はじめに
本記事では、国立国会図書館が公開するNDLOCR-LiteをDocker環境で
REST API化し、PDFや画像からテキストを抽出するWebサービスを
構築していきます。
用語
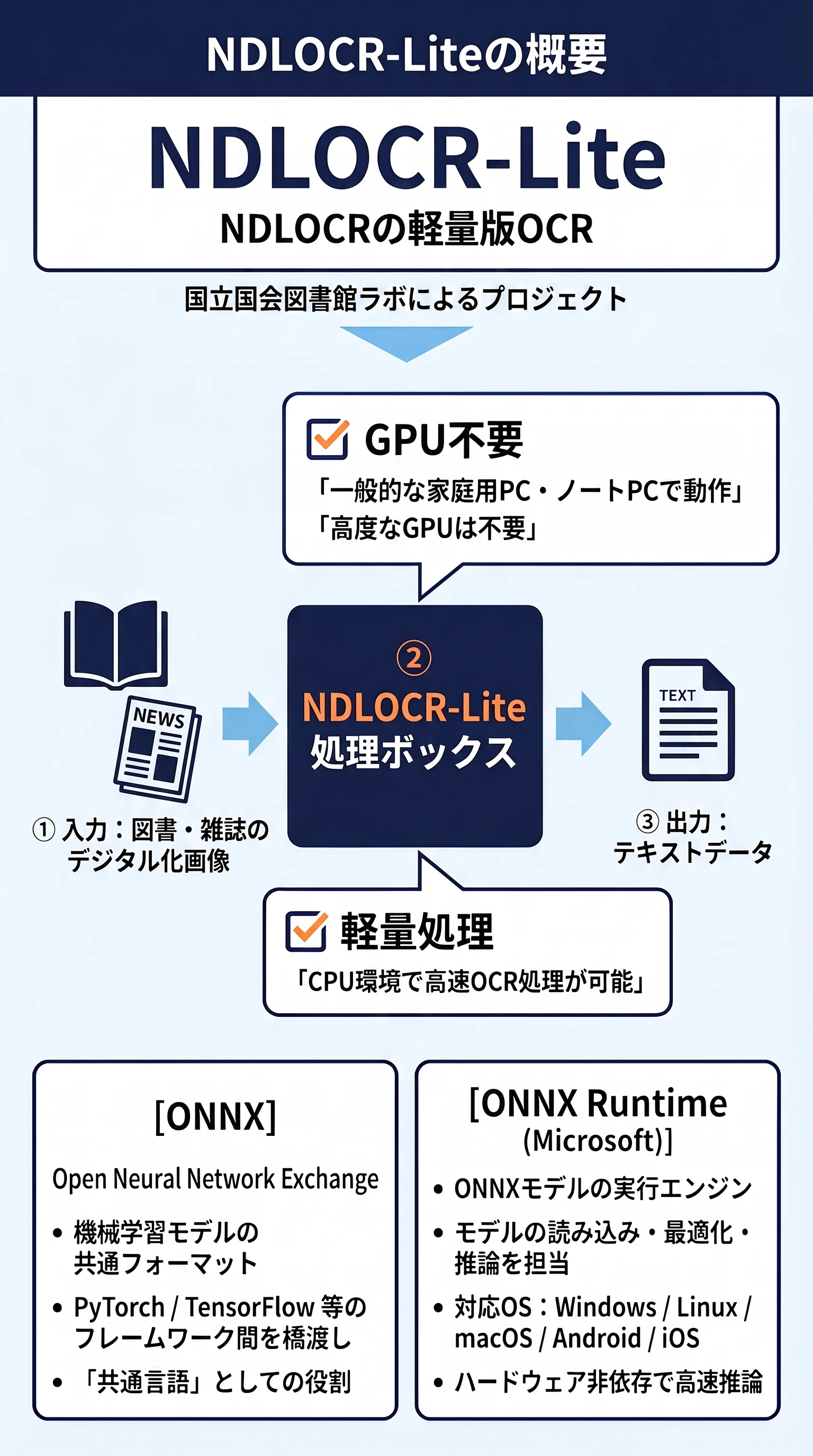
NDLOCR-Liteとは
NDLOCR-Liteは、NDLOCRの軽量版を目指して開発したOCRであり、ノートパソコン等の一般的な家庭用コンピュータやOS環境で、図書や雑誌といった資料のデジタル化画像からテキストデータが作成できるOCRです。
GPU(Graphics Processing Unit。画像描画等の高度な並列計算を処理する装置。)を必要とせず、軽量なOCR処理が可能です。
公式リポジトリ
内部でAIモデルを利用しており、モデルの再学習なども可能なようです。
ONNXとは
ONNX(Open Neural Network Exchange:オニキスまたはオニックス)は、機械学習やディープラーニングのモデルを表現するためのオープンソースの標準フォーマットです。AI開発において、PyTorchやTensorFlowなど様々なフレームワークが存在しますが、ONNXはそれらの間でモデルをやり取りするための「共通言語」としての役割を果たします。
ONNX Runtime
ONNX形式に変換されたモデルを実際に動作(推論)させるためには、実行エンジンが必要です。その代表的なものが、Microsoftが開発したONNX Runtimeです。ONNX Runtimeを使用することで、ONNXモデルを読み込み、最適化し、様々なハードウェアやOS(Windows、Linux、macOS、Android、iOSなど)上で高速に推論を実行することができます。
FastAPI
PythonでWeb APIをすばやく簡単に構築できるモダンなフレームワークです。
ブラウザ上でAPIの動作確認ができるドキュメント(例:Swagger UI)を自動で作成してくれます。
githubリポジトリ
こちらにコード等アップロードしています。
今回はphase01までの内容になります。
今後WebブラウザからD&Dを可能にしたり、
構築
開発環境構築
任意の場所にアプリ開発用のフォルダを用意します。
今回は以下としています。
ndlocr-lite-app/に以下のファイルが存在する
- docker-compose.phase01.yml
ndlocr-lite-app/ndlocr/に以下のファイルが存在する
- Dockerfile
- server.py
- requirements-server.txt
docker-compose.phase01.yml
# Phase 1: NDLOCR-Lite 単体確認用
# ndlocr コンテナだけ起動して OCR が動くことを確認する
#
# 起動: docker compose -f docker-compose.phase01.yml up --build
# 確認: curl -X POST http://localhost:8080/ocr -F "file=@test.jpg"
services:
ndlocr:
build: ./ndlocr
ports:
- "8080:8080"
environment:
- LOG_LEVEL=debug
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 10s
timeout: 5s
retries: 5
start_period: 60s
Dockerfile
# ndlocr/Dockerfile
# NDLOCR-Lite を git clone してFastAPIラッパーをかぶせる
#
# ビルド時に ndlocr-lite をクローンしてモデルファイルをイメージに焼き込む。
# → サーバ起動後にダウンロード不要・再現性が高い
FROM python:3.11-slim
WORKDIR /app
# システム依存(lxml, Pillow, pdf2image用)
RUN apt-get update && apt-get install -y --no-install-recommends \
git curl libgomp1 libgl1 libglib2.0-0 poppler-utils \
&& rm -rf /var/lib/apt/lists/*
# NDLOCR-Lite をクローン(モデルファイルごと)
# ※ .onnx モデルは src/model/ に同梱されているので追加DL不要
RUN git clone https://github.com/ndl-lab/ndlocr-lite.git /ndlocr-lite \
&& pip install --no-cache-dir -r /ndlocr-lite/requirements.txt
# REST APIラッパーの依存
COPY requirements-server.txt .
RUN pip install --no-cache-dir -r requirements-server.txt
# ラッパーサーバのコード
COPY server.py .
# NDLOCR-Lite の src を Python パスに追加するため環境変数で指定
ENV PYTHONPATH=/ndlocr-lite/src
ENV OCR_SRC=/ndlocr-lite/src
EXPOSE 8080
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]
requirements-server.txt
fastapi==0.115.0
uvicorn[standard]==0.30.0
python-multipart==0.0.9
Pillow==10.4.0
pdf2image==1.17.0
server.py
注意: NDLOCR-Lite の出力 JSON は
contentsが二重リスト構造のため、
フラット化処理(_parse_output_dir内)が必要。
また PDF は PIL で直接開けないためpdf2image+popplerで変換してから OCR にかける。
"""
ndlocr/server.py
NDLOCR-Lite を REST API として公開するラッパー
NDLOCR-Lite の ocr.py は CLI前提の設計なので、
内部の OCR エンジン(DEIMv2 + PARSeq)を直接呼ぶ形でラップする。
"""
import os
import sys
import io
import json
import tempfile
import logging
from pathlib import Path
from typing import Optional
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.middleware.cors import CORSMiddleware
# NDLOCR-Lite の src を import
OCR_SRC = os.environ.get("OCR_SRC", "/ndlocr-lite/src")
sys.path.insert(0, OCR_SRC)
logging.basicConfig(level=os.environ.get("LOG_LEVEL", "info").upper())
logger = logging.getLogger(__name__)
app = FastAPI(title="NDLOCR-Lite API", version="1.0.0")
app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_methods=["*"], allow_headers=["*"])
# ── モデルを起動時に一度だけロード ──────────────────────────────
_ocr_engine = None
def get_engine():
global _ocr_engine
if _ocr_engine is None:
logger.info("Loading NDLOCR-Lite models...")
try:
from ocr import OcrEngine # NDLOCR-Lite v1.x の内部クラス
_ocr_engine = OcrEngine()
logger.info("Models loaded.")
except ImportError:
logger.warning("OcrEngine not found, falling back to subprocess mode")
_ocr_engine = "subprocess"
return _ocr_engine
# ── エンドポイント ──────────────────────────────────────────────
@app.on_event("startup")
async def startup():
get_engine()
@app.get("/health")
def health():
engine = get_engine()
return {
"status": "ok",
"engine": "loaded" if engine else "not_loaded",
"mode": "subprocess" if engine == "subprocess" else "direct",
}
@app.post("/ocr")
async def ocr(file: UploadFile = File(...)):
content = await file.read()
suffix = Path(file.filename or "upload").suffix.lower()
if suffix not in {".jpg", ".jpeg", ".png", ".tiff", ".tif", ".bmp", ".jp2", ".pdf"}:
raise HTTPException(400, f"未対応のファイル形式: {suffix}")
engine = get_engine()
# ─ PDF は先にページ画像へ変換してから処理 ─
if suffix == ".pdf":
return await _run_pdf(engine, content)
# ─ Direct モード(OcrEngineを直接使う) ─
if engine != "subprocess":
return await _run_direct(engine, content, suffix)
# ─ Subprocess モード(ocr.py を外部プロセスで叩く) ─
return await _run_subprocess(content, suffix)
# ── PDF モード ──────────────────────────────────────────────────
async def _run_pdf(engine, content: bytes) -> dict:
"""PDF をページ画像に展開して各ページを OCR し結合する"""
try:
from pdf2image import convert_from_bytes
pages = convert_from_bytes(content)
except Exception as e:
raise HTTPException(400, f"PDF 変換エラー: {e}")
all_regions = []
for img in pages:
if engine != "subprocess":
import asyncio
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(None, engine.run, img)
page = _format_result(result)
else:
buf = io.BytesIO()
img.save(buf, format="PNG")
page = await _run_subprocess(buf.getvalue(), ".png")
all_regions.extend(page.get("regions", []))
full_text = "\n".join(r["text"] for r in all_regions if r.get("text"))
return {"text": full_text, "layout_hint": _guess_layout_hint(all_regions), "regions": all_regions}
# ── Direct モード ───────────────────────────────────────────────
async def _run_direct(engine, content: bytes, suffix: str) -> dict:
import asyncio
from PIL import Image
try:
img = Image.open(io.BytesIO(content)).convert("RGB")
except Exception as e:
raise HTTPException(400, f"画像読み込みエラー: {e}")
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(None, engine.run, img)
return _format_result(result)
# ── Subprocess モード ────────────────────────────────────────────
async def _run_subprocess(content: bytes, suffix: str) -> dict:
import asyncio
with tempfile.TemporaryDirectory() as tmpdir:
in_path = Path(tmpdir) / f"input{suffix}"
out_dir = Path(tmpdir) / "output"
out_dir.mkdir()
in_path.write_bytes(content)
cmd = [
sys.executable,
str(Path(OCR_SRC) / "ocr.py"),
"--sourceimg", str(in_path),
"--output", str(out_dir),
]
proc = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
stdout, stderr = await asyncio.wait_for(proc.communicate(), timeout=120)
if proc.returncode != 0:
logger.error("ocr.py stderr: %s", stderr.decode())
raise HTTPException(500, f"OCR処理エラー: {stderr.decode()[:200]}")
return _parse_output_dir(out_dir, in_path.stem)
def _parse_output_dir(out_dir: Path, stem: str) -> dict:
json_files = list(out_dir.glob(f"{stem}*.json"))
txt_files = list(out_dir.glob(f"{stem}*.txt"))
regions = []
layout_hint = ""
if json_files:
try:
data = json.loads(json_files[0].read_text(encoding="utf-8"))
contents = data.get("contents") or data.get("regions") or []
# NDLOCR-Lite の contents は [[{...}, ...], [...]] のネスト構造
if contents and isinstance(contents[0], list):
contents = [item for sublist in contents for item in sublist]
for i, item in enumerate(contents):
text = item.get("text") or item.get("content") or ""
rtype = item.get("type") or item.get("category") or "本文"
regions.append({"text": text, "type": rtype, "order": i})
layout_hint = _guess_layout_hint(regions)
except Exception as e:
logger.warning("JSON parse error: %s", e)
full_text = "\n".join(r["text"] for r in regions)
if not full_text and txt_files:
full_text = txt_files[0].read_text(encoding="utf-8")
return {
"text": full_text,
"layout_hint": layout_hint,
"regions": regions,
}
def _format_result(result) -> dict:
if isinstance(result, str):
return {"text": result, "layout_hint": "", "regions": []}
if isinstance(result, dict):
return {
"text": result.get("text", ""),
"layout_hint": _guess_layout_hint(result.get("regions", [])),
"regions": result.get("regions", []),
}
return {"text": str(result), "layout_hint": "", "regions": []}
def _guess_layout_hint(regions: list) -> str:
types = [r.get("type", "") for r in regions if r.get("type")]
seen = list(dict.fromkeys(types))
return ", ".join(seen)
コンテナイメージのbuild
以下のコマンドを使ってコンテナイメージをbuildします。
✔ ndlocr-lite-app-ndlocr Built と出力されればOKです。
また、docker image ls コマンドでコンテナイメージが出力されることを確認します。
PS C:\Users\ohtsu\Documents\アプリ\ndlocr-lite-app> docker compose -f .\docker-compose.phase01.yml build
中略
#14 resolving provenance for metadata file
#14 DONE 0.0s
[+] Building 1/1
✔ ndlocr-lite-app-ndlocr Built
PS C:\Users\ohtsu\Documents\アプリ\ndlocr-lite-app> docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
ndlocr-lite-app-ndlocr latest 1e8f24c8773b 2 minutes ago 1.33GB
コンテナのデプロイ
buildしたコンテナイメージを使ってコンテナをデプロイします。
PS C:\Users\ohtsu\Documents\アプリ\ndlocr-lite-app> docker compose -f docker-compose.phase01.yml up -d
[+] Running 2/2
✔ Network ndlocr-lite-app_default Created 0.0s
✔ Container ndlocr-lite-app-ndlocr-1 Started
動作確認
以下のコマンドをPowerShellで実行してリッスンしているかを確認します。
StatusCodeが200で返ってくることを確認します。
curl http://localhost:8080/health
StatusCode : 200
StatusDescription : OK
Content : {"status":"ok","engine":"loaded","mode":"subprocess"}
また、Webブラウザで http://localhost:8080/docs にアクセスするとSwagger UIの一覧が出てくればOKです。
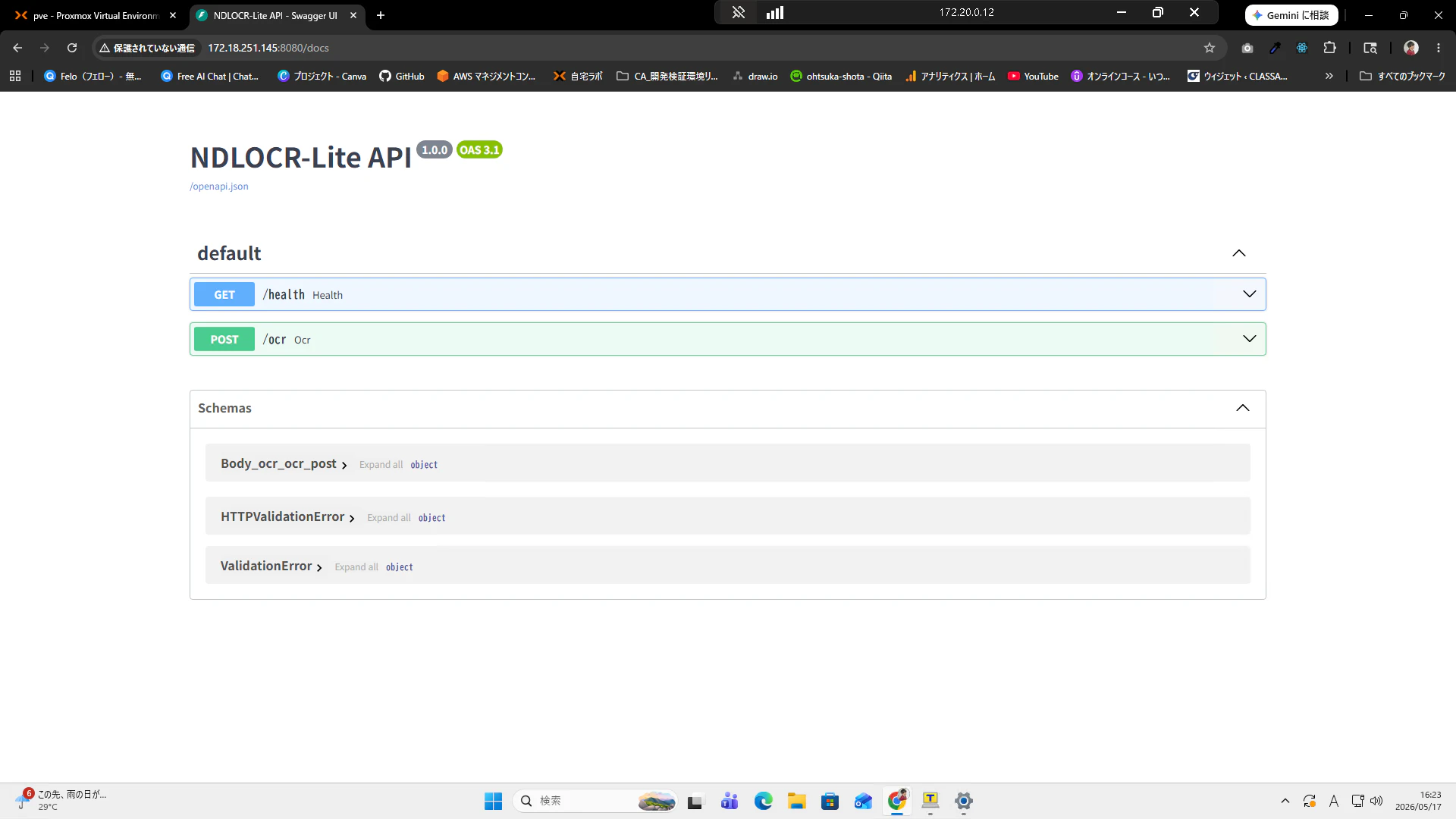
APIがリッスンしていることを確認しましたので、実際にファイルを使って確認してみます。
こちらにある【業務委託契約書(ひな形)】のテンプレートをサンプルとしてOCRを試してみます。
以下のコマンドを実行します。
curl -Method POST http://localhost:8080/ocr -Form "file=get_item('C:\パス\サンプル.pdf')"
今回実行した結果は以下です。
pdfの内容を読み取れていそうです。
PS C:\Users\ohtsu\Documents\アプリ\ndlocr-lite-app> curl.exe -X POST http://localhost:8080/ocr -F "file=@C:\Users\ohtsu\Documents\アプリ\ndlocr-lite-app\sample-file\itaku20241015-min.pdf"
{"text":"業務委託契約書\n委託者○○○○(以下「甲」という)と受託者○○○○(以下「乙」という)は、\n○○○業務(以下「委託業務」という。詳細は第2条に定める)の委託にあたり、以\n下のとおり業務委託契約(以下「本契約」という)を締結する。\n第1条(総則)\n1.甲は、本契約に定めるところに従い、委託業務を乙に委託し、乙はこれを受託す\nる。\n2.本契約に定める業務委託は、委任契約とする。\n第2条(委託業務)\n委託業務について、次のとおりとする。\n(1)委託期間\n令和◦年◦月◦日から令和◦年◦月◦日までとする。\n(2)委託業務内容\n〇〇〇〇\n〇〇〇〇\n(3)善管注意義務\n乙は、委託業務に関して、善良なる管理者の注意をもって誠実にこれを遂行す\nるものとする。\n(4)遂行状況の報告\n乙は、甲からの求めに応じて委託業務の遂行状況を都度報告するものとする。\n(5)委託業務の変更\n委託業務を変更する場合は、事前に相手方と協議の上、
中略
{"text":"本契約に定めのない事項及び疑義を生じた事項については、その都度、甲、乙協議の","type":"本文","order":38},{"text":"上これを決定するものとする。","type":"本文","order":39},{"text":"第16条(準拠法)","type":"本文","order":40},{"text":"本契約の準拠法は日本法とする。","type":"本文","order":41},{"text":"第17条(裁判管轄)","type":"本文","order":42},{"text":"本契約に関し、甲乙間の紛争については、〇〇地方裁判所を第一審の専属的合意管轄","type":"本文","order":43},{"text":"裁判所とする。","type":"本文","order":44},{"text":"以上、本契約の証として、正本2通を作成し、甲乙記名捺印のうえ、各1通を保有す","type":"本文","order":0},{"text":"る。","type":"本文","order":1},{"text":"令和○年○月○日","type":"本文","order":2},{"text":"(甲)","type":"本文","order":3}]}
ハマりポイント
PDF が空レスポンスになる
原因①: PIL は標準で PDF を開けない。poppler-utils と pdf2image を追加し、PDF をページ画像に変換してから OCR にかける必要がある。
原因②: NDLOCR-Lite の出力 JSON の contents は二重リスト構造になっている。
{
"contents": [
[
{ "text": "業務委託契約書", ... },
{ "text": "委託者○○○○...", ... }
]
]
}
フラット化せずにパースすると item.get("text") が失敗して空になる。_parse_output_dir 内で以下の処理が必要。
if contents and isinstance(contents[0], list):
contents = [item for sublist in contents for item in sublist]
デプロイ用のubuntu24.04サーバ構築
サーバのHWスペックは以下です。

以下のコマンドを実行します。
Docker及びDocker composeをインストールします。
test@ocr-dev-env:~$ sudo su -
[sudo] password for test:
root@ocr-dev-env:~# apt update && apt upgrade -y
root@ocr-dev-env:~# apt install ca-certificates curl
root@ocr-dev-env:~# install -m 0755 -d /etc/apt/keyrings
root@ocr-dev-env:~# curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
root@ocr-dev-env:~# chmod a+r /etc/apt/keyrings/docker.asc
root@ocr-dev-env:~# tee /etc/apt/sources.list.d/docker.sources <<EOF
Types: deb
URIs: https://download.docker.com/linux/ubuntu
Suites: $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}")
Components: stable
Architectures: $(dpkg --print-architecture)
Signed-By: /etc/apt/keyrings/docker.asc
EOF
root@ocr-dev-env:~# apt update
root@ocr-dev-env:~# apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
root@ocr-dev-env:~# systemctl start docker
root@ocr-dev-env:~# systemctl enable docker
root@ocr-dev-env:~# docker --version
Docker version 29.5.0, build 98f1464
root@ocr-dev-env:~# docker compose version
Docker Compose version v5.1.3
githubリポジトリからpullするためのgitコマンドもインストールします。
root@ocr-dev-env:~# apt install -y git
リポジトリからクローンします。
root@ocr-dev-env:~# git clone https://github.com/ohtsuka-shota/ndlocr-lite-app/
root@ocr-dev-env:~# ls -ltr
total 4
drwxr-xr-x 7 root root 4096 May 16 13:14 ndlocr-lite-app
移動して環境をデプロイします。
root@ocr-dev-env:~# cd ndlocr-lite-app
root@ocr-dev-env:~/ndlocr-lite-app# docker compose -f docker-compose.phase01.yml build
root@ocr-dev-env:~/ndlocr-lite-app# docker compose -f docker-compose.phase01.yml up -d
root@ocr-dev-env:~/ndlocr-lite-app# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1890a7618a90 ndlocr-lite-app-ndlocr "uvicorn server:app …" 4 seconds ago Up 3 seconds (health: starting) 0.0.0.0:8080->8080/tcp, [::]:8080->8080/tcp ndlocr-lite-app-ndlocr-1
デプロイしたコンテナに対してAPIでOCRを試してみます。問題なさそうですね。
PS C:\WINDOWS\system32> curl.exe -X POST http://172.18.251.145:8080/ocr -F "file=@C:\Users\otsuka-shota\Documents\pdf_test.pdf"
{"text":"PDFのアップロードテスト用に作成しました\nテスト用PDF\n作成者\n見出し1\n(このテキストのような)プレースホルダーテキストをタップして入力するだけで、すぐに作成を\n開始できます。\n・PC、タブレット、スマートフォンからWordを使ってこの文書を表示、編集できます。\n・テキストの編集が可能で、画像、図形、表などのコンテンツの挿入も簡単です。\nWindows、Mac、 Android、iOSデバイスからWordを使ってクラウドにシームレスに文\n書を保存できます。\n・2ページ目も用意してあります。\n見出し2\nファイルから画像を挿入したり、または図形、テキストボックス、表を追加をしたいとします。そ\nの場合は、リボンの[挿入]タブで、必要なオプションをタップするだけです。\n引用文\nこのページに表示されている文字列の書式は、リボンの[ホーム]タブ上にある「スタイル]か\nら1タップで簡単に設定できます。\n列見出し\n行見出し\n行見出し\nテキスト\nテキスト\n123.45\n123.45","layout_hint":"本文","regions":[{"text":"PDFのアップロードテスト用に作成しました","type":"本文","order":0},{"text":"テスト用PDF","type":"本文","order":1},{"text":"作成者","type":"本文","order":2},{"text":"見出し1","type":"本文","order":3},{"text":"(このテキストのような)プレースホルダーテキストをタップして入力するだけで、すぐに作成を","type":"本文","order":4},{"text":"開始できます。","type":"本文","order":5},{"text":"・PC、タブレット、スマートフォンからWordを使ってこの文書を表示、編集できます。","type":"本文","order":6},{"text":"・テキストの編集が可能で、画像、図形、表などのコンテンツの挿入も簡単です。","type":"本文","order":7},{"text":"Windows、Mac、 Android、iOSデバイスからWordを使ってクラウドにシームレスに文","type":"本文","order":8},{"text":"書を保存できます。","type":"本文","order":9},{"text":"・2ページ目も用意してあります。","type":"本文","order":10},{"text":"見出し2","type":"本文","order":0},{"text":"ファイルから画像を挿入したり、または図形、テキストボックス、表を追加をしたいとします。そ","type":"本文","order":1},{"text":"の場合は、リボンの[挿入]タブで、必要なオプションをタップするだけです。","type":"本文","order":2},{"text":"引用文","type":"本文","order":3},{"text":"このページに表示されている文字列の書式は、リボンの[ホーム]タブ上にある「スタイル]か","type":"本文","order":4},{"text":"ら1タップで簡単に設定できます。","type":"本文","order":5},{"text":"列見出し","type":"本文","order":6},{"text":"行見出し","type":"本文","order":7},{"text":"行見出し","type":"本文","order":8},{"text":"テキスト","type":"本文","order":9},{"text":"テキスト","type":"本文","order":10},{"text":"123.45","type":"本文","order":11},{"text":"123.45","type":"本文","order":12}]}
続き
Reactを使ってWebUIを追加したものです