Are you Well-Architected ?
こんにちは(もしくはこんばんは?)AWS Well-Architected Framework の普及に貢献したいマン 大竹 です。
本記事はJapan APN Ambassador Advent Calendar 2020の24日目の記事となります。
はじめに
本記事は、アーキテクチャの設計やレビューをする時に個人的に大事にしている考え方をまとめたものです。
考え方を実践しやすくするために具体的な思考パターンとしてまとめたものではありますが、こちらのセッションで伝えきれなかったものを別な角度から補足するものでもあります。クラウドを理解する上では様々な観点があると思いますが、『アーキテクチャ設計』を軸に 1+5、つまり6つの視点でまとめてみました。
読者としては
アーキテクチャの設計スキルを磨きたい人で、AWS認定資格(アソシエイト以上)の資格を取得した人(または、これから取得しようとしている人)を想定していますので、入門レベルの説明は割愛または表現が雑になっています。ご容赦を m(_ _)m
ちなみに
AWS Well-Architected Frameworkは抽象度がやや高いので、これからアーキテクチャの設計スキルを磨きたい人には『AWSでアーキテクチャ設計を検討する上で知っておくべき10のこと(+1)』を入門用として激推します。
1+5 のWell-Architectedな思考パターンとは何か?
具体的な 1+5 の内訳としては以下の6つになります。
(1) Design for Failure
(2) リスクベースアプローチ
(3) マネージドサービスの活用
(4) ペットと家畜
(5) APIによる操作
(6) ファクトベースアプローチ
(1) はクラウドの性質をあらわした表現ですが、(2) 以降はクラウドとの付き合い方の心得とも言えるようなものです。そういった意味で6つの思考パターンをあえて 1+5 としました。
アーキテクチャ設計のベストプラクティス では11個の設計原則が紹介されており、いずれもクラウドをうまく活用する上で重要なプラクティスが具体的に記載されています。
- スケーラビリティを確保する
- 環境を自動化する
- 使い捨て可能なリソースを使用する
- コンポーネントを疎結合にする
- サーバではなくサービスで設計する
- 適切なデータベースソリューションを選択する
- 単一障害点を排除する
- コストを最適化する
- キャッシュを使用する
- すべてのレイヤーでセキュリティを確保する
- 増加するデータの管理
これら11個の設計ベストプラクティスと 1+5 の思考パターンをマッピングさせると下記のようになります。1+5 の思考パターンの習得は、設計ベストプラクティスをより深く理解し思考する上での一助となるはずです。

それでは 1+5 の思考パターンについて、具体的な説明をしていきたいと思います。
Design for Failure
過去にHAクラスタリングソフトウェアを開発していた経緯もあり、Design for Failre の考え方に非常に共感しています。
AWSのサービスであれ、自前のコンポーネントであれ、あらゆるモノについて『障害は発生する』という前提で設計を行うものです。クラウドサービスと付き合う上で非常に重要な概念ですが、実際にアーキテクチャを設計する時にはどのような検討をすべきでしょうか。個人的な思考パターンですが書き出してみました。
- 利用するAWSのサービスを全て列挙する(理想的にはアーキテクチャ図として表現できているとGood)
- サービスを1つ選択し、そのサービスがダウンしたと想定する(想定が難しければ妄想!Mo-So!)
- システム全体がどのように振る舞うのかを確認し、課題を抽出する
- 他のサービスを対象に 2)、3) を繰り返す
※AWS IAMなどリージョン縛りのないサービスにおいても障害が発生した場合のシナリオを考えておきましょう
これをやることによっていくつかシナリオが見えてくるかと思います。個人的には以下の3種類が基本シナリオだと思っています。
A) システムを継続して稼働させることが可能
B) システムを縮退して稼働させることが可能
C) システムを継続して稼働させることが不可能
議論をシンプルにするために、一旦 B) を除外しておくのはアリだと思います。兎にも角にも『このサービスがダウンしたら、このシステムはどうなっちゃうの!?』をいろんなパターンで考えることが重要です。
リスクベースアプローチ
セキュリティや各種障害のあらゆるリスクを洗い出し具体的な対策を検討するのが理想ですが、全てのリスクに対し完璧な対策を講じるのは現実的ではありません。まずはシステムと人(運用)に観点を絞ってリスクを洗い出すことが重要です。自分の場合、こんな感じで考えています。
<システム観点のリスク>
-
想定されるリスクを全て列挙する(机上レベルで考えられるものはとりあえず列挙しておく)
-
リスクの顕在化が現実的なものをピックアップする
-
ピックアップしたものを対象に、リスクの顕在化をどうやって検知できるのか検討する
-
2)でピックアップされなかったもの(リスクの顕在化が非現実的なもの)に対し、対処策を検討する
-
は 3)と同様にリスクの顕在化をどうやって検知できるのかを検討したり、リスクを許容し『何もしない』など、ピックアップされなかったものに対する対応方針を決めたりします。
システムに対して『Design for Failure』の考え方が適用できますが、人(運用)観点の場合は『ヒューマンエラー』と『性悪説』の考え方を適用します。特にセキュリティ観点では性悪説で物事を考えることで様々なリスクを検討することができます。
結果的に様々なリスクを検討することになるのですが、私のオススメは『最も重篤なインシデントの発生について検証してみる(検証というか、想像もしくは妄想するところから?)』です。インシデントが発生したことをどうやって検知するのか、検知したことはどうやって運用チームに通知されるのか、初動の対処として運用チームがやるべきことは何か、エスカレーションは誰まで上げるのか、等を検証(想像)してみることです。検討を進めるほど考慮すべき様々な観点が出てくるかと思いますが、ポイントは『最も重篤なインシデント』で考えてみる(想像してみる)ことです。このレベルで検討ができていれば、他のものは対応のレベル感が下がるだけなので、まずは最悪のケースを想定して検討してみるというのは非常に効果的です。
マネージドサービスの活用
AWSのメリットをどれだけ享受できるかは、AWSのマネージドサービスをどれだけうまく活用できているかにかかっていると言っても過言ではありません。とは言え、どんな状況でもマネージドサービスを使うのが正解ではありません。新規にシステムを開発する場合と、既存のシステムを移行する場合とでは勝手が違います。まずは新規にシステムを開発する場合について、具体的な例を見ていきましょう。
<新規にシステムを開発する場合>
- アプリケーションのコアロジックを実行するサービスを検討する
→ Amazon EC2、AWS Lambda、Amazon ECS(またはEKS) などコンピュート系サービスから選ぶのが王道 - システムの機能要件を最低限満たすためにはどのサービスが必要なのか検討する
- 非機能要件も考慮した上で追加すべきサービスをピックアップし、目指すべきアーキテクチャ構成を検討する
この時点で出来上がるアーキテクチャ構成は『マネージサービスをフル活用した際の理想形(ゴール)』のようなものです。このゴールをそのまま目指すのもひとつの戦略ですが、実際問題としてプロジェクトの予算やスケジュール、それにチームメンバのスキルなどを考慮したゴールの設定をしておかないと大変なことになってしまいます。どれくらい大変な事態になるのかはご想像にお任せしますが、スケジュールとチームメンバの保有するスキルを加味した上で、いくつかのマネージサービスの採用を見送る、または実現可能な手段への代替を検討することで、リスクの軽減を図ることが重要です。
次は既存のシステムを移行する場合について見てみましょう。
<既存のシステムを移行する場合>
- マネージドサービスを極力使用せずに既存のシステムをAWS上に移行した場合のアーキテクチャ構成を検討する
(リフト&シフトにおける『単純リフト』に相当します) - 機能的にマネージサービスに置き換えることでメリットがあるものがないか検討する
- 更にマネージサービスを追加することで既存課題の解決など、何らかの改善ができないかを検討する
(リフト&シフトにおける『シフト』に相当します)
前述の新規にシステムを開発する場合と同じく、スケジュールとチームメンバの保有するスキルを加味した上で、無理のないアーキテクチャ構成にブラッシュアップしていくことがポイントです。
ペットと家畜(Pets vs Cattle)
こちらのスライドが有名で猫の可愛さに『オンプレ回帰もアリかな』と考えてしまうほどですが、クラウドであっても猫と仲良くなる方法はあります。
話がおかしな方向に行きそうなので戻します。
『ペットと家畜』はオンプレミスのITリソースをペット、クラウドのITリソースを家畜に例えた表現ですが、とても雑な言い方をすると『使い捨て可能なITリソースはバンバン使い捨てる』というプラクティスを端的に表現したものです。この『使い捨て可能なITリソース』のわかりやすい例がAmazon EC2のインスタンスです。AWS Management Console からマウスでポチポチするとあっという間にWindows Serverなどのインスタンスがデプロイされます。不要になれば同じくボタンをポチッとするだけで削除完了です。とても便利です。非常に極端な例ですが、デプロイされたインスタンスのOSのアップデートも定期的に実施する必要はなく、アップデートが適用された新しいAMIを使って都度デプロイすることで最新の状態を保つことが可能です。ここまでやるかどうかはさておき、使い捨て可能な状態にしておくのはメリットがあるのでチャレンジしておきたいところです。では、具体的にどうやって使い捨て可能な状態にするのか見ていきましょう。Amazon EC2のインスタンスを題材に記載していますが、他のサービスを利用する場合でも考え方は同じです。
<インスタンスを使い捨て可能にする>
- ユーザーデータとコンフィグレーションをシステム領域から切り離す
→ OSイメージが格納されているEBSボリュームとは別なストレージサービス(追加のEBSボリュームなど)に格納する - ユーザーデータやコンフィグレーションがインスタンス間で共有する必要があるものであれば、Amazon EFSなどの利用を検討する
- OSやアプリケーション、ユーザーデータ、コンフィグレーションなど、それぞれどの単位で管理するのが最適なのか検討する(必要に応じてOS領域とアプリケーション領域の分離も検討する)
APIによる操作
AWSのサービスをManagement Consoleから利用しようとも、AWS CLIから利用しようとも本質的にはAWSのAPIをコールしているに過ぎません。SDKを使ってアプリケーションと連携させるにしても、結局はAPIをコールしているだけです。操作の手段によって様々な見え方があるかも知れませんが、本質的なところはAPIです。クラウドサービスは『APIの集合体』であり、サービスの制御はAPIコールで実現できることを理解しておきましょう。AWS Management Consoleで行っている手動操作の自動化を検討する際、全ての操作はAWS CLIなどで再現可能なことを理解していれば、自動化なんて楽勝ですね(言い過ぎ)。
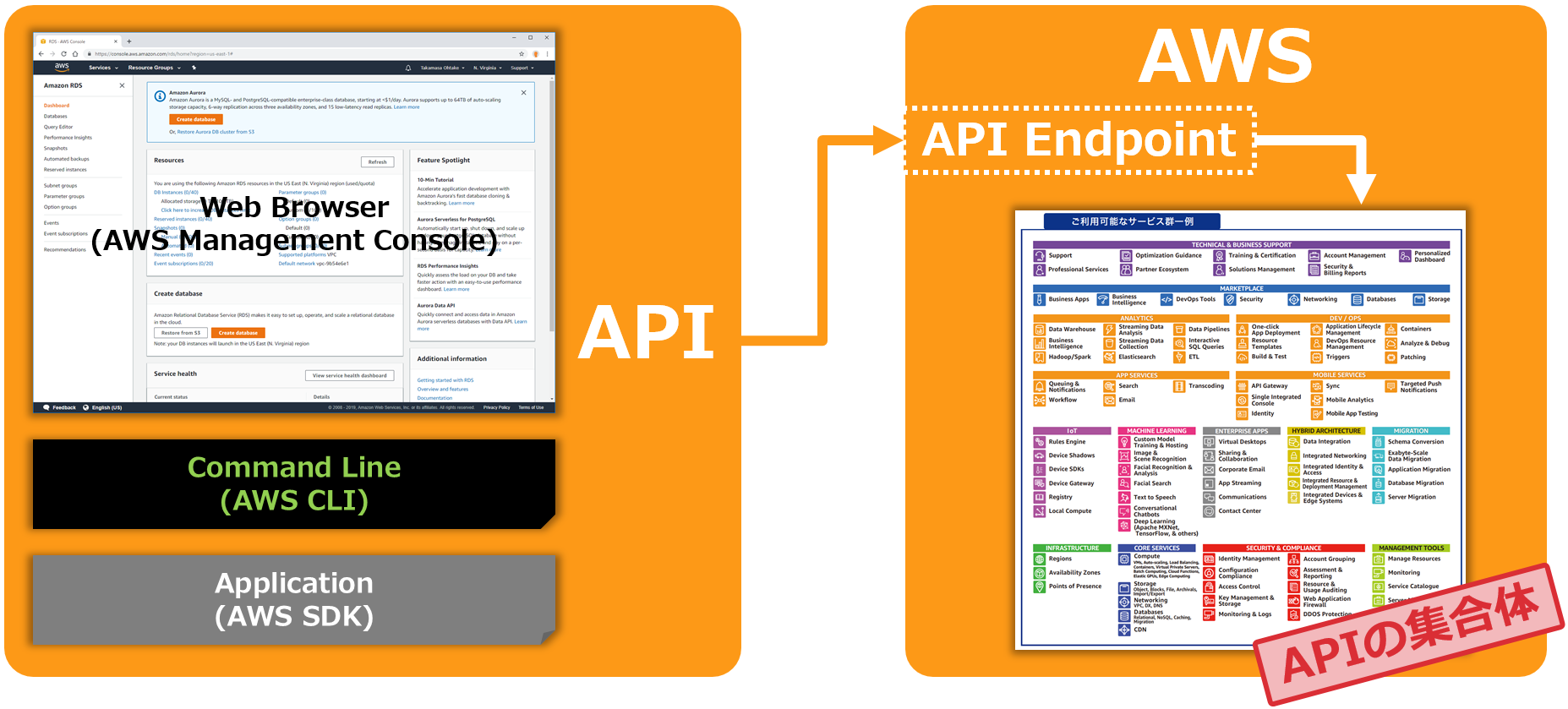
APIを意識することが非常に有効なシーンのひとつとしてIAMポリシーの設計があります。運用プロセスを設計する際に運用者に与えるべき最小の権限とは何かを検討する際にAPIを意識することが非常に効果的です。では、具体的に見ていきましょう。
<特定の操作に絞った権限の付与>
- AWS Management Console上での操作を定義する
- 定義した操作をAWS CLIで再現する
- 再現したAWS CLIのコマンドラインオプションから許可すべきAPIをピックアップする
→ 具体的なAPIは、AWS Management ConsoleのIAMのポリシー作成画面などで確認すると簡単です。 - AWS CLIを実行し、APIコールの結果が 3) で期待通りであることを AWS CloudTrail で確認する
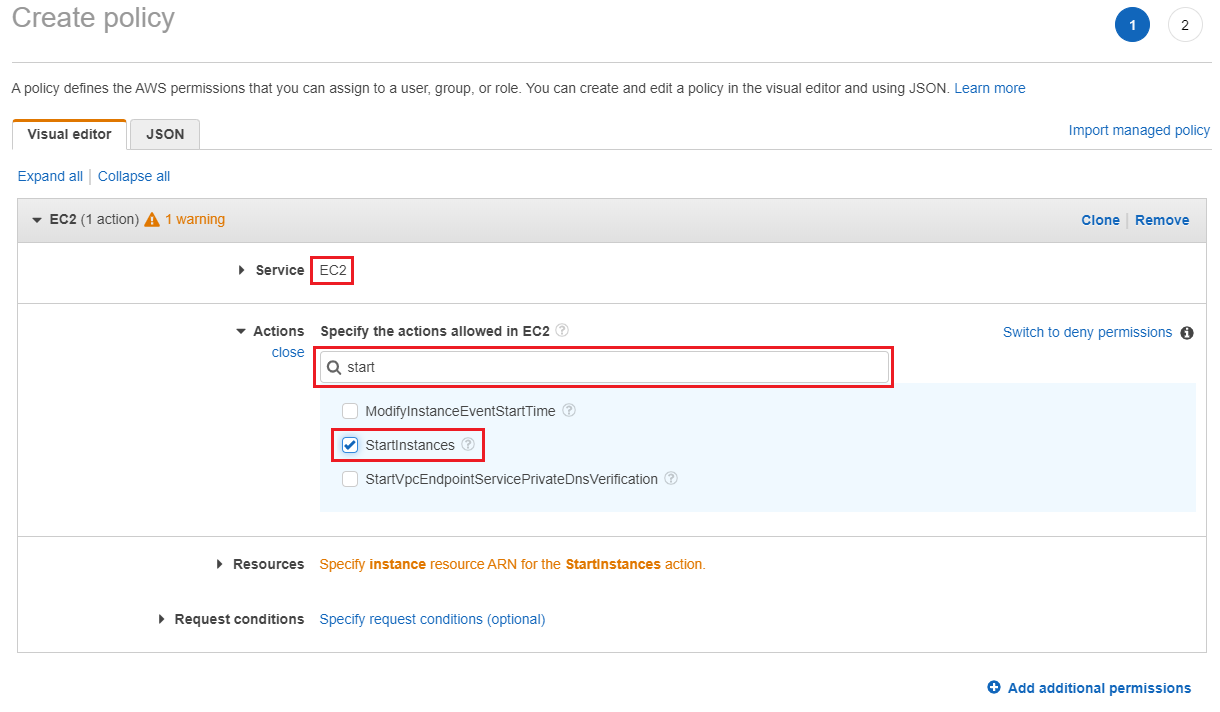
<補足:IAMポリシーの作成画面でAPIの具体的なアクションを確認する>
AWS CLIのコマンドラインオプションから具体的なAPIは比較的簡単に類推することが可能です。例えばインスタンスの起動であれば以下のようなコマンドラインになります。
# aws ec2 start-instances --instance-ids i-1234567890abcdef0
AWS CLIの細かい説明はこちらに譲るとして、上記コマンドラインの1つ目のオプション(command)が ec2、2つ目のオプション(subcommand)が start-instances になります。
AWS Management Console のAWS IAMのポリシー作成画面にてサービスを選択し、検索ボックスに subcommand の一部を入力するとそれっぽいアクションを見つかると思います。(ハイフンの有無などは気にしないでおきましょう)
ファクトベースアプローチ
これは思考パターンと言うより、心構えに近いものです。何か障害や意図しない事象が発生した際、即『AWSのサービス側に問題があるのではないか?』と疑いがちです。ただ経験上そんなことは稀で、自分が設定したパラメータやソースコードに問題があることの方が多いので、まずはしっかりと事実確認をしましょうという戒めを込めたものです。また、AWSを継続的に利用していていく上で、コストやパフォーマンスなど何らかの改善を図っていくことが多いと思いますが、その場合においても事実(実績値)を元にした改善を行うことが非常に大切です。
『事実で語れ!』ってやつですね、ハイ。
まとめ
個人的な『Well-Architectedを意識した 1+5 の思考パターン』を紹介してみました。経験からくる私見をまとめてみたら6つになったというだけで、今後これが変わるかも知れません。『アーキテクチャ設計における10年後も変わらない思考パターン』を生み出すくらいの境地にたどり着きたいものですが、まだまだ修行が足りないようです。新たな発見があった際にはまた脳内ダンプをして、ブログの神様が降臨するのを待ってみたいと思います。
(単に腰が重いだけ?)
またどこかでお会いしましょう。
ではでは。|彡サッ
おまけ
技術バックグラウンドや現在担当している業務領域がどんな方であれ、アーキテクチャの設計原則を学ぶ人には等しくセキュリティの意識を高めて欲しいと常々思っているので、こちらのセッションも是非どうぞ。
また、アーキテクチャ設計のベストプラクティス 11原則 と AWS Well-Architected Framework の違いを人生に例えて説明しようと思ったのですが、それはまた別の機会にしたいと思います。