本記事は 機械学習工学 / MLSE Advent Calendar 2018 10日目の記事です。
最近、機械学習システムの信頼性と、その元となる不確実性を整理した論文を紹介していただいて、面白かったので、概要を自分なりにまとめた上で、考察を加えたいと思います。考察は微妙です。
| タイトル | Towards a Framework to Manage Perceptual Uncertainty for Safe Automated Driving |
|---|---|
| 著者 | Krzysztof Czarnecki and Rick Salay |
| 関連資料 | WAISE2018のスライド |
| 概要 | 自動運転における状況認識タスク(歩行者の検知、教師あり学習)を題材に、パーセプション・トライアングル (Perception Triangle) というモデルを提案し、それをもとに知覚的不確実性 (perceptual uncertainty) を整理しています |
機械学習応用システムの品質保証と不確実性
機械学習応用システム(内部で機械学習を利用しているシステム)と従来のシステムの一番の違いは、データでシステムの振る舞いが決まる点です。例えば、従来のシステムに "パンダ" を学習させるには、まず目があって、口があって、耳があって、目の周りが黒くてその周りは白くて、、、目の定義は、白目が、、、とすべてのルールを人がコーディングする必要がありました。システムの挙動はコードによって決められます。
一方機械学習応用システムでは、大量のパンダの画像とパンダ以外の画像を与えることで、パンダであるという判断をするためのルールを自動的に生成します。システムの挙動はコードとデータによって決められます。機械学習とは、データでコーディングすることである、と言う人もいますし、従来の方法が演繹的であり、機械学習応用システムは帰納的であるという人もいます。
なんにせよ、コードで挙動を制御できる従来のシステムと比較して、機械学習システムには不確定要素が多数含まれてしまいます。この不確実性が、自動運転のような安全性が重要なタスクに機械学習を利用することの壁となってしまいます。そのため、そのようなシステムでは、どのような不確実性があるのかをしっかりと整理し、対策をうっておく必要があります。今回読んだ論文では、パーセプション・トライアングルと呼ばれるツールを導入して、そういった不確実性とその要因を整理しています。
パーセプション・トライアングル
まず最初に、論文の主題の1つである、パーセプション・トライアングルについて解説します。パーセプション・トライアングルとは、意味論・記号論で用いられる semiotic triangle に着想を得て作られた、知覚のモデルです。と、言葉で書いてもわかりませんが、図をみていただくと簡単に理解できます。
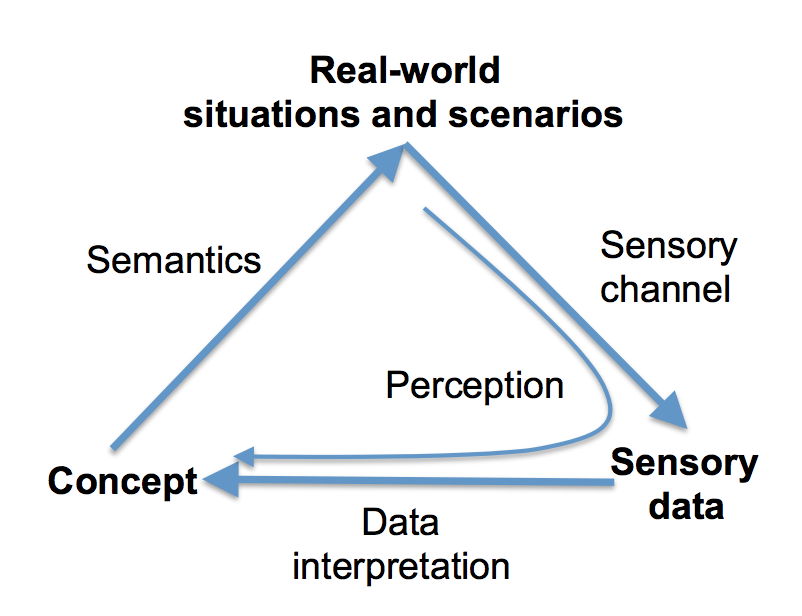
パーセプション・トライアングルは、概念と実世界のシーン・シナリオと感覚データ(センサーデータ)の関係を表しています。例えば「歩行者とは、車に乗っていない、道に立っている人間」という定義が概念に対応します。歩行者が実際にいるかどうかは、カメラやライダーなどのセンサーなど(Sensoy channel)で観測されたデータ(Sensory data)を解釈する(Data interpretation)ことで、認識(Perception)されます。概念から実世界のシーン・シナリオへの矢印は、その概念をあらわす実際のものへの対応をあらわしています。
より具体的に、教師あり学習をつかって歩行者検出をする場合の例が下図です。
実際に歩行者がいるとして、カメラやライダーなどのセンサで観測可能な情報から、歩行者(どういう状態かを含む)を認識します。実際に歩行者がいるという意味で、真の状態があるので、認識した値とのズレを計算することができます。

はじめの図と2つめの図で、概念と実世界のシーンやシナリオとの矢印の向きがしれっと逆になっています。はじめの図では、興味のある概念をすべて含むシーンやシナリオをあらわしていて(つまり、興味の対象となる概念を決めると、それを定義するの必要なシーンやシナリオがきまる)、2つめの図では、個別のシーンを表しています(シーンが与えられて、そこから興味の対象を認識する)。たぶん。
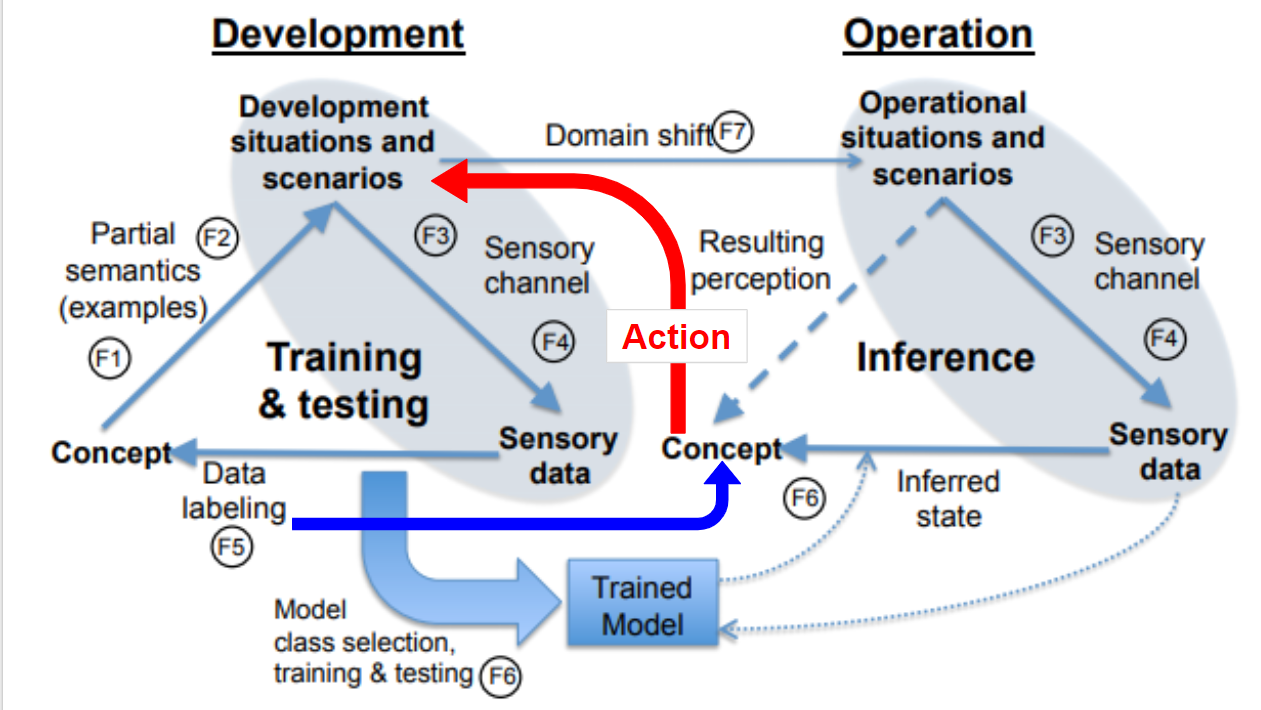
開発時と運用時の分離
機械学習には、データからモデルを最適化する訓練フェーズと訓練されたモデルを利用する推論フェーズがあるので、パーセプション・トライアングルは、それぞれのフェーズで描くことができます。論文では、開発時(Development)と運用時(Operation)という言い方をしています。

開発時には、まず認識したいもの(=概念)があり、それをもとに様々なシーンやシナリオを用意します。そして、センサーデータと別途用意した正解ラベルから、訓練を実施し、訓練済モデルが生成されます。運用時には、与えられた(特定の)シーンに対して、センサーでセンシングし、訓練済モデルを使って、興味のある概念を推定します。開発時と運用時で、それぞれ先の1つめと2つめのトライアングル(概念とシーンとの矢印が逆)になっています。また、開発時と運用時でシーンやシナリオが全く同じということはありえないので、矢印を引いてあります。
7種類の不確実性
さて、開発時と運用時のパーセプション・トライアングルの関係が明確になったので、あとはそれぞれの項目に不確実性があるか、ある場合は、その要因は何で、どのように対処すべきかを検討します。論文では、7つの不確実性をあげています。
-
Conceptual Uncertainty (F1)
- そもそもコンセプトに含まれる不確実性
- 例えば、歩いている人、自転車を押している人、自転車に乗っている人のどこまでを歩行者とするかなど、コンセプトが一意に決まりません。また、この不確実性は、どのような状況やシーンを学習時に考慮するか、開発者の判断にも影響を与え、次の F2 の要因の一つとなりますし、正解ラベルが不正確になるという意味で、F5にも影響を与えます。
- 有識者のレビューやラベルの不一致率などをつかって把握できます
-
Development Scenario Coverage (F2)
- コンセプトを記述するのに必要なパターンを網羅できているか
- 路上に寝そべっているひと、変な洋服を着ている人のように、興味のある概念の状態を全て想定して、それを含むシーンを全て洗い出すのは実質的に不可能です。これは、モデルの精度が落ちる原因となります。
- F1と異なり、未知の未知(Unknown Unknowns)となるようなもので、なかなか難しい問題です。

-
Situation or scenario uncertainty (F3)
- センシングが難しい状況おなることで発生する不確実性
- 例えば、人が木に隠れてしまったり、濃霧のせいで前が見えないような状況を指します。
- この不確実性がどれくらいのインパクトを与えるか、テスト時にしっかりと確認する必要があります。
-
Sensor properties (F4)
- カメラやライダーなどのセンサーの個体差や設定値のブレによる不確実性
- ダイナミックレンジ、解像度、ノイズ特性、キャリブレーション状況の違いなどによる不確実性です。
- 既知の手法をつかって、センサーに対する要求を明確にすることができるので、訓練済モデルごとに、きちんと評価すべきです
-
Labeling uncertainty (F5)
- 正解ラベルについての不確実性
- 例えば、人間がラベルを作成する際にミスをしてしまったり、概念の定義があいまいで、ラベリングがぶれてしまうような状況を指します。
- この不確実性は、計測もできるし減らす手法も存在しています。(F1と同様)
-
Model uncertainty (F6)
- モデル自身の不確実性
- 機械学習なので、モデルが100%正しいということはありません。
- 運用時に信頼度を計算することなどで、ある程度把握することができますが、訓練データやアルゴリズムを変えて、モデルの弱点を補っていくような工夫が考えられます。
-
Operational domain uncertainty (F7)
- 運用時のドメインの不確実性
- 例えば、運用で遭遇するシーンが訓練時に想定したシーンか、センサーが運用時もきちんと設定されているかなど、訓練時と運用時の違いの不確実性です
- 訓練時のデータと運用時のデータが似ているか、チェックし続けるなどの対処方法が考えられます
パーセプション・トライアングルを他のタスクにあてはめてみる
論文では、パーセプション・トライアングルをつかって、自動運転における物体検出タスクを教師あり学習によって行う場合に限定して、不確実性の整理をしていました。また、目的はあくまでセーフティです。
不確実性は、セーフティ以外でも重要な概念だと思いますし、他のタスクでもこういった整理ができるのであれば、いろいろうれしそうです。そこで、機械学習応用システムの例をいくつか挙げて、不確実性の整理にパーセプション・トライアングルが使えるか考え手みようと思います。
対象タスクは以下の6つとします。
- 画像分類
- 教師あり学習(自動運転以外の教師あり学習の事例)
- 想定する事例: オークションサイトで、ユーザーが写真をアップロードすると、自動的に品物の種類や価格を推定してくれる
- 異常検知
- 教師なし学習(訓練データの用意が難しいため教師なし学習となるが、ラベルは明確に決まっている)
- 想定する事例: 食品工場で、ラインを流れてくる原料を常時異常検知し続けるシステム
- クラスタリング
- 教師なし学習(正解ラベルが不明なもの)
- 想定する事例: ECサイトで、ユーザーを行動履歴からクラスタリングして、施策を出し分ける
- レコメンデーション
- 教師あり学習(開発時の目的関数と運用時の目的が異なる)
※ 過去データでは、レコメンドしたことで購入につながったのか、レコメンドしなくても購入したのかがわからないので、別の目的関数(例えば、単純な購買確率)を設定する必要がある - 想定する事例: ECサイトで、閲覧履歴と購買履歴から、購入しそうな商品をレコメンドする
- 教師あり学習(開発時の目的関数と運用時の目的が異なる)
- 強化学習
- 強化学習(環境と相互作用しながら訓練を進める)
- 想定する事例: 最適経路探索
- 対話システム
- 教師あり学習
- 想定する事例: ルールベースのものではなく、機械学習で文を生成するMicrosoftのTAYのように、ユーザーとの対話のなかで、自動的に訓練されていくもの
それぞれのタスクにおける パーセプショント・ライアングル
まずは、それぞれのタスクをそもそもパーセプション・トライアングルに埋め込むことができるかを見てみます
- 画像分類
- Concept: 品物の種類や想定価格
- Real-World: 実際の品物や、サイトでの適正価格
- Sensory-data: ユーザーの撮った写真
- ラベル: ユーザーの人手による付与
- 異常検知
- Concept: 不良箇所(の有無)
- Real-World: 工場のラインを食品が流れている状況
- Sensory-data: 食品原料の写真やセンシングデータ
- ラベル: なし(訓練データの用意が難しいため教師なし学習)
- クラスタリング
- Concept: 各ユーザーのクラスタ
- Real-World: ユーザーの状況や行動
- Sensory-data: ユーザーの行動履歴
- ラベル: なし
- レコメンデーション
- Concept: 各ユーザーの「おすすめしてほしいもの」
- Real-World: ユーザーが欲しいものを探している状況
- Sensory-data: ユーザーの行動履歴
- ラベル: 閲覧履歴と購買履歴
- 強化学習
- Concept: 次に取るべき行動 (?)
- Real-World: その状況
- Sensory-data: 各拠点間の距離
- ラベル: 適正に設定された報酬
- 対話システム
- Concept: ユーザーに伝えたい内容 (?)
- Real-World: 対話している状況
- Sensory-data: ユーザーの発話内容を音声認識した結果と、ユーザーに伝えたい内容(?)
- ラベル: なし (?)
パーセプション・トライアングルは、そもそも認知タスクを想定したものなので、レコメンデーション、強化学習、対話システムを当てはめるのは、無理がありますね。ただし、例えば強化学習では、「エージェント」が「環境」を「観測」して意思決定をするので、Concept を Action に変えれば、割とすんなり受け入れられるかも。
それぞれのタスクにおける パーセプション・トライアングル x 2
パーセプション・トライアングルへの埋め込みが厳しそうなタスクもありますが、そのまま進んで自動運転のときと同様に、開発時と運用時に分けて見ていきましょう
-
画像分類
- 基本的に自動運転のままで良さそうです。
- スマホのカメラで商品(Real Stuation)を撮影(Sensory Data)したユーザーに、商品名(Concept)を提示するのが運用時、間違えた場合はユーザーに修正してもらって(Labeling data)、撮影データ(Sensory Data)と一緒に保存しておき、モデルを訓練し直すのが開発時です
-
異常検知
- 教師なし学習を想定しているので、基本的には自動運転のままで良さそうです。ただし、F6でtestingするためには、検証用の正解ラベルが必要であることに注意が必要です。(もちろん、十分な正解ラベルが入手できるのであれば、教師あり学習を行うこともできます。)
- 今回の例では、不良品の発見を完全に自動化してしまうと、人手による正解ラベルの付与ができません。そのため、未知の未知が発生してしまいまう可能性があります。
-
クラスタリング
- 異常検知と同じく、教師なし学習であり、正解クラスタ、というものが存在しません。そのため、モデルのテストが困難になる可能性があります。(F6: モデルの不確実性 に含めてもよいかもしれない)
- トライアングル自体は、自動運転と同じで良さそうです。
-
レコメンデーション
- レコメンデーションでは、開発時に「レコメンドしたことで商品を購入したのか、レコメンドしなくても購入したのかどうかがわからない」という問題があります。そこで、レコメンドの有無を無視した購買確率を推定するモデルをつくるのが一般的です。(協調フィルタリングも同じ)。そのため、開発時と運用時では、指標が異なります。よって、データの Domain Shift を考えたのと同様に、評価指標のシフトも考慮に入れたほうが良いかもしれません。
- また、レコメンドによってユーザーの行動を制御しているので、訓練済モデルによって得られるデータが変わります。たとえば、人気商品ばかりをレコメンドするモデルを使うと、みんなが人気商品を見に行くようになり、それ以外の商品のデータが集まらなくなります。そのため、訓練済モデルから開発時のReal-World への矢印を加える必要もありそうです。
図にするとなんかごちゃごちゃしちゃったけど、暗黙のフィードバックループ感がある図にはなった
-
強化学習
- 強化学習では、運用しながらモデルを更新していくため、開発時と運用時のトライアングルがかさなると思われるかもしれませんが、強化学習はあくまでモデルの最適化方法の一種なので、そういうわけではありません。よくやられているのは、事前にシミュレーションで大量のデータをつかって訓練しておき、運用時には強化学習は利用しない方法です。
- そのため、強化学習でも、パーセプション・トライアングルは大筋変わらないように思います。ただし、そもそも認知タスクではないので、パーセプション・トライアングルを無理やり当てはめるのはどうよ、というのお、レコメンドと同様、モデルが行動を決定し、行動によって状況が変わるため、追加の矢印が必要そうです。
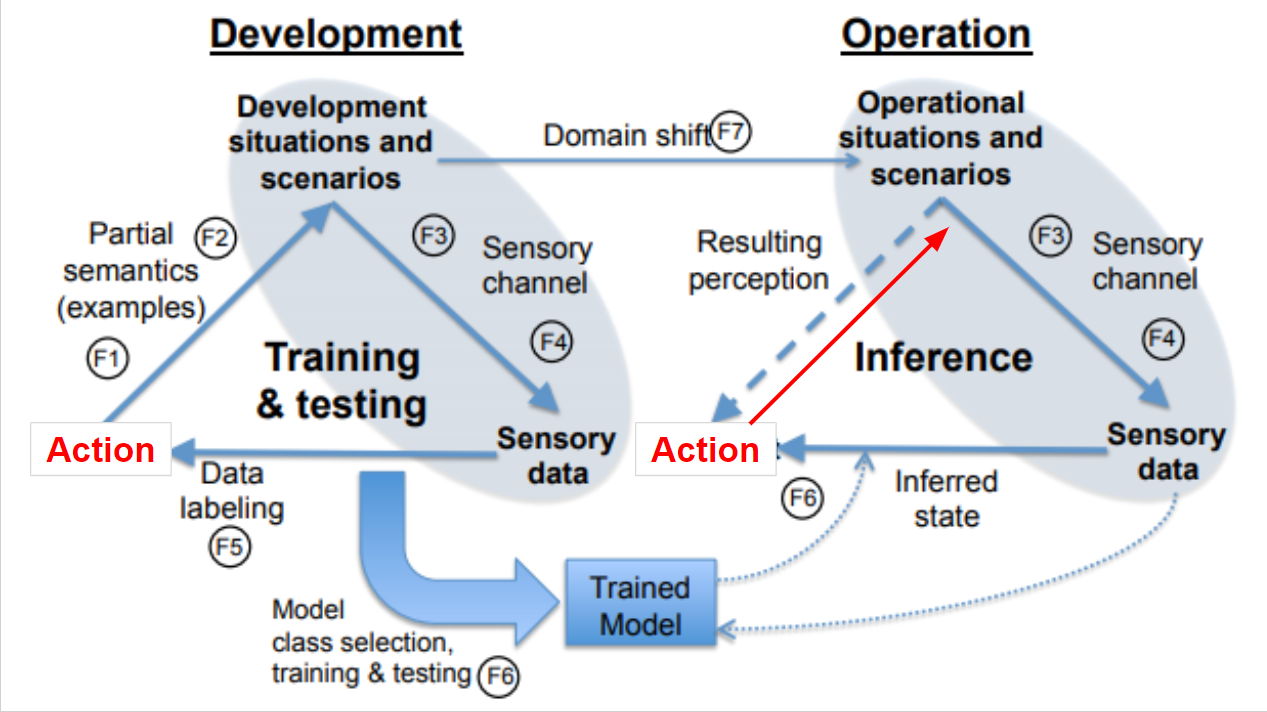
この図は、こんなんでいいのか感がある
-
対話システム
- そもそもパーセプション・トライアングルで大丈夫か問題はありますが、教師あり学習なので自動運転のときとそんなに違いはなさそうです。ただし、MicrosoftのTayの例では、おそらくユーザーとの対話履歴をつかってモデルの訓練を行っていたようです。そのため、レコメンデーションと同様に暗黙のフィードバックの矢印が必要そうです
雑感
- パーセプション・トライアングルは、そもそも認知タスクのためのもの(自動運転でも、認知と制御をわけて、認知についてのみパーセプション・トライアングルで整理している)なので、それ以外のタスクについてまじめに考えるには、そのためのフレームワークがあったほうがよさそうです
- とはいえ、少し変えたら対応できそうです
- 訓練方法(教師あり・なし・強化学習)による分類よりは、アクションがあるかどうか(つまり、機械学習の結果が実世界のシーンやシナリオに影響をあたえるかどうか)で、結構違いそうなので、そういう分け方のほうがすっきりしそうです
まとめ
- 自動運転の認知タスクに関する不確実性の整理の論文を読みました
- その論文では、パーセプション・トライアングルと呼ばれるツールをつかって分析しています
- パーセプション・トライアングルを機械学習のほかのタスクに適用できるか、具体例をいくつか用意してみました
- タスクによっては適用できるし、タスクによっては修正が必要そうですが、ちょっと手を加えればいい感じにせいりできるのではないかという感触を得ました