タイトルににある通り、本家ことProxmox Server Solutions のサポート窓口に問い合わせ、正式にサポートされないことを確認した構成に関する内容です。
実際に利用する際は自己責任でお願いします。
TL;DR
- なぜサポートされないのか
- デフォルト設定の2ノードクラスタでは1ノード停止時にクラスタも利用不可となるから。
- 設定を変更することで上記は免れるが、今度はスプリットブレインに陥る可能性があるから。
- 読み取りモードにならない為の設定
-
/etc/pve/corosync.confにtwo_node: 1を追加
-
- NW障害発生時にスプリットブレインにならない為の設定
- フェンシングで対応
2ノードクラスターの問題点
なぜサポートされないのか。
PVEでは3ノードでのクラスタ構成が推奨されています。
PVEクラスタは、Corosyncをクラスタリングに採用しており、クラスタの整合性を保つために「Quorum(クォーラム)」という概念が使われます。Quorumはクラスタ内のノードの多数決に基づいて、クラスタが正常に動作できるかを判定します。
そのため、2ノードクラスタでは1ノード停止した際に過半数を満たせなくなり、クラスタが正常に動作していないと判定されるためです。
3ノードの例
3ノードの場合、過半数は2なのでQuorumも2。
そのため、2ノードCorosync通信が行えていればクラスタは動作する。
root@pve:~# pvecm status
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
2ノードの例
2ノードの場合、過半数は2(1では過半数に足りない)なのでQuorumも2。
そのため、2ノードCorosync通信が行えていればクラスタは動作する。
つまり、1ノード疎通が行えくなるとクラスタは動作しない。
root@pve:~# pvecm status
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2
Flags: Quorate
たまに2ノードでクラスタを構築した、という表現の記事等を見ることがありますが、これらの多くはちゃんと障害試験を行っていないか、Qデバイスを利用した2+1と呼ばれる構成の場合がほとんどです。
Quorumを満たせなくなるとどうなるか?
Quorumを満たせなくなり、起動しているPVEノードは再起動後、読み取りモードで起動します。
読み取りモードでは、PVEノード上のリソース(ホストVM・CT)の起動が出来ません。
そのため、クラスタ単位で利用が出来なくなります。
※なお、障害発生ノードが復旧した場合などにはQuorumを満たせるため、正常に利用可能になります。
2ノードクラスターを利用するには
Quoramu喪失時に読み取りモードにならない為の設定
この記事でも書きましたが、以下の設定を記載します。
quorum {
provider: corosync_votequorum
two_node: 1
}
この構成での問題点
前述の設定により、Quorumが2から1に変更となり、Corosyncとして異常状態とならないため、再起動・読み取りモードでの起動はしなくなります。
ですが今度はPVEノードが停止した場合は問題がないが、Corosyncネットワークの障害発生時にスプリットブレインが発生するという状況になります。
スプリットブレインとは
スプリットブレイン(Split-Brain)は、ネットワーク分断(障害)により、各ノードがクラスタ全体の状況を認識できなくなる問題です。
この状態では各ノード・クラスタ上でリソースが動作し、データ不整合につながる可能性があります。
つまり、スプリットブレインによるデータ不整合等を防止するためにQuorumがあるということです。
実際に障害を起こした時の動作
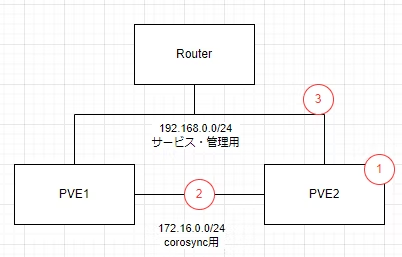
上記画像のような構成で、②の場所で障害を発生させます。
※片側のInterfaceをDownさせます。
クラスターの状態は以下のように対向ノードと接続できないため、voteは1ですが、two_node: 1を設定しているためQuorumが1となっているため、Quorate:Yesとなっています。
root@pve-2node1:/var/lib/vz/snippets# pvecm status
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 1
Quorum: 1
Flags: 2Node Quorate WaitForAll

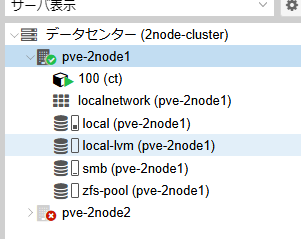
CT100をHA対象としています。
また、ZFSレプリケーションを設定しています。
ノード1のGUIの画面
ノード2のGUIの画面
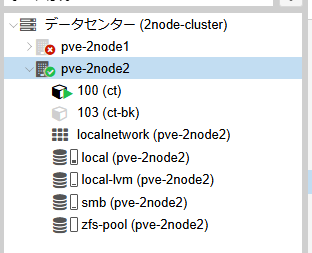
各ノードでCT100が実行されています。
今回はZFSを利用しているためリソースとしては問題なく起動できていますが、同一リソースが2つのノード上に存在し、サービス接続時などに問題が発生する可能性があります。
また、NFSなどの共有ストレージの場合は2つノードから書き込みが発生し、データ不整合が発生する可能性があります。
復旧させた時の動作
※異常系からの復旧なので再現性があるかは微妙です。
Corosyncの復旧後、HAのプライオリティが高い方(正常時にリソースが起動している方)のノードが一度再起動しました。
その後はHAの設定通りの動作(リソースはプライオリティが低いノードから削除・高いノードで実行)となりました。
ノード再起動直後に上記動作がされており、プライオリティが低いノードで動作していた期間の差分は反映されていないと思われます。
そういう意味では、データ不整合が発生しているといえます。
NW障害発生時にスプリットブレインにならない為の設定
障害発生ノードが起動しているからスプリットブレインになってしまうので、Fencingで停止してしまおうという考えです。
ドキュメントにはPVEにはWatchdogをサポートしているため、WatchdogをサポートしているFencingデバイスを活用してね!と書いてあります。
今回はそもそもが公式サポートされない構成なので、Watchdogは意識せずにFencingを実行してみたいと思います。
なので、Linuxだけで実現できないかを模索しました。
スクリプト
Corosyncインタフェースであるvmbr1がDownしたらOSをシャットダウンするスクリプトを作成しました。
#!/bin/bash
# 監視対象のNIC名
MONITORED_NIC="vmbr1"
# ログファイル
LOG_FILE="/var/log/fencing.log"
# NICの状態を取得
NIC_STATUS=$(ip link show $MONITORED_NIC | grep -o "state UP")
# ログに現在の状態を記録
echo "$(date) - Checking NIC status for $MONITORED_NIC: $NIC_STATUS" >> $LOG_FILE
if [ "$NIC_STATUS" != "state UP" ]; then
echo "$(date) - NIC $MONITORED_NIC is DOWN. Executing fencing action." >> $LOG_FILE
# フェンシング処理(シャットダウン)
shutdown -h now
else
echo "$(date) - NIC $MONITORED_NIC is UP. No action required." >> $LOG_FILE
fi
スクリプトの配置場所
PVEのデフォルト作成されるlocalのストレージ設定でスニペットを有効にし、そこに格納しました。
各ストレージのパスは/etc/pve/storage.cfgに記載されています。
設定を変更しないと該当のディレクトリは作成されない点には注意が必要です。
※スニペットを有効にしないと/var/lib/vz/snippets/は作成されない等。
root@pve-2node1:~# cat /etc/pve/storage.cfg
dir: local
path /var/lib/vz
content snippets,vztmpl,backup,iso
shared 0
ちなみに、このディレクトリに配置することでGUIのスニペット一覧として表示されます。
ですが、GUIから実行できる操作は削除のみです。
現状イマイチなので、実行・アップロード・ジョブ設定等出来てもいいのでは?という機能リクエストは送って見ようと思いました。
スクリプトのジョブ設定
ジョブ設定はsystemdから行いました。
サービス設定
[Unit]
Description=NIC Fencing Script
After=network.target
[Service]
ExecStart=/var/lib/vz/snippets/fencing.sh
Type=simple
タイマー設定
[Unit]
Description=Run NIC Fencing Script every 10 seconds
[Timer]
OnBootSec=10s
OnUnitActiveSec=10s
[Install]
WantedBy=timers.target
権限変更・有効化
chmod +x fencing.sh
systemctl enable fencing.timer
systemctl start fencing.timer
systemctl list-timers --all | grep fencing
journalctl -u fencing.service
動作確認
Corosyncの対象インタフェースをDownさせ、ノードシャットダウンされることを確認。
もちろん、ノード障害同様にHAリソースもマイグレーションされました。
その他
懸念点
今回の例ではインタフェースのDownを検知してノードをシャットダウンします。
なので、Corosyncのインタフェースがノード直結の場合には、両ノードダウンが発生します。
間にスイッチ等が存在し、インタフェースのステータスが連動しないことが必要です。
※今回の環境はPonPで直結になっていたため、片方のノードのみでスクリプトを有効にしました。
まとめ
フェンシングをしてスプリットブレインにならないようにすれば、2ノードでのHAクラスタも出来なくはなさそうです。
ですが、本家サポートなしでここまでするなら余っているノード・NAS・PBSあたりをQデバイスにして2+1構成にしたほうがいいと思います。
ただし、インタフェースの障害発生時のフェンシング自体は3ノード以上の構成であっても、障害ポイント次第で正常に切り替わらない場合・切り替わった方が望ましいという場合に有用だと思うので、検討の余地はありそうです。
もちろんその場合はWatchdogの利用含めて、検知方法・検知後の動作など検討は必要です。
PVE2ノード関連記事
参考