はじめに
AidemyのWebアプリコースを受講し、その最終成果物の作成についてを記事にしました。
どのようなアプリを作るのか少し悩みましたが最近流行っていて自分も観ているアニメを題材にしようということで、「葬送のフリーレン」のキャラクターを判別するアプリを作ることにしました。
0.目次
0.目次
1.開発環境
2.使用ライブラリ
3.画像収集
4.データの前処理
5.学習データとテストデータの作成
6.学習モデルの作成と学習
7.モデルの適用
8.終わりに
9.参考にしたサイト
1.開発環境
JupyterLab 3.6.3
python: 3.10.12
Apple M1
・各ファイルのディレクトリ
'/Users/***/Aidemy/output3_frames'
※以降、Aidemyより上の階層は省略いたします。
・実行しているpythonの.ipynbファイル(jupyter lab)です。
Aidemy/character_identification.ipynb
・各データとファイル
Aidemy/anime1.mov
Aidemy/output3_frames
Aidemy/trimmed_faces2
Aidemy/trimmed_faces2/Eisen
Aidemy/trimmed_faces2/re_Eisen
Aidemy/result
2.使用ライブラリ
keras: 2.15.0
opencv-python: 4.8.1.78
matplotlib: 3.8.2
numpy: 1.26.0
scikit-learn: 1.3.2
tensorflow: 2.15.0
PIL : 10.1.0
setuptools: 68.0.0
3.画像収集
以下の手順で画像収集を行いました。
・手順
2-1 動画を録画(.movファイル)する
2-2 録画した動画を一定の間隔でスクショする
2-3 スクショした画像を顔のみ抽出する
2-4 画像をキャラごとに分類
それでは、各手順ごとに行った内容を説明していきます。
※2-1はコードを書くものではないので、今回は説明を割愛します。
2-2.録画した動画を一定の間隔でスクショする
まず、動画が1秒間にどのくらいフレームが使われているのか確認し、
その後に1秒間に何回分スクショを取るのか決めます。
#1秒間にフレームがどのくらいあるか確認する。
import cv2
# 動画ファイルのパスを作る
video_path = 'anime1.mov'
# 動画を読み込み
cap = cv2.VideoCapture(video_path)
# フレームレートの取得(1秒間にフレームがいくつあるか確認する。)
fps = cap.get(cv2.CAP_PROP_FPS)
print("動画のフレームレート:", fps)
cap.release()

1秒間に60枚の画像が使われていることが分かりました。
パッと動画を見た感じで1秒に12枚前後取れば様々な表情が抑えれるのではないかと思ったため、今回は、1秒に12枚ずつ画像をスクショすることにしました。
※1話分を実際に1秒12分割した所、同じ画像が多すぎため2話目以降は1秒4分割に修正しました。
#動画からスクショをする方法
import cv2
import os
# 動画ファイルのパスを指定します。
video_path = 'anime1.mov'
# スクリーンショットを保存するフォルダを指定し、存在しない場合は作成します。
output_folder = 'output3_frames'
# osライブラリ もし、変数名のoutput_folderのフォルダがなければフォルダを新規作成する。
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# OpenCVを使用して動画ファイルを読み込む。
cap = cv2.VideoCapture(video_path)
# 動画のフレームレート(1秒あたりのフレーム数)を取得します。
fps = cap.get(cv2.CAP_PROP_FPS)
# フレーム間隔を計算して、フレームレートを整数に変換する。
# この場合、frame_interval = 「5」
frame_interval = int(fps / 12)
# 処理するフレームの番号を初期化(設定)します。
frame_number = 0
# 保存するフレームの番号を初期化(設定)します。
# 後々、画像のNo.になる。
captured_frame_number = 0
# 動画の終わりまでループを続けます。
# While Trueは無限ループなので、breakを必ず付ける。
while True:
# 動画から次のフレームを読み込みます。
# retには真偽値が代入される。True or False
# frameには画像データ(NumPy配列)で格納される。
ret, frame = cap.read()
# フレームがなくなったら(動画の終わりに達したら)ループを終了します。なくなるとFalseになる。
if not ret:
break
# frame_number % frame_interval が 0 の場合に保存します。
# frame_interval =「5」なので、1秒60フレームで5フレームに1度スクショする。つまり、1秒に12枚スクショする。
if frame_number % frame_interval == 0:
#print(captured_frame_number)
#cv2.imwriteはcv2.imwrite(ファイル名,画像データ(numpy配列))が引数。
cv2.imwrite(os.path.join(output_folder, f'frame1_{captured_frame_number}.jpg'), frame)
# 画像のNo.をインクリメント(増加)し、重複しないようにする。
captured_frame_number += 1
# フレーム番号をインクリメント(増加)させてループに戻る。
frame_number += 1
# 動画キャプチャをリリース(閉じ)ます。
cap.release()
print('end 合計'+str(captured_frame_number)+'枚')
1話だけで合計28313枚の画像が切り取れました。

フレーム間隔が狭すぎると同じ画像もかなり入っていたため、
2話以降は1秒4枚くらいの感覚に変更しました。
2-3 スクショした画像を顔のみ抽出する
画像にはキャラクターが写っていない画像もかなり多く含まれているため、
顔周辺を切り取り、別のフォルダに保存します。
ここでは、
cv2.CascadeClassifierのCascadeメソッドを活用した識別器(分類器)で有志がGithubで公開してくださっている「lbpcascade_animeface.xml」lbpcascade_animeface.xmlという公開されているトレーニング済みのモデルを活用します。
#顔の周辺画像を四角でトリミングする。
import cv2
import os
def crop_anime_face(input_folder, output_folder):
#変数名「face_detector」にlbpcascade_animeface.xmlを代入
face_detector = cv2.CascadeClassifier('lbpcascade_animeface.xml')
# フォルダの存在の有無確認と作成
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 元データのフォルダ確認。画像ファイルだけ読み取るようにする。
for filename in os.listdir(input_folder):
#末尾を指定して抽出。
if filename.lower().endswith(('.png', '.jpg', 'jpeg')):
img_path = os.path.join(input_folder, filename)
img = cv2.imread(img_path)
else:
continue
faces = face_detector.detectMultiScale(img)
# 検出された顔の周囲に矩形を描画
for i, (x, y, w, h) in enumerate(faces):
#print(f"顔の位置とサイズ:(x: {x}, y: {y}, w: {w}, h: {h})")
#cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
face_img = img[y:y+h, x:x+w]
# 切り出した顔の画像を保存
output_path = os.path.join(output_folder, f'trimmed_{filename}_{i}.jpg')
cv2.imwrite(output_path, face_img)
crop_anime_face('/Users/***/Aidemy/output3_frames', '/Users/***/Aidemy/trimmed_faces2')
これにより、
事前にスクショして保存した画像から顔を検出して、一定の範囲で矩形に切り取った画像が以下のように保存されます。
2-4 画像をキャラごとに分類
この分類はどうしても自動化できないため手動で行いました。
5キャラクター合計で7時間くらいかかりました。
分類を行った結果は下記です。
re_Eisenの画像数: 10
re_Starkの画像数: 306
re_Heiterの画像数: 45
re_Himmelの画像数: 542
re_Fernの画像数: 3768
re_Frierenの画像数: 4117
以下の理由から各キャラクターで枚数にかなりのばらつきが出てしまった。
・キャラクターの出現時間が大幅に違うこと
・そもそも、前述のカスケード型識別器は一部のキャラクターが顔と識別されない(長方形だったり、やけに髭が長い。仮面つけてるから?)
この枚数で行うと学習結果の偏りが出てしまう恐れがあるため、
足りないキャラクターはそのキャラのみの動画を数秒単位で取り、2-2で画像を確保し、
更に偏りが出ないように画像をスクリーングした結果、最終的は下記枚数になりました。
re_Eisenの画像数: 55
re_Starkの画像数: 139
re_Heiterの画像数: 21
re_Himmelの画像数: 423
re_Fernの画像数: 351
re_Frierenの画像数: 430
これでフォルダ分けが完了です。
4.データの前処理
今回、使う転移学習のモデルであるvggモデルが32*32のサイズの画像に適しているモデルのため、
リサイズを行います。(学習させる際は全ての画像サイズを統一をする必要があります。)
import cv2
import os
def resize_images_in_folder(source_folder, dest_folder, new_size):
if not os.path.exists(dest_folder):
os.makedirs(dest_folder)
for root, dirs, files in os.walk(source_folder):
for file in files:
if file.lower().endswith(('.png','jpg','jpeg')):
image_path = os.path.join(root, file)
image = cv2.imread(image_path)
resized_image = cv2.resize(image, new_size)
rel_path = os.path.relpath(root, source_folder)
dest_path = os.path.join(dest_folder, rel_path)
if not os.path.exists(dest_path):
os.makedirs(dest_path)
cv2.imwrite(os.path.join(dest_path, file), resized_image)
source_folders = ['/Users/***/Aidemy/trimmed_faces2/re_Eisen', '/Users/***/Aidemy/trimmed_faces2/re_Fern', '/Users/***/Aidemy/trimmed_faces2/re_Frieren', '/Users/***/Aidemy/trimmed_faces2/re_Heiter', '/Users/***/Aidemy/trimmed_faces2/re_Himmel', '/Users/***/Aidemy/trimmed_faces2/re_Stark']
dest_folders = ['/Users/***/Aidemy/trimmed_faces2/re_Eisen', '/Users/***/Aidemy/trimmed_faces2/re_Fern', '/Users/***/Aidemy/trimmed_faces2/re_Frieren', '/Users/***/Aidemy/trimmed_faces2/re_Heiter', '/Users/***/Aidemy/trimmed_faces2/re_Himmel', '/Users/***/Aidemy/trimmed_faces2/re_Stark']
new_size = (32, 32)
for source, dest in zip(source_folders, dest_folders):
resize_images_in_folder(source, dest, new_size)
次にフォルダ分けした画像にラベルを付ける関数を作ります。
今回はフォルダ名=キャラ名という想定で進めています。
def load_images_from_folder(folder):
images = []
labels = []
character_name = os.path.basename(folder) # フォルダ名からキャラクター名を抽出
for filename in os.listdir(folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')):
img = cv2.imread(os.path.join(folder, filename))
if img is not None:
#既にリサイズしている場合は必要なし。
image = cv2.resize(img, (32, 32))
#
images.append(img)
#
labels.append(character_name) # 各画像にキャラクター名をラベルとして追加
return images, labels
5.学習データとテストデータの作成
トレーニングデータとテストデータをランダムに分割します。
test_size=0.3がテストサイズの量になるので、今回は3割をテストデータに用います。
import os
import numpy as np
from sklearn.model_selection import train_test_split
# 各キャラクターのフォルダパス
folders = ['/Users/***/Aidemy/trimmed_faces2/re_Eisen', '/Users/***/Aidemy/trimmed_faces2/re_Fern', '/Users/***/Aidemy/trimmed_faces2/re_Frieren', '/Users/***/Aidemy/trimmed_faces2/re_Heiter', '/Users/***/Aidemy/trimmed_faces2/re_Himmel', '/Users/***/Aidemy/trimmed_faces2/re_Stark']
# トレーニングデータとテストデータを格納するリスト
train_data = []
test_data = []
train_labels = []
test_labels = []
for folder in folders:
# フォルダから画像データを読み込む
images, labels = load_images_from_folder(folder)
# トレーニングデータとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.3)
# 結果をリストに追加
train_data.extend(X_train)
test_data.extend(X_test)
train_labels.extend(y_train)
test_labels.extend(y_test)
# 最終的なトレーニングセットとテストセットを作成
train_data = np.array(train_data)
test_data = np.array(test_data)
train_labels = np.array(train_labels)
test_labels = np.array(test_labels)
train_data = train_data.astype('float32') / 255.0
test_data = test_data.astype('float32') / 255.0
これで画像データをトレーニングデータとテストデータに割り振ることができました。
6.学習モデルの作成と学習
今回、学習モデルには転移学習のモデルであるVGG16を使用しているため、
少ない画像でも対応が可能とのことなので、画像のかさ増しを行わずに学習を進めてみます。
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC, SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from tensorflow.keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, Dropout, Input
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.optimizers.legacy import SGD
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# ImageNetで事前学習した重みも読み込まれます
# カラーの場合は3
input_tensor = Input(shape=(32, 32, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 何個の答えか。
number_of_classes = 6
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(number_of_classes, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# modelの19層目までがvggのモデル
# VGG16は19層ある。
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
# ラベルエンコーダの初期化
label_encoder = LabelEncoder()
train_labels_encoded = label_encoder.fit_transform(train_labels)
test_labels_encoded = label_encoder.transform(test_labels)
# ラベルをone-hotエンコーディング
train_labels_one_hot = to_categorical(train_labels_encoded, num_classes=6)
test_labels_one_hot = to_categorical(test_labels_encoded, num_classes=6)
# トレーニングの実行
history = model.fit(train_data, train_labels_one_hot, epochs=100, batch_size=32, validation_data=(test_data, test_labels_one_hot))
# テストデータによるモデルの評価
score = model.evaluate(test_data, test_labels_one_hot, verbose=0)
print(score)
#modelの保存
model.save("my_model.keras")
#1回目~100回目までの結果をプロットする。
#acc, val_accのプロット
plt.plot(history.history['accuracy'], label='accuracy', ls='-')
plt.plot(history.history['val_accuracy'], label='val_accuracy', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
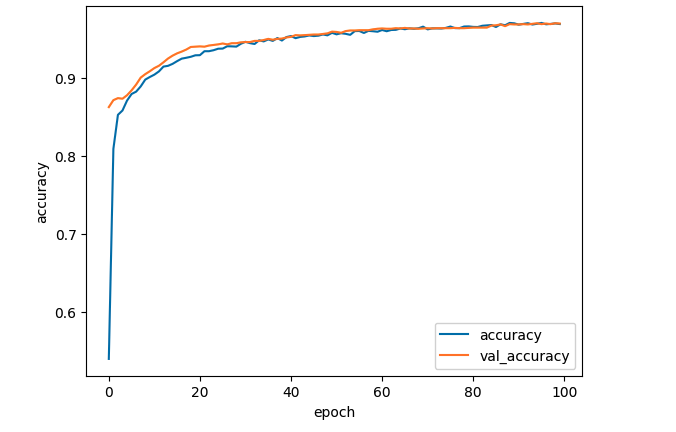
訓練データとテストデータの精度が良い感じになったモデルとなりました。
7.モデルの適用
では、最後にモデルの適用を行います。
トレーニングデータとテストデータで使っていない、Google検索で取ってきた画像を元に検出結果から取ってきた画像を使用します。
import os
import keras
import cv2
import matplotlib.pyplot as plt
from keras.models import load_model
import numpy as np
import glob
#ディレクトリを作成
if not os.path.exists("result"):
os.mkdir("result")
dirname = "./result/"
#modelの読み込み
model = load_model("my_model.keras")
#適用する画像があるディレクトリを開く
image_dir_path = '/Users/***/Aidemy/test_file/'
# JPEGファイルのリストを取得
jpg_files = glob.glob(image_dir_path + '/*.jpg')
jpeg_files = glob.glob(image_dir_path + '/*.jpeg')
png_files = glob.glob(image_dir_path + '/*.png')
# すべてのファイルリストを結合
img_path_list = jpg_files + jpeg_files + png_files
num = 0
for img_path in img_path_list:
img = cv2.imread(img_path, 1)
name,ext = os.path.splitext(img_path)
num += 1
file_name = dirname + "pic" + str(num) + str(ext)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cascade_path = "./lbpcascade_animeface.xml"
cascade = cv2.CascadeClassifier(cascade_path)
#顔認識を実行
faces=cascade.detectMultiScale(img_gray, scaleFactor=1.2, minNeighbors=1, minSize=(68,68))
Labels=["re_Eisen", "re_Fern", "re_Frieren", "re_Heiter", "re_Himmel","re_Stark"]
Threshold = 0.90
#顔が検出されたとき
if len(faces) > 0:
for fp in faces:
# 学習したモデルでスコアを計算する
img_face = img[fp[1]:fp[1]+fp[3], fp[0]:fp[0]+fp[2]]
img_face = cv2.resize(img_face, (32, 32))
score = model.predict(np.expand_dims(img_face, axis=0))
# 最も高いスコアを書き込む
score_argmax = np.argmax(np.array(score[0]))
#閾値以下で表示させない
if score[0][score_argmax] < Threshold:
continue
#文字サイズの調整
fs_rate= 0.008
text = "{0} {1:.1f}% ".format(Labels[score_argmax], score[0][score_argmax]*100)
#文字を書く座標の調整
text_rate = 0.22
#ラベルを色で分ける
#cv2なのでBGR
if Labels[score_argmax] == "re_Eisen":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0, 0, 255), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)),cv2.FONT_HERSHEY_DUPLEX,(fp[3])*fs_rate, (0,0,255), 2)
if Labels[score_argmax] == "re_Fern":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0, 255, 0), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)),cv2.FONT_HERSHEY_DUPLEX,(fp[3])*fs_rate, (0,255,0), 2)
if Labels[score_argmax] == "re_Frieren":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (152, 145, 234), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (152, 145, 234), 2)
if Labels[score_argmax] == "re_Heiter":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0,255,255), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (0,255,255), 2)
if Labels[score_argmax] == "re_Himmel":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(255,0,0), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (255,0,0), 2)
if Labels[score_argmax] == "re_Stark":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(100,145,200), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (100,145,200), 2)
plt.figure(figsize=(8, 6),dpi=200)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
cv2.imwrite(file_name, img)
# 顔が検出されなかったとき
else:
print("no face")
結果は以下のようになりました。




・フリーレン、フェルンは画像があるため、ほとんど検出されていた。
・ヒンメル、シュタルクは検出される時とそうでない時がある。
・アイゼン、ハイターは単体の画像でも検出されない。
これは画像の数がそもそも少なかったからの可能性があると思いました。
8.終わりに
・今回、二値化、標準化などのデータ処理を行わなかったため画像数が少ない状態でも結果が出るか試しましたが、一定の結果は得られることがわかりました。
・画像は一定数無いと難しいということが分かりました。
・そもそも分類器時点で顔として認識されてないのか、それとも判別が出来ていないので表示されないのか分からないため、不明の場合は不明と出すようにしても良いと思いました。
今回、記事にするのはここまでですが、今後、画像加工などで枚数を増やし精度を上げていきたいと思います。
9.参考にしたサイト
・動画から画像に変換する方法
https://note.nkmk.me/python-opencv-video-to-still-image/
https://note.com/nao_py/n/n149e703aad05
・全体的な方法
https://qiita.com/Taka_input/items/04a23bd8e9101788e583
・顔検出
https://ultraist.hatenablog.com/entry/20110718/1310965532
https://github.com/nagadomi/lbpcascade_animeface