今回はProxmoxで構築したホームラボにローカルLLMを導入していきたいと思います。
用語
ローカルLLM
ローカルLLMとは、ChatGPTのようなクラウドサービスを利用するのではなく、自分のPCや自社サーバーなどのローカル環境(オンプレミス)で大規模言語モデル(LLM)を直接動作させる技術のことです。
近年、プライバシー保護やコスト削減の観点から、企業や個人の開発者の間で急速に注目を集めています。
Ollama
Ollama(オラマ)は、大規模言語モデル(LLM)を自分のPCなどのローカル環境で簡単に実行・管理できるオープンソースのツールです。
従来、AIモデルを動かすには複雑な設定や高性能なサーバーが必要でしたが、Ollamaは「ローカルLLM界のDocker」や「Homebrew」と例えられるほど、導入と操作を簡略化しているのが特徴です
| 項目 | Ollama (ローカル) | クラウド型 (ChatGPT等) |
|---|---|---|
| データプライバシー | 非常に高い(外部に出ない) | 低い(サーバーに送信される) |
| 利用料金 | 無料(電気代・機密費のみ) | 従量課金または月額制 |
| インターネット | 不要(オフライン可) | 必須 |
| 処理速度 | PCの性能に依存 | ネットワーク速度に依存 |
Ollama Library
Ollama公式が提供している大規模言語モデル(LLM)の配布・管理ハブを指します。Dockerにおける「Docker Hub」のような役割を果たしています
Continue(VSCodeの拡張機能)
VS Codeの拡張機能であるContinueは、GitHub CopilotのようなAIコーディング支援を、自分の好きなAIモデル(特にローカルLLM)で実現できるオープンソースのツールです。
主な特徴や使い方は以下の通りです。
Continueの主な機能
- チャット (Chat): サイドバーでAIにコードの解説や修正案を質問できます(Ctrl/Cmd + Lでコードを選択して追加)。
- インライン編集 (Edit): コード上で直接「この関数をリファクタリングして」といった指示を出し、差分を確認しながら適用できます(Ctrl/Cmd + I)。
- オートコンプリート (Autocomplete): コードの続きをリアルタイムで予測・補完します。
- コンテキスト参照: @filename や @codebase と入力することで、特定のファイルやプロジェクト全体をAIに読み込ませて回答の精度を高められます
Qwen
Qwen(クウェン)は、中国のAlibaba Cloud(アリババクラウド)が開発・提供している大規模言語モデル(LLM)シリーズです。2024年から2026年にかけて急速に進化を遂げ、オープンソース界隈においてMeta社のLlamaシリーズと並ぶ、あるいは一部の性能で凌駕するトップクラスのモデル群として知られています
nomic-embed-text
Ollamaで利用可能なテキスト埋め込み(Embedding)専用の高機能オープンソースモデルです。
このモデルは、テキストを数値ベクトルに変換することに特化しており、主にRAG(検索拡張生成)やセマンティック検索(意味ベースの検索)などの用途で使用されます。
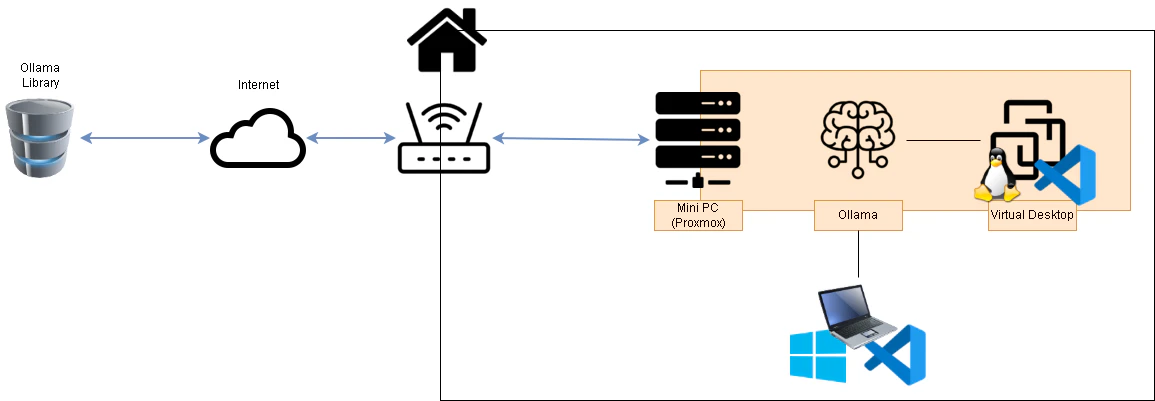
環境イメージ
LXCを使ってLLMを動かすOllama環境を構築します。
Ollama上で動かすLLMはOllama Libraryから引っ張ってきて、それをローカルで実行します。
VSCodeのContinueをOllamaと紐づけることでAIを使った開発環境を作ってみようと思います。
環境構築
LXC環境の用意
LXCでOllamaを動かす環境を用意していきます。
画面右上のCTを作成を押下します。
ホスト名はOllam
非特権コンテナとして、パスワードを指定します。
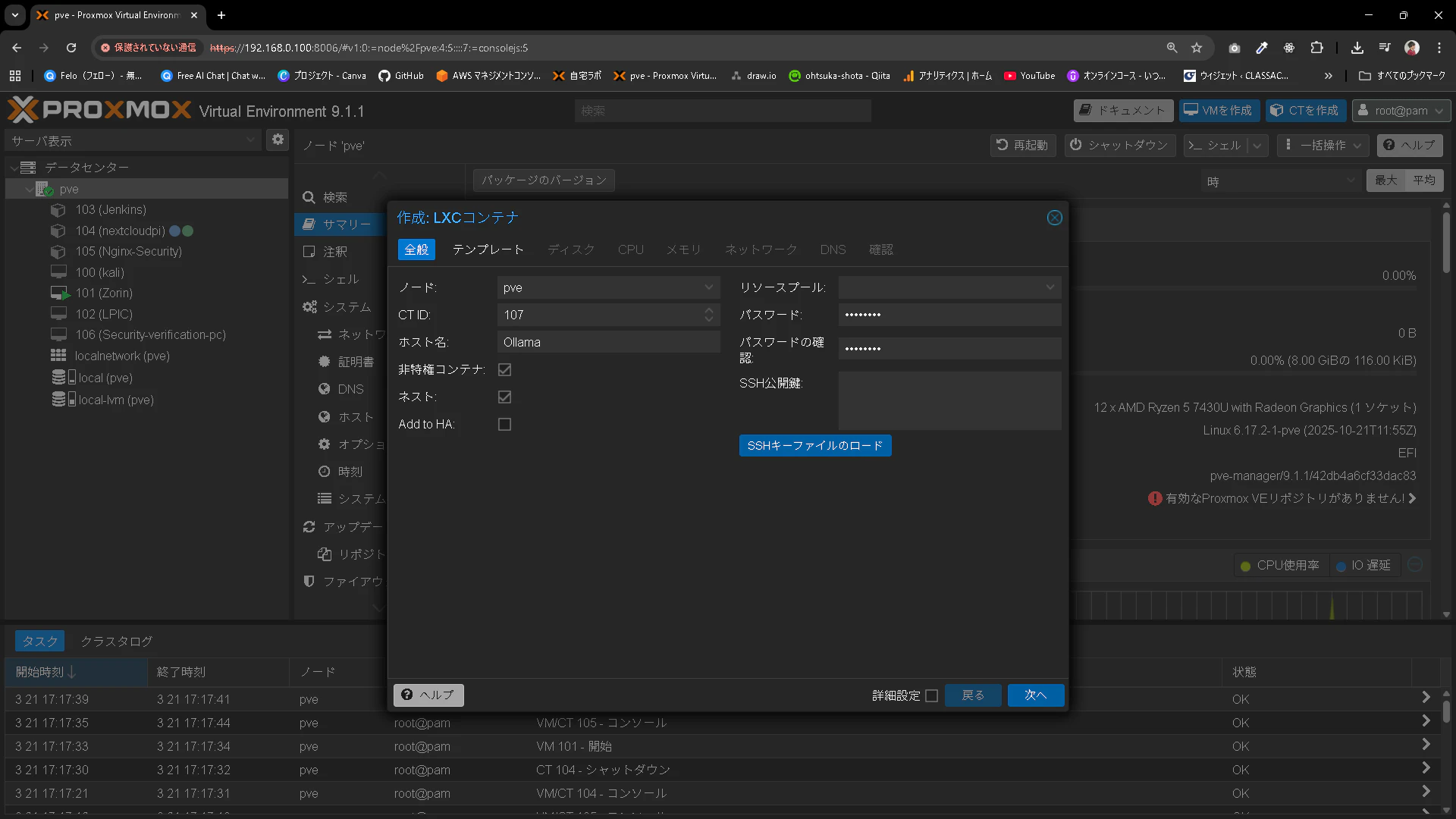
テンプレートはubuntuとします。
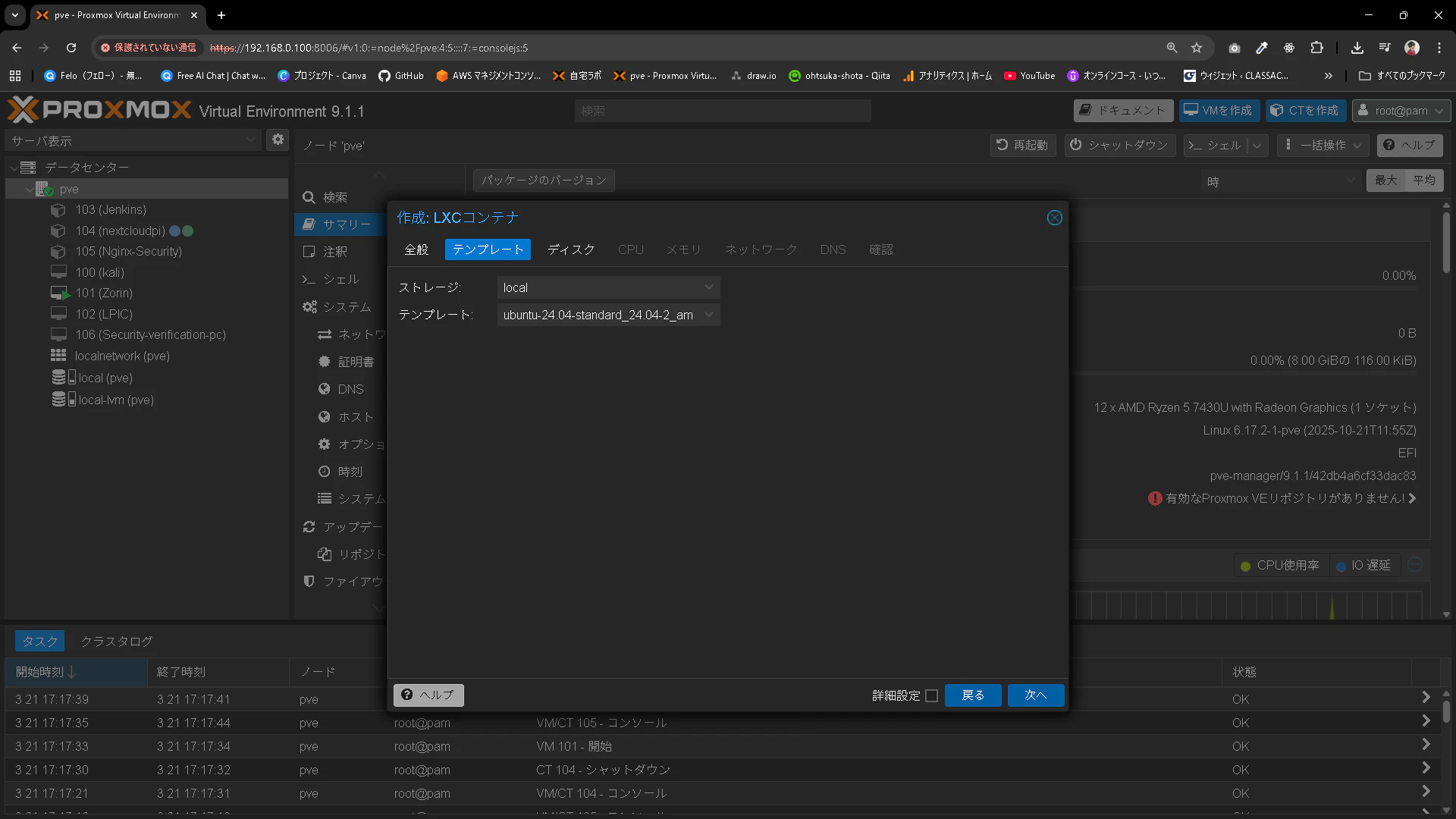
Diskは10GB位割り当てます。
※後からわかったのですが、30GB位あった方が良いと思います。
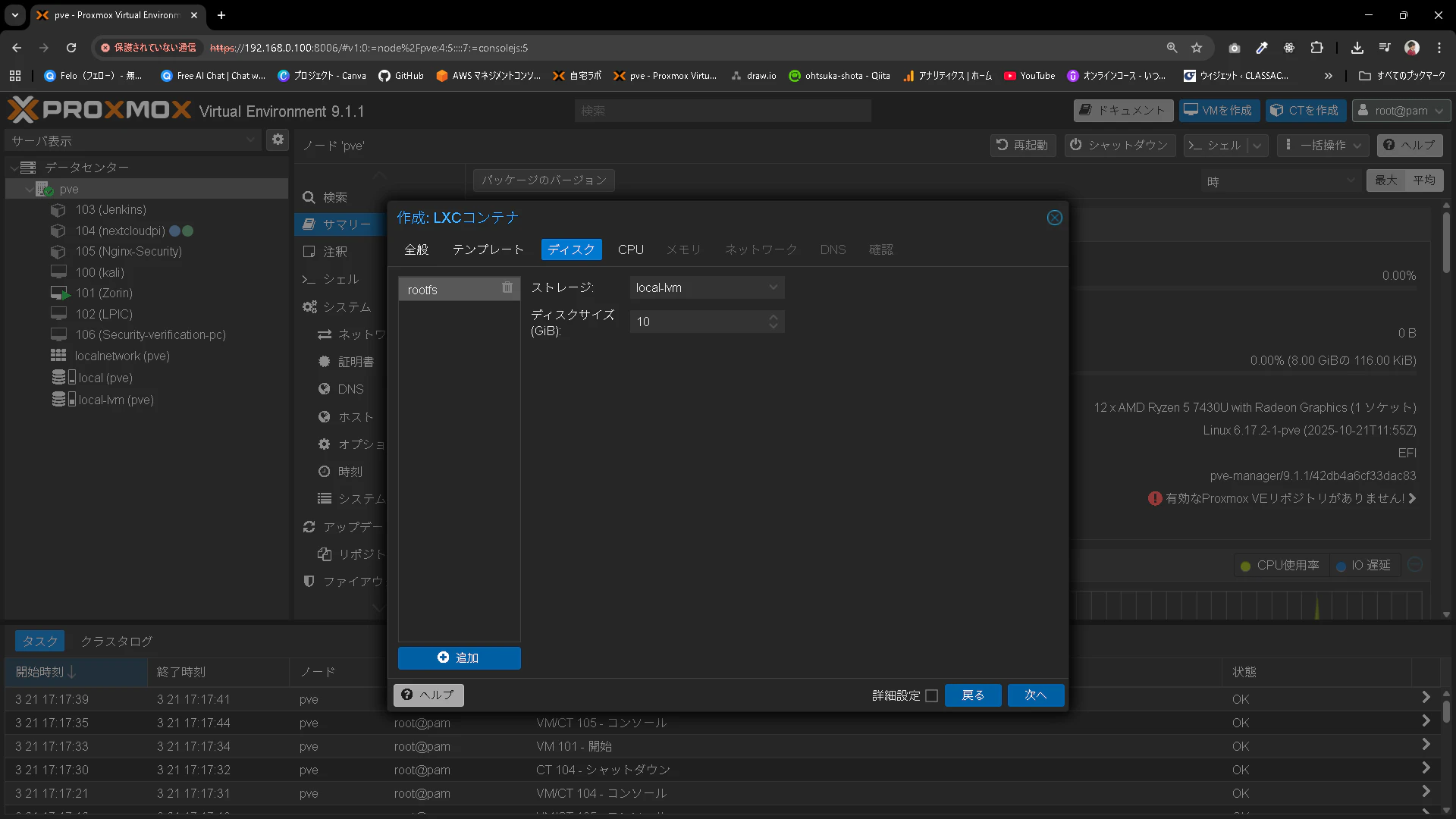
CPUは8コアとします。
※4コアでも動きますが、かなりカツカツです。8とかあると遅いですがそれなりに動きます。
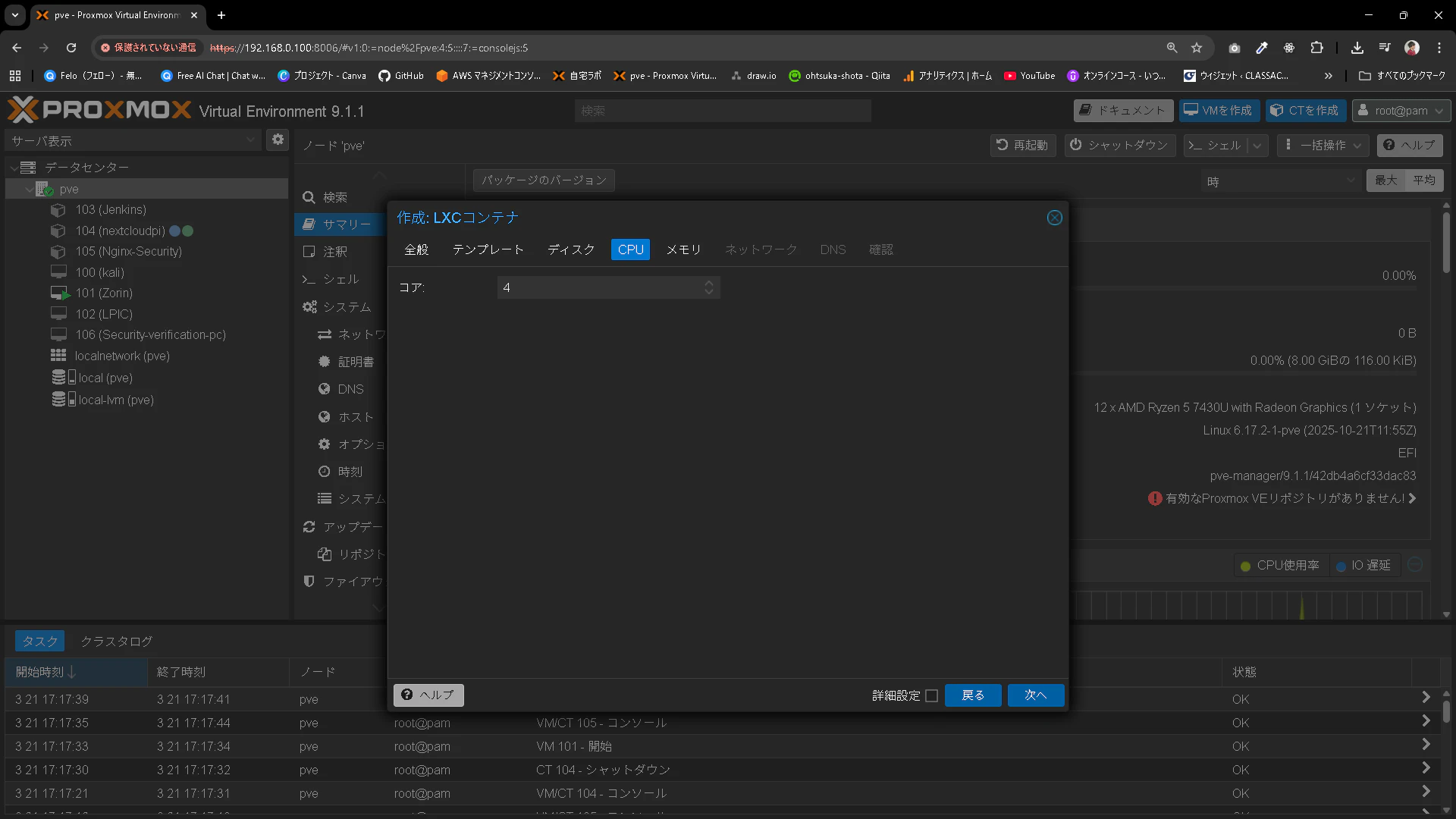
メモリは12288MiB。スワップは2048MiBとします。
※スクショだとこれより小さいですが、あとから動かしてみて足りないことが発覚して増やしてます。
ネットワークは他のVMやLXCがいるインターネットに繋がるものを設定しておきます。
IPアドレスを自動で割り当てるために、DHCPを設定しておきます。
LXCが爆速で立ち上がると思います。
ユーザはroot、パスワードは先ほど設定したもので問題ありません。
apt update && apt upgrade -yを実行しておきましょう。
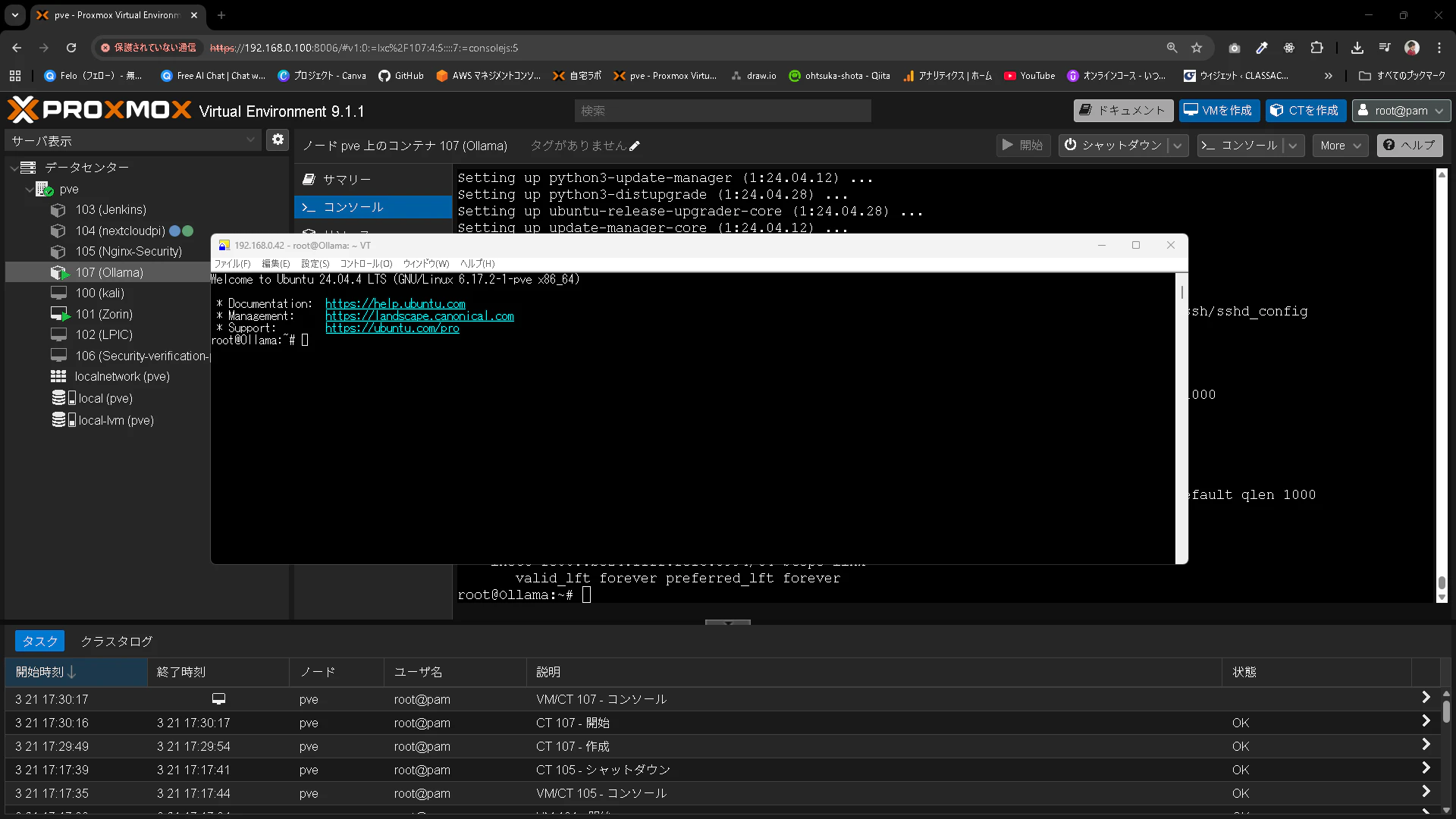
デプロイしたLXCにTeratermなどからSSHをするために以下の手順を実行しておきます。
次のコマンドを実行してSSH接続出来るようにします。
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
systemctl restart ssh
Teratermで接続出来ました。
Ollama導入
この辺りを見ています。
curlとzstdが必要なのでインストールしておきます。zstdはgzipとかよりも高機能な奴らしいです。
zstdは公式とかに書いてませんでしたが、コマンド実行したら必要だと怒られました。
apt install -y curl zstd
curl -fsSL https://ollama.com/install.sh | sh
バージョンは0.18.2でした。
起動しようとしたらはじかれましたね。。。
インストールしたら自動で立ち上がっているのかな?
root@Ollama:~# ollama -v
ollama version is 0.18.2
root@Ollama:~# ollama serve
Couldn't find '/root/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 ●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
Error: listen tcp 127.0.0.1:11434: bind: address already in use
以下のコマンドを実行します。
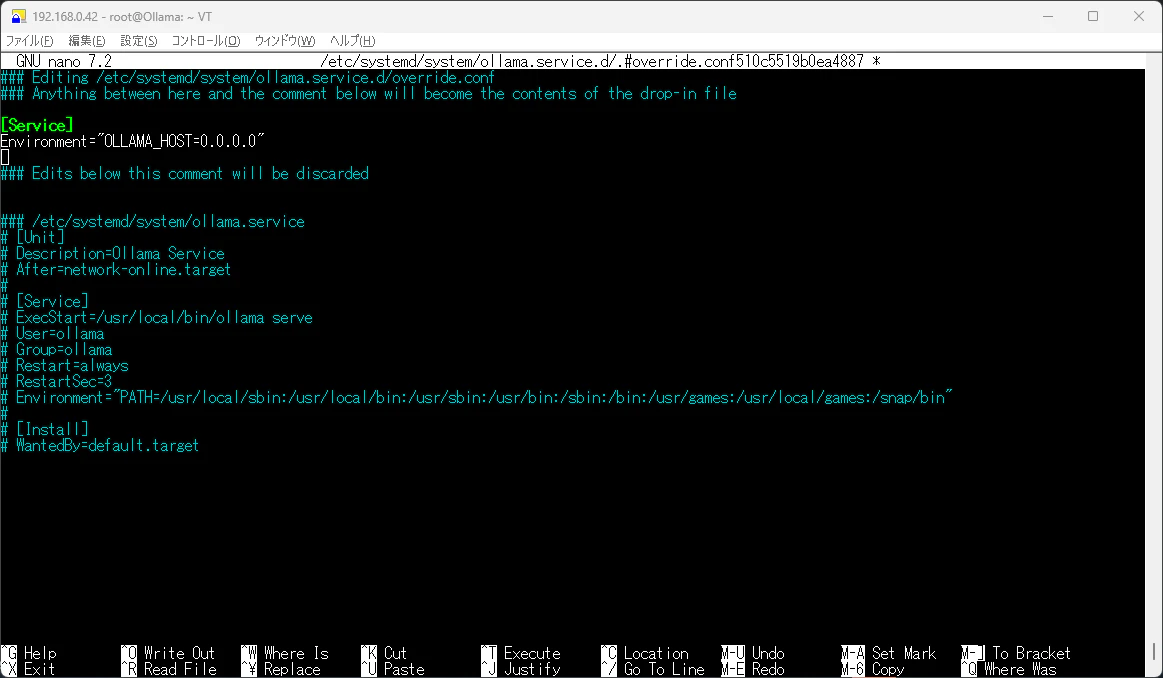
systemctl edit ollama.service
edit画面が開きました。恐らくnano系のコマンドで開いているように見えます。
以下を一番上に追記します。他のPCやサーバからの接続を受け付けるという内容です。
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
次のコマンドを実行して、設定を反映していきます。
systemctl daemon-reload
systemctl restart ollama
systemctl enable ollama
自分自身にcurlを叩いてOllamaが起動しているかを確認します。
Ollama is runningとなっていれば問題ありません。
root@Ollama:~# curl http://localhost:11434
Ollama is running
Ollamaにモデルをpullする
モデルをpullします。
ollama listコマンドでpullしたモデルがあることを確認します。
# チャット・修正用(賢い)
ollama pull qwen2.5-coder:7b
# 自動補完用(爆速)
ollama pull qwen2.5-coder:1.5b
# embedding用
ollama pull nomic-embed-text
root@Ollama:~# ollama list
NAME ID SIZE MODIFIED
nomic-embed-text:latest 0a109f422b47 274 MB 4 seconds ago
qwen2.5-coder:1.5b d7372fd82851 986 MB 6 minutes ago
qwen2.5-coder:7b dae161e27b0e 4.7 GB 7 minutes ago
VSCodeのセットアップ
Webブラウザを開き、http://:11434/とアクセスして、以下のようにOllama is runningと表示されることを確認します。
VScodeの拡張機能でContinueを探してインストールします。
画面左にあるContinueのアイコンを押下して歯車マークを押下します。
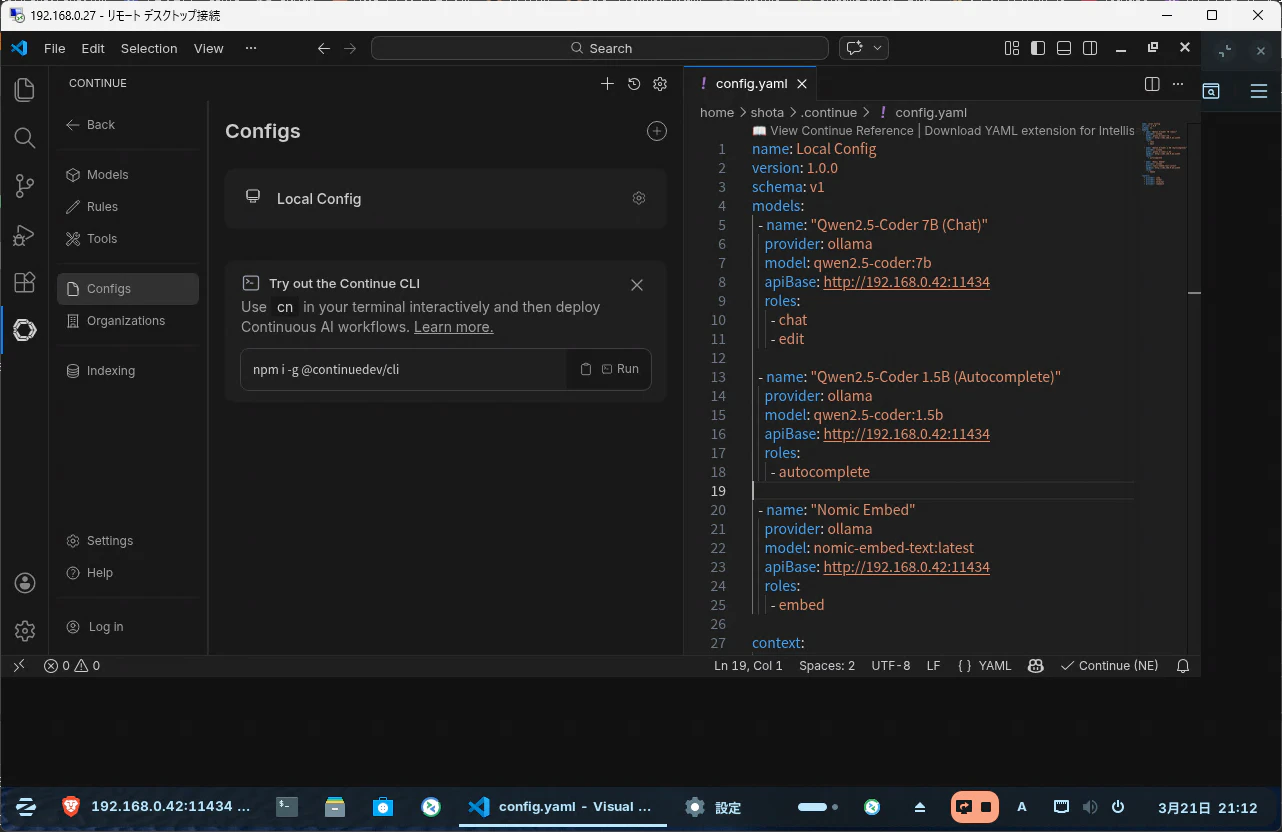
Configsを開くとLocal Configというものがあります。
これの歯車を押下するとconfig.yamlが開きます。
中身を以下とします。
Ollamaが稼働しているLXCのIPアドレスに修正しましょう。
name: Local Config
version: 1.0.0
schema: v1
models:
- name: "Qwen2.5-Coder 7B (Chat)"
provider: ollama
model: qwen2.5-coder:7b
apiBase: http://192.168.1.xxx:11434
roles:
- chat
- edit
- name: "Qwen2.5-Coder 1.5B (Autocomplete)"
provider: ollama
model: qwen2.5-coder:1.5b
apiBase: http://192.168.1.xxx:11434
roles:
- autocomplete
- name: "Nomic Embed"
provider: ollama
model: nomic-embed-text:latest
apiBase: http://192.168.1.xxx:11434
roles:
- embed
context:
- provider: code
- provider: folder
- provider: terminal
- provider: codebase
修正した図。
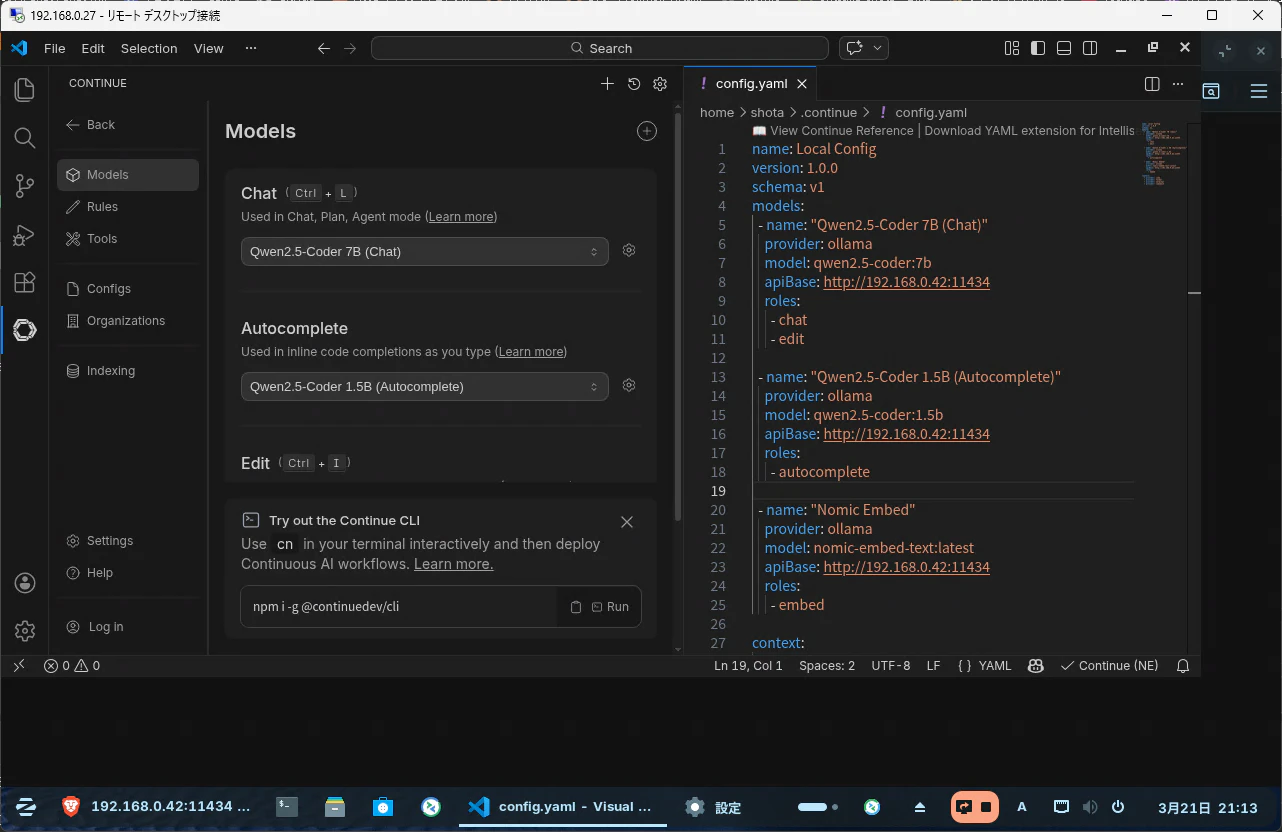
動作確認
ModelsのChat部分にQwen2.5-Coder7Bと記載があることを確認します。
画面右下にContinueという表示があるので押下します。
Chatを開けると思います。
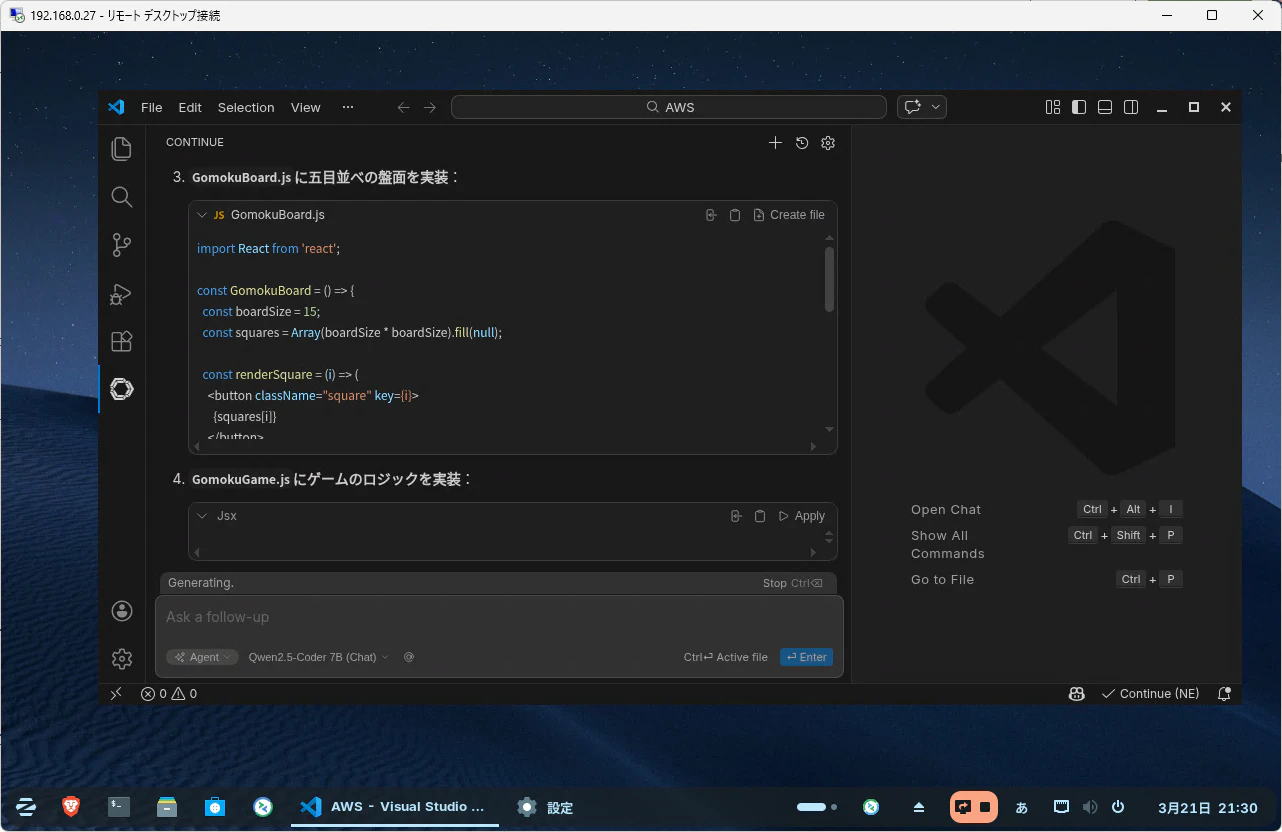
PythonでHello Worldを書いてとメッセージを送ってみます。
処理が始まりました。
Proxmoxのリソースにも負荷がかかっていますね。当たり前ですが。
出来ました。
ただ、最低限のスペックなのでちょっとこのままだと頂けないですね。
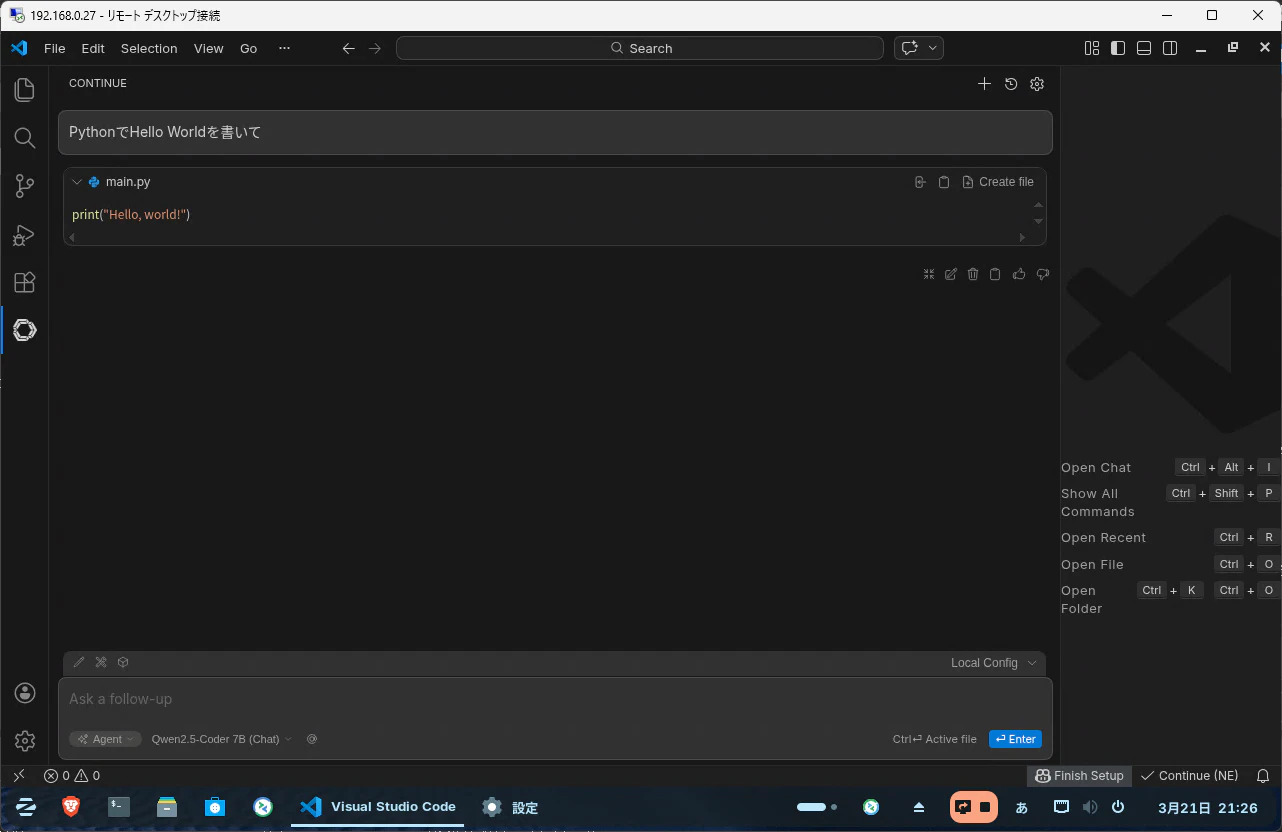
精度はともかく、雑な指示でもコーディングはしてくれます。
まともに使いたいのであれば、Ollamaを使うタイミングでは、Proxmoxで潤沢にリソースを割り当ててあげて、使い終わったら元に戻す、みたいな運用をすればいいのかなと思いました。