AWS Redshiftの初歩の初歩をハンズオンで試してみたいと思います。
普段触らない部分ばかりなので、頭をフル回転させながらアウトプットしてます
参考にしている動画
用語
Redshiftとは
AWSが提供するクラウド型データウェアハウスサービスです。大規模なデータ分析に特化しており、ペタバイト級のデータを高速に処理できます。列指向ストレージとMPP(超並列処理)アーキテクチャにより、複雑な分析クエリを効率的に実行します。
RPU(Redshift Processing Unit)
CPU + メモリ + ネットワーク + Redshiftの実行基盤をまとめた“処理能力のかたまり”
ServerlessではこのRPUが増えるほど、同時にさばける量や処理速度が上がりやすい。
Serverless(Redshift Serverless)
従来の「クラスタ(ノード)を立てて常時起動」ではなく、
クエリ実行に必要な計算リソースを RPU という単位で使い
(設定により)負荷に応じて 自動でスケール
課金は主に 計算(RPU-hours)+保存(ストレージ)
という運用モデルです。
「インスタンスサイズを決めてサーバを維持する」ではなく、「使った分だけ」寄りです。
namespace
Namespaceには主に次が入ります。
データ(テーブルの中身)
スキーマ、テーブル、ビューなどのメタデータ
データベース(例:sample_data_dev)やその中の tickit スキーマ など
管理ユーザー情報(admin など、作成時設定)
課金面では、Namespaceにデータが残っている限り ストレージ課金が続きます。
ようはデータとDB定義の入れ物
workgroup
Workgroupは主に次を持ちます。
接続エンドポイント(Query Editorやアプリが繋ぐ先)
Base capacity(ベースRPU) と Max capacity(上限RPU)
ネットワーク設定(VPC/Subnet/Security Group)
認証・アクセス周り(IAM、SG等)
課金面では、Workgroupがクエリ処理等で動いている間の **計算課金(RPU-hours)**が中心です。
ようは計算リソース+接続先
Query Editor v2
Redshift Query Editor v2 は、ブラウザ上でRedshift(Provisioned/Serverless)に接続してSQLを実行できるAWSの管理ツールです。結果表示、クエリ履歴、保存クエリ、DBオブジェクト参照などができ、ローカルにクライアントを入れなくても使えます。
一部BIツール的な側面もある。
Redshift系の登場人物の相関図を図にまとめる

DWH(Data Warehouse/データウェアハウス)
企業の意思決定を支援するために、複数のシステムから収集したデータを統合・蓄積する基盤です。過去データを含む大量の情報を保管し、BIツールなどで分析しやすい形式で整理されています。トランザクション処理ではなく、分析処理(OLAP)に最適化されています。
Data Lake(データレイク)
構造化・非構造化を問わず、あらゆる形式の生データを大量に保存できるストレージリポジトリです。DWHと異なり、データを事前に加工せず元の形式のまま保管するため、柔軟な分析が可能です。S3などのオブジェクトストレージ上に構築されることが多く、機械学習やビッグデータ分析に活用されます。
ETL(Extract, Transform, Load)
データソースから抽出(Extract)し、分析用に変換・加工(Transform)してから、DWHなどへ格納(Load)する従来型のデータ統合プロセスです。変換処理を事前に行うため、データ品質を保証しやすい反面、処理に時間がかかります。
ELT(Extract, Load, Transform)
データを抽出(Extract)後、まず格納先へ投入(Load)し、その後に変換(Transform)する新しいアプローチです。クラウドDWHの高い処理能力を活用でき、データの取り込みが高速で、必要に応じて柔軟に変換できるメリットがあります。
処理の流れ・構成図
AWSの各種サービスで表現すると、一例としては以下のようになると思います。

① ETLフロー(Glueを使うパターン)
S3(Raw) → Glue(加工) → S3(Curated) → Redshift → QuickSight
- Raw:とりあえず溜めた“生”
- Glue:生を洗って整える係(必要なときだけ)
- Curated:整え終わった“きれいなデータ置き場”
- Redshift:分析しやすい形にさらにSQLでまとめたり、集計したりする場所
- QuickSight:可視化
Glueを使うのは、前で整えた方が都合がいい時だけ(汚いCSV、個人情報のマスキング、Parquet化したい等)。
② ELTフロー(Redshiftで加工するパターン)
S3(Raw) → Redshift(取り込み) → Redshift内SQLで加工 → QuickSight
- Glueを挟まず、Redshiftに入れてからSQLで整形する
「前段で加工がマスト」ではなく、Redshift内で加工してOKという考え方
ハンズオン
まず、オハイヨリージョンで今回作業していきます。
いつも使っている東京リージョンは、デフォルトのVPCを削除してしまっておりまして。
Redshiftの環境を作るのにお手軽な方法としてデフォルトのVPCを使う方法があり、デフォルトVPCが残っているリージョンで作業を行っていきます。

AWSマネジメントコンソールからRedshiftと検索してアクセスすると以下のような画面にアクセスできます。
無料トライアルボタンを押下します。
設定画面が出ると思いますが、まずIAMロールについて。
恐らく最初は何も記載がないと思われますので、IAMロールを作成を押下します。
デフォルトの設定で問題ありませんので、そのままIAMロールをデフォルトとして作成するを押下します。
これはS3にデータを取得する時に使う権限の様です。
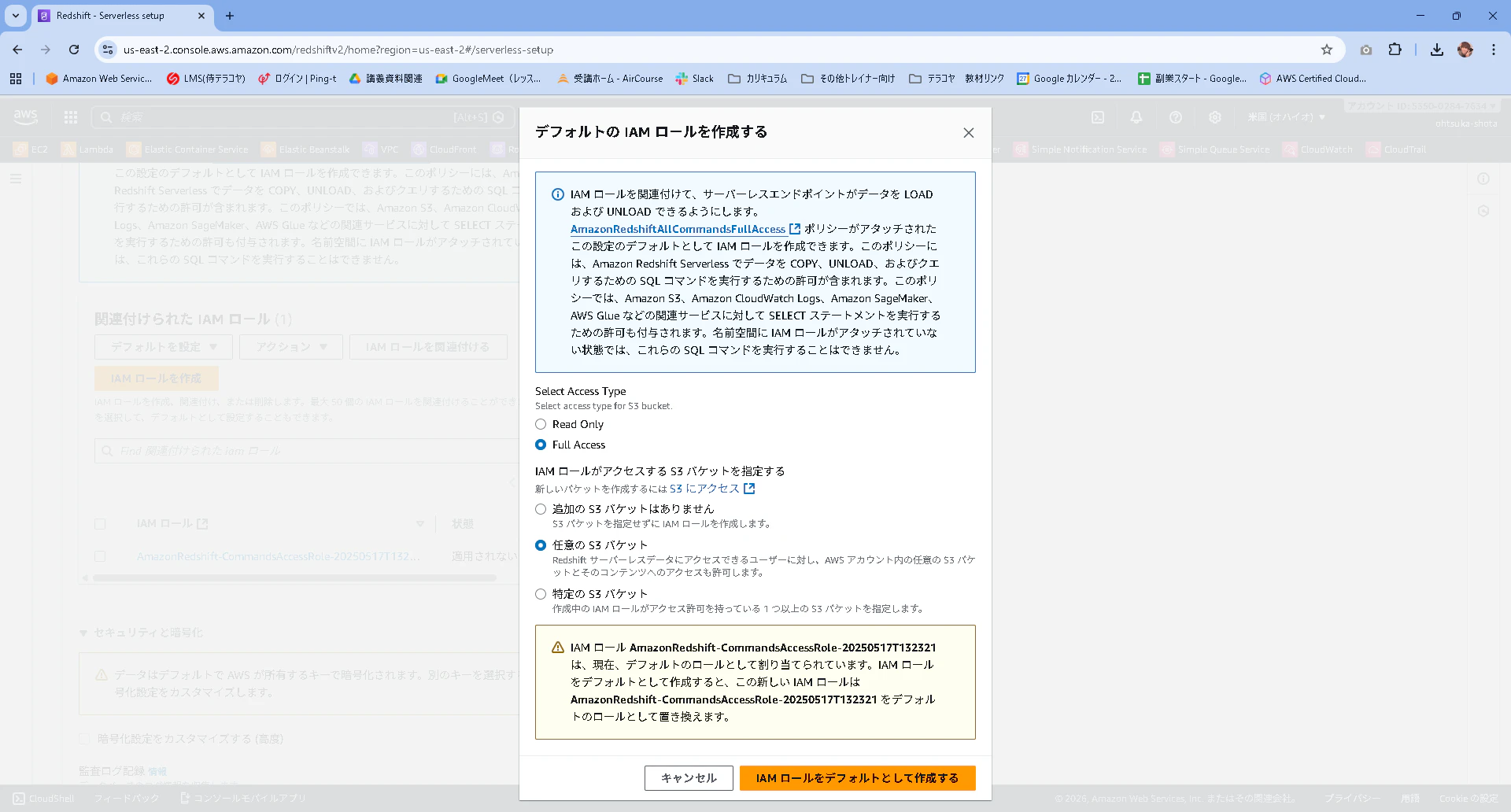

改めて、今回は以下の設定で作成をしていきます。
設定:設定をカスタマイズ
名前空間:redshift-namespace
IAMロール:先ほど新規作成したもの
ワークグループ:redshift-workgroup
ベース容量:8(RPU(Redshift Processing Unit))※今回のハンズオンでは重い操作をしない為、軽めのスペックにしてクレジットを少しでも消費しないようにします。
他はデフォルトの設定で設定を保存を押下します。
作成が開始されると以下のような画面が表示されます。
暫く待機します。
環境のデプロイが完了すると次へボタンが押せるようになりますので、これを押下します。

以下のような画面が表示されます。
無料トライアルの部分でクレジットが存在していることを念のため確認しておきましょう。

画面左にあるデータクエリv2を押下します。

redshiftで作業するためのWebUIが表示されます。
Serverless:reshift-workgroupの記載があることを確認します。

実際にworkgroupに接続するためには上記で確認した
Serverless:reshift-workgroupを押下することで接続することが出来ます。
デフォルトの設定Federated UserでDatabaseはdevのままCreate Connectionを押下します。

接続が成功して、workgroupの配下に色々情報が表示されるようになったことがわかります。

これらはそれぞれ以下のような意味合いになります。
devやsample_data_dev: データベース。Excelのbookみたいなもの。
publicやtickit等: スキーマ。テーブルやビュー、関数などをまとめる “フォルダみたいなもの
Table: データベーステーブル。Excelでいうシートみたいなもの。
external databases(awsdatacatalog): Redshiftの“中”にあるデータではなく、主に S3上のデータを対象にする「外部データ(Spectrum)」側のカタログです(Glue Data Catalog)
サンプルデータを投入していきます。tickitの右側にあるアイコンを押下して、Openしていきます。

Createしていきます。

問題なくCreate出来たことを確認します。Create出来ると別タブでtickit-sample-notebookというnotebookが作成されていることがわかります。
この時、AWSが用意しているS3から自分のRedshiftのnamespaceに紐づくmanaged storageにデータが読み込まれております。

改めて見てみると、Jupiter NotebookやGoogle Colabのような構成で、それぞれがサンプルクエリであることがわかります。

試しにSales per eventに用意されているクエリを実行すると、eventnameとtotal_priceからなるデータセットが出力されると思います。
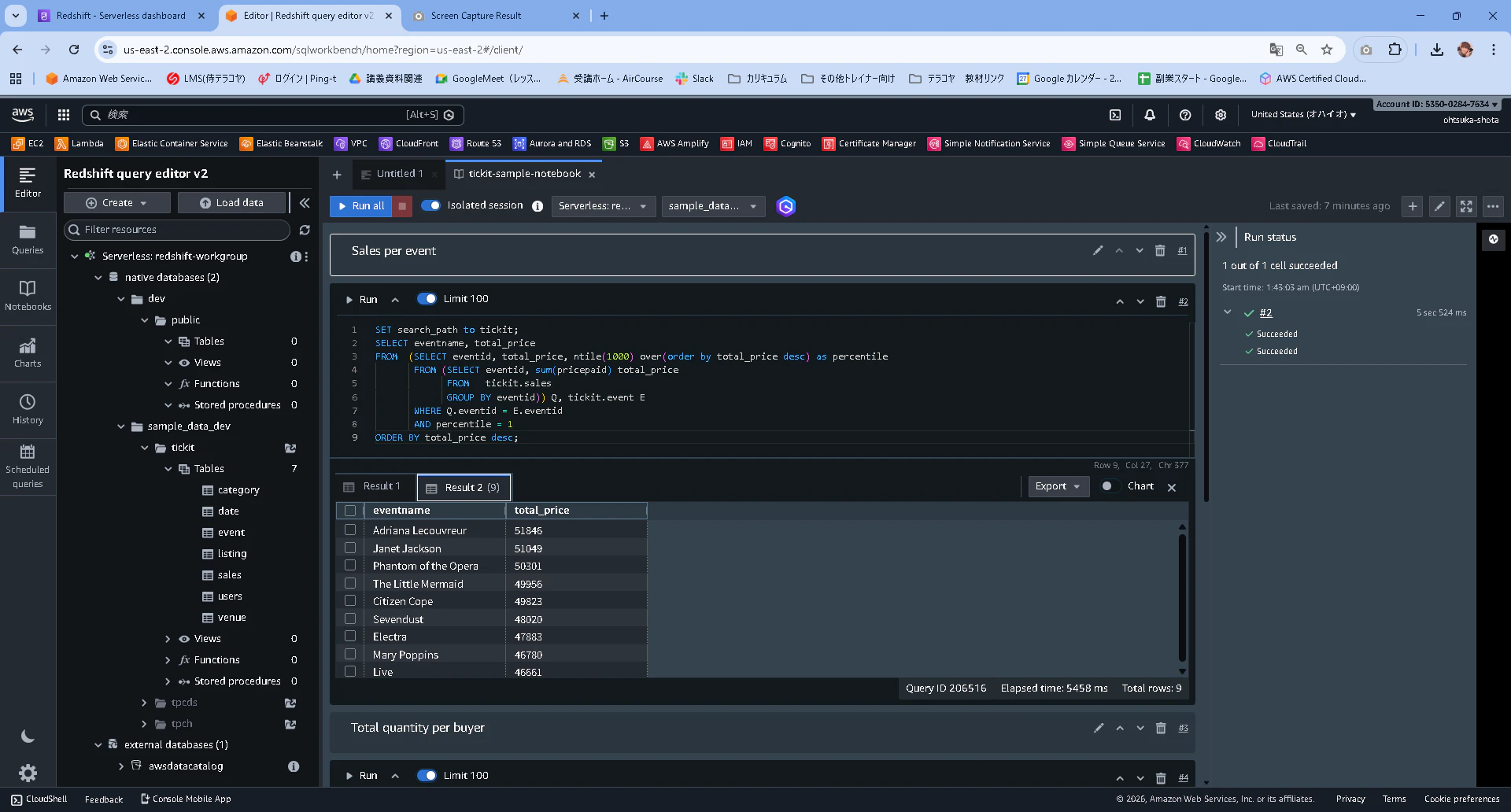

この時実行しているクエリはこれになります。AIにどんなクエリか確認したところ、以下の様でした。
イベント(event)ごとの売上合計(salesのpricepaid合計)を計算し、売上が特に大きいイベント(上位0.1%)だけを取り出して、イベント名と売上合計を降順で表示する、という意味です。
SET search_path to tickit;
SELECT eventname, total_price
FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM tickit.sales
GROUP BY eventid)) Q, tickit.event E
WHERE Q.eventid = E.eventid
AND percentile = 1
ORDER BY total_price desc;
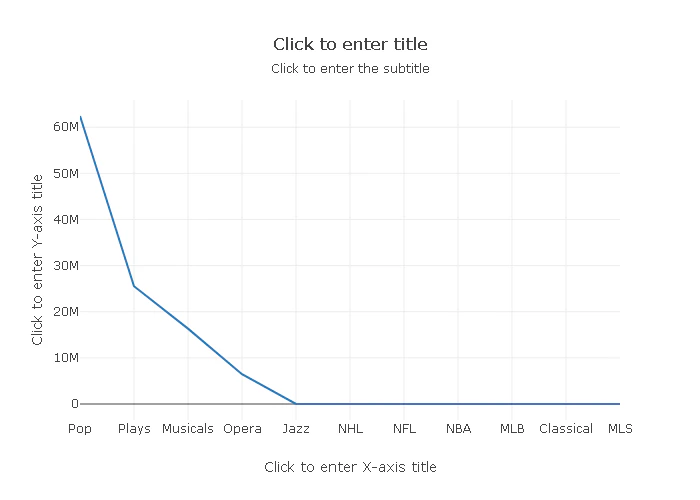
クエリの結果をそのままグラフにして出力することも出来ます。
クエリ結果の右側にあるChartを押下して
Type:Bar
X:eventname
Y:total_price
とすることでグラフ化することが可能です。
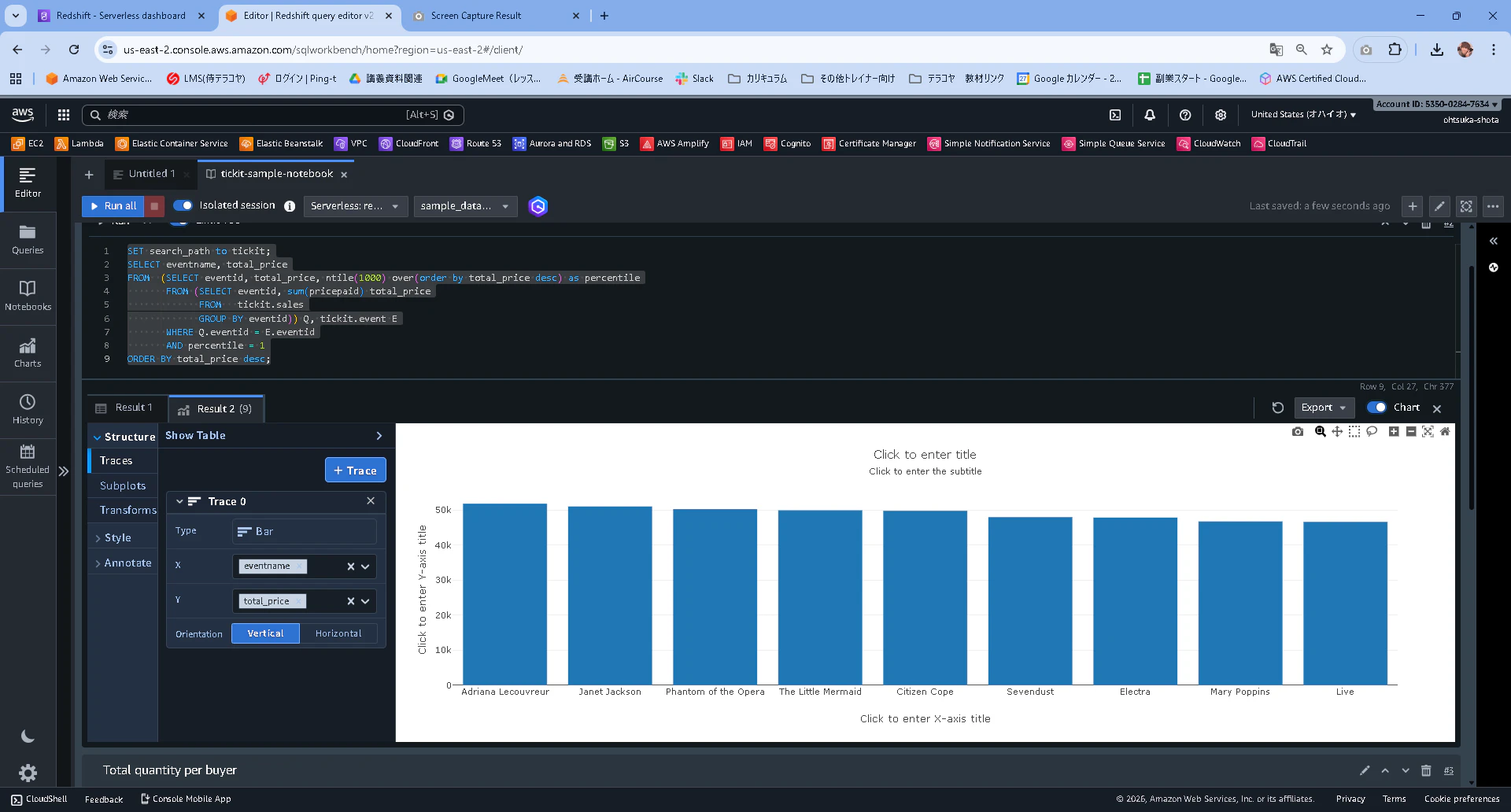
エクスポートしたグラフになります。
雑ですが。

データベーステーブルを見るとCategoryというものがあるので、カテゴリごとの売り上げも分析してみたいと思います。
まずCategoryテーブルにどんなデータが入っているかを、次のクエリで確認します。
最初に用意されていたUntitled 1というタブを開いて以下のクエリを入力します。
また、クエリ対象のデータベースをsampl_data_devとします。
SELECT catid, catgroup, catname
FROM tickit.category
ORDER BY catgroup, catname;
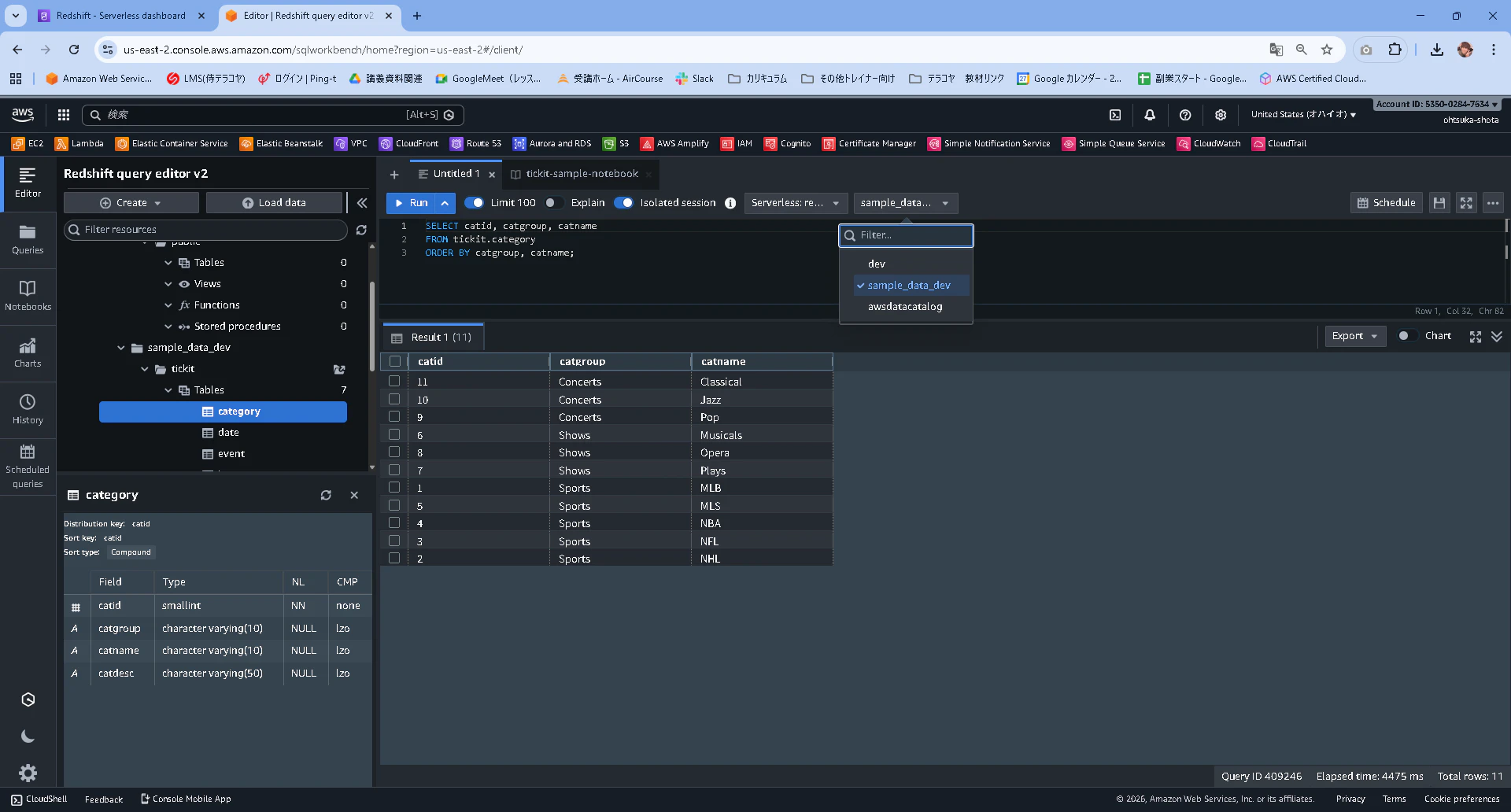
実行結果が以下となります。
どうやら、コンサートとスポーツに関してのカテゴリがあるようです。

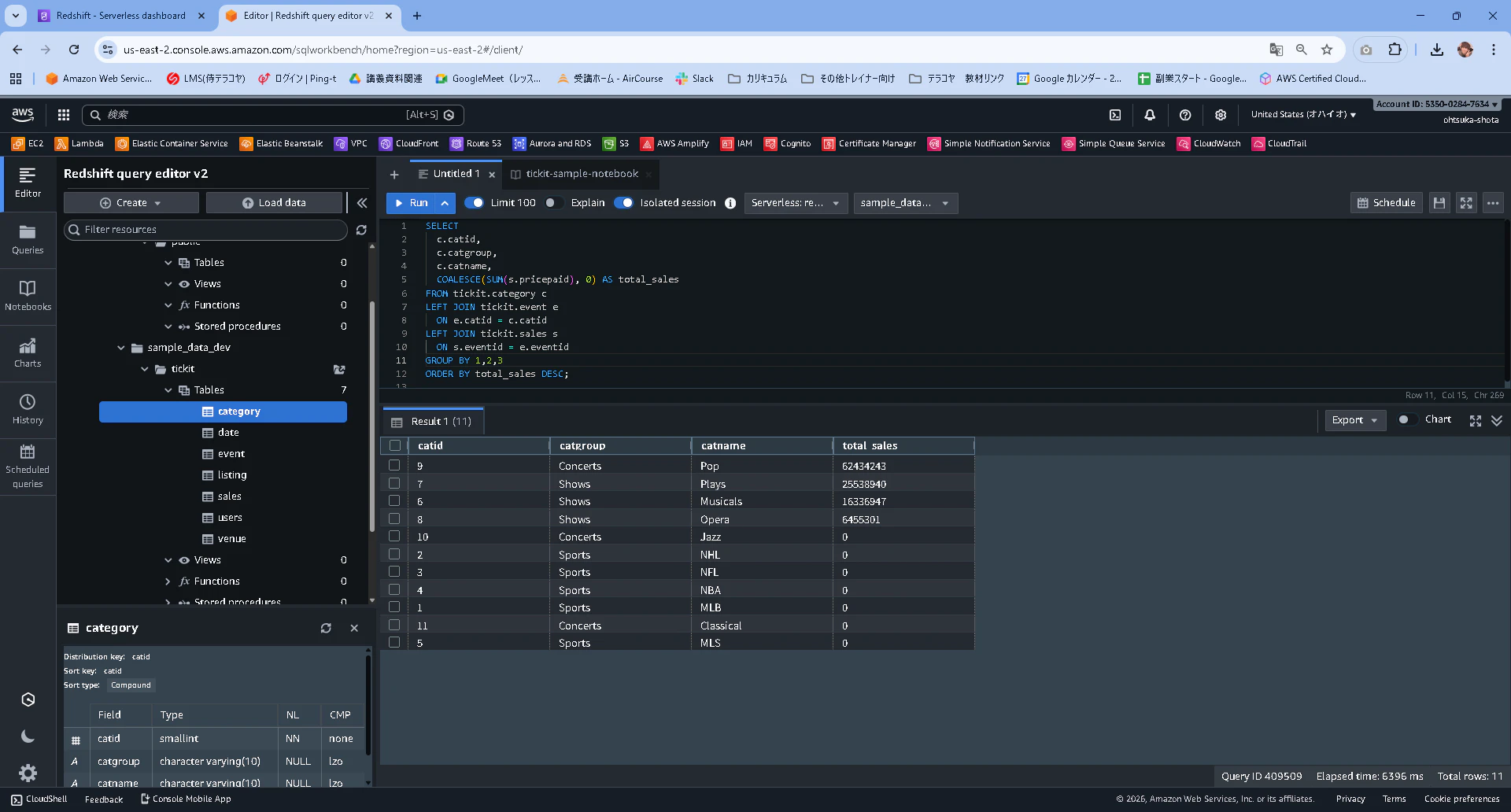
次に以下のクエリを入力して実行します。
SELECT
c.catid,
c.catgroup,
c.catname,
COALESCE(SUM(s.pricepaid), 0) AS total_sales
FROM tickit.category c
LEFT JOIN tickit.event e
ON e.catid = c.catid
LEFT JOIN tickit.sales s
ON s.eventid = e.eventid
GROUP BY 1,2,3
ORDER BY total_sales DESC;
実行結果が以下となります。
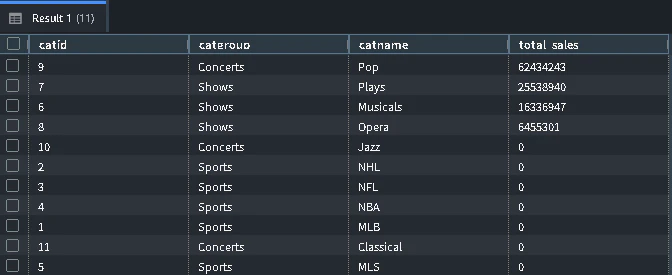
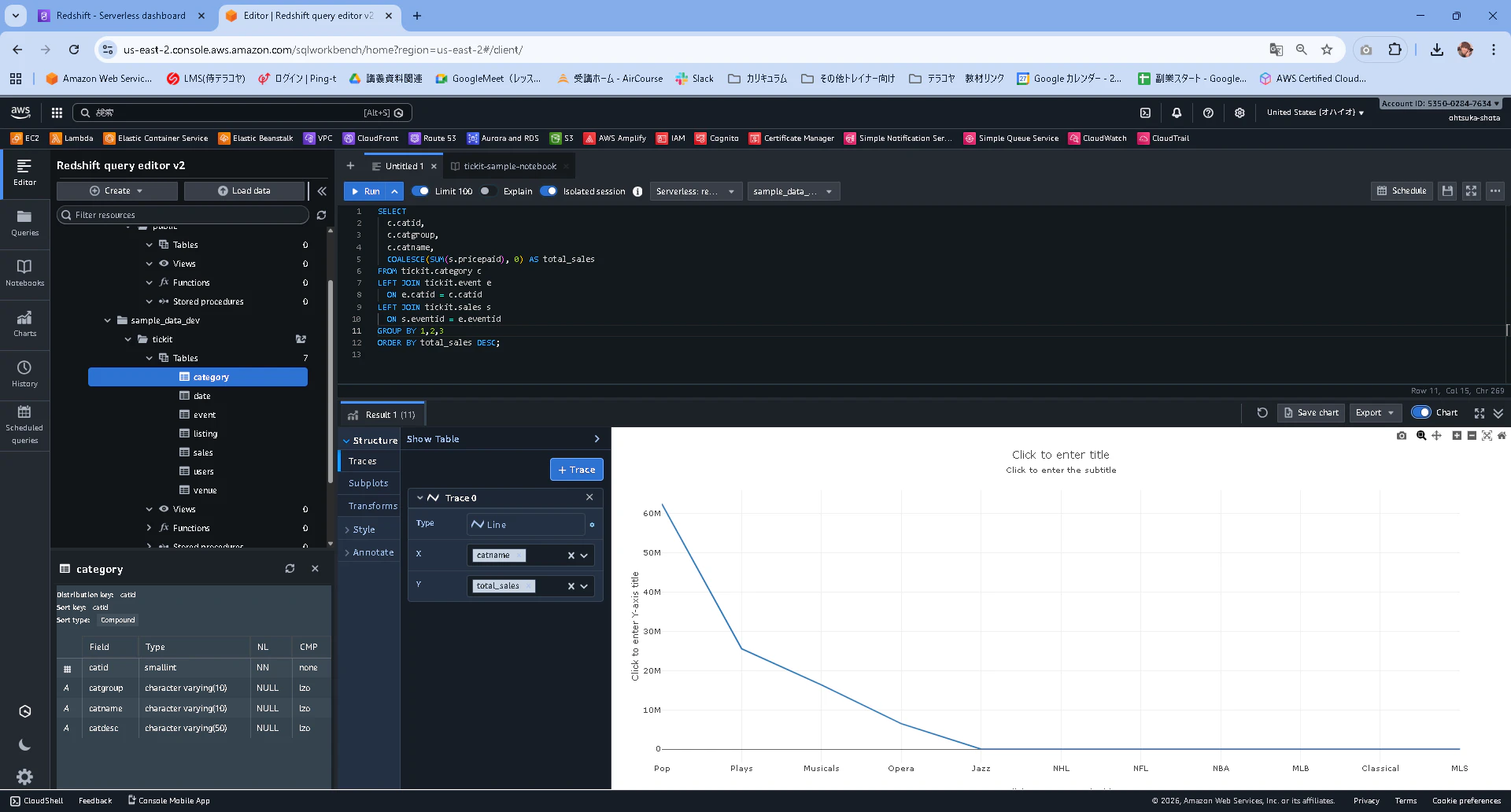
チャートに表してみます。
ハンズオン後
Redshiftで課金が発生しないようにNamespaceとWorkgroupの双方を削除しましょう。
Redshift Serverlessはストレージ料金(Namespace)とコンピュート料金(RPU)が別体系です。Namespaceを残しているとデータ量に応じて課金が続きます。またコンピュート料金はクエリ実行時に課金がされます。そのため学習用であれば使い終わったら削除するのが無難でしょう。
ワークグループの設定を押下して、存在しているWorkgroupを選択して、アクションから削除を選択します。
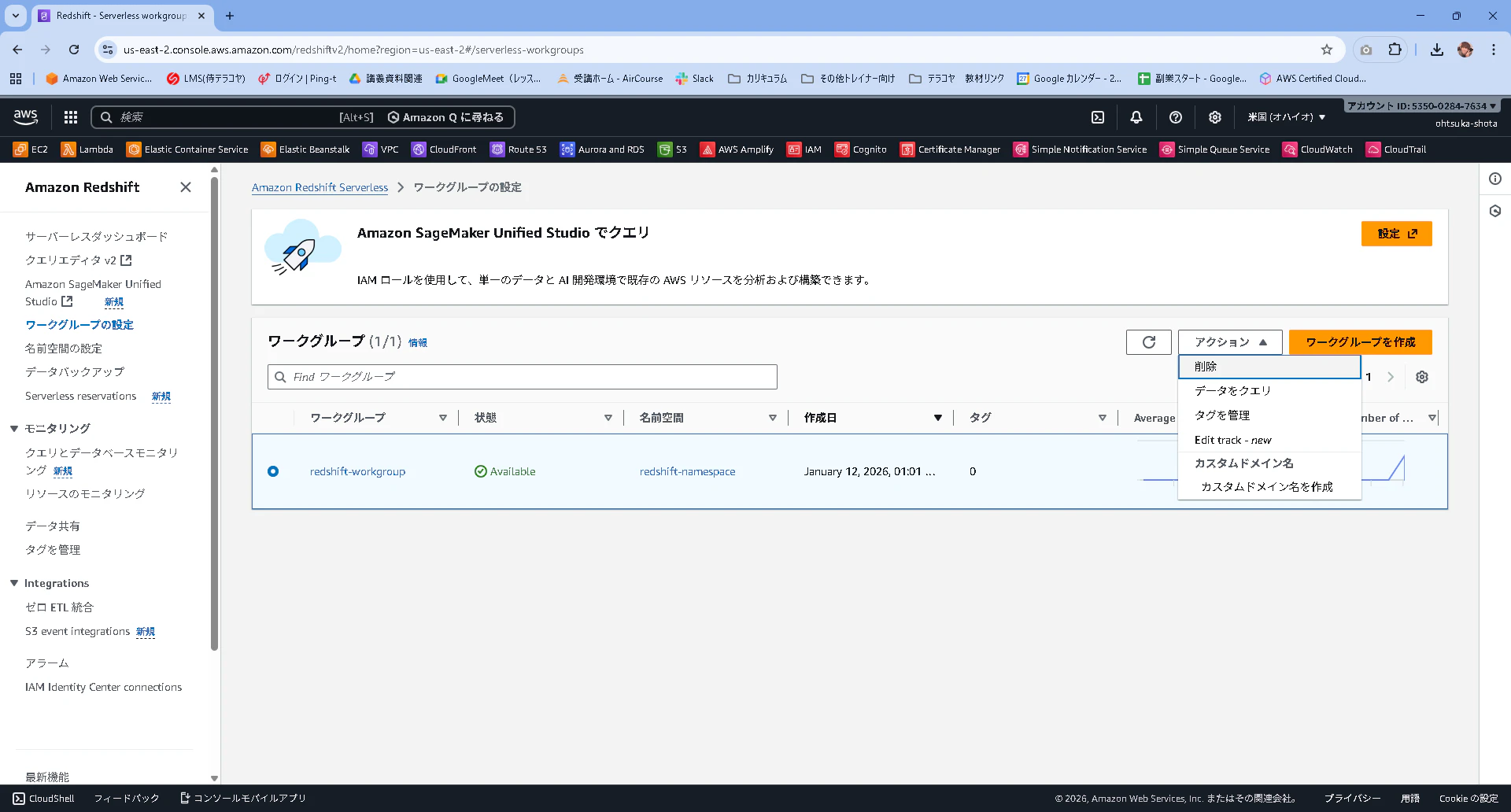
ワークグループの削除と、スナップショットの作成に入っているチェックを外して、削除と入力してボタンを押下します。

WorkgroupとNamespaceが一覧から消えていればOKです。DeletingになっていればOKでしょう。

