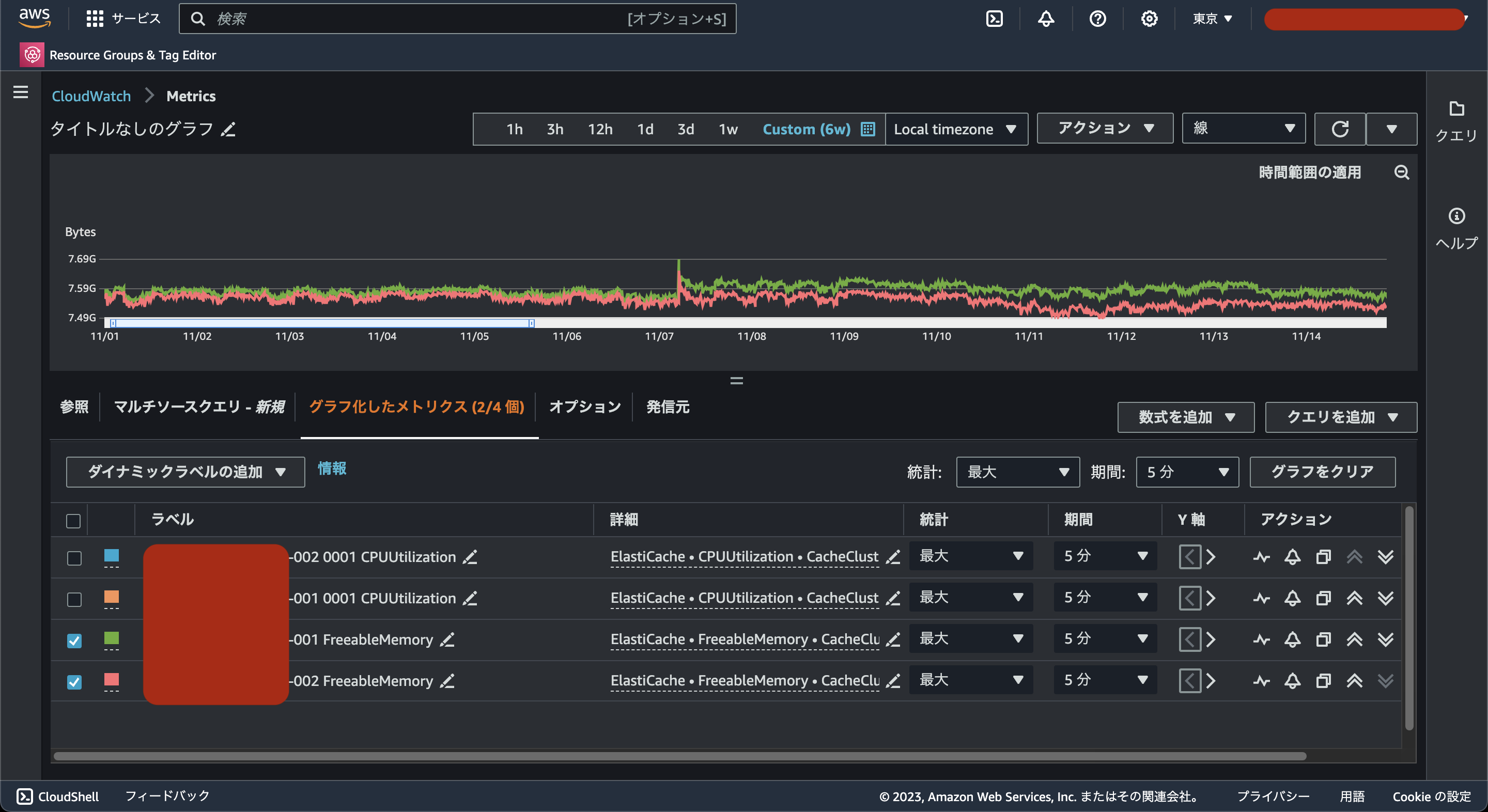
使用しているインスタンスはcache.m4.largeですが、CPU使用率、残メモリともに異常はなさそうです。
コンピューティングリソースに異常はなさそうだったのでネットワーク関連を調査しました。
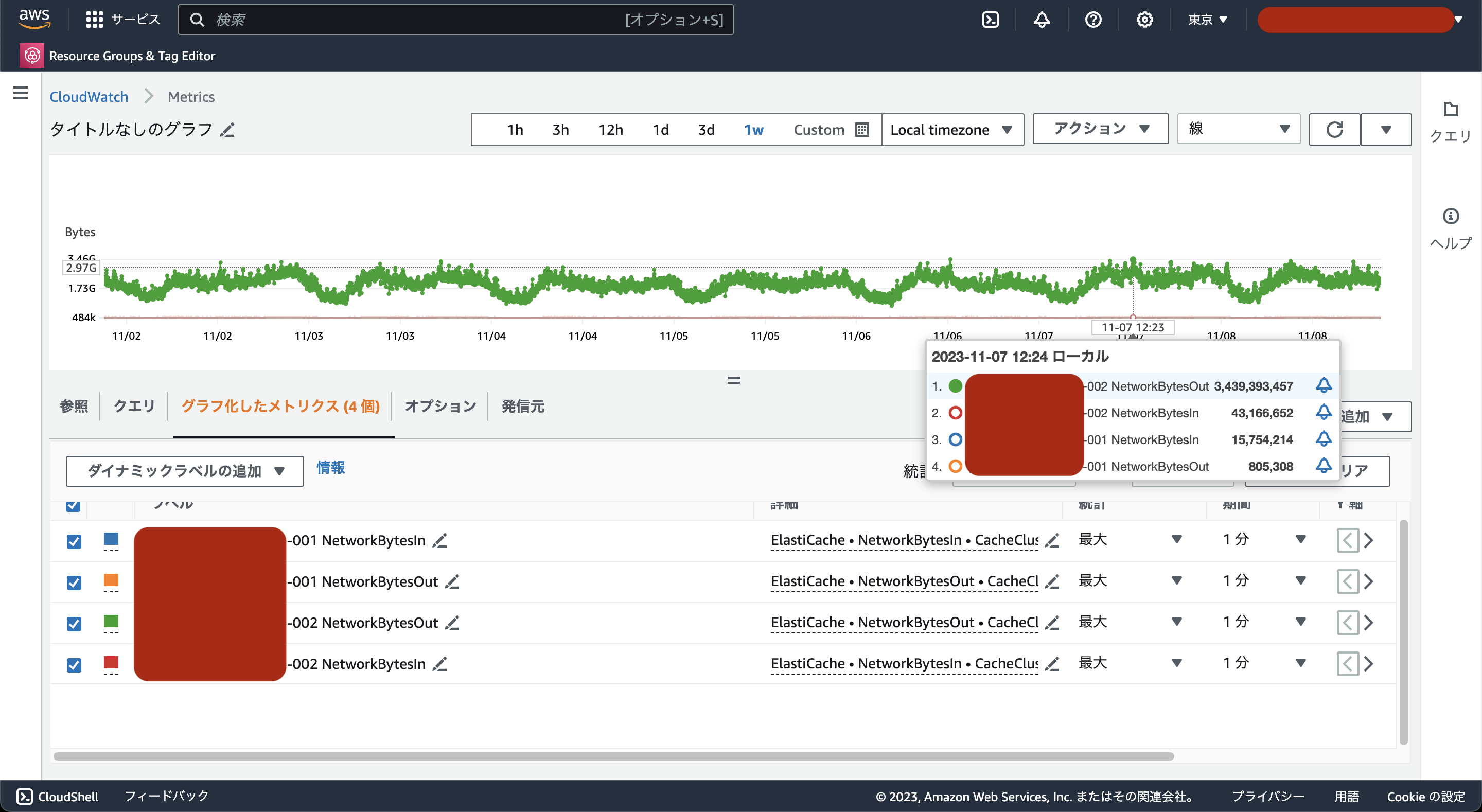
ネットワークのI/Oを確認すると、プライマリインスタンスから外部への通信量が最大で3.4GB/分あることがわかりました。
※今回調査したElastiCache for Redisはクラスターモードを有効にしていますが、2台しかノードがなく、READONLYコマンドを発行していないので全てプライマリインスタンスにリクエストがリダイレクトしています。
原因
ワークロードの通信量がcache.m4.largeのベース帯域の上限に達していました。
3.4GB/分はGbpsに変換すると0.453...Gbpsとなり、ベース帯域の上限に合致します。
そのため、Redisからのキャッシュ取得量が一定以上の時に帯域上限に引っかかってレイテンシが遅くなってしまっていたと推測できます。

解決方針
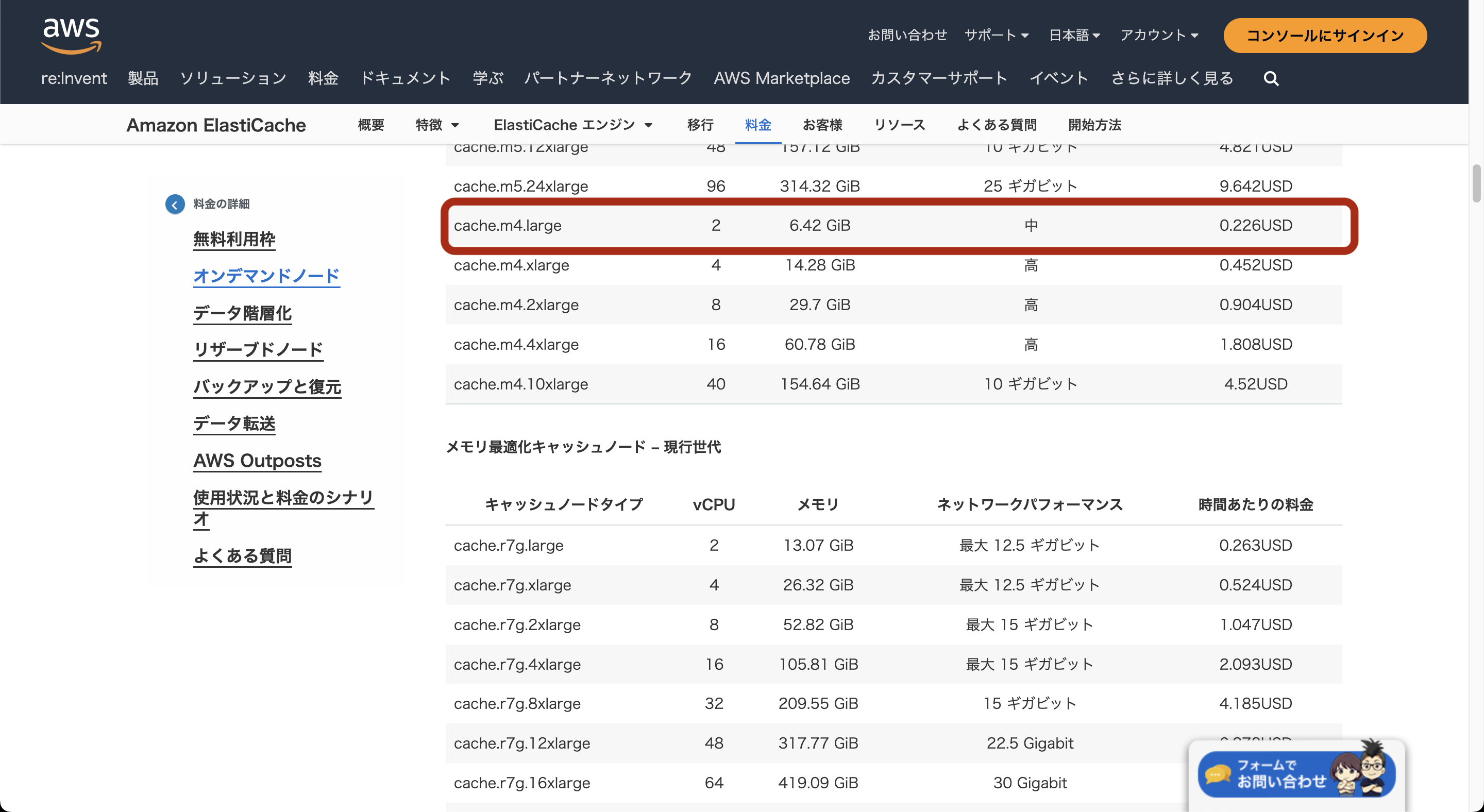
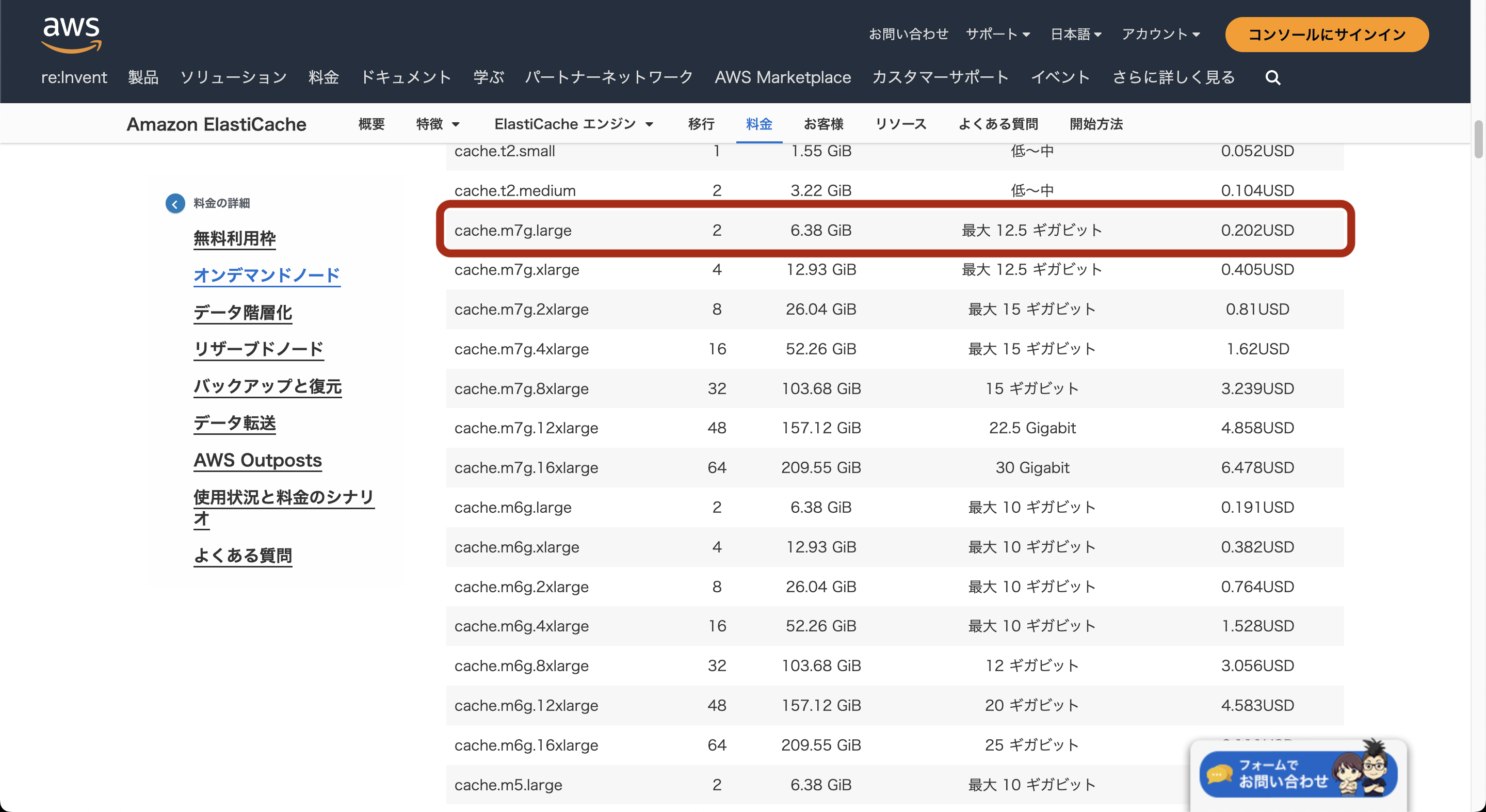
最新のcache.m7g.largeにスケールアップしました。
2vCPU、16GBメモリでcache.m4.largeと同じリソース量ですが、帯域上限がほぼ倍あります。

また、cache.m4.largeは0.226USD/月ですが、cache.m7g.largeは0.202USD/月で使用可能です。
このスケールアップは2023/11/15の01:00~02:00(JST)で行いました。
New Relicで当初課題となったトランザクションのRedisのレスポンス速度を見てみると、スケールアップ前後で20%程度向上していることがわかります。
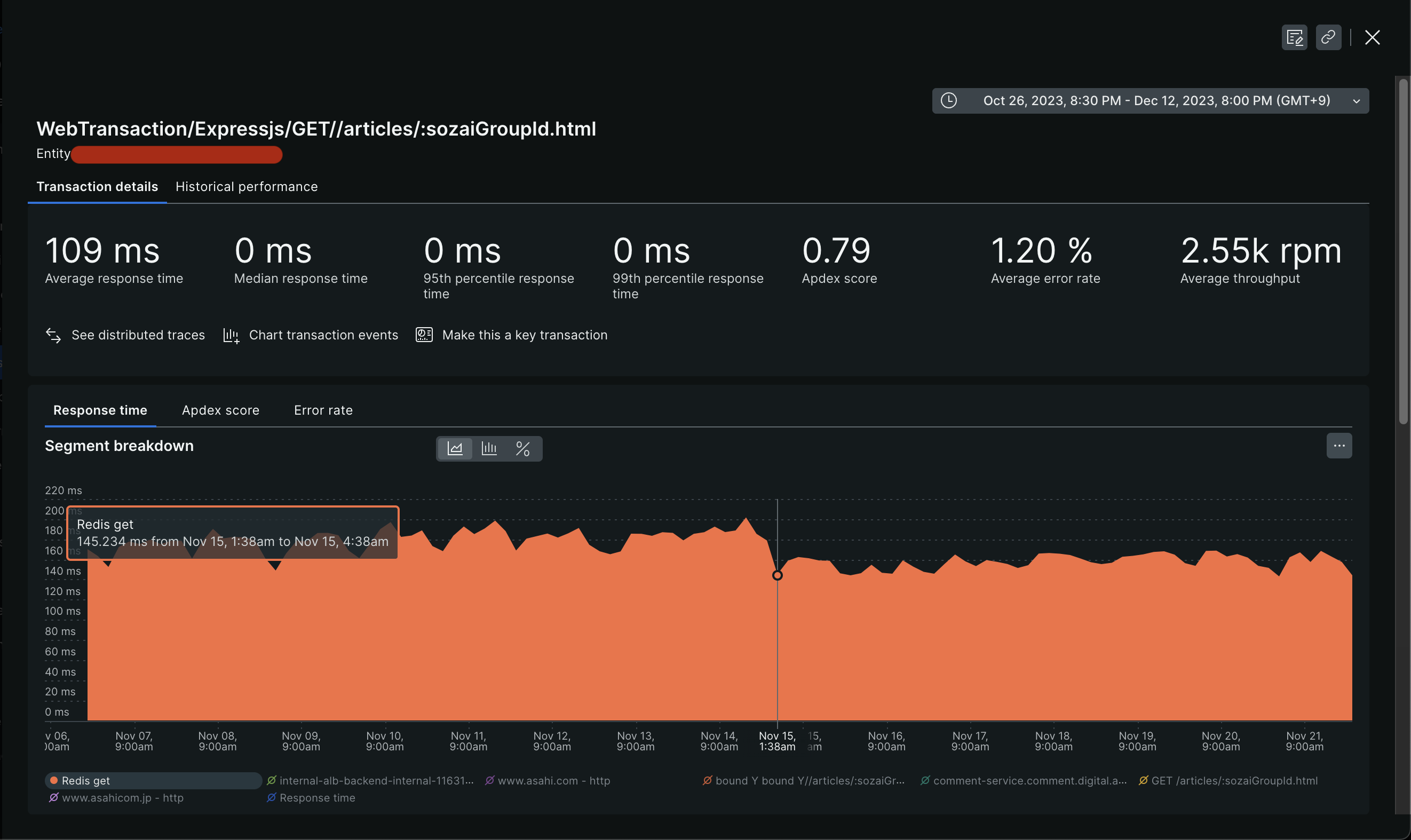
スケールアップ前後で99%tileでの記事ページ全体のレスポンスが30ミリ秒ほど短縮できました。
-
スケールアップ前
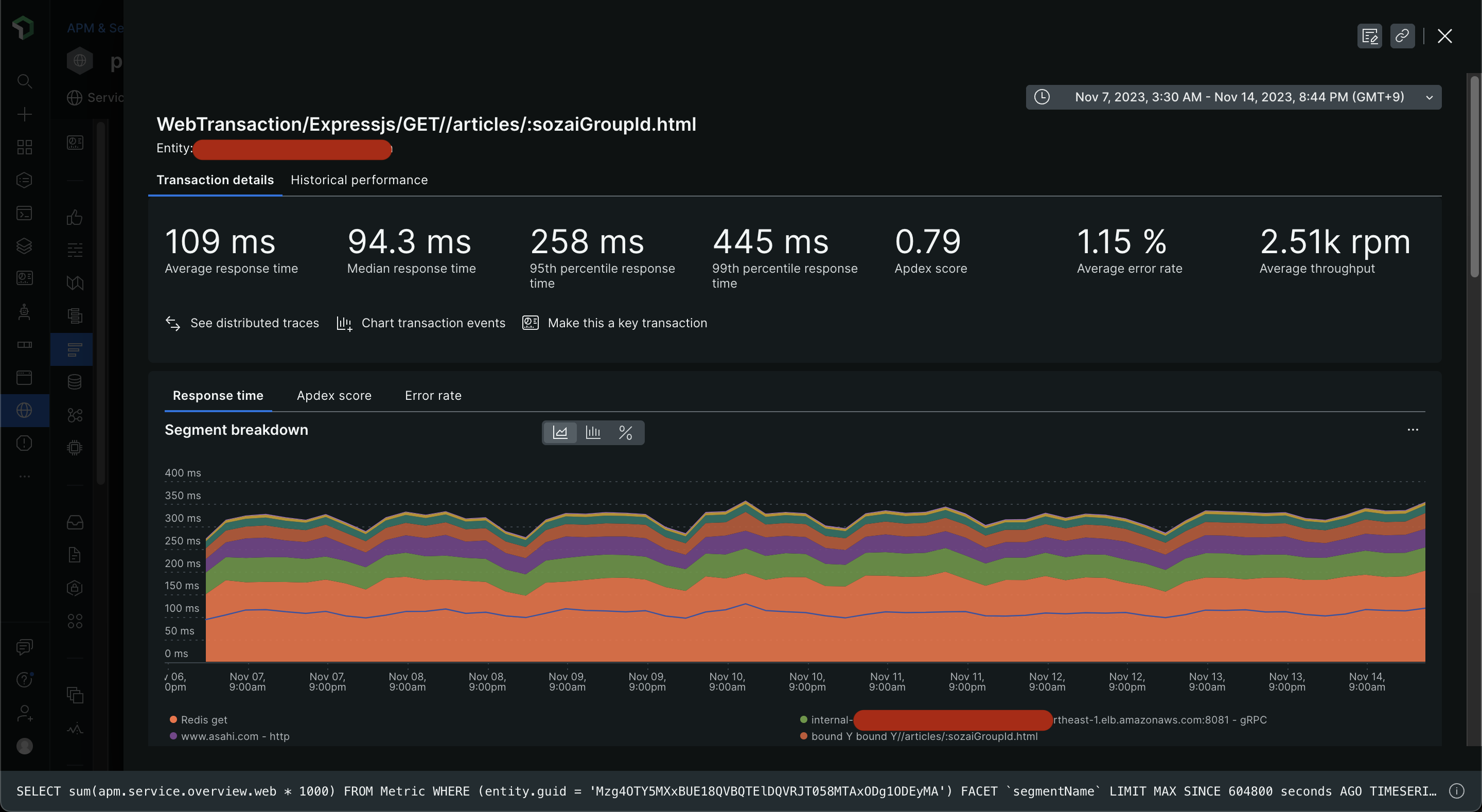
-
スケールアップ後
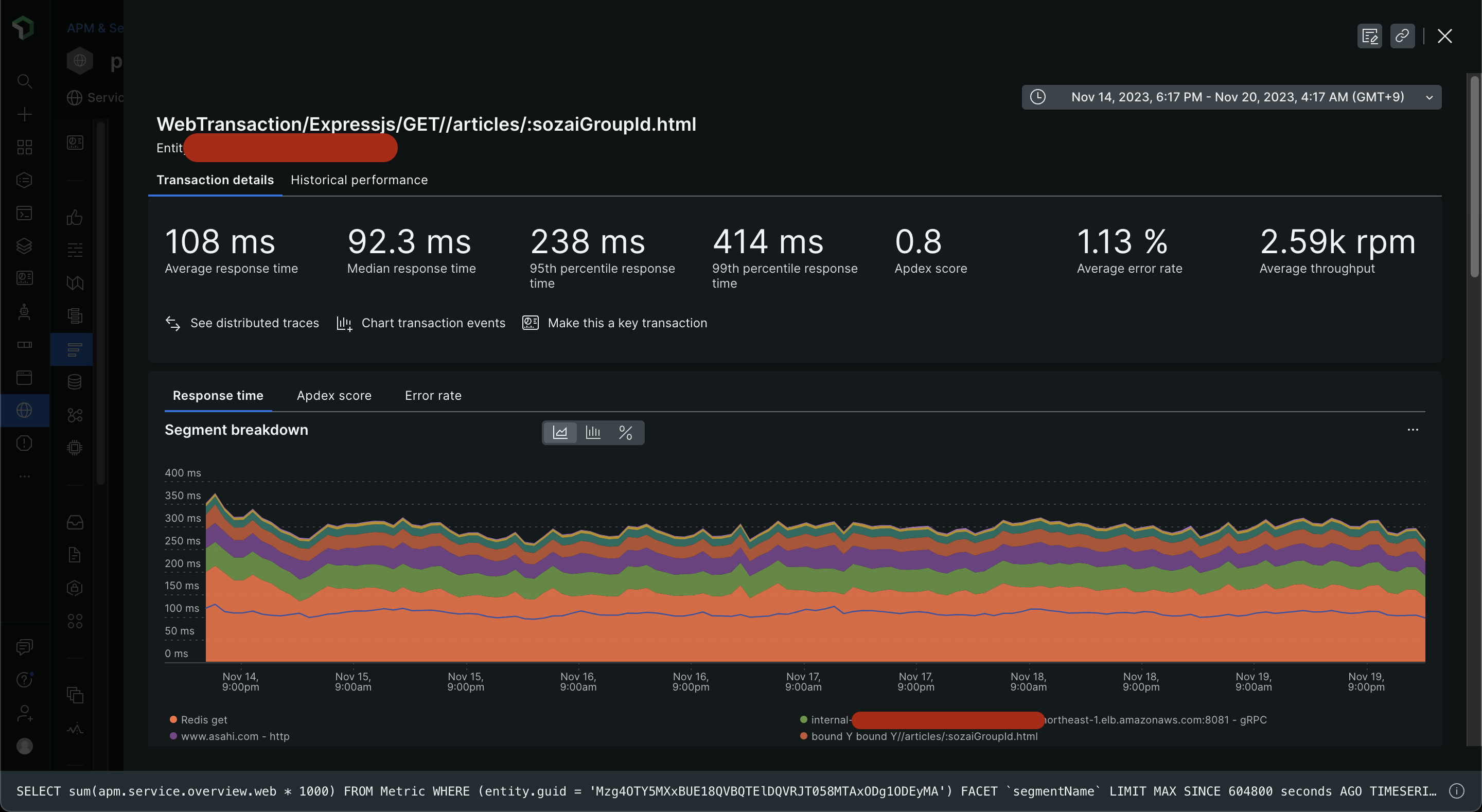
小さな改善ですが、ElastiCacheの帯域にボトルネックがあったことに気づけて良かったです。
まとめ
New Relicの分散トレーシングでRedisのレスポンス速度が遅い点を発見し、帯域のボトルネックを解消までを行いました。
分散トレーシングで処理ごとの内訳をサービスを跨いで閲覧できることで、ボトルネックを見つけやすいと思います。
AWSリソースはインスタンスタイプごとに帯域が設定されていますが、小さいインスタンスタイプは小や中と明示されていない資料も多いです。設計時から時間が経ってRedisにキャッシュするオブジェクトが肥大化していってしまい、当初は厳密に考慮しなくても良かった帯域の制限に達してしまいました。