きっかけ
その昔、データ基盤を作るお仕事をしてました。
最近データクレンジングとか重複排除の話をする機会があったので、思い立って形にしてみました。
※ 個人の経験に基づく感想です。こんな考えの人がいるんだなーぐらいで見ていただけますと。
コンセプト
データ基盤設計の大枠に適用できる重要な考え方を
「毎日増え続けるデータ(センサ出力、ログなど)を分析可能な形でデータウェアハウスに保持する」
という題材に沿って解説していこうと思います。
大切な要素
私がデータ基盤を設計するとき、特に以下の3つに注意を払います。
- コスト
- 堅牢性
- 速度
普通のシステム設計とあまり変わりませんね。
他にもセキュリティとかデータマートの設計とかの話もありますが最もプリミティブなものを挙げるなら上記3点になるでしょう。
データ基盤設計
悪い例
最初に愚直に要件を満たしそうな設計を考えてみます。
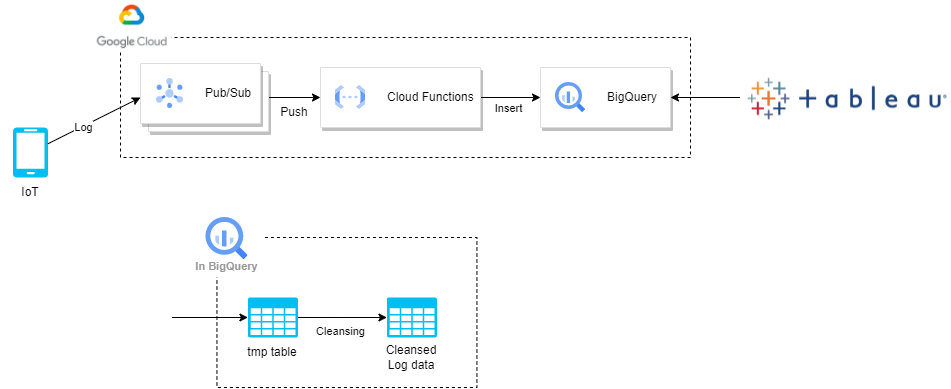
動作機序
- センサやスマホからの出力を Pub/Sub に送信
- Pub/Sub から Cloud Functions に Push
- Cloud Functions から Big Query にデータを Insert
- tmp table に一時的にためる
- 定期的に tmp table のデータをクレンジングし Log data テーブルに Insert
- その後 tmp table を Truncate
評価
先述の3点に従って評価してみます。
コスト
Big Query はスキャン量に対して課金されるので Tableau でレポートを出力するたびに課金が発生します。
検証目的であえて簡単構成として採用するのはアリですが、使い方によって非常に高額の課金が発生する可能性については留意が必要です。
適切な項目(たとえば日付)でクラスタリングを行えば SELECT 時のスキャン量を大幅に下げられるので、そのような工夫も有効でしょう。
対して Cloud SQL は起動時間に対して課金されます。
Tableau から Cloud SQL を参照する構成の場合、起動時間に依存した課金しか発生しないのでコスト予測がしやすくなります。
ストレージやデータパイプラインなどにも料金はかかりますが、大抵 DB, DWH のコンピューティングリソースが一番大きくなります。
堅牢性
システムを堅牢にするにはデータの汚染と破壊に強くする必要があります。
この例ではテーブルが壊れたときに復旧する方法がありません。
データレイクにファイルとして貯めておく方がベターでしょう。
また、データ加工においてシンク側の参照は可能な限り避けるべきです。
実行結果が前回の実行結果に依存するので、この構造はデータが壊れた際の復旧を難しくする可能性があります。
-- SINKに投入するデータを作るときにSINKを参照するのはよくない。
INSERT INTO SINK_TABLE
...
SELECT ... FROM SOURCE_TABLE
...
SELECT ... FROM SINK_TABLE
...
-- こっちの方がいい
INSERT INTO SINK_TABLE
...
SELECT ... FROM SOURCE_TABLE
...
クレンジングで重複排除を行う場合、今回の例では一時テーブルとログデータ両方を参照する必要があるのでシンク側の参照が発生してしまいます。
シンク側の参照を避けるには一時テーブルではなく蓄積していく方式の方がベターでしょう。
汚染されたデータや壊れたデータが見つかった場合の対処も簡単になります。
加工工程や復旧工程を管理するために Airflow や Dagster 等のワークフロー管理ツールを導入するのもよいでしょう。
速度
主に DB, DWH 内でのデータ加工にかかる時間と、BIツールをからレポートを出力するときにかかる時間、この二つを意図しています。
今回の場合、毎日データが増えていくので工夫しなければスキャン量が毎日増えていきます。
パーティショニングやクラスタリングをするべきでしょう。
また、BIツールで参照するテーブルも工夫しなければレポート生成に時間がかかってしまいます。
レポート生成時に他のテーブルと統合したり、ある粒度で集約したりすることが必要な場合、事前に利用しやすい形で用意しておけないかを考えます。一般的にデータマートと呼ばれるものです。
大規模なデータを扱う場合、必ずしも正規化された形が適切とは限りません。
改善例
先述の良くない点を改良した構成を考えてみます。
今回はできるだけマネージドサービスを利用する構成を目指します。
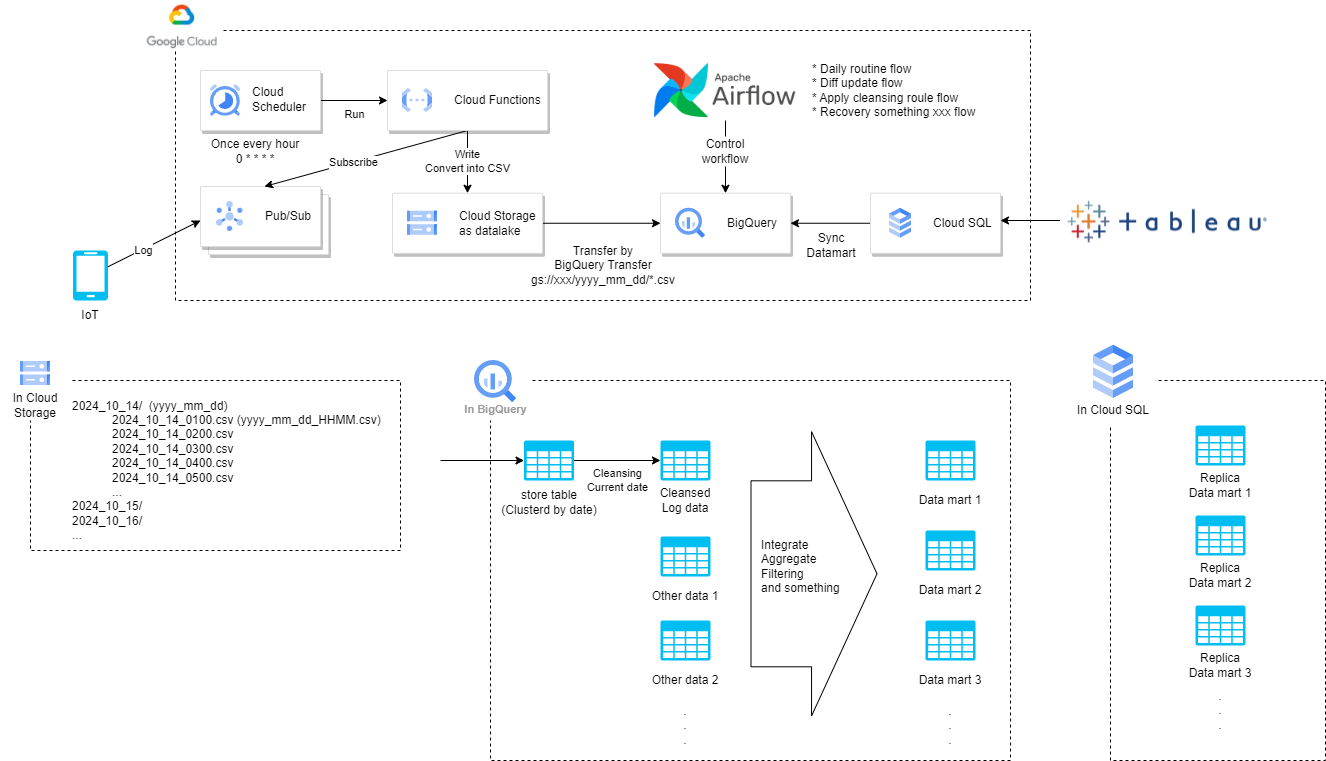
動作機序
- センサやスマホからの出力を Pub/Sub に送信
- 1時間ごとに Cloud Scheduler から Cloud Functions を起動
- Pub/Sub にたまったデータを一気に Subscribe して CSV に変換して GCS に出力
- BigQuery Data Transfer Service を使って GCS の CSV を BigQuery の store table に蓄積
- store table から当日データのみをクレンジングしてクレンジング済みデータに Insert
- クレンジング済みデータとその他データからデータマートを作成
- Cloud SQL に存在するデータマートのレプリカを同期
※1 わかりやすくするために当日と書いているが、厳密には前日データを処理する。なぜなら1日分データが全て揃ってから処理した方が効率が良いから。
※2 BigQuery Data Transfer Service は一日一回実行する。ランタイムパラメータを使って前日の GCS パスを参照するように設定する。
※3 前回の構成は Log 一件ごとに BigQuery に Insert するようになっていたが、量が多いと Operation Limit に引っかかる恐れがある。今回の構成では起こらない。
評価
前の構成と比較してみます。
コスト
Cloud SQL にデータマートのレプリカを作成しているので、たくさんの人間がBIツールでインタラクティブにレポートを作成しても Cloud SQL を起動している時間に対してしか課金が発生しません。(BIツールで作成するレポートがそれほど多くなかったり、固定レポートの出力のみの場合は冗長かもしれません)
store table には愚直にデータが蓄積されて、その後当日分のデータだけクレンジングを行いクレンジング済みデータのテーブルに Insert します。
store table は日付でクラスタリングされているので、スキャン量は当日データのみになります。
堅牢性
GCSにデータをためているので、仮に Big Query のデータが消えても復旧可能です。
クレンジング済みデータに汚染されたデータや壊れたデータが見つかった場合、ルールを更新してからデータに再度反映する必要があります。
クレンジングは当日分のみにしていますが、この日付レンジを広げるだけで更新したクレンジングルールの再適用ができます。
Airflow で定常フロー、復旧フロー、差分更新フローを管理していれば、不具合が見つかった場合もより確実に早く安全に復旧可能でしょう。
速度
データをクラスタリングしているので、当日分の SELECT は高速になります。
目的に合わせて統合・集計済みのデータマートをBIツールから参照するので、レポートを生成するときにかかる時間が短縮されます。
オプション
一例を示しましたが目的によって他の構成も考えられます。
- Cloud Scheduler, Cloud Functions, Data Transfer Service を使っていますが、Airflow 使っても同じことができます。
- PubSub から直接 GCS に出力も可能ですが、デコードやコンバートなどの自由度を確保するには Cloud Functions を利用するのがベターでしょう。
- Pub/Sub のデータをそのまま Raw data としてデータレイクに保存してから CSV に加工する方がお行儀が良いです。
- BigQuery Data Transfer Service を使って GCS から BigQuery に転送していますが、External table を使えば GCS の CSV をテーブルとして扱えるので、その方法でデータを持ってくることもできます。(ワイルドカードも使えて便利)
- GCS にファイルが生成されたときに Cloud Functions をトリガーすることができるので、ファイル単位で BigQuery に転送していくのもアリ。
- BigQuery の Materialized View はベースのテーブルが更新されると自動で更新されて超便利ですが、使い方をミスれば超課金が発生するリスクがあるのであまりお勧めはしません。
感想
たいした内容書いてないけど結構たいへんでした。
文字がミチミチで読むのしんどいですね。反省します。