PVE9.2正式リリース前にtestリポジトリで評価した内容です。
PVE9.2正式リリース時にどのようになっている(含まれているか・テクノロジープレビューか)は未定です。
VMware(vSphere)でいうところのDRS的な機能がPVE9.2で実装されそうです。
気になったのでフライング気味にtestリポジトリで評価しました。
※no-subscription の9.1.9にもGUIだけ振ってきているらしく、GUIから変更できるように見えて実際の設定には反映されないようです。そのため、実際に評価するなら現時点ではtestリポジトリになりそうです。
CRS(Cluster Resource Scheduler )
HAマネージャーがHAリソースの起動するノードを選ぶための仕組みです。
一応 basic/static が選べたのですが実際のリソース状況を評価する仕組みではなく、すべてのリソース(VM/CT)をアフィニティルールの対象にすることも多いため、あまり意識されない機能でした。
しかし最近ではリソースアフィニティルールがPVE9.0で追加されました。
一部のリソースだけルール対象にし、それ以外はCRSに任せたい。が、今までのCRSはDRSのようにリソース状況を考慮しない配置しかできなく、結局ノードアフィニティルールで実現…というケースはありました。
そのあたりが機能追加の理由かもしれません。
DRS(Distributed Resource Scheduler)
各ホストのリソース状況を見ながら、VM の初期配置や再配置を自動化する機能。
この機能を使えばクラスタに配置をある程度お任せできます。
逆に適切に設定できないとリソースが移動しまくり不安定になっちゃうとかもあります。
設定
色々ありますが、大雑把に言うと以下2点が追加
- HA Scheduling にDynamic Loadが追加
- 実際のCPU/MEM利用率に基づいた評価ができるオプション
- 今まではリソース数 or 割当CPU/MEMの評価しかなかった。
- Automatic Rebalance の追加
- 通常稼働中も自動でリソースを再配置する機能
- 多くの項目が追加されているが、ほとんどがこの機能のオプション
- 今まではHA関連のイベント(サービス起動・ノード障害・HA設定変更等)にしか評価・再配置しなかった
GUI
Before/Afterですが、もう見るからに項目が増えています。
Before
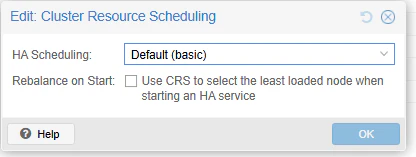
After

設定項目
まだドキュメントは追いついていません。
開発メーリスを生成AIに食わせた出力結果、間違ってるかもor今後変わるかもなので参考程度に。
| GUI項目 | 説明 | 運用上の見方 |
|---|---|---|
| HA Scheduling | CRS が HAリソースの起動先・復旧先・一部の再配置先を選ぶときのスケジューリング方式です。GUI の Default (basic) は、UI実装上は明示値を入れず、スキーマ既定値の basic を使う形です。 |
まずは basic で安全に始め、負荷偏りを見たい検証では static / dynamic を選びます。static / dynamic は tech preview 扱いです。 |
| Rebalance on Start | 停止中 HA リソースを start するタイミングで CRS に最適ノードを再評価させる設定です。選ばれたノードが現在ノードと異なる場合、そのノードで開始する動きになります。 | 停止状態からの起動時だけ最適配置したい場合に有効です。共有ストレージ環境では特に効果を見やすいです。 |
| Automatic Rebalance | クラスタ不均衡が条件を満たしたとき、HA Manager が HAリソースを自動で順次移動して負荷偏りを下げる機能です。現時点では HAリソースのみが対象で、HA affinity rules を遵守します。 |
static / dynamic のときのみ有効です。GUI もその前提で制御されます。 |
| Imbalance Threshold | 自動再配置を検討する クラスタ不均衡のしきい値です。不均衡は「各ノード load の 標準偏差 ÷ 平均」で計算されます。値が大きいほど鈍感、小さいほど敏感です。 |
0.0 にすると、Hold Duration を満たすたびに再配置候補を選びに行きます。GUI 上の最小値は 0.0、刻みは 0.01 です。 |
| Rebalancing Method | 自動再配置時に、どの移動候補を「最善」とみなすかを決める採点方式です。GUI の Default (bruteforce) は、明示設定しない場合に既定値 bruteforce を使う意味です。 |
厳密に imbalance 最小化を狙うなら bruteforce、CPU/メモリ使用率のバランスも含めた評価を試すなら TOPSIS です。 |
| Hold Duration |
Imbalance Threshold 超過が 何 round 連続したら再配置を実行候補にするか、を表します。単位は HA Manager round です。 |
1 round は 約10秒とされているため、既定値 3 は概ね 約30秒継続のイメージです。GUI 上の最小値は 0、刻みは 1 です。 |
| Minimum Imbalance Improvement | 再配置を実行するために必要な 最小改善率です。設定説明では「cluster node imbalance の最小相対改善量」とされています。 |
0.1 は 10% 以上の改善がないと移動しない、という見方でよいです。0.0 なら改善ゼロでも実行対象になり得ますが、負値不可のため 悪化する移動は実行しません。GUI 上は 0.0〜1.0、刻み 0.01 です。 |
HA Scheduling の選択肢の意味
| 選択肢 | 意味 |
|---|---|
| Basic (Resource Count) | ノード上の アクティブ guest 数を使って最適ノードを選ぶ、という方向に docs patch が更新されています。なお、現行の 9.0 beta 公開 docs では「アクティブ HA services 数」と書かれており、ここはドキュメント追随中です。 |
| Static Load | アクティブ guest の静的使用量で選定します。主に 設定済み CPU / Memory quota を含む考え方です。 |
| Dynamic Load | アクティブ guest の動的使用量で選定します。平均 CPU 使用量・平均 Memory 使用量・設定済み CPU / Memory quota を含む説明です。 |
Rebalancing Method の選択肢の意味
| 選択肢 | 意味 |
|---|---|
| Bruteforce | 候補移動の中から、クラスタ node imbalance が最小になるものを選びます。 |
| TOPSIS | 候補移動の中から、CPU / Memory 使用率の shifted RMS と最大値のバランスがよいものを選ぶ方式です。 |
評価(簡易版)
本格的な評価は正式リリース後にしようと思います。
CPU/MEM合わせて評価されるので、CPUに負荷をかけます。
また、ホストの負荷状況で判断するのでリソースだけでなくホストに負荷を与えたときの影響も見ます。
環境
- 3ノードクラスタ
- CT
- OSインストールめんどくさいから…
- 再配置時にマイグレーションじゃなくて停止・起動になるのは仕様通り(relocate扱いになる)
- 1CPU×4
- 2CPU×1
- ストレージ
- NFS
- CRS
- HA Scheduling を変更しながら動作確認
- Automatic Rebalance ON
- Imbalance Threshold は 0
- Hold Durationごとに再配置検討
- CTの負荷が小さく、デフォルト0.3では閾値到達しなかったので。
- Hold Duration は 1
- 待ち時間を間隔を短く
- Minimum Imbalance Improvement は 0
- 改善があまりなくても再配置する
- CTの負荷が小さく、デフォルト0.1では閾値到達しなかったので。
初期状態
1ノードに寄せておきます。

Basic
BasicではAutomatic Rebalance は対象外なので、Automatic RebalanceをONにしても何も起きません。
Static
2CPUのCT1、1CPUのCT2つずつに移動します。
VM・ホストに負荷をかけても移動はしません。
以下コマンドで8割、2分で負荷かけました。。
stress-ng --cpu 0 --cpu-load 80 --timeout 2m

Dynamic
VMに負荷をかけようとしたら、閾値設定がガバガバ・敏感すぎてひたすら再配置を繰り返し、カオスに…。たぶんですが、HA時の停止・起動の負荷にも反応しています。
しばらく放置したら、画像のようにシャッフルされた状態に。
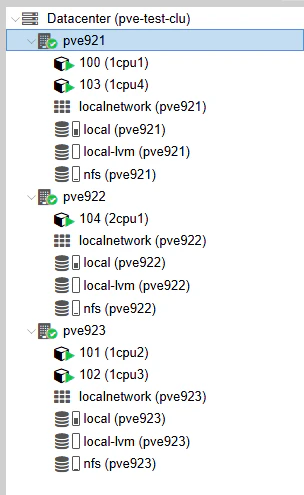
VMに負荷をかけようとしていると再配置が発生し、CTの停止・起動によりコマンド実行が出来ずなのでホストに負荷をかけます。
一つ目のホスト(pve921)に負荷をかけると、それ以外のノードに分散しました。
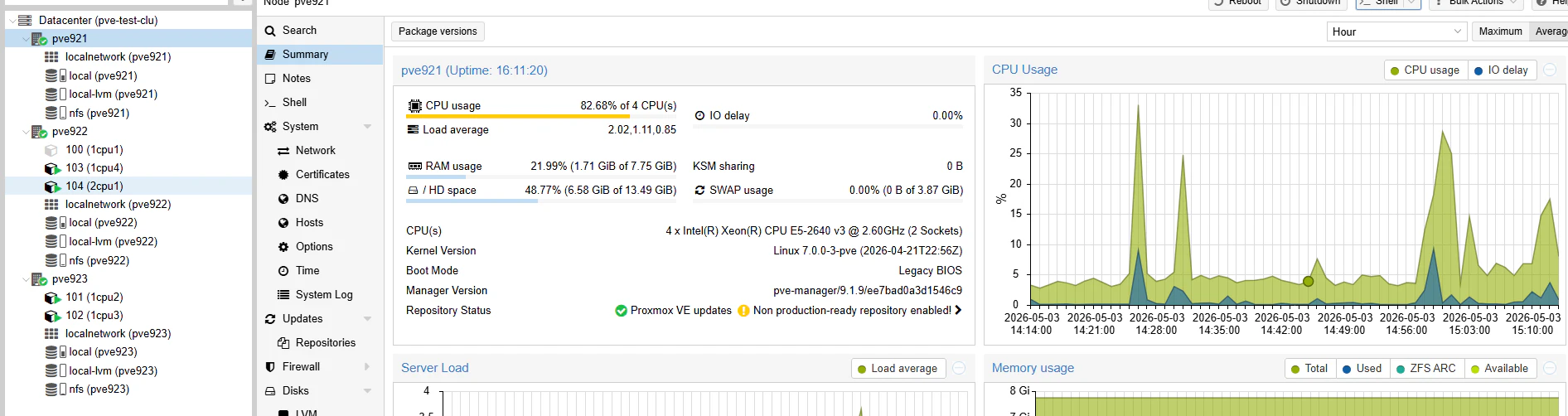
まとめ
とりあえず動作してそうです。
設定をガバガバにすると今回のように勝手に移動を繰り返してしまうので、実環境で使う際には設定値の検討が重要だと思います。
もっとちゃんとした評価は正式リリース後にやろうと思います。