はじめに
SAAに合格したので、勉強のこつや学んだ知識を残しておきます。あとに続く方の参考に少しでもなればよいなーっていうモチベーションです。
学習量
2ヶ月前くらいから本買って読み始めましたが、正味2週間弱といった感じです。人間、直前にならないとやらないということで…
前提
一応、私のAWS歴ですが、仕事でほんのちょぴっと触る(といってもガチエンジニアではないのでほんとちょぴっと)くらい。ただし、趣味で個人開発をしており、Amplifyまわりはそれなりに詳しくなりました。
合格までのロードマップ
-
- 読み物としても悪くなかったし、模擬試験含め問題もそれなりの量あって悪くないかと思います。模擬試験で点数の悪かった分野を集中的に潰すような使い方をしました。
-
AWS認定ソリューションアーキテクト-アソシエイト問題集 (白本)
- こちらは問題集というだけあって問題量が豊富です。黒本と合わせ、この2冊やり込めば十分合格点には乗るかと思います。
-
AWS公式模擬試験
- 無料で受けられるので受けてください。受験方法が少々めんどいのでこちらを御覧ください。
勉強方法
- 人間は集中力がない生き物なので、ポモドーロ・テクニックを使って25分区切りで勉強しましょう。Focus-Todoというアプリがおすすめです。
- 貸し自習室みたいなところで集中作業するのがおすすめです。2,000円/日くらいの投資にはなりますが、周りが仕事や勉強をしているとだらけることができなくなるのでマジで集中できます。落ちることに比べたら安い投資でしょう。
自分には合わなかった教材
-
Udemy講座【2022年版】これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座
- 流し見してましたが、ぶっちゃけ、見てるだけじゃあまり身につきません。めちゃ長いので途中でやめて問題集に切り替えました。時間もったいないので問題集解きましょう。
-
- 学習始める前にこの記事みたいなが合格体験記を複数読みましたが、よく紹介されていたのでやってみました。それなりにお金払いましたが私にはまったく合わなかったです。問題量は豊富ですが、こんなにやる必要ありませんし、解説も微妙ですし、間違ったところを記録して集中的に出題してくれるなどの管理機能もありませんし、何が良いのかさっぱりわかりませんでした。※あくまで私には合わなかったというだけで合う人には合うんだと思います、ごめんなさい🙇♂️
受験した感想
システム設計におけるベストプラクティスを学べ、今後、システム設計をするうえでナレッジとして蓄積できたと感じます。疎結合・伸縮性のあるシステムを構築することはAWSに限らず大切なことで、AWSソリューションの学習をしていたはずが、AWSに閉じない良質な設計論を学ぶことができ、とても有意義でした。
※ここから下は私の苦手箇所の整理用です。※
苦手事項整理
ここからは私の苦手知識をつらつらと整理し、試験前に読み返したものになります。あまりきちんと整理する気はありませんのでツッコミ無しでお願いします… ただ、私が苦手としているところは苦手としている方が多いかもしれませんので、なにかのお役に立てれば幸いです。
Route53におけるZone Apex
Zone Apexとはドメイン名自体のこと。
wwwなどを含めたドメインをサブドメインといいます。Zone Apexはこのサブドメインを伴わないドメイン名自体を指します。
既に権威DNSサーバーがNSレコードとして登録されていてCNAMEレコード(ドメイン名やホスト名に別名を定義するレコードです。)を設定出来ないから変わりにALIASレコードを使って名前解決を行います、ということらしい。同一ドメイン名ではレコードタイプが異なっても複数登録出来ないというRFC仕様があるようで。私もこのあたり、あまりよくわかっていませんが、仕様なのでまぁそうだよね、と納得しちゃってます・・・
- CNAMEレコードにZone Apexをマッピングできない件について - サーバーワークスエンジニアブログ https://blog.serverworks.co.jp/tech/2016/07/07/zone-apex-cname/
プレイスメントグループ
[ここ](【AWS】プレイスメントグループを完全に理解する - Qiita https://qiita.com/mzmz__02/items/8651f578601f3a567fa0)読めばOK。
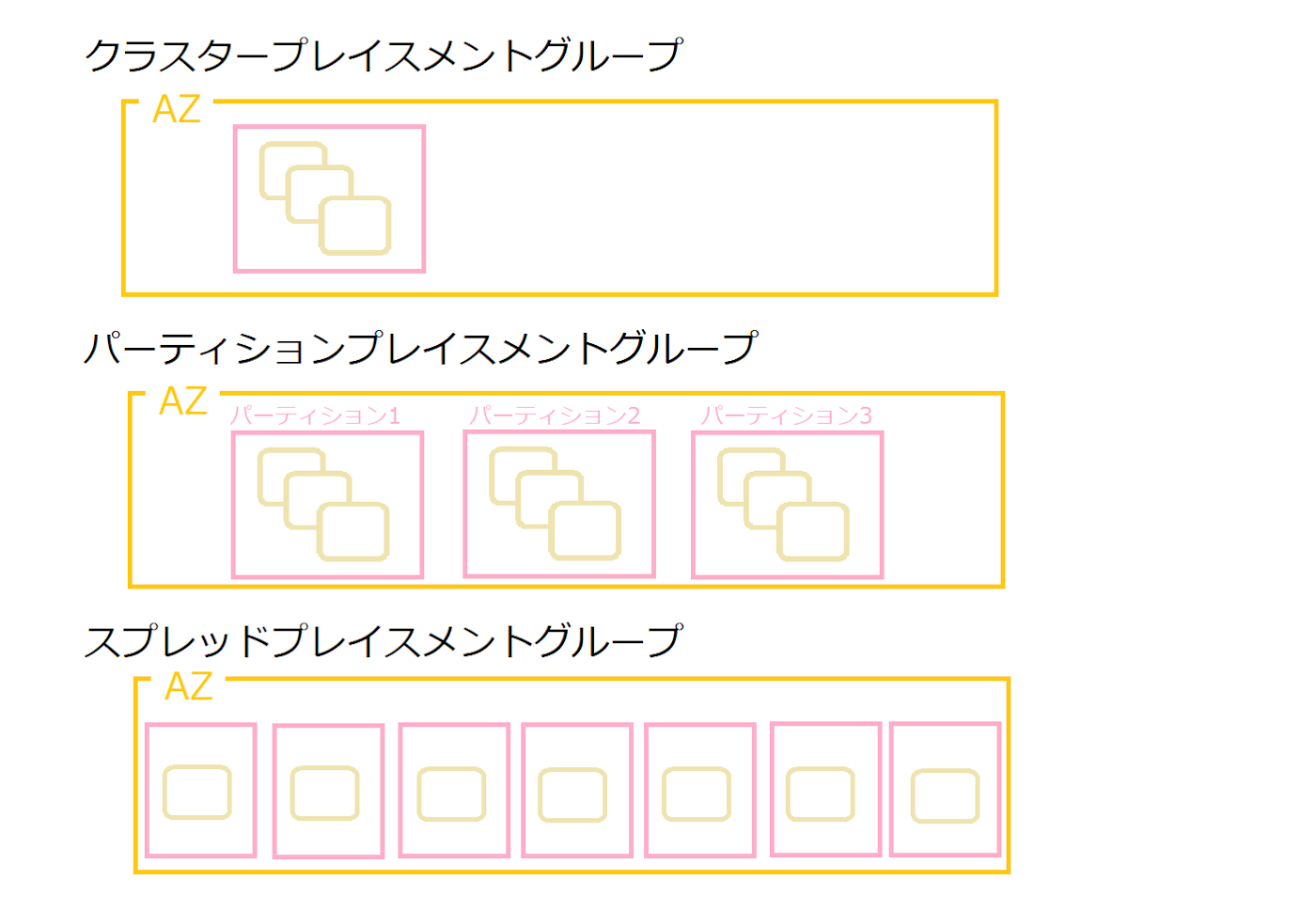
複数のインスタンスを論理的にグループ化して、パフォーマンスの向上・耐障害性を高める機能のこと。クラスタープレイスメントグループ、パーティションプレイスメントグループ、スプレッドプレイスメントグループの3つの種類がある。
クラスタープレイスメントグループは主にパフォーマンスを向上させるためのもので、パーティションプレイスメントグループとスプレッドプレイスメントグループが耐障害性を高めるもの。
クラスタープレイスメントグループは、1つのAZ内のインスタンスを複数のグループにまとめる。パーティションプレイスメントグループはインスタンスをグループにまとめるときに、いくつかのパーティションに分ける。(9台のインスタンスを3つのパーティションに分けるような感じ)スプレッドプレイスメントグループは、パーティションと同様にセグメント分けする。1台につき1つのセグメントを割り当てる。
Site-to-Site VPN
VPN間接続のこと。VPCとオンプレミスとの接続の場合にはそれぞれ、仮想プライベートゲートウェイとカスタマーゲートウェイの作成と接続が必要になる。
AutoScalingの起動設定
AutoScalingの「起動設定」をCloudformationで変更するときの手っ取り早いやりかた | DevelopersIO https://dev.classmethod.jp/articles/cf_as_change_lc/
AutoScaling(以下、AS)には「起動設定」と呼ばれるパラメータがあります。この「起動設定」は、AS環境下でインスタンスが起動されるときに読み込まれるパラメータであり、「インスタンスタイプ」や「ストレージサイズ」や「セキュリティグループ」等の設定を予め定義して指定しておくことができます。 AS環境下のインスタンスに対して共通の設定を適用できるという非常に便利な機能なのですがこの「起動設定」には以下のような制約があります。
Auto Scalingを調べて使ってみた。 | DevelopersIO https://dev.classmethod.jp/articles/as-explanation-try/
- ターゲット追跡スケーリング
定義された性能指標を利用したり、カスタム性能指標を作成してターゲット値に設定したりする。
例)性能指標はCPU使用率、ターゲット値は50%に設定すると、オートスケーリングが自動的にEC2インスタンス数を調節し、CPU使用率が40%くらいに維持する。
CloudWatchの警告を生成·モニタリングして警告が発生すると、オートスケーリングポリシーを実行させてインスタンス数を自動的に増加·減少させる。- ステップスケーリング
簡易スケーリングポリシーより細かい規則を追加したいときに使う。
例)CPU使用率が50%~60%の場合、2つのインスタンスを追加し、60%を超えると4つのインスタンスを追加する。- 簡易スケーリング
CPU使用率やネットワーク流入、流出比率などの警告指標でインスタンスをスケールアップ、ダウンする。
ポリシーを作成する際には、二つのポリシーが必要になる。
グループのサイズを増加させるスケールアップポリシー
グループのサイズを減少させるスケールダウンポリシー
スケーリングアクティビティが開始されると、ポリシーはスケーリングアクティビティまたはヘルスチェック交換が完了し、クールダウン期間が終了するまで待つ必要がある。
Memo
「スケーラブルな」サービスを構築したいという話が出た場合は自動でスケールするAutoScalingが回答の選択肢になる可能性が非常に高い
ALBとNLB、API Gatewayの違い
ALBはユーザー認証やL7レベルでの細やかな振分ができる。NLBはネットワークレベル(L4)での振分なのでALBほどきめ細やかな振分はできないが早い。
API GatewayはAPIを構築するためのいろいろな機能を持っている。タイムアウト値が29秒と制約が厳しい模様。受け付けるポートも443しか受け付けない制約あり(ALBは任意のポートで受けられる)。その他、受け付けるペイロードサイズの違いなどもあるんだとか。
AWS Lambda:API GatewayとApplication Load Balancerの違い - Qiita https://qiita.com/unhurried/items/5a497ec81e4fefe22396
スケールイン中の処理の中断について
デフォルトでは、Elastic Load Balancing 登録解除プロセスが完了するまで 300 秒待って、ターゲットへ処理中のリクエストが完了するのを助けることができます。Elastic Load Balancing の待機時間を変更するには、登録解除の遅延値を更新します。
ElastiCache(Redis)を使ったセッション管理
ElastiCacheではRedisとMemchachedを選択できる。
主な違いは[こちら](ElastiCacheを利用したWebセッション管理 - Qiita https://qiita.com/cloud-solution/items/e10c099a80c17d3e1c2f)参照。永続化とレプリケーション・自動フェールオーバーができるRedisを使うということ。
- Redisは永続化、レプリケーション・自動フェールオーバに対応
- Memcachedはマルチスレッドに対応
- Redisは多様なデータ型に対応、MemcachedはシンプルなKey-Value型のみ対応
- Memcachedはスケールイン・スケールアウトに対応
- Memcachedはキャッシュ用途に特化、Redisはデータストアとして設計されているNoSQL
SNSとSQSを使ったファンアウトパターンの構築
メッセージの発生源ーSQSとしてしまうと発生源の方で全てのSQSにメッセージを投げるような処理を記載する必要がある。であれば、間にSNSを挟んでSQSの各キューはSNSのトピックを購読するようにしておけば疎結合で発生源側で処理を各キュー個別に書く必要のないファンアウトパターンが出来上がる。
セキュリティグループとネットワークACLの違い、使い分け
| 概要 | デフォルト設定 | 形式 | ルール | ||
|---|---|---|---|---|---|
| セキュリティグループ | インスタンスに割り当てるFWのようなもの。1つ、もしくは複数のインスタンスに割り当てることができる | インバウンド:すべて拒否 アウトバウンド:すべて許可 |
ホワイトリスト | すべてのルールが適用される | ステートフル |
| ネットワークACL | ネットワークに適用するFWのようなもの。サブネット単位での適用が可能。 | インバウンド:すべて許可 アウトバウンド:すべて許可 |
ブラックリスト | 割当らた番号順に適用される | ステートレス |
スポットインスタンスの削除
スポットインスタンスを削除するには、スポットリクエストをキャンセルしてからスポットインスタンスを終了するのが適切なステップです。
インスタンスメタデータとユーザーデータの取得
インスタンスメタデータを取得する唯一の方法は、リンクローカルアドレス (169.254.169.254) を使用することです。
$ curl http://169.254.169.254/latest/meta-data/instance-id
i-0123456789abcd5c1
どんなデータが取得できるかは[こちら](EC2のmeta-dataとuser-dataの使い方 | Oji-Cloud https://oji-cloud.net/2019/09/22/post-3097/)を参照。
- 下記の様にユーザーデータにアクセスします。curlコマンドを実行した結果、ユーザーデータに設定しているsudo groupadd、sudo useraddの2行が出力されました。
$ curl http://169.254.169.254/latest/user-data sudo groupadd -g 600 test-group sudo useradd -u 600 -g test-group -d /home/test-user -s /bin/bash test-user
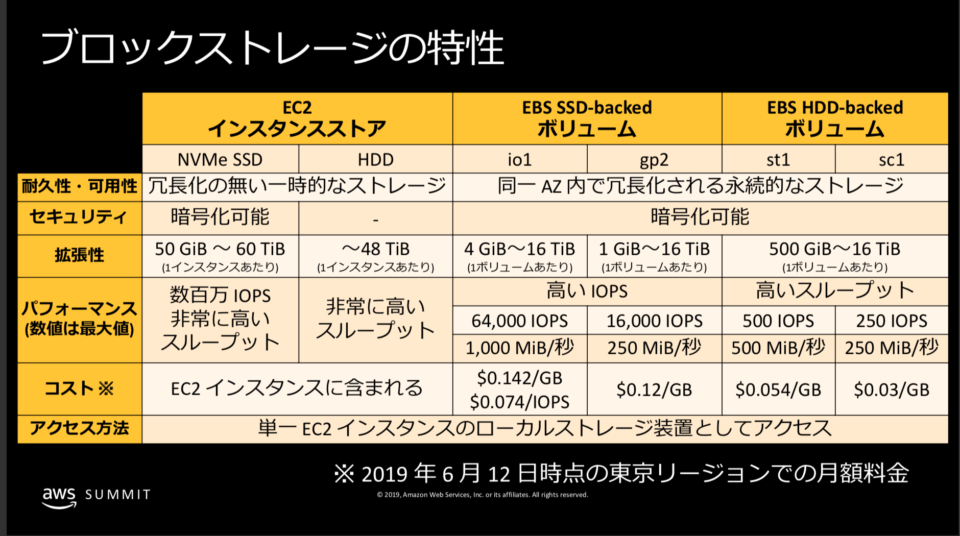
EBS ボリューム
ストレージにスループットが必要な場合、プロビジョンド IOPS SSD EBS ボリュームを用いる。プロビジョンド IOPS SSD EBS ボリュームは、ボリュームごとに最大 64,000 IOPS を提供します。
汎用SSD EBS ボリュームは、ボリュームごとに 16,000 IOPS に制限されています。
詳細はこちら参照。
インスタンスストア
SSD バックドストレージ最適化 (i2) インスタンスは、365,000 を超えるランダム IOPS を提供します。インスタンスストアには、インスタンスの通常の時間単位のコストと比較して、追加コストはありません。
こちらがわかりやすかった。
S3のマルチパートアップロード
[こちら](マルチパートアップロードとは 通常のアップロードは以下のようにファイルをそのままサーバに送りつけるだけです。 マルチパートアップロードではファイルを分割(みじん切りに)し、それぞれのパーツを並行してアップロードします。最終的にすべてのパーツがサーバ上に揃った段階で合体しもとのファイルに復元するという仕組みです。 https://blog.katsubemakito.net/aws/s3-multipartupload)がわかりやすかった。
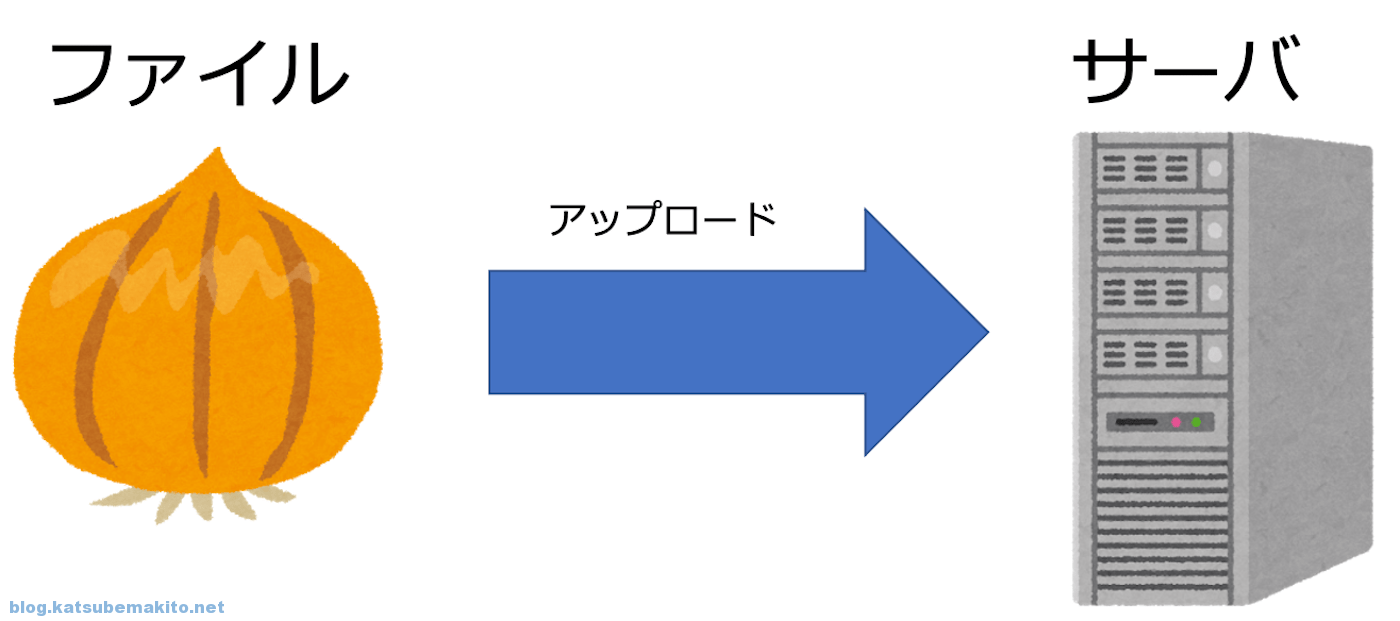
マルチパートアップロードとは
通常のアップロードは以下のようにファイルをそのままサーバに送りつけるだけです。
マルチパートアップロードではファイルを分割(みじん切りに)し、それぞれのパーツを並行してアップロードします。最終的にすべてのパーツがサーバ上に揃った段階で合体しもとのファイルに復元するという仕組みです。

Q: Amazon S3 にはどれだけのデータを保存できますか?
格納可能なデータの総量とオブジェクトの数には制限はありません。個別の Amazon S3 オブジェクトのサイズは、最低 0 バイトから最大 5 テラバイトまでさまざまです。1 つの PUT にアップロード可能なオブジェクトの最大サイズは 5 GB です。100 MB 以上のオブジェクトの場合は、マルチパートアップロード機能を使うことをお考えください。
S3 Transfer Acceleration
クライアント-S3間の通信を高速に行う。送信元であるクライアントからS3間の距離が離れている場合などに効果を発揮する。
Region間で高速にデータをコピーしたいのであればクロスリージョンレプリケーションを使う。
S3オブジェクトへのクロスアカウントアクセス
異なるAWSアカウントからS3オブジェクトへのアクセスを認めたい場合、「バケットポリシー」の設定で対応できます。
こちら参照。
リソースベースのバケットポリシーを使用して、クロスアカウントアクセスコントロールを管理し、S3 オブジェクトのアクセス権限を監査します。バケットレベルでバケットポリシーを適用すると、次のような定義が可能です。
- バケット内のオブジェクトにアクセスできるのは誰ですか (Principal 要素を使用)
- どのオブジェクトにアクセスできるか (Resource 要素を使用)
- バケット内のオブジェクトにアクセスする方法 (Action 要素を使用)
S3の暗号化方法
Amazon S3の暗号化について調べてみた。 | DevelopersIO https://dev.classmethod.jp/articles/lim-s3-sse-2021/
S3のイベント通知
SNSとか使わなくてもイベント通知できる。これを利用して、ファイルが置かれたらLambda起動してごにょごにょする、みたいなことができる。
カスタマー側のキーを使ってS3を暗号化する
オブジェクトをアップロードする際、Amazon S3 はお客様が用意した暗号化キーを使用してデータに AES-256 暗号化を適用し、メモリから暗号化キーを削除します。
S3 バケットのデフォルトの暗号化動作は、SSE-S3 または AWS Key Management Service (AWS KMS) に保存されているカスタマーマスターキー (CMK) (SSE-KMS) のいずれかに設定できます。SSE-C でファイルをアップロードできますが、デフォルトの S3 バケット暗号化として設定することはできません。
S3の結果整合性モデル(2020年12月1日以前)とデータ整合性モデル
上記のとおり、2020/12/1までは結果整合性モデル(データを作成・変更・削除すると時間は掛かるとして結果は整合性が保たれる)だったようです。それが12/1以降はデータ整合性モデルになり、即時で整合性が保たれるようになったということのようです。
【2020年12月1日からの変更点】S3のデータ整合性モデル - Qiita https://qiita.com/1_ta/items/a3a18b39805b238edb74
Glacierの取り出し速度
「迅速」取り出し
- 1〜5 分以内 で取り出し可能
- アーカイブのサブセットが迅速に必要になった場合にデータにすばやくアクセス可能
- 最大規模のアーカイブ(250 MB 以上) は対象外
「標準」取り出し
- 3〜5 時間 で取り出し可能
- 取り出しオプションのデフォルト設定
「大容量」取り出し
- 5〜12 時間 で取り出し可能
- 最も安価な取り出しオプション
- 大量のデータ (ペタバイトのデータを含む) を 1 日以内に低コストで取得可能
Snowball Edge
こちら参照。
AWS Snowball をご存知でしょうか? あまり使う機会がないかもしれませんが、Snowball は巨大なデータを AWS に送る場合に利用できる物理デバイスをやり取りする仕組みです。これを使うとネットワーク経由で時間をかけて転送する必要はありません。
いまのところ、1台の最大容量は 100TB ですが、複数台使えばペタバイトクラスのデータを AWS に送ることもできます。ちなみに Snowball Edge は Snowball の機能拡張版という位置づけだったのですが、オリジナルの Snowball は現在既に利用できなくなっているため、Snowball といえば Snowball Edge の事を指すことになります。この文章では単純に Snowball と記述しています。
DynamoDBのエンドツーエンド暗号化
DynamoDB 暗号化クライアントが AWS KMS を使用するように設定されている場合、AWS KMS 以外を使用すると必ず暗号化されるカスタマーマスターキー (CMK) が使用されます。この暗号化マテリアルプロバイダーから、テーブル項目ごとに一意の暗号化キーと署名キーが返ります。この暗号化方式は対称 CMK を使用します。
DynamoDB 暗号化クライアントは、転送中および保管中のデータをエンドツーエンドで保護します。テーブル内の選択した項目または属性値を暗号化できます。
DynamoDB アクセラレーター(DAX)
DAXはマイクロ秒単位の応答時間を実現する。
DBのリージョン間レプリケーションサポート
S3とRDSはリージョン間レプリケーションをサポートする。EBSはサポートしていないので注意。
DynamoDB Streamsでレコードの変更検知
その名のとおり。有効にするとイベントを検知してストリームに流すことができるようになるため、そのストリームをLambdaからポーリングして処理を行うなどの実装をすることができる。
署名
AWS に HTTP リクエストを送る際、AWS が送信元を特定できるようリクエストに署名します。リクエストには AWS アクセスキーを使用して署名します。AWS アクセスキーは、アクセスキー ID とシークレットアクセスキーで構成されています。AWS は次の 2 つの署名バージョンをサポートしています。 署名バージョン 4 および署名バージョン 2。AWS では署名バージョン 4 の使用を推奨しています。
EBSのスナップショット
取得開始時点のデータで取得される。よって取得が完了するまでデータが変更できないといったことはない(が変更してもスナップショットには反映されない)。
EBSの暗号化
EBSでは、OSが提供するファイルシステムの暗号化の機能を用いて、ユーザーがファイルシステム全体を暗号化してからデータを保管します。ボリュームの作成時に暗号化が可能です。既存のEBSボリュームを暗号化ボリュームに変更する際には、スナップショットを取得して、スナップショットを複製する際に暗号化オプションを指定する必要があります。
EFSとFSx
一番苦手だったので。
【AWS】EFSとFSxの違い – ITblog https://www.itblog.jp/?p=10014
わかりやすい違いとしては、EFSは、LinuxのNFSという技術を使っているので、つまりはLinuxやUnix系のサーバで使うということですね。
これに対してFSxは、Windowsから使用することができるので、サーバがWindows系の場合にはこちらを選ぶのかなというイメージです。
FSxには、Windows向けと、HPCというハイスペックのコンピュータ向けのファイルシステムの2種類が存在しているみたいです。
その他、FSxはフルマネージドなので管理がしやすいという特徴があるみたいです。
VPC→S3/DynamoDBに接続する際の方法
2つのVPCエンドポイントの違いを知る | DevelopersIO https://dev.classmethod.jp/articles/vpc-endpoint-gateway-type/
ゲートウェイ型とインターフェイス型の2種類があります。ゲートウェイ型は最初に出たVPCエンドポイントで、S3とDynamoDBが対応しています。インターフェイス型は、それ以降に出てきたサービスで50種類以上のサービスが対応されています。
この記事ではアクセス先のAWSリソースへのグローバルIPアドレスでのアクセスを禁じるとどうなるか、という実験を行ってくださっています。結果、結局グローバルIPアドレスしか持たないゲートウェイ型はアクセスできなくなって、インターフェース型はENIを作ってプライベートIPアドレスを作るのでアクセスできる、ということらしいです。
ストレージゲートウェイ
オンプレミスのソフトウェアアプライアンスとクラウドベースのストレージを接続します。Storage Gateway は、オンプレミスの IT 環境と Amazon S3 などの AWS ストレージインフラストラクチャ間のデータセキュリティ機能が確保された統合を可能にします。
OUとSCP
[AWS Organizations] SCP(サービスコントロールポリシー)の継承の仕組みを学ぼう | DevelopersIO https://dev.classmethod.jp/articles/organizations-scp-inheritance/
Global Accelerator(グローバルレベルでのロードラバランシング)
AWS Global AcceleratorはAWSが提供するGSLB(グローバルサーバロードバラシング)の一種です。 AWSのグローバルネットワークを使用し、アプリケーションのグローバルな可用性とパフォーマンスを向上させることができます。
Application Load Balancer、Network Load Balancer、Amazon EC2 インスタンスなど、単一または複数の AWS リージョンのアプリケーションエンドポイントへの固定 IP アドレスを使えます。
AWS Global Accelerator は、AWS グローバルネットワークを使用してユーザーからアプリケーションへのパスを最適化し、トラフィックのパフォーマンスを 60% も改善します。
ルーティングポリシの選択
- シンプルルーティングポリシー – ドメインで特定の機能を実行する単一のリソースがある場合に使用します。例えば、example.com ウェブサイトにコンテンツを提供する 1 つのウェブサーバーなどです。
- フェイルオーバールーティングポリシー – アクティブ/パッシブフェイルオーバーを構成する場合に使用します。
- 位置情報ルーティングポリシー – ユーザーの位置に基づいてトラフィックをルーティングする場合に使用します。
- 地理的近接性ルーティングポリシー – リソースの場所に基づいてトラフィックをルーティングし、必要に応じてトラフィックをある場所のリソースから別の場所のリソースに移動する場合に使用します。
- レイテンシールーティングポリシー – 複数の AWS リージョンにリソースがあり、より少ない往復時間で最良のレイテンシーを実現するリージョンにトラフィックをルーティングする場合に使用します。
- 複数値回答ルーティングポリシー – ランダムに選ばれた最大 8 つの正常なレコードを使用して Route 53 が DNS クエリに応答する場合に使用します。
- 加重ルーティングポリシー – 指定した比率で複数のリソースにトラフィックをルーティングする場合に使用します。
コンバーティブルリザーブドインスタンス
コンバーティブルリザーブドインスタンスでは、インスタンスファミリー、オペレーティングシステム、テナンシーを変更できます。
LambdaでのJavaアプリケーションの実行について
Lambda 関数を作成するには、まず Lambda 関数のデプロイパッケージを作成します。このパッケージは、コードと依存関係で構成される .zip ファイルまたは .jar ファイルです。
Lambda関数のバージョン管理
AWS Lambdaのバージョン管理とエイリアスについて https://zenn.dev/amarelo_n24/articles/158a166d832487
模擬試験では、以下のように設問がありました。
Q)2 つの Lambda 関数エイリアスを作成する。一方を「本番」、もう一方を「開発」と名付ける。本番エイリアスを本番対応の非修飾 Amazon リソースネーム (ARN) バージョンに割り当てる。開発エイリアスを $LATEST バージョンに割り当て。
A)本番用と開発用に別々のエイリアスを作成することで、システムは必要に応じて正しいエイリアスを開始できます。Lambda 関数のエイリアスを使用して、特定の Lambda 関数のバージョンに割り当てることができます。エイリアスとそのリンクバージョンを更新する機能を使用して、開発チームは必要に応じて必要なバージョンを更新できます。$LATEST バージョンは最新の公開バージョンです。
AWS Lambda のバージョン管理の仕組み | DevelopersIO https://dev.classmethod.jp/articles/lambda-versioning/
本番用は非修飾ARNで$LATESATを、開発用はバージョン指定で、となっています。こーゆうものだと覚えておきましょう(逆でもたぶんできるんでしょうが、お作法としてこーゆうものだと認識しています)。
Lambda イベントソースマッピングは、バージョン ARN またはエイリアス ARN に割り当てることができますが、レイヤー ARN には割り当てられません。
まず、Lambdaでのレイヤーとは、共通のコードやデータを外だしにして共有化することができるというものです。これはどーゆうことかというと、イベントソースはLambda 関数を呼び出す AWS Lambda リソースのことを指しますが、それらにはレイヤーARNを割り当てられないということです。
参考)Lambdaとは - Qiita https://qiita.com/fjisdahgaiuerua/items/07124dc15ba4bba0b007
ECS/ECR
普段、DockerやKubernetesを使っているような人でも、それらの用語とECS用語(TaskやらServiceやら)とのマッピングが必要。
[こちら](Amazon EC2 Container Service(ECS)のデータモデルについて整理した | DevelopersIO https://dev.classmethod.jp/author/mochizuki-masao/)がわかりやすかった。
動的ホストポートマッピングとALBによる負荷分散の問題がでることもあるので要チェック。
動的ホストポートマッピングでは、同じサービスからの複数のタスクが各コンテナインスタンスに対して許可されます。
Amazon ECS がコンピューティングに Fargate を使用する場合、アプリケーションがアイドル状態のときにコストは発生しません。Aurora サーバーレスは、アイドル状態のときにコンピューティングコストも発生しません。
Memo
AuroraやRDSは事前にインスタンスクラスを定義する必要があるが、Auroraサーバレスは処理負荷に応じて自動でスケールイン/スケールアウトしてくれる。
CodeDeployのデプロイパッケージに含めるもの
CodeDeploy AppSpec (アプリケーション固有) ファイルは CodeDeploy に固有のものです。AppSpec ファイルは、ファイルで定義されている一連のライフサイクルイベントフックとして、各デプロイを管理するために使用されます。
AppSpecとは
AWS CodeDeploy の AppSpec を読み解く | DevelopersIO https://dev.classmethod.jp/articles/code-deploy-appspec/
Application Specification File (AppSpec file) は、CodeDeploy があなたの EC2 インスタンスに対して、Amazon S3 または GitHub にあるアプリケーションのリビジョンをどのようにインストールするか決定する、YAML フォーマットのファイルです。また同様に、デプロイの様々なライフサイクルイベントをフックして処理を実行するか決定します。
AppSpec ファイルの名前は必ず
appspec.ymlとし、ルートディレクトリに配置しておかなればいけません。この要件を満たしていない場合、デプロイは失敗します。また、AppSpec ファイルが存在する場合は、これを含めたデプロイ用のコンテンツを.zip(Windows Server 以外は.tarおよび.tar.gzも可能) 形式の圧縮ファイルにすることができます(詳しくは Prepare a Revision を参照)。
Step Functions
Step Functionsでは、ワークフロー=ステートマシン。ワークフローの各ステップはタスク=ステート。どっちやねん、という話ですが、両方覚えておけばよいかと。
ワークフローはASLというJSONもどきを使って記載する。
AWS Config
AWS Config を使用すると、AWS のリソースの設定を評価、監査、審査できます。
ストレージはちゃんと暗号化してるよね、とか。マネージドルール使えば評価もかんたん。
認証・認可
- API GatewayでAPIを構築する場合にアクセスをCognitoユーザープールのユーザーに限定する方法として、
- Amazon Cognito ユーザープールとの統合には、Cognito オーソライザーを使用する必要があります。
- オーソライザーの作成に加えて、API に対してそのオーソライザーを使用するように API メソッドを設定する必要があります。
IAMのポリシー
ユーザーベースのポリシーはユーザーに紐付けるポリシー。操作主体が明らかであることからPrincipalはない。
リソースベースのポリシーはリソースに割り当てるポリシー。操作主体であるPrincipalを記載する必要あり。
信頼ポリシーはポリシー内にPrincipalとして記載したユーザーに権限を以上することができる。
[ここ](AWS IAMポリシーを理解する | DevelopersIO https://dev.classmethod.jp/articles/aws-iam-policy/)がとてもわかりやすかった。
AWSが提供するセキュリティ関連サービス
Trusted Advisor セキュリティチェックとデータ暗号化サービスを提供。
カスタマーアプリケーションの完全な PCI コンプライアンスや、自動侵入テスト、著作権のあるコンテンツの検出などのサービスは提供していません。
Trusted Advisor には、これまで多数の AWS のお客様にサービスを提供してきた経験に基づくベストプラクティスが活かされています。これらのベストプラクティスには、セキュリティチェックが含まれます。具体的にはS3のアクセス権限のチェックやルートアカウントのセキュリティチェック(多要素認証が有効になっているか)など。
Firewall Manager を使用すると、AWS WAF、Shield Advanced、その他の AWS サービスを管理できます。AWS WAF は、悪意のある可能性のある SQL コード (SQL インジェクション) の存在を検出できます。AWS WAF は、悪意のある可能性のあるスクリプト (クロスサイトスクリプティング) の存在を検出することもできます。Shield Advanced は DDoS 攻撃から保護します。
AWS WAF
Webアプリを保護することができる。CloudFrontやALB、API Gatewayに適用できる。
よく出題される設計原則
伸縮性
伸縮性は、必要なときにリソースをアクティブ化し、不要になったらリソースを返却する能力です。
AWSでのWeb3階層システムの構成例
こちらで紹介されているように、プレゼンテーション層、アプリケーション層にそれぞれロードバランサを挟む構成が可用性を維持できる、ミニマムでベーシックなパターン。

AWS Organizations での一括請求のメリット
一括請求は AWS Organizations の機能です。組織内のすべてのアカウントの使用量を結合し、料金のボリューム割引、リザーブドインスタンスの割引、Savings Plans を共有できます。このソリューションでは、個々のスタンドアロンアカウントの使用と比較して料金が安くなる可能性があります。
AWS Organizationsでの利用サービス制限
サービスコントロールポリシー(SCP)を使うと、複数のAWSアカウントで利用できるサービスを制限できる。
CloudWatch Logs
AWS CloudTrailやVPCフローログなどさまざまなAWSのログを統合的に収集するサービス。
CloudTrail
こちら参照。
AWS CloudTrail(以下、CloudTrail)は、AWSサービスの操作を監視し、AWSアカウントのガバナンス/コンプライアンス/運用とリスクの監査を実施するためのマネージドサービスです。CloudTrailは、ユーザーのAWSマネジメントコンソールのログイン、ユーザーが実施したAWSサービスに関する設定変更/APIを利用した操作、およびAWSサービスが実施した操作など、**AWSに対するアクティビティログを記録します。標準で90日間、アクティビティを各リージョンで記録しています。**証跡を有効化すると、S3バゲットにアクティビティログを保存します。また、CloudWatch Logsへの送信を有効化すると、ログをCloudWatch Logsに送信できます。AWSコンソールまたはCloudTrail API/SDKを利用し、記録されているアクティビティを確認できます。
VPCフローログ
こちら参照。
VPC フローログは、VPC のネットワークインターフェイスとの間で行き来する IP トラフィックに関する情報をキャプチャできるようにする機能です。フローログデータは Amazon CloudWatch Logs または Amazon S3 に発行できます。フローログを作成したら、選択した送信先でそのデータを取得して表示できます。
請求金額のモニタリング
CloudWatch を使用すると、AWS 予想請求額をモニタリングできます。AWS アカウントの予想請求額のモニタリングを有効にすると、予想請求額が計算され、メトリクスデータとして CloudWatch に 1 日数回送信されます。
サポートプランの比較
AWS Support プラン比較 | デベロッパー、ビジネス、エンタープライズ、エンタープライズ On-Ramp | AWS Support https://aws.amazon.com/jp/premiumsupport/plans/
障害発生時の対応(「本番システムのダウン」)くらいは見ておくと良いかも。左(2列名)からデベロッパー/ビジネス/エンタープライズ On-Ramp/エンタープライズ
ケースの重要度と応答時間* 一般的なガイダンス: 24 時間内** システム障害: 12 時間内** 一般的なガイダンス: 24 時間以内 システム障害: 12 時間以内 本番システムの障害: 4 時間以内 本番システムのダウン: 1 時間以内 一般的なガイダンス: 24 時間以内 システム障害: 12 時間以内 本番システムの障害: 4 時間以内 本番システムのダウン: 1 時間以内 ビジネスクリティカルなシステムのダウン: 30 分以内 一般的なガイダンス: 24 時間以内 システム障害: 12 時間以内 本番システムの障害: 4 時間以内 本番システムのダウン: 1 時間以内 ビジネス/ミッションクリティカルなシステムのダウン: 15 分以内