以前Glue Data CatalogについてはAthenaを通じてなんとなく理解しました。
今回はGlue CrawlerとJobを触って理解していき、ETL後のデータベーステーブルを対象にAthenaで分析するまでをやってみたいと思います。
用語
AWS Glue Crawlerとは
Glue Crawlerは、Amazon S3やDynamoDBなどのデータストアに接続してデータをスキャンし、そのスキーマ(構造)を自動的に推論する機能です。
推論されたメタデータ(列名やデータ型など)に基づいてAWS Glue Data Catalogにテーブル定義を自動作成・更新し、データ資産を一元管理します。
これにより、AthenaやRedshift Spectrumなどのサービスから、S3上のファイル群などを標準的なSQLクエリで操作可能なデータベースとして扱えるようになります。
AWS Glue Jobとは
Glue Jobは、データの抽出(Extract)、変換(Transform)、ロード(Load)を行うETL処理を実行するための、サーバーレスな計算環境です。
Apache SparkやPython Shellをベースとしたマネージド環境上で、PythonやScalaで記述されたスクリプトを実行し、大規模なデータ処理やデータの移動を行います。
Data Catalogに登録されたデータをソースとして読み込み、フォーマット変換(例:CSVからParquet)やデータの結合・加工を行った上で、分析用ストレージ等に保存する役割を担います。
Parquetとは
Parquet(パーケット)は、Apache Hadoopエコシステムで開発された列指向のデータストレージフォーマットです。データを列単位で格納することで、特定のカラムのみを効率的に読み取れるため、分析クエリのパフォーマンスが向上し、圧縮率も高くなります。ビッグデータ処理(Spark、Hive、Prestoなど)で広く採用されており、スキーマ情報も含まれるため、データの互換性と可搬性に優れています。
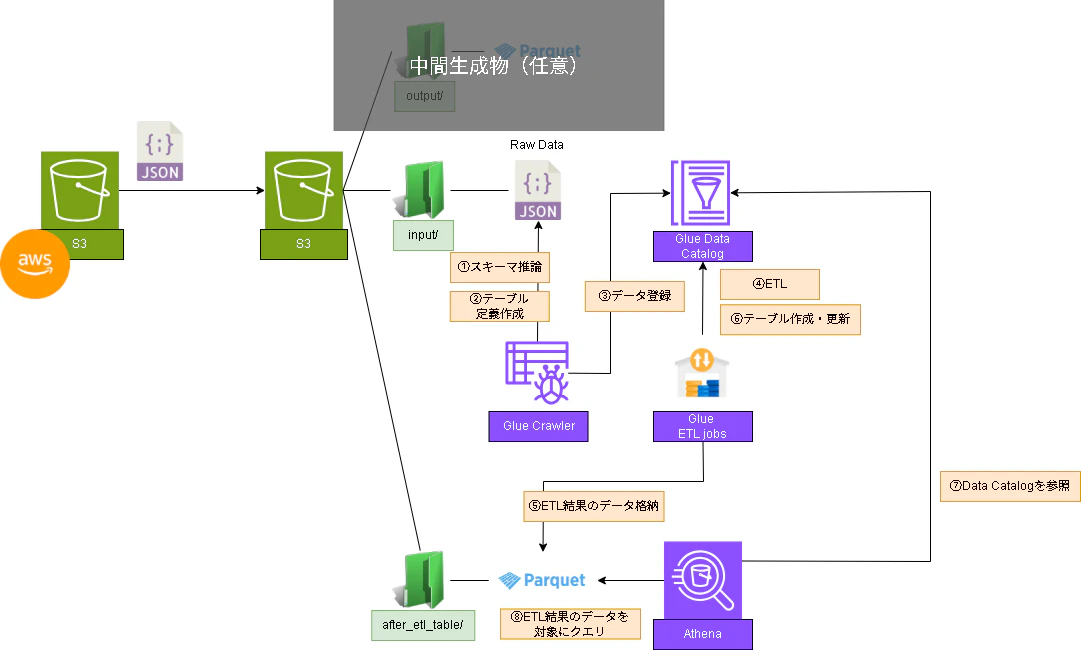
構築イメージ
ハンズオン
データの準備
生データ格納用のS3を準備します。
名前は任意のものを記入し、他はデフォルトの設定でバケットを作成します。
バケットを作成したら内部にinput/outputのフォルダを切っておきます。
CloudShellを使って以下のコマンドを実行します。
~ $ aws s3 ls aws-glue-handson-owhwfqnvqeo (先ほど作成したバケット名)
PRE input/
PRE output/
~ $
~ $ aws s3 cp s3://awsglue-datasets/examples/us-legislators/all/persons.json s3://aws-glue-handson-owhwfqnvqeo/input/
copy: s3://awsglue-datasets/examples/us-legislators/all/persons.json to s3://aws-glue-handson-owhwfqnvqeo/input/persons.json

S3のinputフォルダにjsonファイルがあることを確認します。
このJSONファイルの中身の一部を以下に示します。
アメリカ合衆国議会(連邦議会)の議員に関するプロフィール情報らしいです。
{"family_name": "Collins", "name": "Mac Collins", "links": [{"note": "Wikipedia (de)", "url": "https://de.wikipedia.org/wiki/Mac_Collins"}, {"note": "Wikipedia (en)", "url": "https://en.wikipedia.org/wiki/Mac_Collins"}, {"note": "Wikipedia (sv)", "url": "https://sv.wikipedia.org/wiki/Mac_Collins"}, {"note": "website", "url": "http://www.house.gov/maccollins"}], "gender": "male", "image": "https://theunitedstates.io/images/congress/original/C000640.jpg", "identifiers": [{"scheme": "bioguide", "identifier": "C000640"}, {"scheme": "everypolitician_legacy", "identifier": "C000640"}, {"scheme": "freebase", "identifier": "/m/0255g_"}, {"scheme": "google_entity_id", "identifier": "kg:/m/0255g_"}, {"scheme": "govtrack", "identifier": "400078"}, {"scheme": "house_history", "identifier": "11254"}, {"scheme": "icpsr", "identifier": "29340"}, {"scheme": "nndb", "identifier": "229/000036121"}, {"scheme": "opensecrets", "identifier": "N00002556"}, {"scheme": "snac", "identifier": "w6086f24"}, {"scheme": "thomas", "identifier": "00222"}, {"scheme": "uscongress", "identifier": "C000640"}, {"scheme": "viaf", "identifier": "258630693"}, {"scheme": "wikidata", "identifier": "Q1882459"}, {"scheme": "wikipedia", "identifier": "Mac Collins"}], "other_names": [{"lang": "bar", "note": "multilingual", "name": "Mac Collins"}, {"lang": "ca", "note": "multilingual", "name": "Mac Collins"}, {"lang": "da", "note": "multilingual", "name": "Mac Collins"}, {"lang": "de", "note": "multilingual", "name": "Mac Collins"}, {"lang": "en", "note": "multilingual", "name": "Mac Collins"}, {"lang": "es", "note": "multilingual", "name": "Mac Collins"}, {"lang": "fa", "note": "multilingual", "name": "\u0645\u06a9 \u06a9\u0627\u0644\u06cc\u0646\u0632"}, {"lang": "fi", "note": "multilingual", "name": "Mac Collins"}, {"lang": "fr", "note": "multilingual", "name": "Mac Collins"}, {"lang": "hu", "note": "multilingual", "name": "Mac Collins"}, {"lang": "it", "note": "multilingual", "name": "Mac Collins"}, {"lang": "lb", "note": "multilingual", "name": "Mac Collins"}, {"lang": "nb", "note": "multilingual", "name": "Mac Collins"}, {"lang": "nds", "note": "multilingual", "name": "Mac Collins"}, {"lang": "nl", "note": "multilingual", "name": "Mac Collins"}, {"lang": "nn", "note": "multilingual", "name": "Mac Collins"}, {"lang": "sv", "note": "multilingual", "name": "Mac Collins"}], "sort_name": "Collins, Michael", "images": [{"url": "https://theunitedstates.io/images/congress/original/C000640.jpg"}, {"url": "https://upload.wikimedia.org/wikipedia/commons/2/26/MacCollins.JPG"}], "given_name": "Michael", "birth_date": "1944-10-15", "id": "0005af3a-9471-4d1f-9299-737fff4b9b46"}
{"family_name": "Huizenga", "contact_details": [{"type": "fax", "value": "202-226-0779"}, {"type": "phone", "value": "202-225-4401"}, {"type": "twitter", "value": "RepHuizenga"}], "name": "Bill Huizenga", "links": [{"note": "Wikipedia (de)", "url": "https://de.wikipedia.org/wiki/Bill_Huizenga"}, {"note": "Wikipedia (en)", "url": "https://en.wikipedia.org/wiki/Bill_Huizenga"}, {"note": "Wikipedia (fa)", "url": "https://fa.wikipedia.org/wiki/\u0628\u06cc\u0644_\u0647\u0648\u06cc\u0632\u0646\u06af\u0627"}, {"note": "Wikipedia (fr)", "url": "https://fr.wikipedia.org/wiki/Bill_Huizenga"}, {"note": "Wikipedia (it)", "url": "https://it.wikipedia.org/wiki/Bill_Huizenga"}, {"note": "Wikipedia (ko)", "url": "https://ko.wikipedia.org/wiki/\ube4c_\ud558\uc774\uc9d5\uc544"}, {"note": "Wikipedia (pl)", "url": "https://pl.wikipedia.org/wiki/Bill_Huizenga"}, {"note": "Wikipedia (sv)", "url": "https://sv.wikipedia.org/wiki/Bill_Huizenga"}, {"note": "Wikipedia (zh)", "url": "https://zh.wikipedia.org/wiki/\u6bd4\u723e\u00b7\u4f11\u4f0a\u66fe\u52a0"}, {"note": "facebook", "url": "https://facebook.com/RepHuizenga"}, {"note": "instagram", "url": "RepHuizenga"}, {"note": "twitter", "url": "https://twitter.com/RepHuizenga"}, {"note": "website", "url": "http://huizenga.house.gov/"}, {"note": "youtube", "url": "RepHuizenga"}], "gender": "male", "image": "https://theunitedstates.io/images/congress/original/H001058.jpg", "identifiers": [{"scheme": "ballotpedia", "identifier": "Bill Huizenga"}, {"scheme": "bioguide", "identifier": "H001058"}, {"scheme": "cspan", "identifier": "1033765"}, {"scheme": "everypolitician_legacy", "identifier": "H001058"}, {"scheme": "fec", "identifier": "H0MI02094"}, {"scheme": "freebase", "identifier": "/m/05b0j1w"}, {"scheme": "google_entity_id", "identifier": "kg:/m/05b0j1w"}, {"scheme": "govtrack", "identifier": "412437"}, {"scheme": "house_history", "identifier": "15610"}, {"scheme": "icpsr", "identifier": "21142"}, {"scheme": "maplight", "identifier": "1448"}, {"scheme": "nndb", "identifier": "841/000265046"}, {"scheme": "opensecrets", "identifier": "N00030673"}, {"scheme": "quora", "identifier": "Bill-Huizenga"}, {"scheme": "thomas", "identifier": "02028"}, {"scheme": "uscongress", "identifier": "H001058"}, {"scheme": "votesmart", "identifier": "38351"}, {"scheme": "wikidata", "identifier": "Q862199"}, {"scheme": "wikipedia", "identifier": "Bill Huizenga"}, {"scheme": "youtube", "identifier": "UCQPlLLiMnysMmeJ5qUSSjQg"}], "other_names": [{"lang": "da", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "de", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "en", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "es", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "fa", "note": "multilingual", "name": "\u0628\u06cc\u0644 \u0647\u0648\u06cc\u0632\u0646\u06af\u0627"}, {"lang": "fi", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "fr", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "hu", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "it", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "ja", "note": "multilingual", "name": "\u30d3\u30eb\u30fb\u30cf\u30a4\u30bc\u30f3\u30ac\u30fc"}, {"lang": "ko", "note": "multilingual", "name": "\ube4c \ud558\uc774\uc9d5\uc544"}, {"lang": "lb", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "nb", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "nl", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "nn", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "pl", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "sv", "note": "multilingual", "name": "Bill Huizenga"}, {"lang": "zh", "note": "multilingual", "name": "\u6bd4\u723e\u00b7\u4f11\u4f0a\u66fe\u52a0"}], "sort_name": "Huizenga, Bill", "images": [{"url": "https://theunitedstates.io/images/congress/original/H001058.jpg"}, {"url": "https://upload.wikimedia.org/wikipedia/commons/c/c1/Bill_Huizenga,_Official_Portrait,_112th_Congress.jpg"}], "given_name": "Bill", "birth_date": "1969-01-31", "id": "00aa2dc0-bfb6-4412-a7fc-4f0cfdc00ebf"}
{"family_name": "Clawson", "contact_details": [{"type": "phone", "value": "202-225-2536"}, {"type": "twitter", "value": "RepCurtClawson"}], "name": "Curt Clawson", "links": [{"note": "Wikipedia (commons)", "url": "https://commons.wikipedia.org/wiki/Category:Curt_Clawson"}, {"note": "Wikipedia (de)", "url": "https://de.wikipedia.org/wiki/Curt_Clawson"}, {"note": "Wikipedia (en)", "url": "https://en.wikipedia.org/wiki/Curt_Clawson"}, {"note": "Wikipedia (fr)", "url": "https://fr.wikipedia.org/wiki/Curt_Clawson"}, {"note": "Wikipedia (it)", "url": "https://it.wikipedia.org/wiki/Curt_Clawson"}, {"note": "Wikipedia (zh)", "url": "https://zh.wikipedia.org/wiki/\u79d1\u7279\u00b7\u514b\u52de\u68ee"}, {"note": "facebook", "url": "https://facebook.com/RepCurtClawson"}, {"note": "twitter", "url": "https://twitter.com/RepCurtClawson"}, {"note": "website", "url": "http://www.curtclawson.com/"}], "gender": "male", "image": "https://theunitedstates.io/images/congress/original/C001102.jpg", "identifiers": [{"scheme": "bioguide", "identifier": "C001102"}, {"scheme": "cspan", "identifier": "75516"}, {"scheme": "everypolitician_legacy", "identifier": "C001102"}, {"scheme": "fec", "identifier": "H4FL19074"}, {"scheme": "freebase", "identifier": "/m/03wphq2"}, {"scheme": "google_entity_id", "identifier": "kg:/m/03wphq2"}, {"scheme": "govtrack", "identifier": "412604"}, {"scheme": "maplight", "identifier": "2060"}, {"scheme": "nndb", "identifier": "882/000168378"}, {"scheme": "opensecrets", "identifier": "N00035854"}, {"scheme": "thomas", "identifier": "02200"}, {"scheme": "uscongress", "identifier": "C001102"}, {"scheme": "votesmart", "identifier": "148899"}, {"scheme": "wikidata", "identifier": "Q16728087"}, {"scheme": "wikipedia", "identifier": "Curt Clawson"}], "other_names": [{"lang": "bar", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "ca", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "de", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "en", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "es", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "fi", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "fr", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "hu", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "it", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "ja", "note": "multilingual", "name": "\u30ab\u30fc\u30c8\u30fb\u30af\u30ed\u30fc\u30bd\u30f3"}, {"lang": "nds", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "nl", "note": "multilingual", "name": "Curt Clawson"}, {"lang": "zh", "note": "multilingual", "name": "\u79d1\u7279\u00b7\u514b\u52de\u68ee"}], "sort_name": "Clawson, Curtis", "images": [{"url": "https://theunitedstates.io/images/congress/original/C001102.jpg"}, {"url": "https://upload.wikimedia.org/wikipedia/commons/c/cc/Curt_Clawson_2014_Congressional_Photo.jpg"}], "given_name": "Curtis", "birth_date": "1959-09-28", "id": "00aca284-9323-4953-bb7a-1bf6f5eefe95"}
Glue Crawlerの準備と実行
Glueの管理画面を開きます。
Data Catalog配下のCrawlerを押下します。
Create Crawlerを押下します。
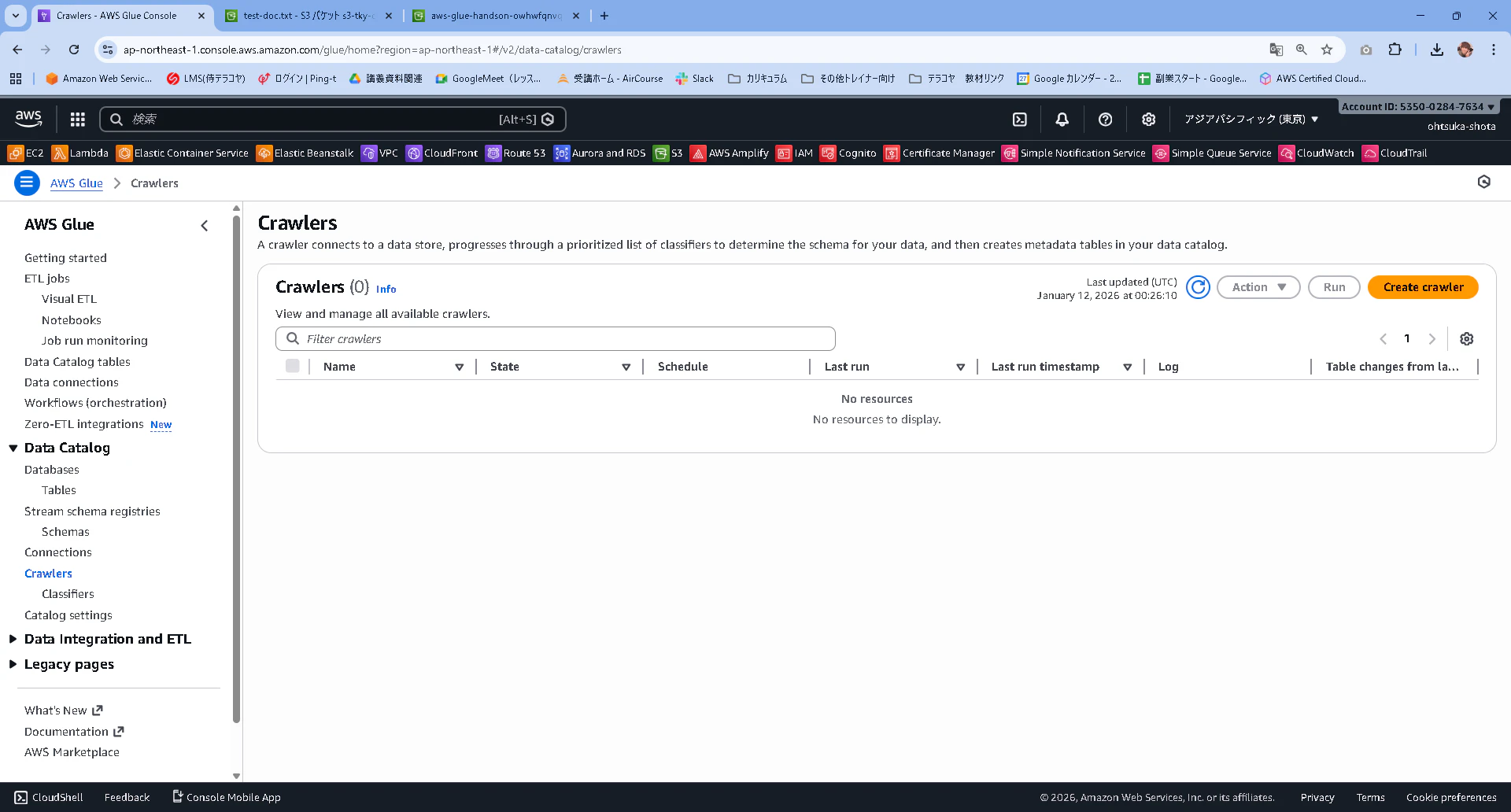
名前はなんでもいいですが、aws-glue-handson-crawlerとして次に進みます。
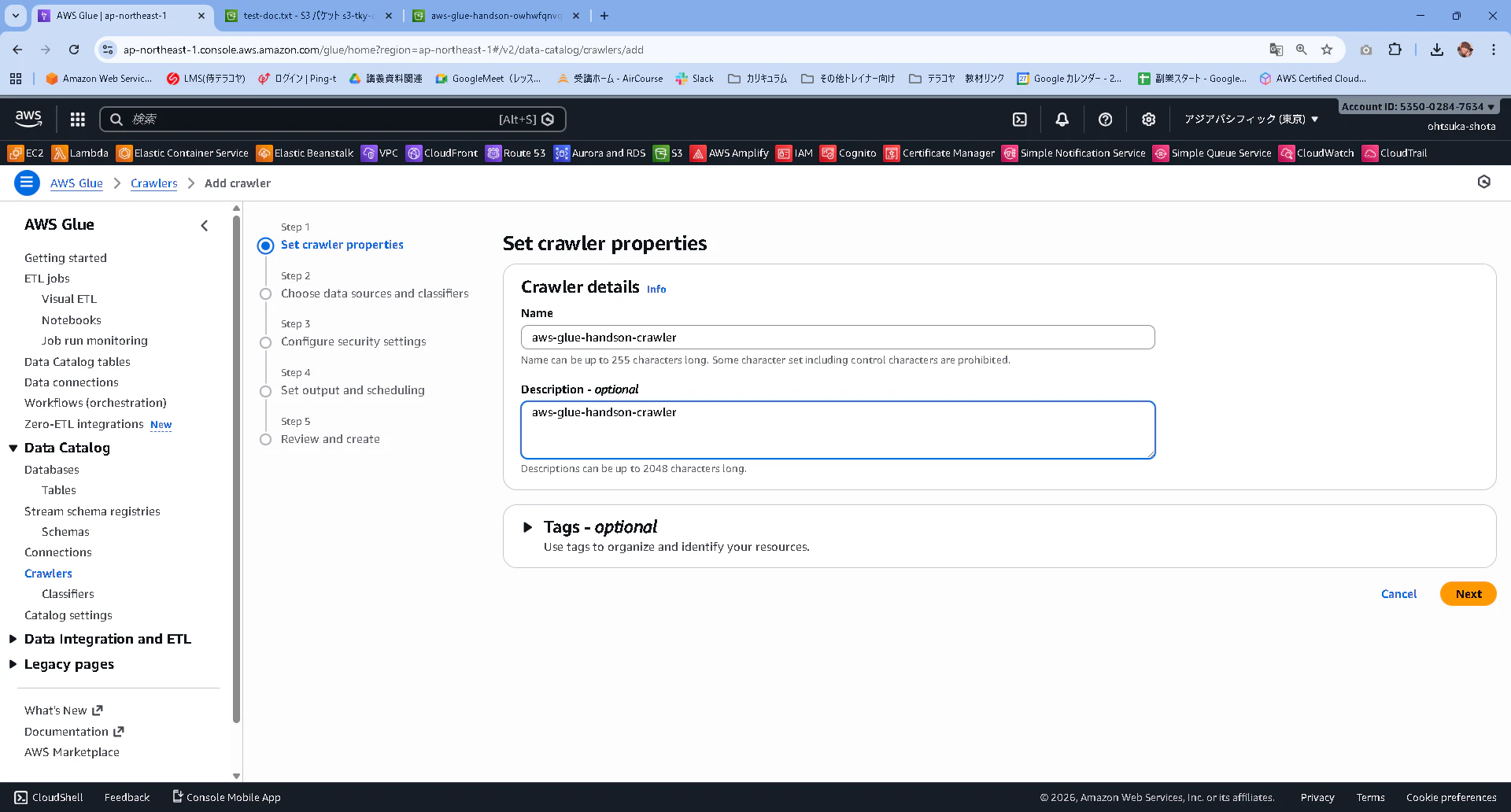
次のようなページが表示されます。
既にData Catalogがある場合はYesを選択すればよさそうですが、まだ作成していないので、Not yetを選択している状態でAdd a data sourceを選択します。
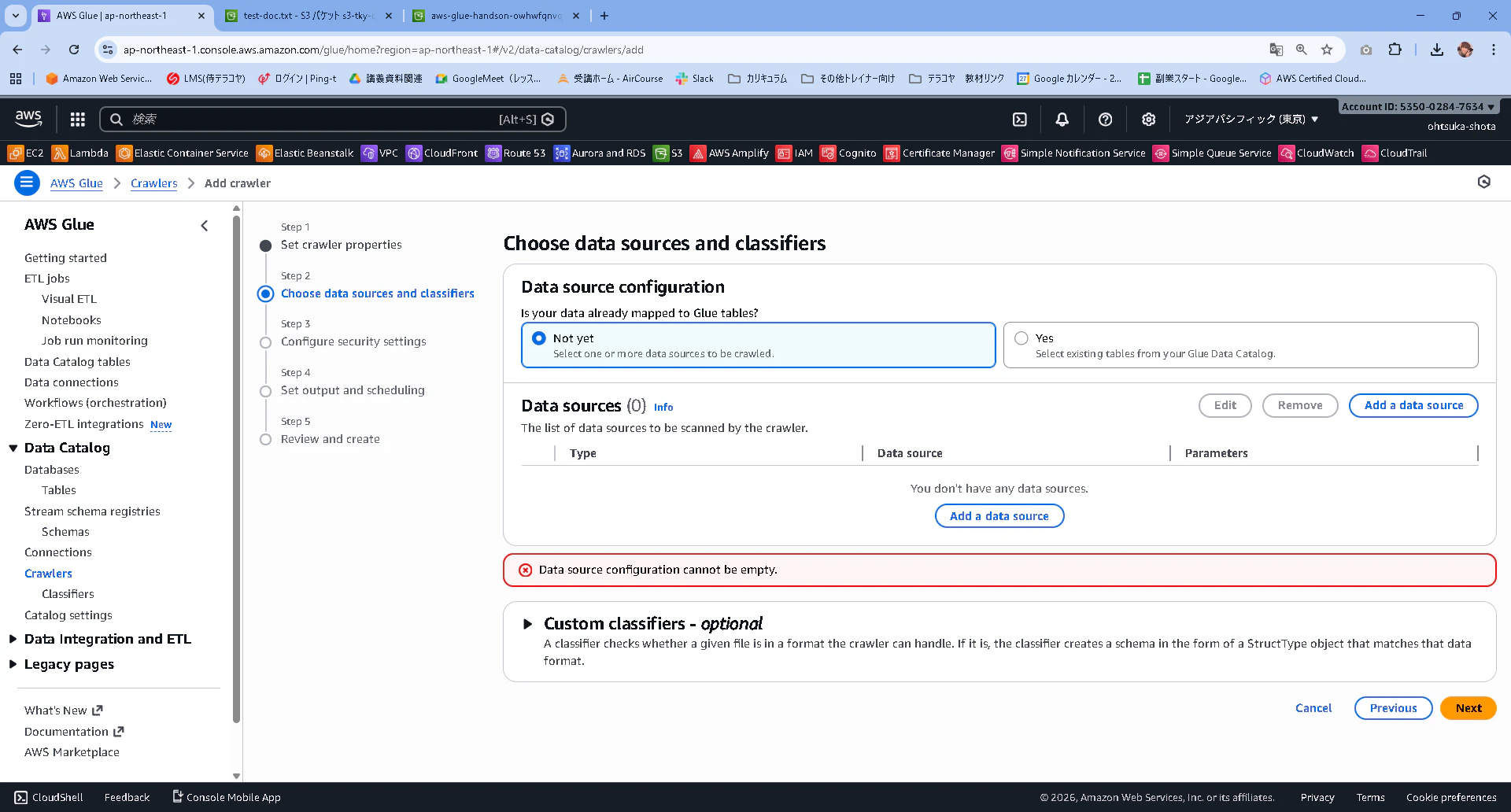
Data SourceはS3を選択。
S3 Pathは私の場合s3://aws-glue-handson-owhwfqnvqeo/inputとして、Addを押下します。
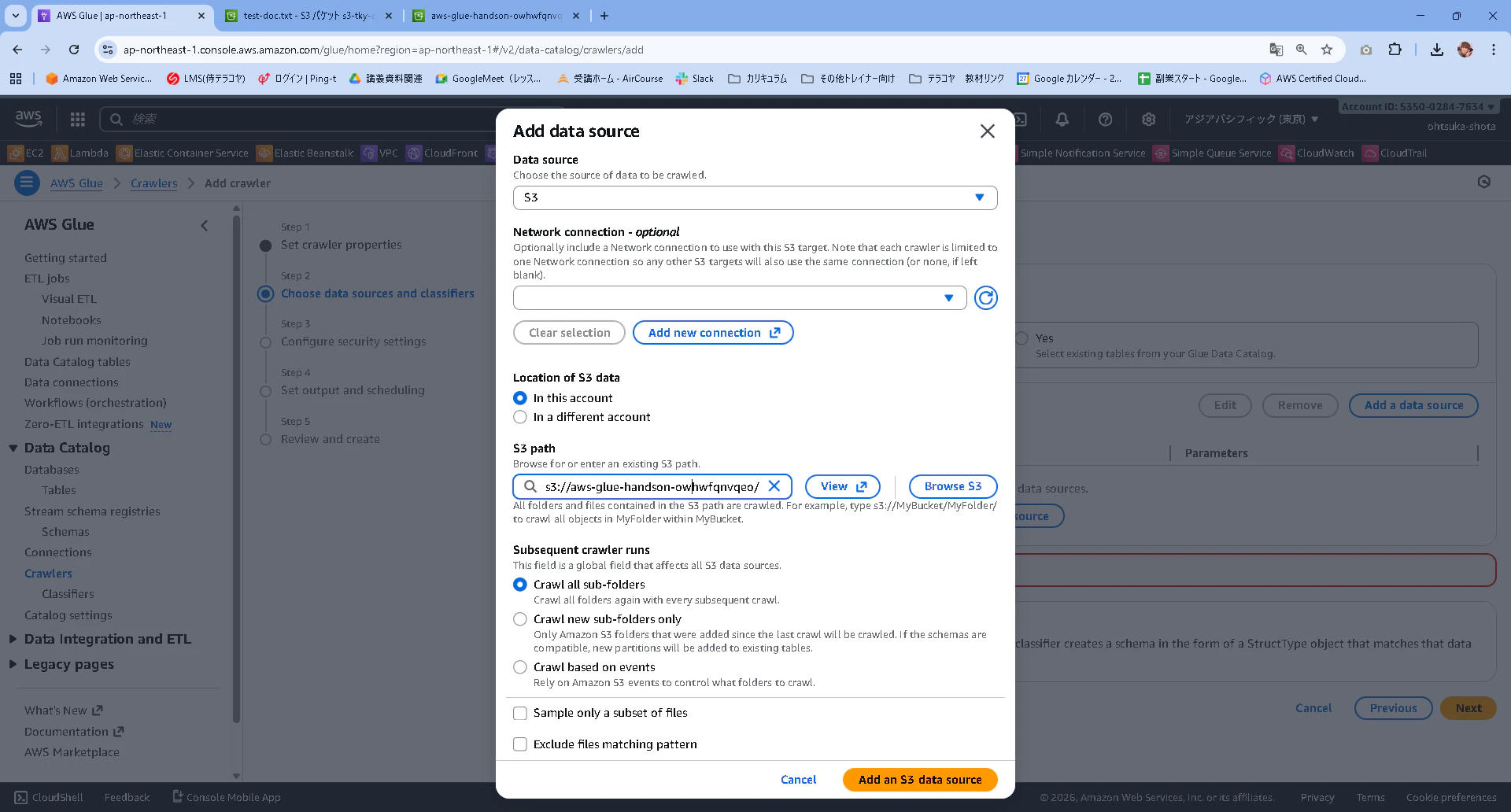
Data sourcesにS3が表示されていることを確認して、次に進みます。
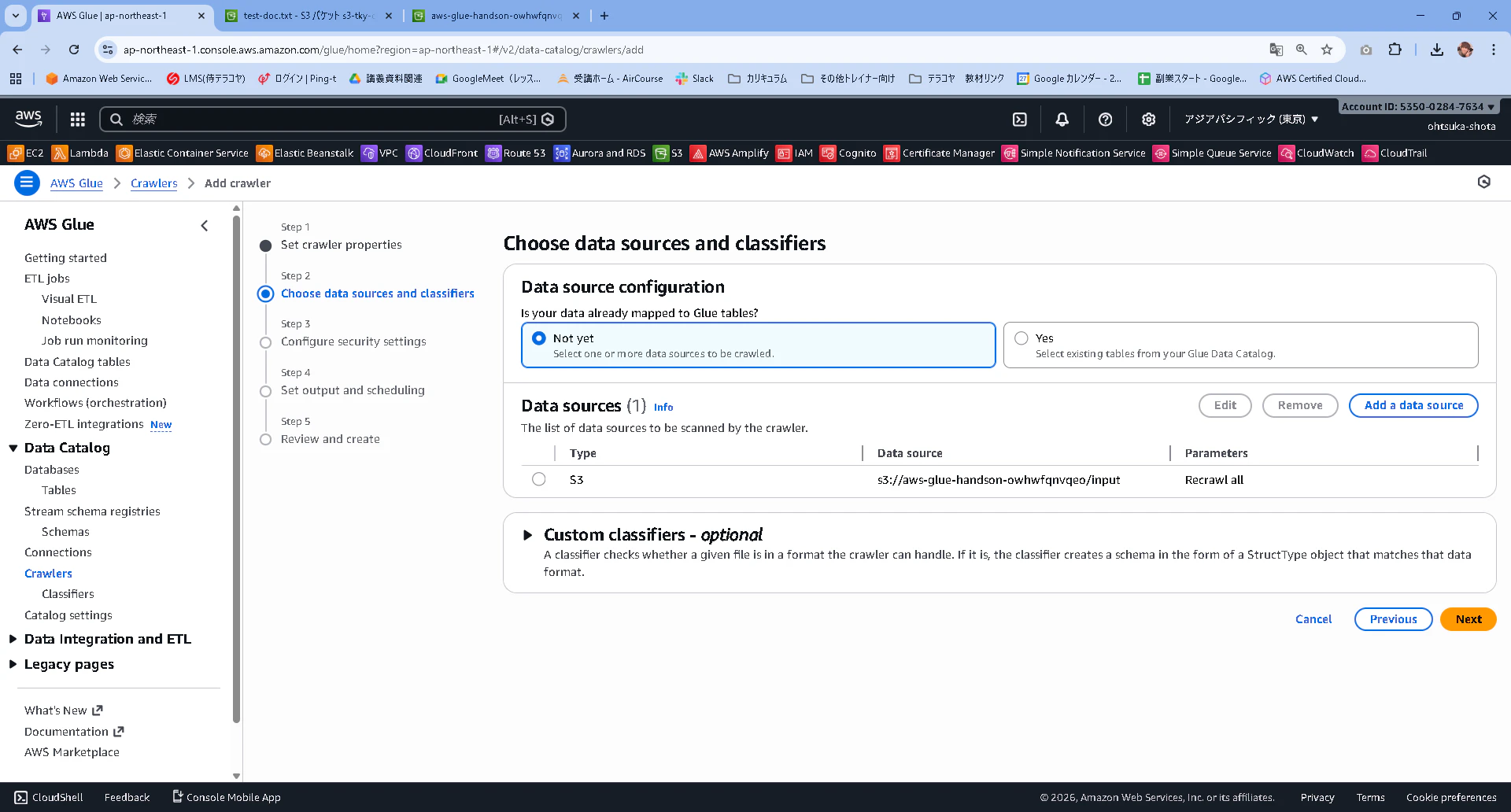
IAMロールについての画面が表示されます。何も作成していない場合はCreate new IAM roleを押下して作成します。
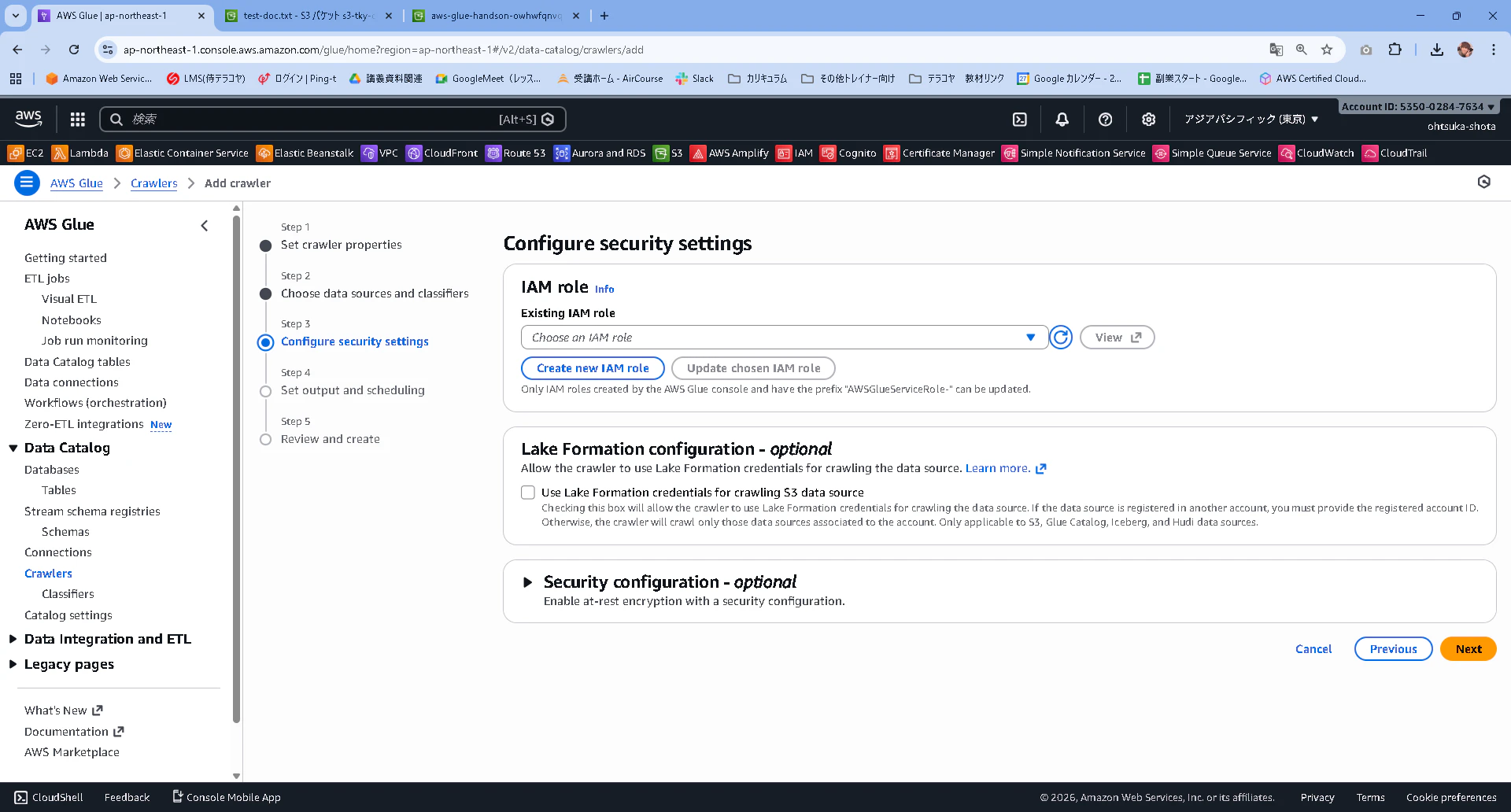
AWSGlueServiceRole-handsonという名前でroleを作成しようと思います。
IAM roleが設定されていることを確認して次に進みます。
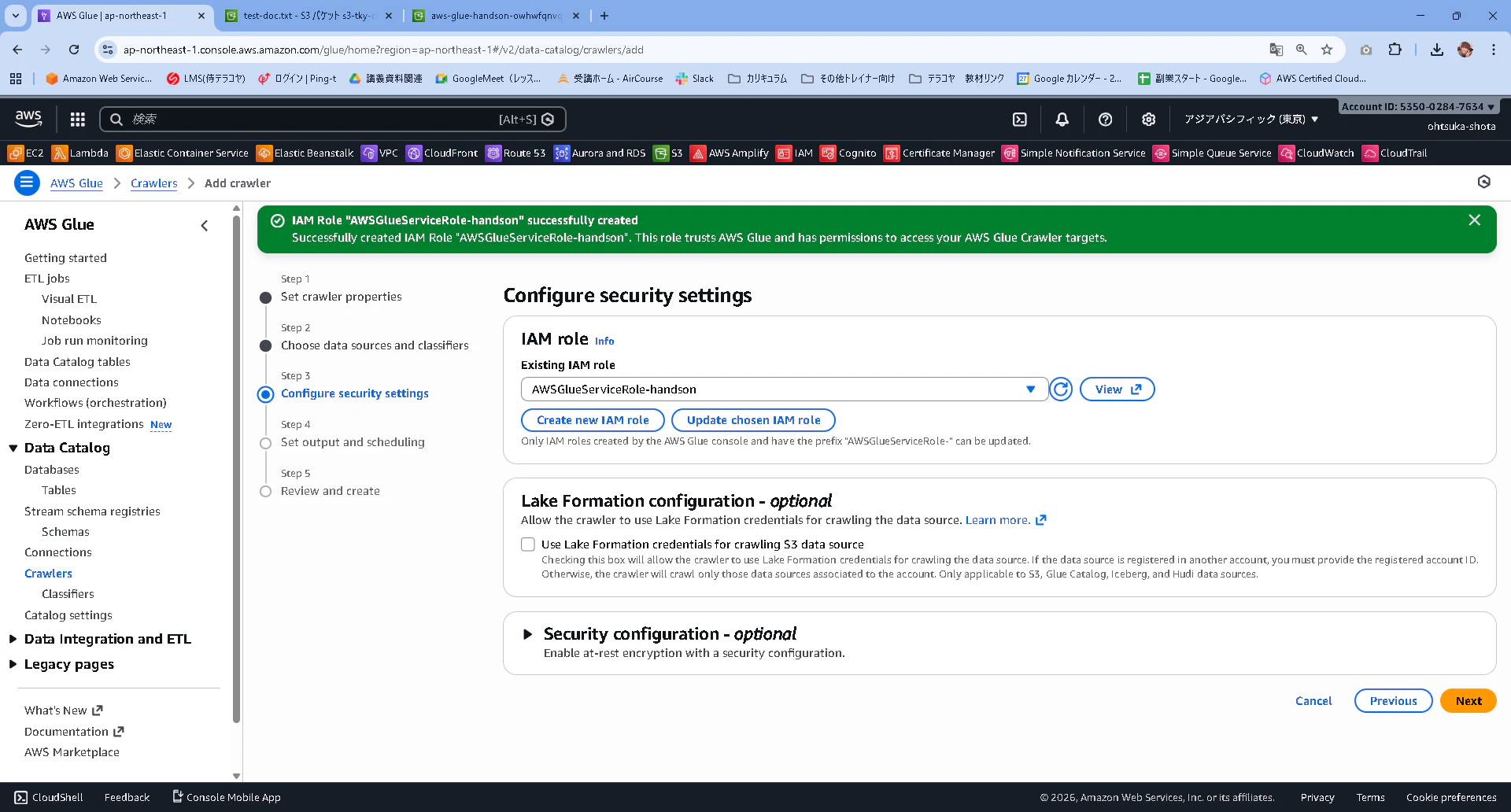
Target DatabaseではAddを押下します。
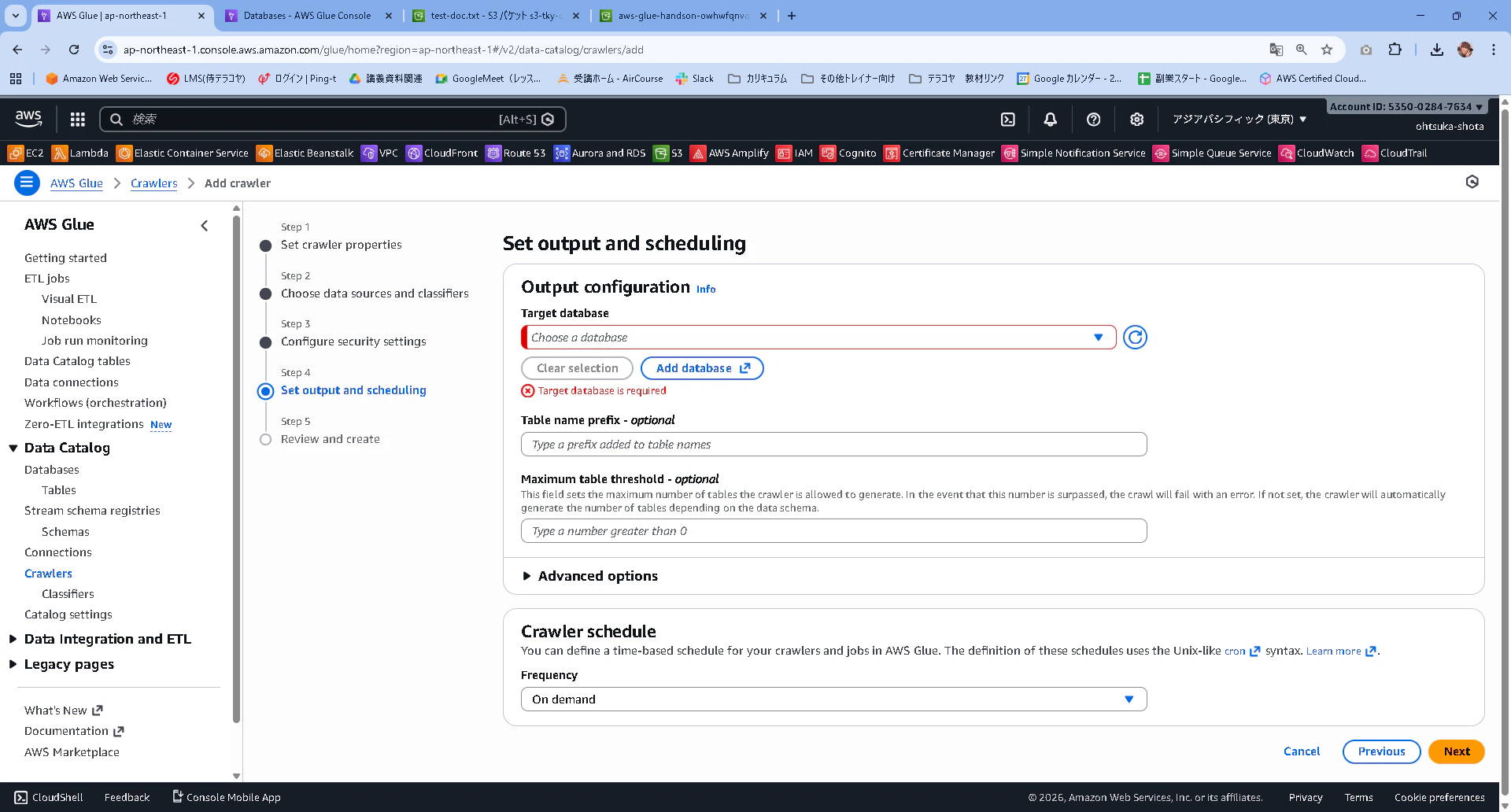
Glue Data CatalogのTableのページが別タブで開きます。
aws-glue-handson-databaseという名前でdatabaseを作成します。
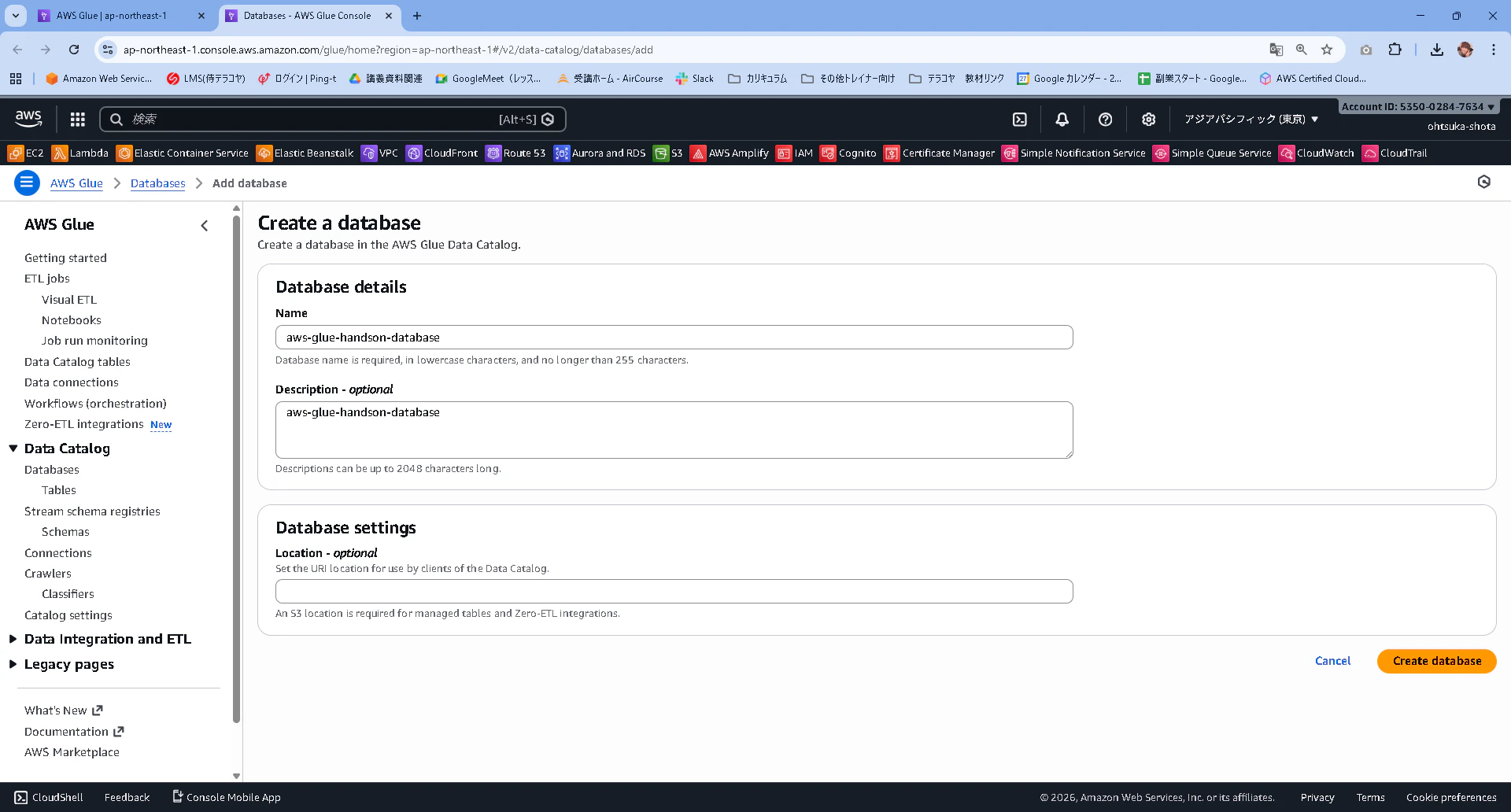
作成出来たことを確認します。
Crawlerの画面に戻り、先ほど作成したdatabaseを選択します。
スケジュールについてはon demandを選択しておきます。
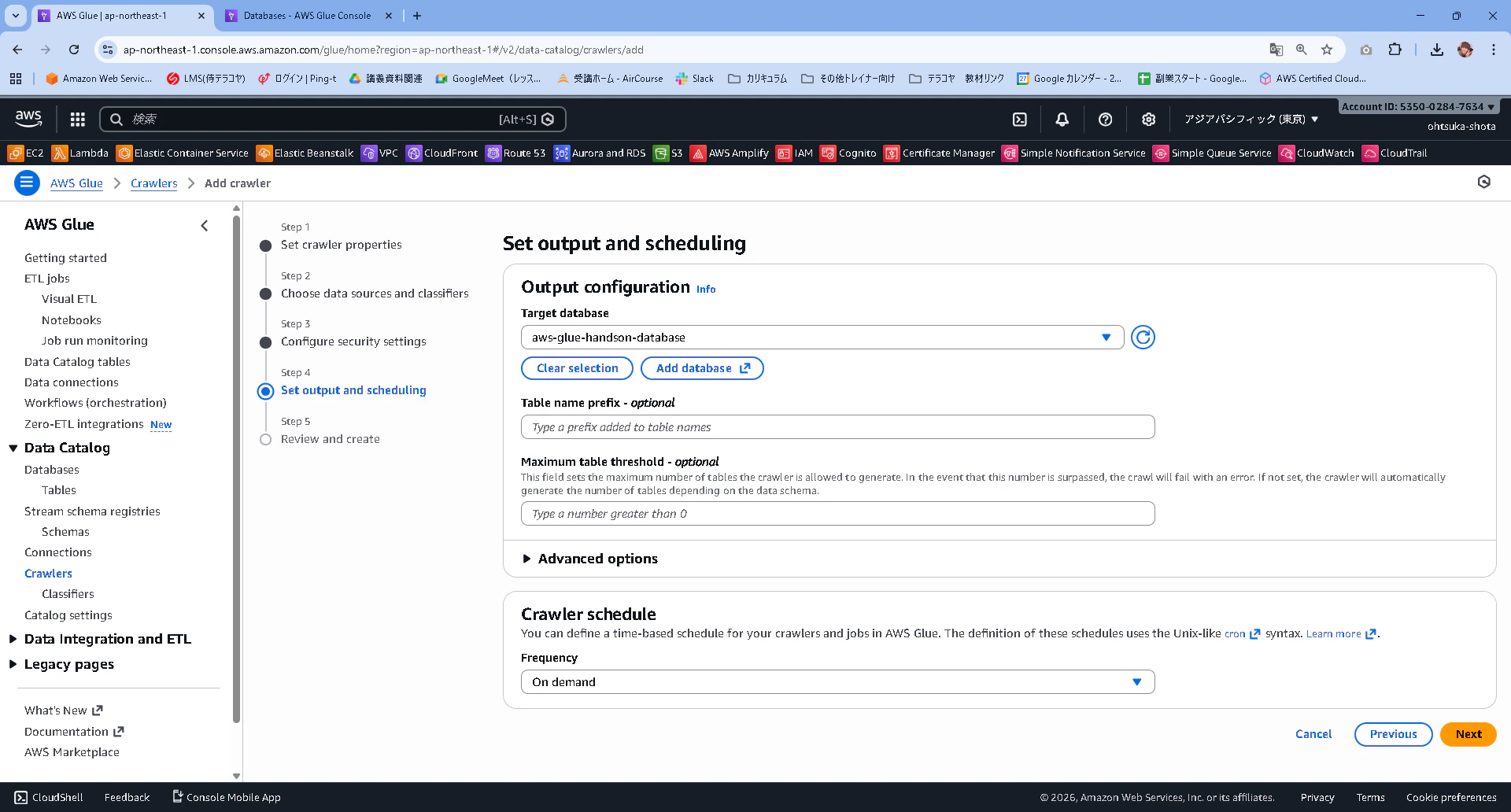
設定内容を確認して、作成します。
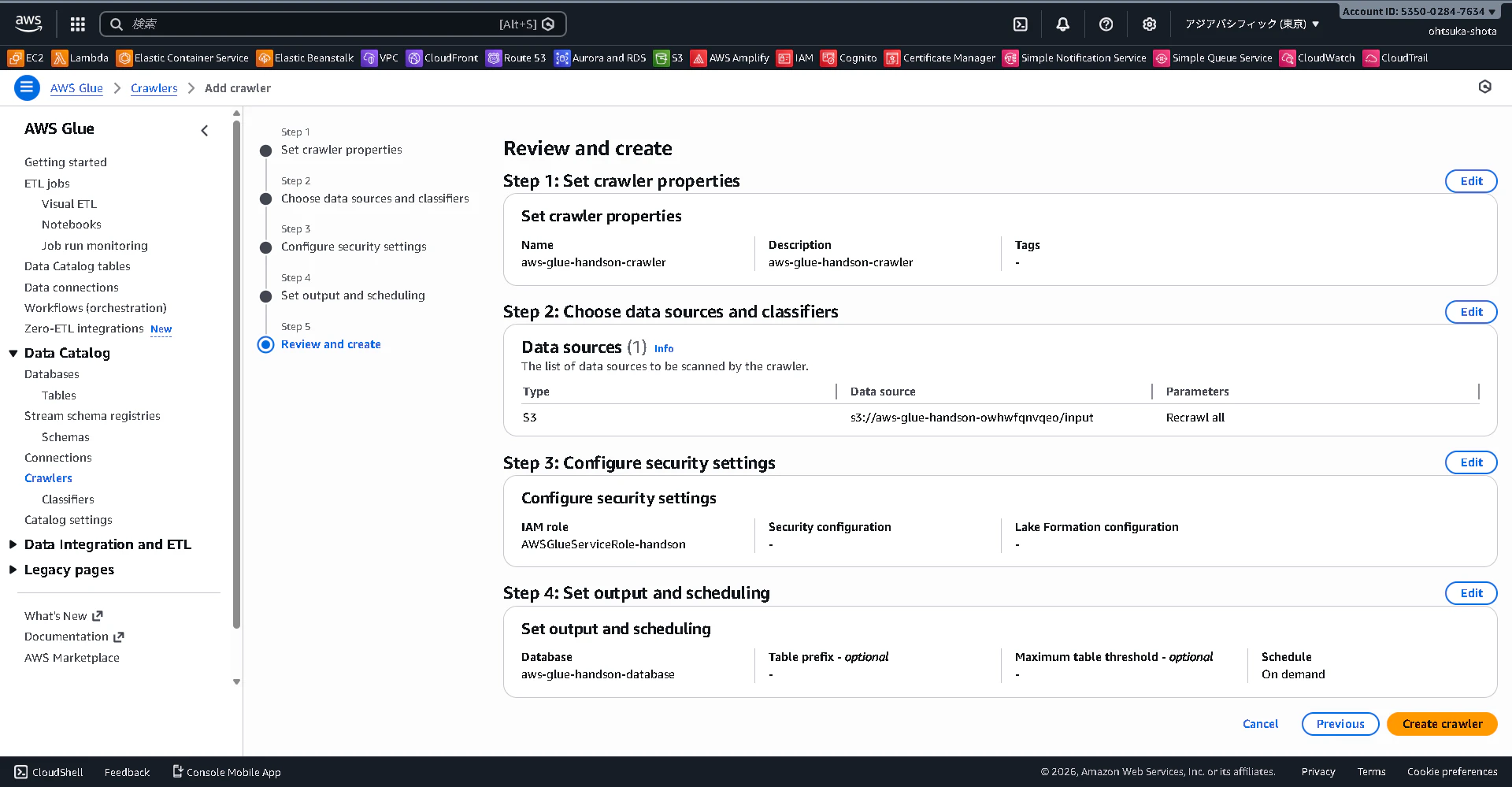
作成出来ました。StatusがReadyとなっていればOKです。
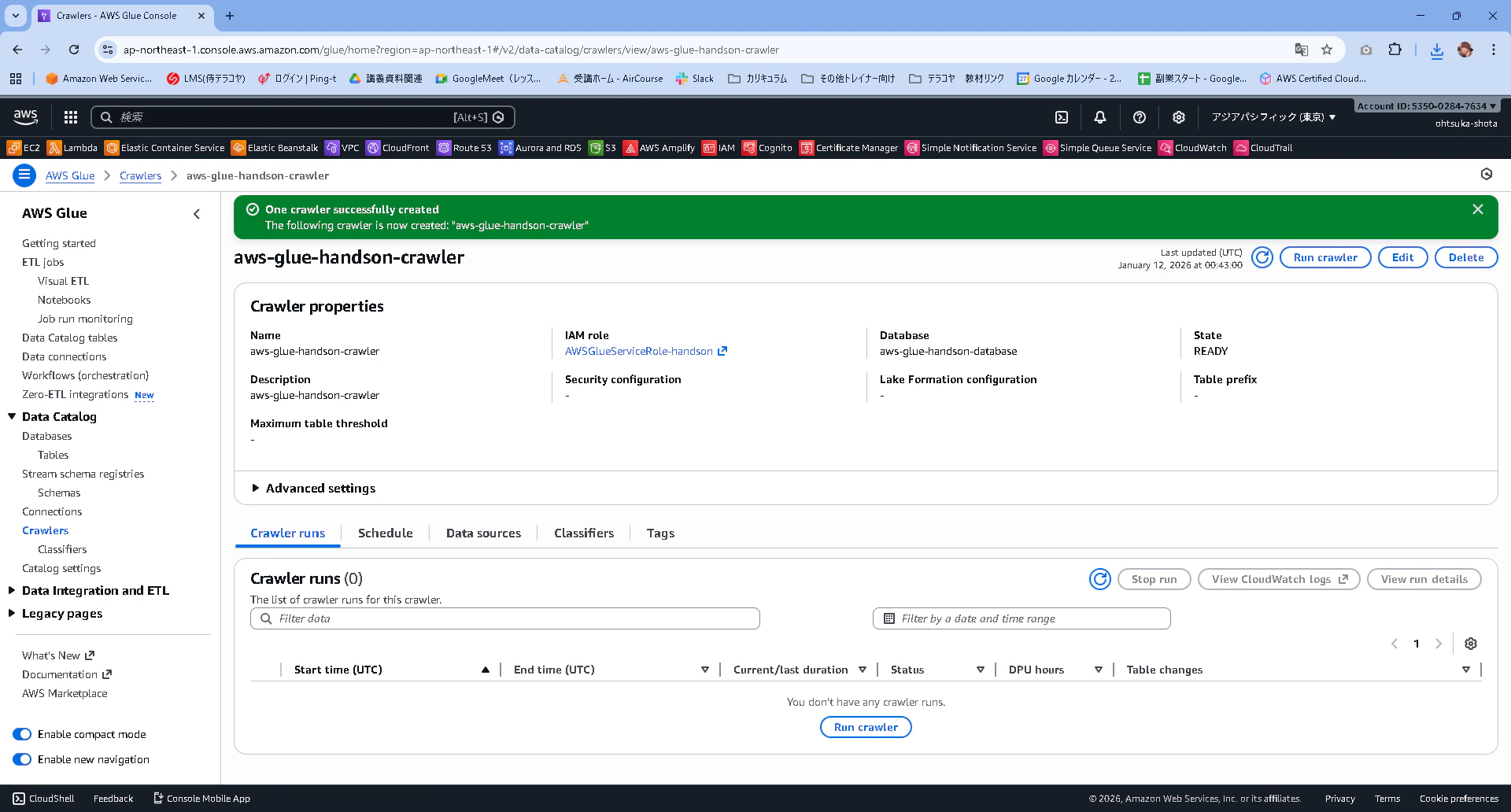
Data Sourceタブを確認すると先ほど設定したS3が紐づけられていると思います。
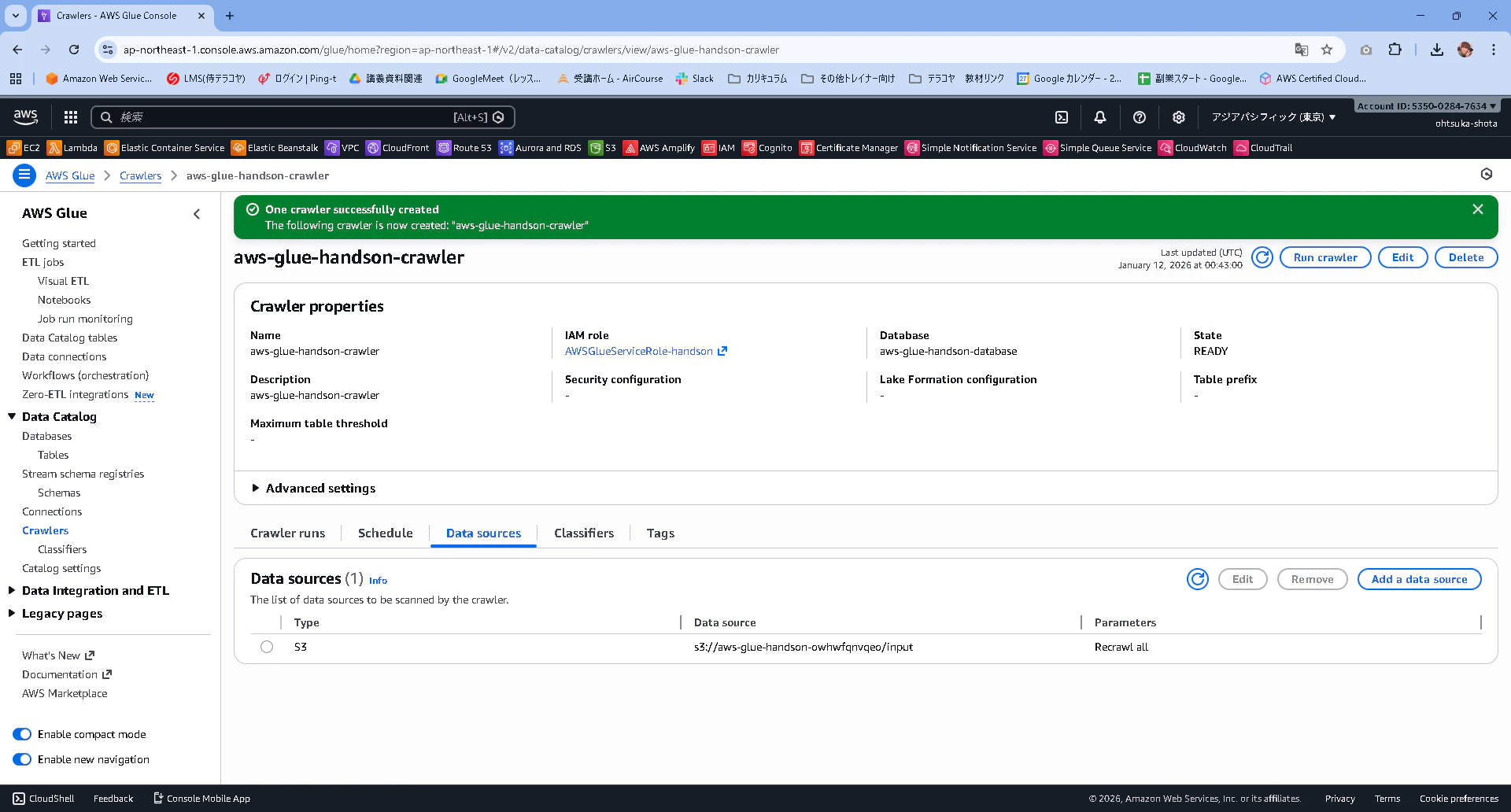
画面右上にあるRun Crawlerを押下します。
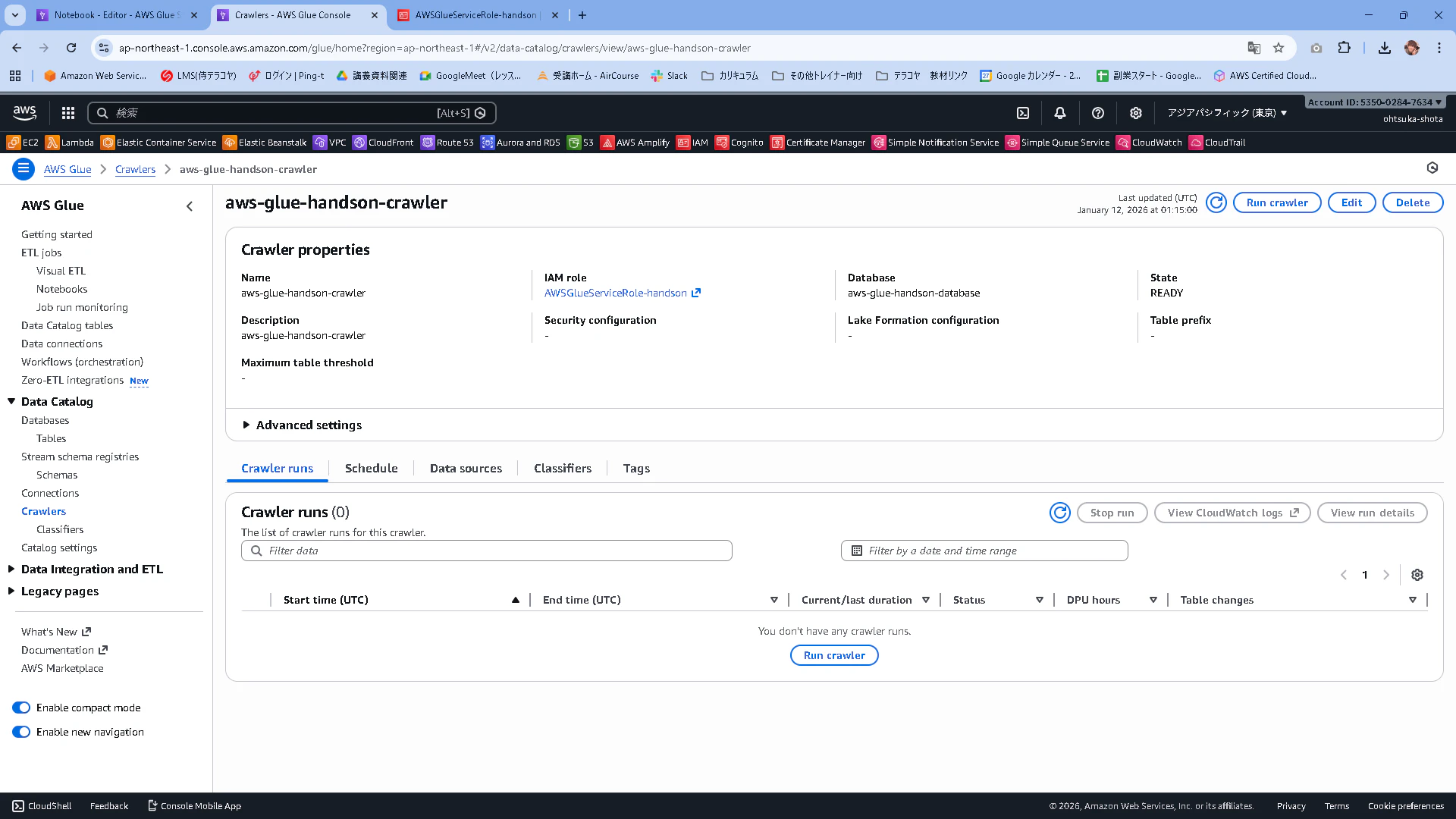
実行できたことを確認します。Crawler runsのタブでStatusがRunningになることを確認します。
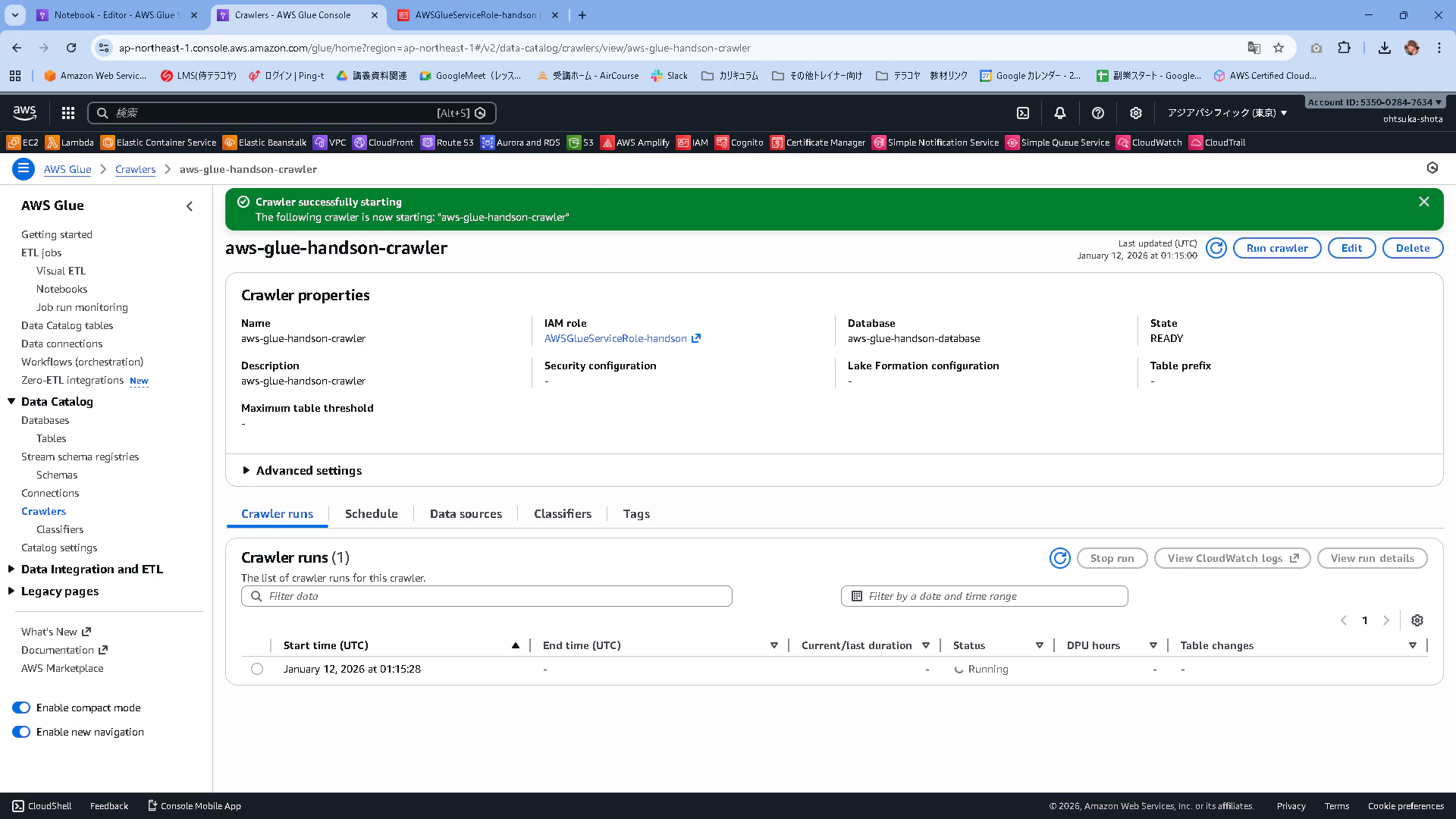
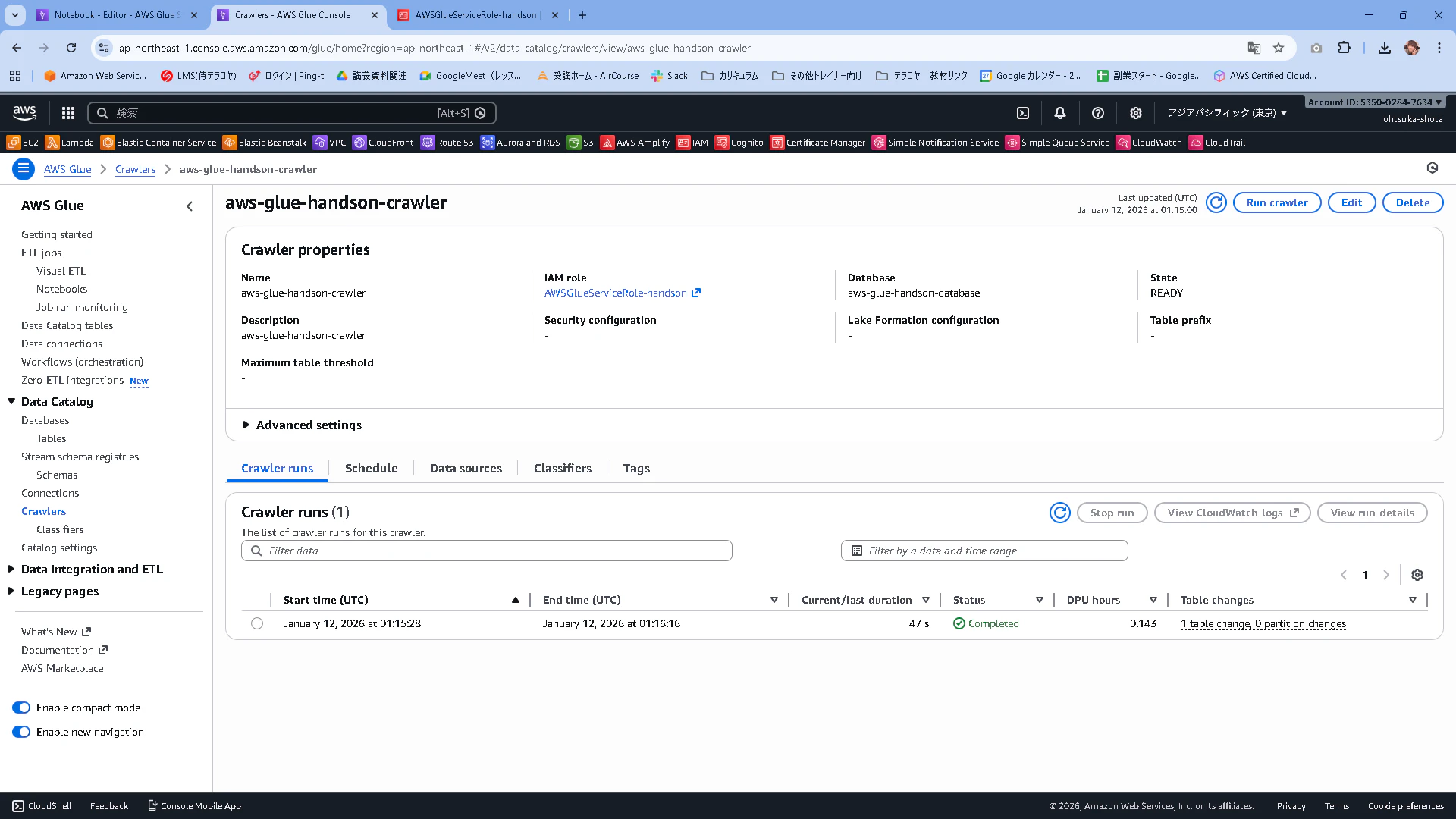
正常終了したことを確認します。Table Changeのところに1 table change, 0 partition changesと記載されていることを確認します。
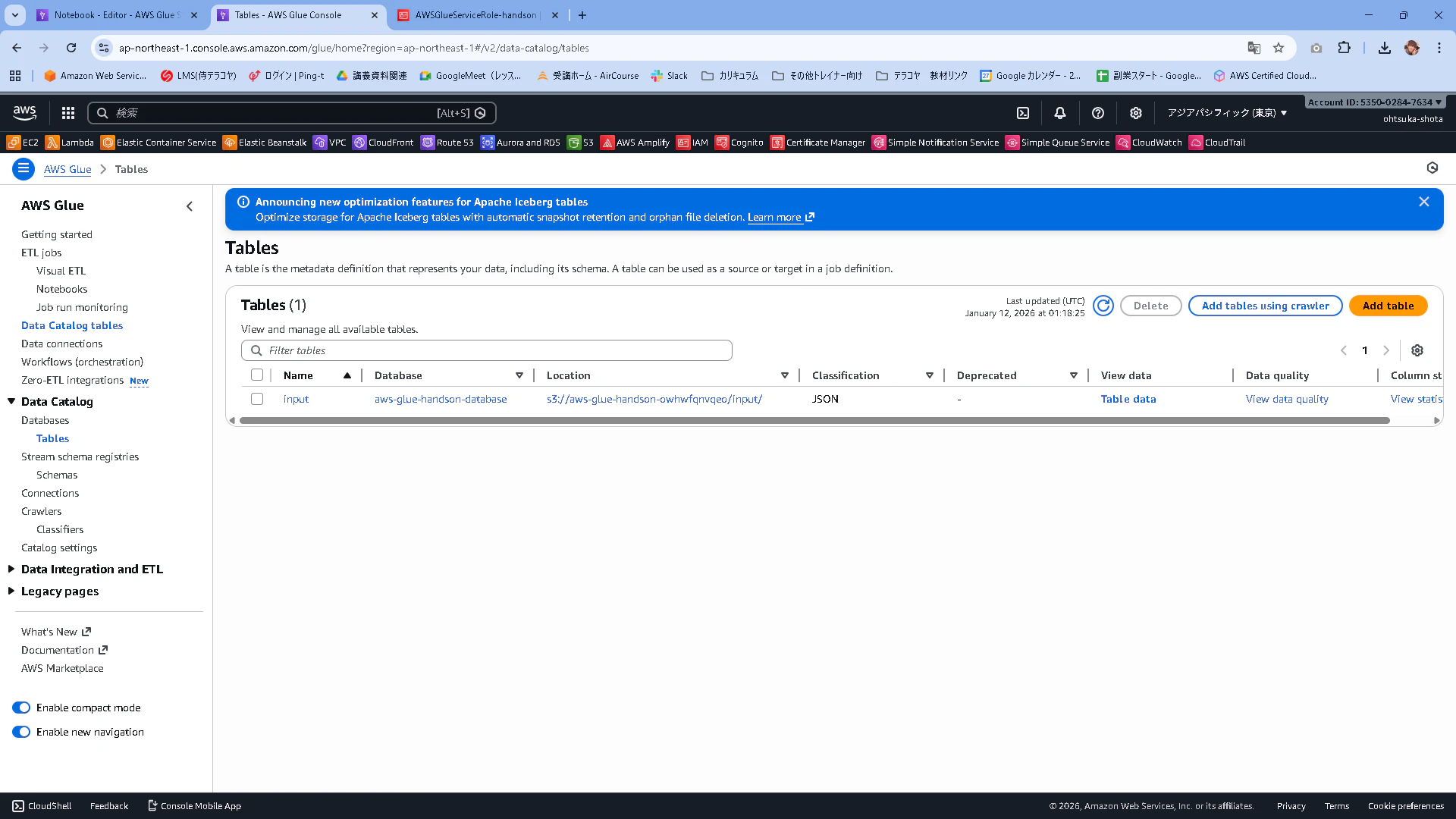
DatabaseのTableを確認すると、inputという名前のデータベーステーブルが、aws-glue-handson-databaseに作成されていることがわかります。LocationはTableを作成するために使った生データがどこにあるかを記載しています。
Glue Jobを準備してETLをしてみる
次にETLの準備をしていきます。
今回NoteBookを使って、ETLの為のコードを作っていきたいのですが、IAM roleの権限が不足しているので追加します。インラインポリシーで作成します。
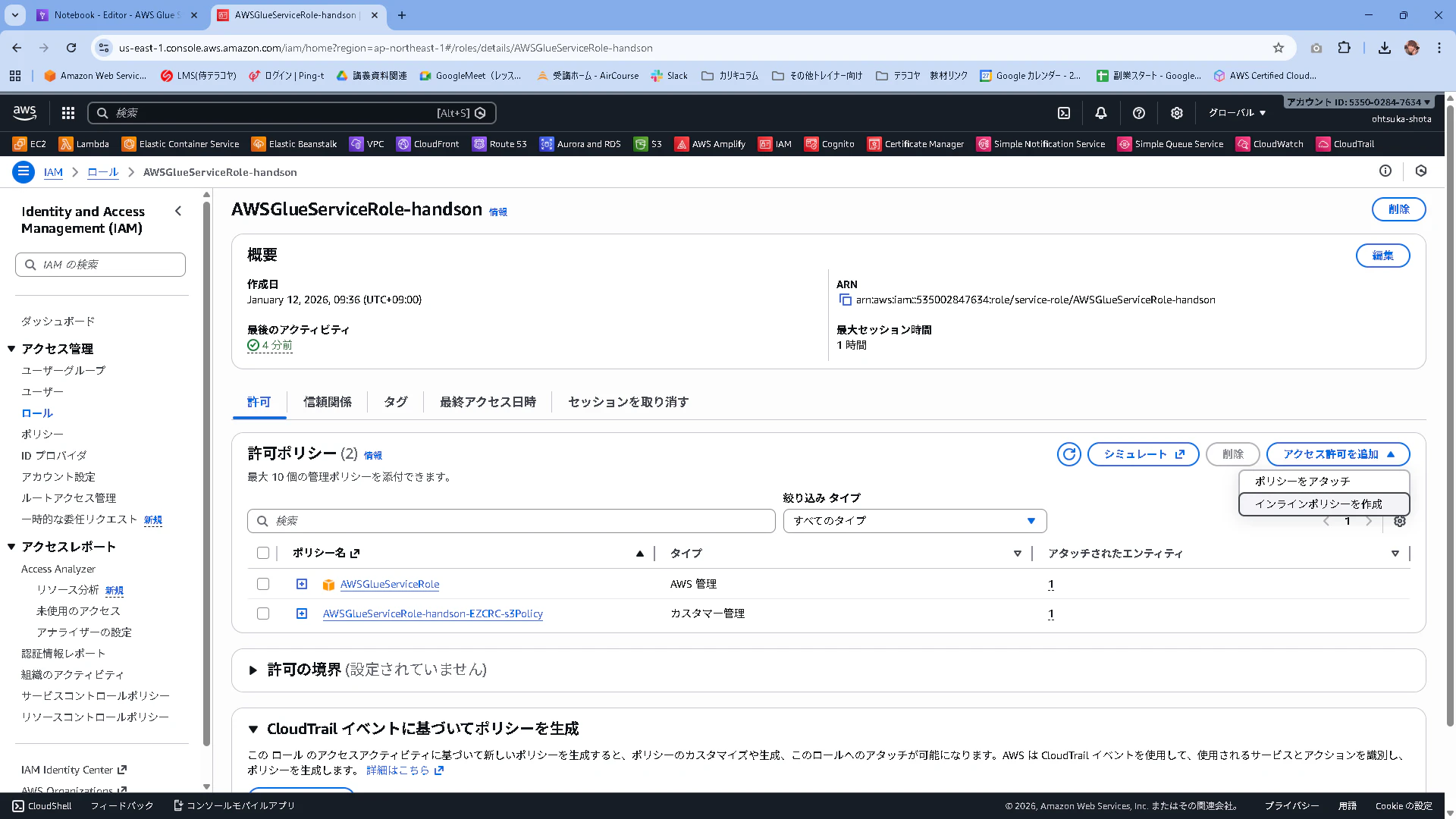
以下のJSONを貼り付けます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::535002847634:role/service-role/AWSGlueServiceRole-handson"
}
]
}
名前はGlueNotebookPassRolePolicyとして作成・適用しました。
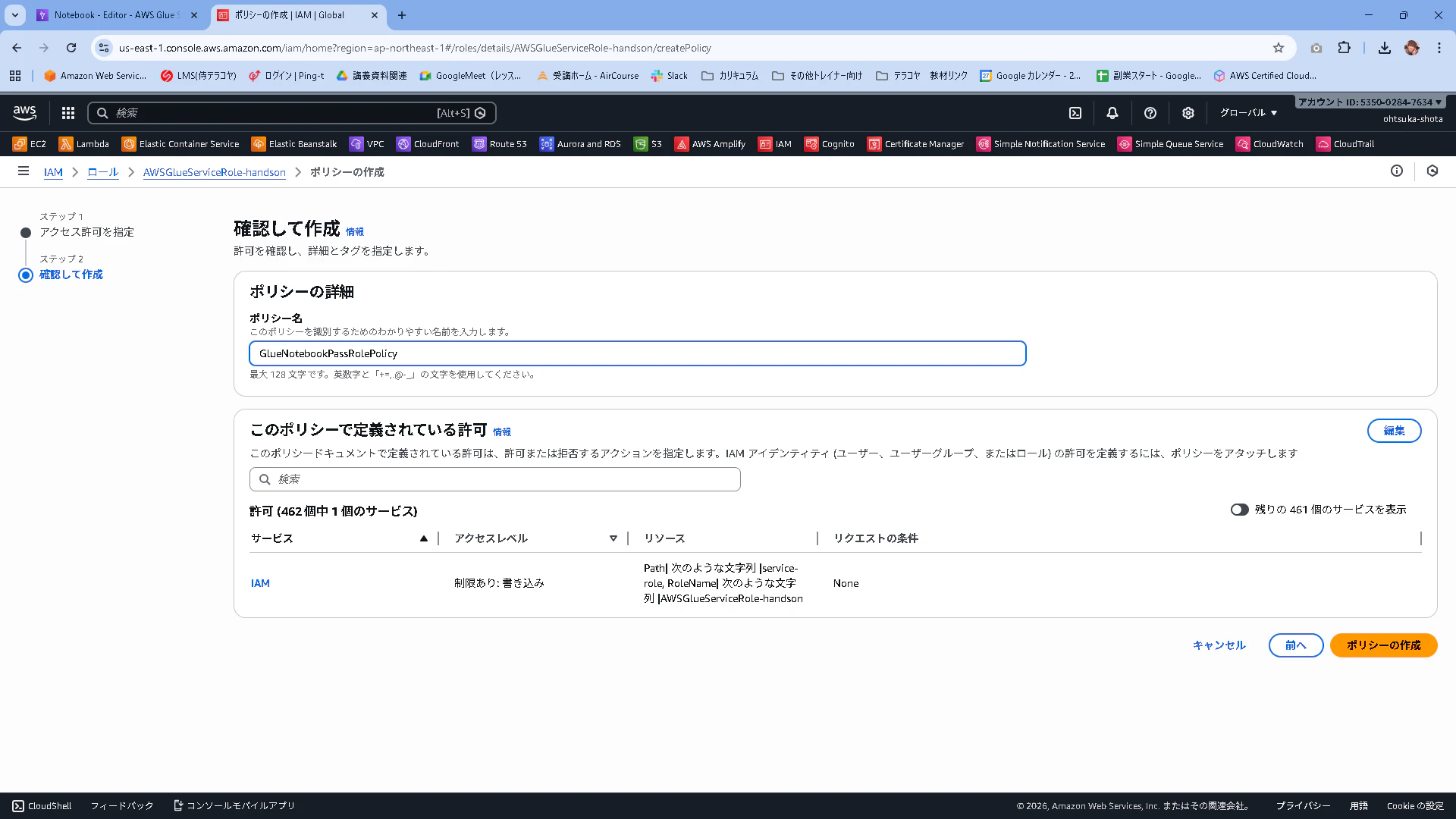
Glueの画面に戻ります。画面左のETL jobsを選択して、ETLの為のコードを書いていきます。
どれを選択しても問題ないと思いますが今回はNotebookを選択します。
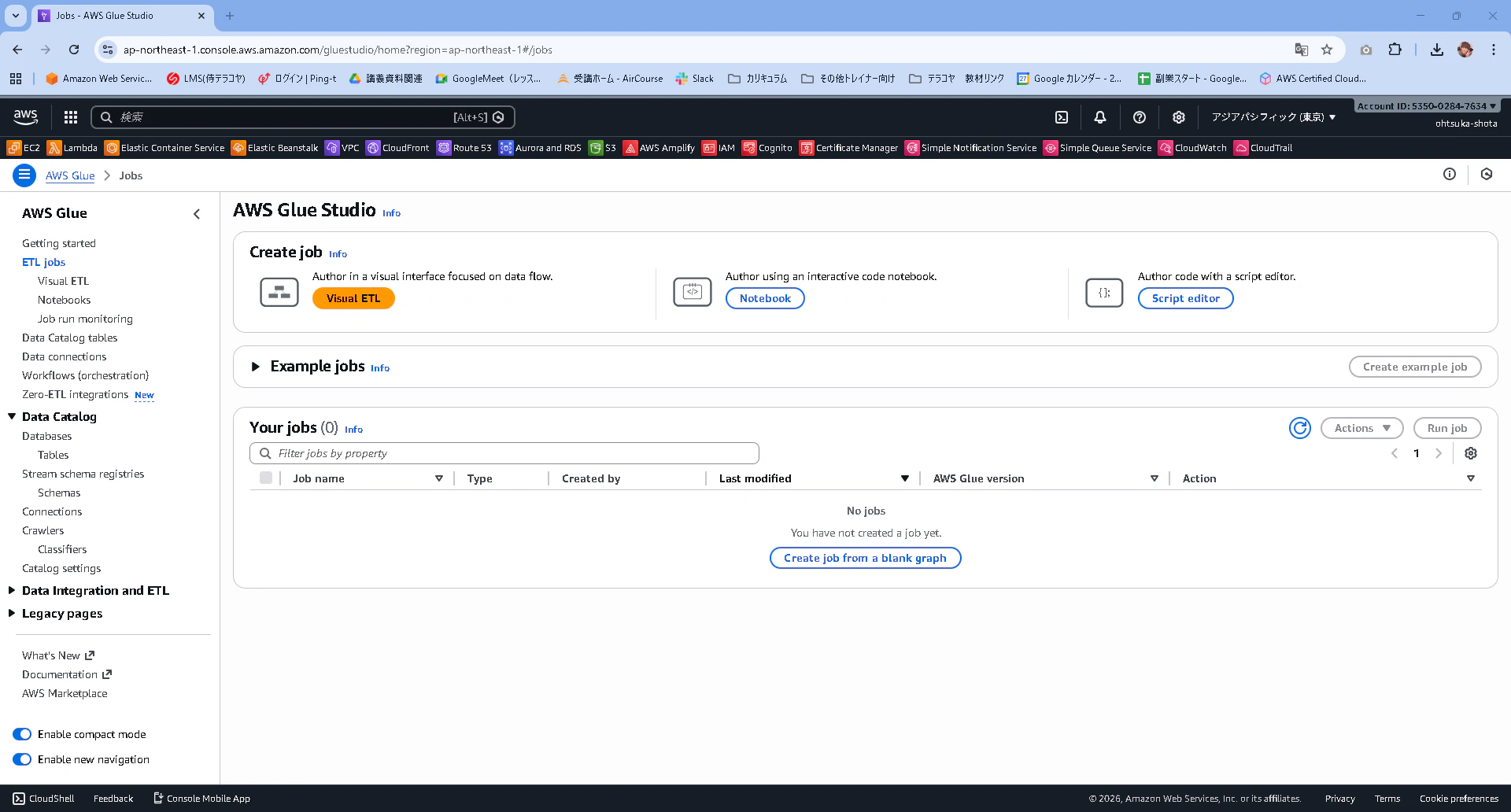
OptionsはStart fresh。roleは先ほど作成したもので問題ありません。
この状態で作成していきます。
以下のようなページが開きます。Jupiter Notebookの画面が開きます。
Notebookが開いている間は課金が発生するようです。1時間あたり0.88USDくらいみたいです。結構かかりますね。。。
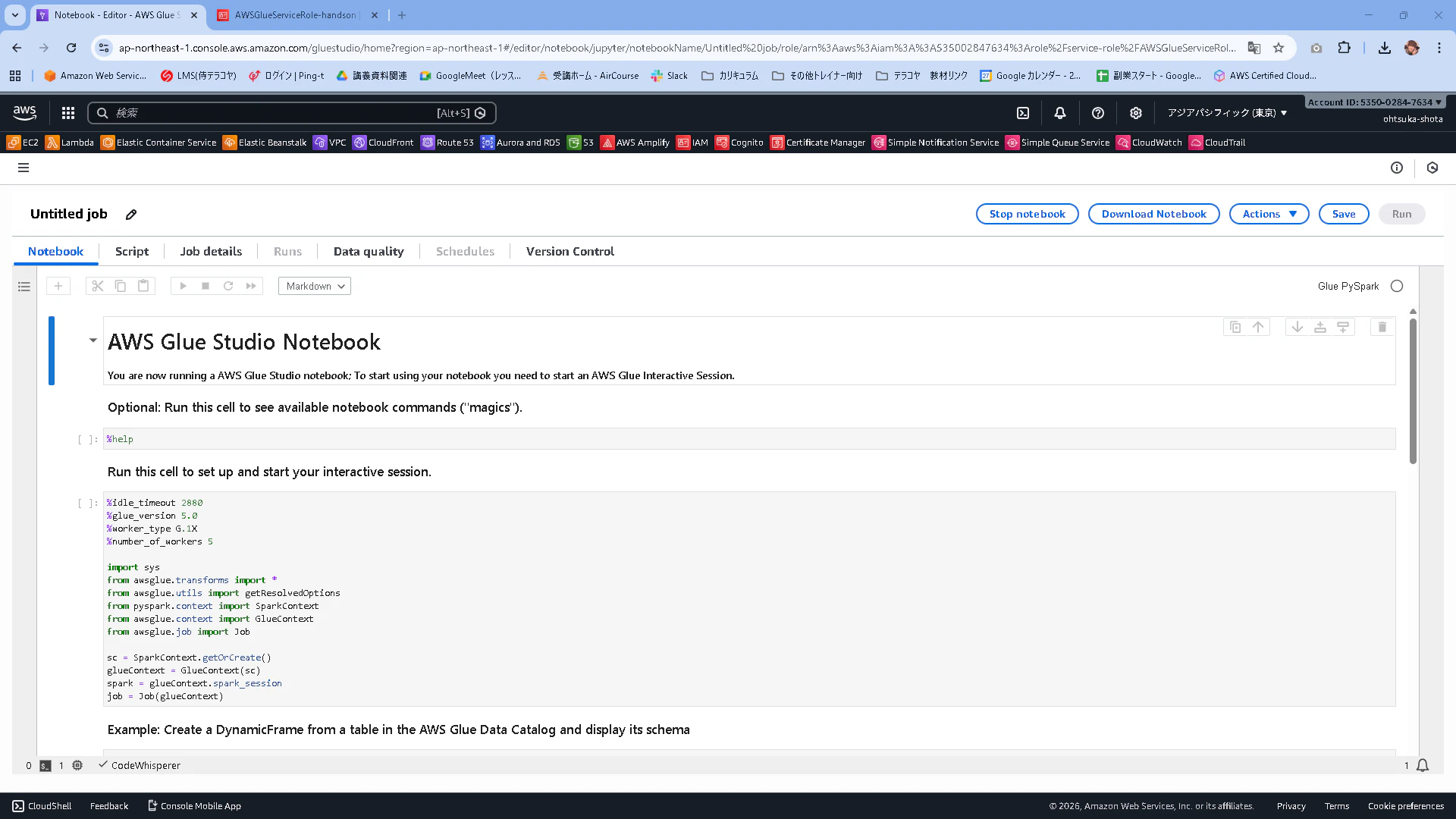
デフォルトで書かれている内容を全て削除して以下のコードを貼り付けます。
%idle_timeout 2880
%glue_version 4.0
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init("notebook_job", args={})
# データを読み込む
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "aws-glue-handson-database", # 作成したGlueのDatabase
table_name = "input" # GlueのDatabaseにCrawlerで作成したTable
)
# データを画面に表示してみる
datasource0.printSchema() # 構造を表示
datasource0.show(5) # 実際のデータを5行表示
# 必要な列だけ選ぶ
transformed_dyf = SelectFields.apply(
frame = datasource0,
paths = ["family_name", "given_name", "birth_date", "gender"]
)
# 保存する
glueContext.write_dynamic_frame.from_options(
frame = transformed_dyf,
connection_type = "s3",
connection_options = {"path": "s3://aws-glue-handson-owhwfqnvqeo/output/"}, # S3バケット名
format = "parquet"
)
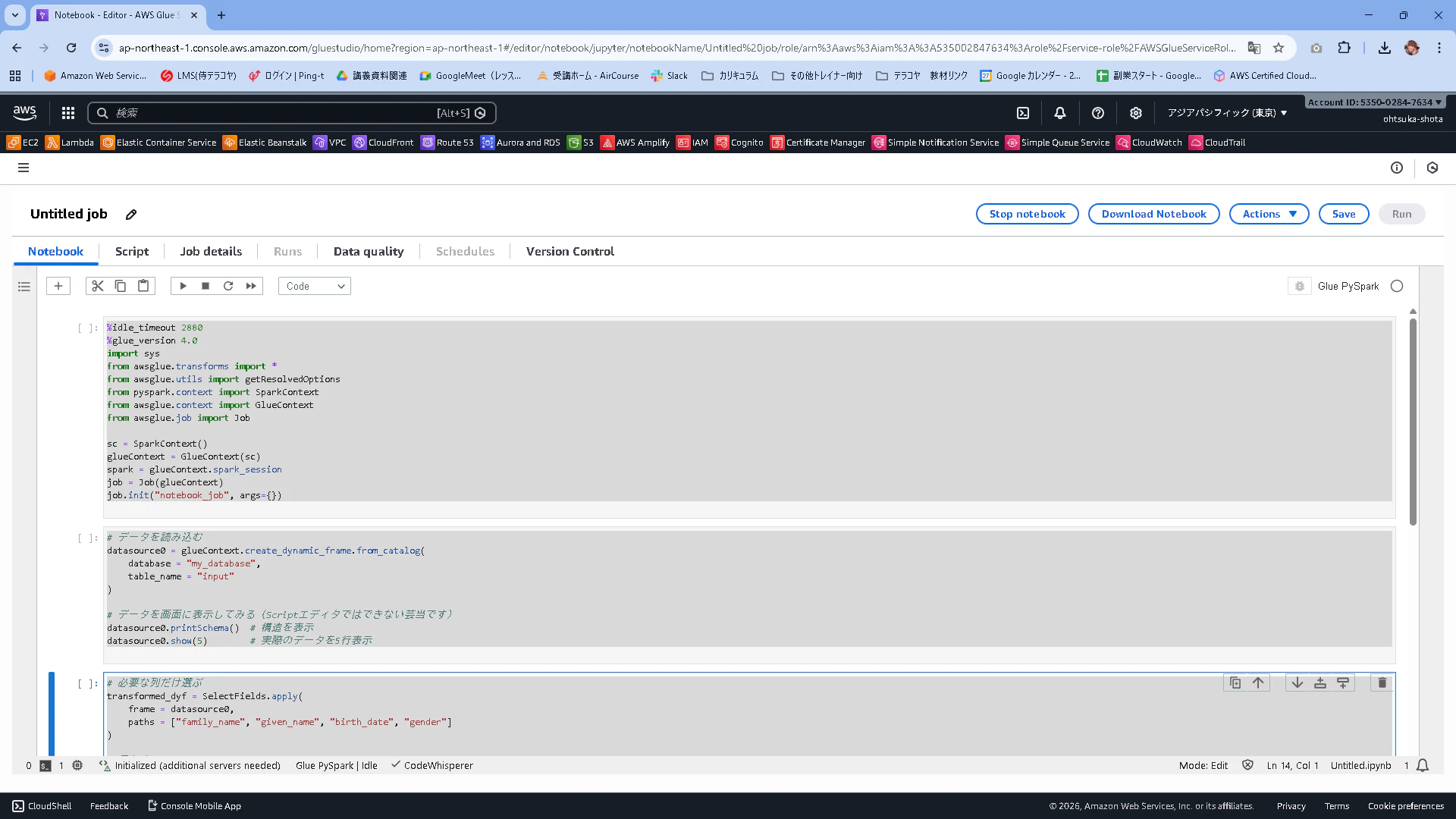
入力しているコードを上から順番に実行します。

実行した後の画面が以下のようになります。
3つ目を実行した後は何も出てきませんが、問題ありません。

データのスキーマ(読み込んだデータの「構造(設計図)」)が以下のようになっていることがわかりますね。
root
|-- family_name: string
|-- name: string
|-- links: array
| |-- element: struct
| | |-- note: string
| | |-- url: string
|-- gender: string
|-- image: string
|-- identifiers: array
| |-- element: struct
| | |-- scheme: string
| | |-- identifier: string
|-- other_names: array
| |-- element: struct
| | |-- lang: string
| | |-- note: string
| | |-- name: string
|-- sort_name: string
|-- images: array
| |-- element: struct
| | |-- url: string
|-- given_name: string
|-- birth_date: string
|-- id: string
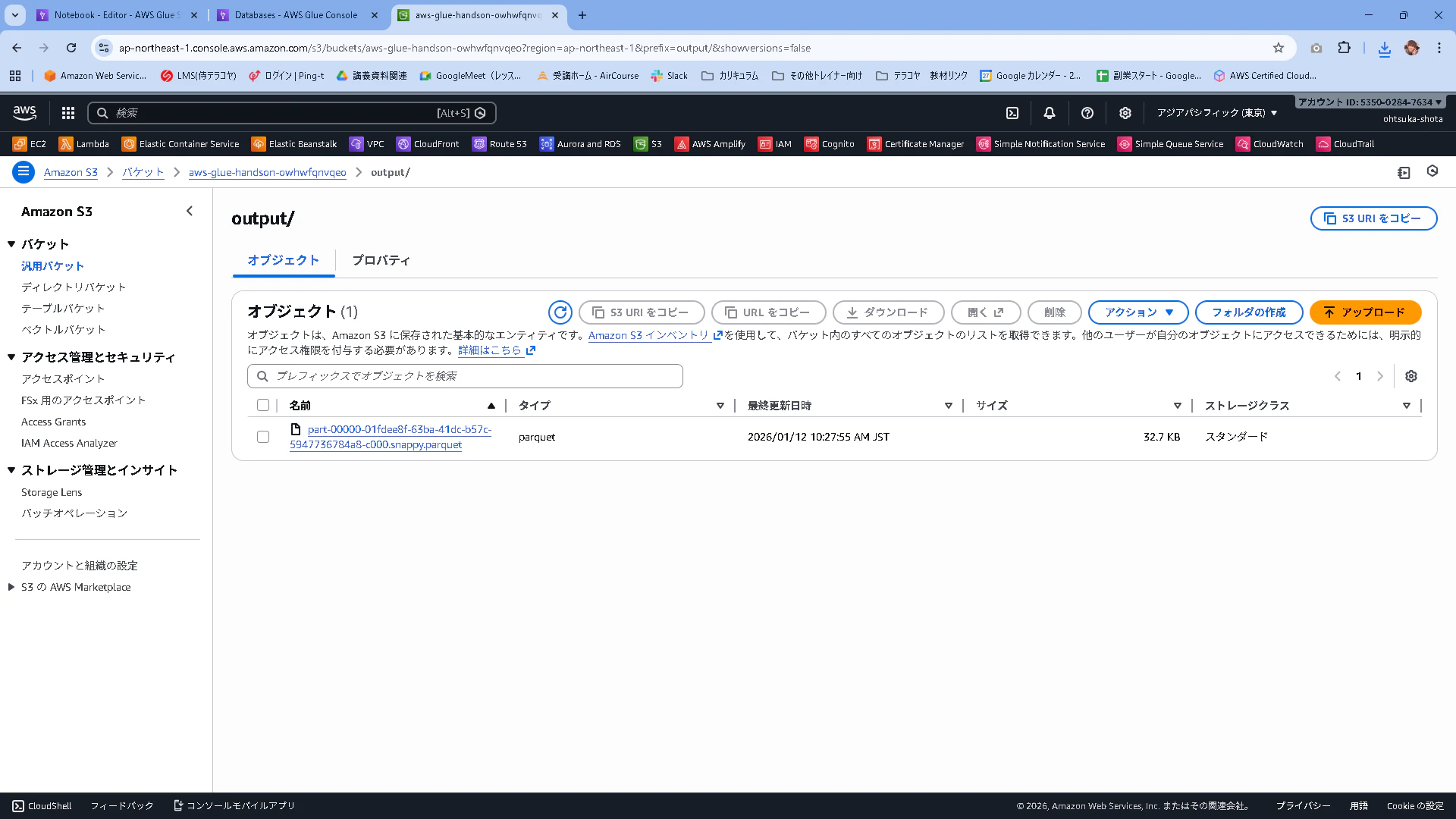
S3を見てみます。.parquetデータがありますね。
Notebookに戻って以下のコードを追加して実行します。
# ---------------------------------------------------------
# データ書き込み & カタログ自動登録
# ---------------------------------------------------------
# 1. シンク(保存先)の設定
# getSinkを使うのがモダンな書き方です
sink = glueContext.getSink(
connection_type="s3",
# 保存先のS3パス(新しいフォルダに変えておきます)
path="s3://aws-glue-handson-owhwfqnvqeo/after_etl_table/",
enableUpdateCatalog=True, # 「カタログも更新する」スイッチ
updateBehavior="UPDATE_IN_DATABASE" # テーブルがなければ作る、あれば更新する
)
# 2. フォーマットと、登録したいテーブル名の指定
sink.setFormat("glueparquet") # Glue最適化されたParquet
sink.setCatalogInfo(
catalogDatabase="aws-glue-handson-database", # 既存のデータベース名
catalogTableName="after_etl_table" # ★ここに「作りたいテーブル名」を書く
)
# 3. 書き込み実行
sink.writeFrame(transformed_dyf)
print("保存とテーブル作成が完了しました!Athenaの確認をしましょう")
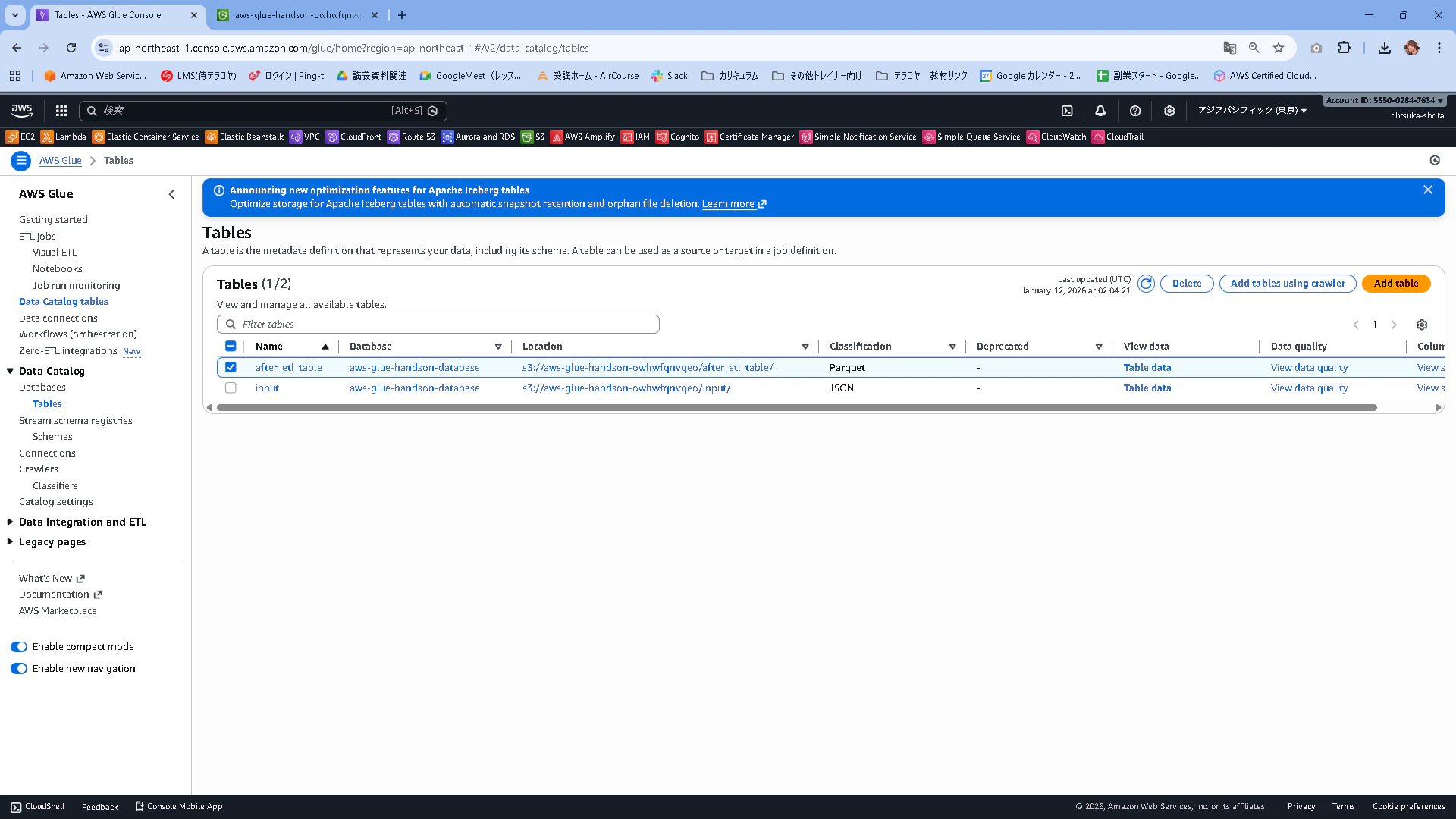
実行後、Glue Data Catalogを確認するとaws-glue-handson-databaseにTableが追加されていることがわかると思います。
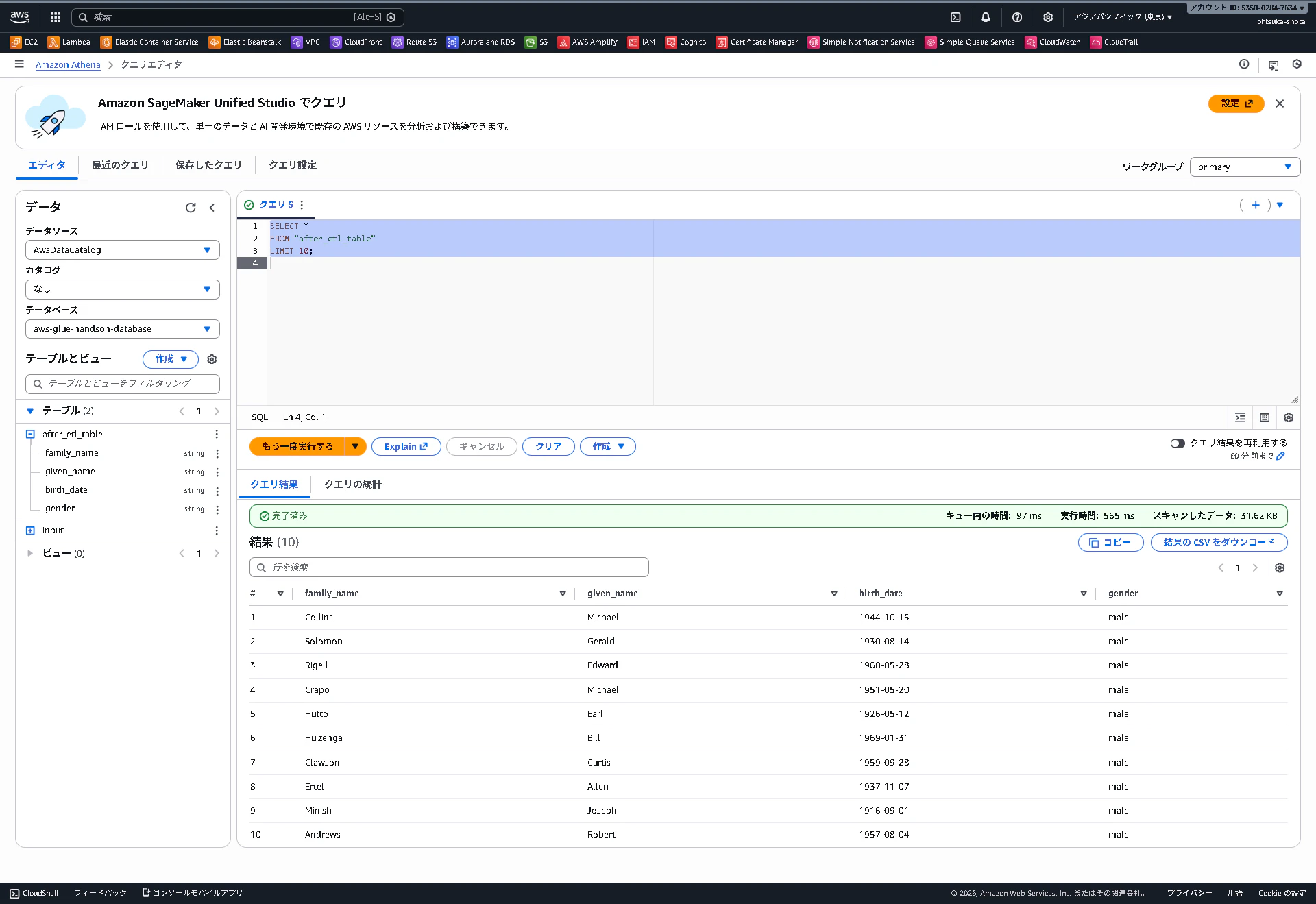
Athenaのクエリエディタを開きます。
データソースをAwsDataCatalogにして、データベースをaws-glue-handson-databaseとするとテーブルにafter_etl_tableが出来上がっていることがわかります。

ここまで実行出来たら、Notebookはstopしておきましょう。課金を回避するためです。
Notebook自体は保存したり、ダウンロードが出来るのでそれらもStopする前にやっておくといいでしょう。

Athenaで分析してみる
このNotebookでアウトプットされたものをAthenaで分析していきたいと思います。
改めてAthenaのクエリエディタを開き、クエリ欄に以下を入力して実行します。
SELECT *
FROM "after_etl_table"
LIMIT 10;
中身が見れていれば完了です。
課金体系
AWS Glue・Athena 料金まとめ
| 項目 | 課金 | コスト感 |
|---|---|---|
| データベース存在 | ❌ ほぼなし | 100万オブジェクトまで無料 |
| テーブル存在 | ❌ ほぼなし | 同上 |
| Crawler実行 | ✅ あり | 実行時のみ、$0.15〜/回(10分) |
| Notebook起動 | ✅ あり | $0.88/時間(2 DPU)、起動中は常に課金 |
| Athenaクエリ実行 | ✅ あり | $5/スキャン1TB、クエリ実行時のみ |
多分Notebookに気を使っておけば基本は問題ない。
使わなくなったらすぐに止める。
補足
Notebook
- 使わない時は必ず停止すること
- アイドル状態でも課金される
- 1日8時間で約$7、月間で$140程度
Athena
- スキャンしたデータ量に応じて課金
- 最小課金:10MB(約$0.00005)
- パーティション分割やカラムナフォーマット(Parquet等)でコスト削減可能
- クエリ結果はS3に保存(別途S3料金)
コスト削減のポイント
- Notebook: こまめに停止、自動停止設定を活用。あるいはそもそもNotebookではなく、Scriptを使う。
- Crawler: 必要な頻度のみ実行、増分クロールを活用
- Athena: パーティション活用、SELECT *を避ける、Parquet形式を使用
NotebookはInteractive Sessionsで現在のステータスを確認できる。
Stoppedばかりであれば問題ない。