この記事は、 TensorFlow Advent Calendar 2016 25日目の記事です。
今年の10/7、TensorFlow UserGroup (TFUG) が発足しました。
「TensorFlow User Group立ち上げの儀」 に私も参加させていただいたのですが、そこで議題となったのが 「TensorFlowの読み方(カタカナ表記)」 でした。その場で多数決をとって、TFUGとしては 「テンソルフロー」 にすることに決定したのですが、思い通りに進まないのが世の常。
- TFUG コアメンバの多数決の結果、 TFUGでは 「テンソルフロー」 に統一することに決定
- TFUG #1 で、 NHKの取材が入り、 「テンサーフロー」 と書かれる
- Googleの中の人に聞くと 「テンサーフロー」 だと言われる
と、混乱を極めております。そこで、 TensorFlow Advent Calender の締めくくりとして、TensorFlow 自身に呼び方を決めてもらおうと思います。
全体方針
さて、TensorFlowのカタカナ表記を決めるにはどうしたらよいでしょうか。
英語の「TensorFlow」をカタカナに翻訳できれば良いでしょう。幸いにも、翻訳は深層学習の典型的な応用例の1つです。TensorFlowでの翻訳事例もたくさんあります。TensorFlowに興味のある方であれば下のような図を見たことがあると思います。
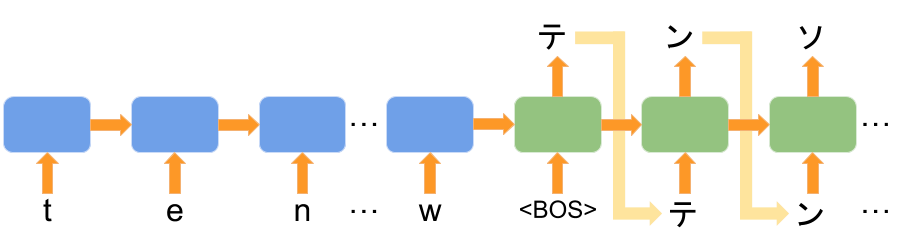
これは、「sequence to sequence」 と呼ばれるモデルで、深層学習を使って翻訳や要約する定番のモデルです。最近高精度化した Google 翻訳でも用いられている手法ですし、この記事でも、このモデルの派生系を使ってカタカナへの翻訳を試みます。
Sequence to Sequence モデル
sequence to sequence モデル自体については、いろいろな記事で紹介されているので、詳しい解説はそちらにおまかせして、ここでは概要だけ説明します。
深層学習にかぎらず、機械学習には最適なパラメーターを探す「学習」フェーズと、見つけたパラメータで予測をする「推定」フェーズがありますが、イメージのつきやすい「推定」フェーズからみてみます。
推定フェーズ
まず、上記のネットワークは入力データを固定長の長さに圧縮する「エンコーダー」部分と圧縮された情報から出力を生成する「デコーダー」部分にわかれます。
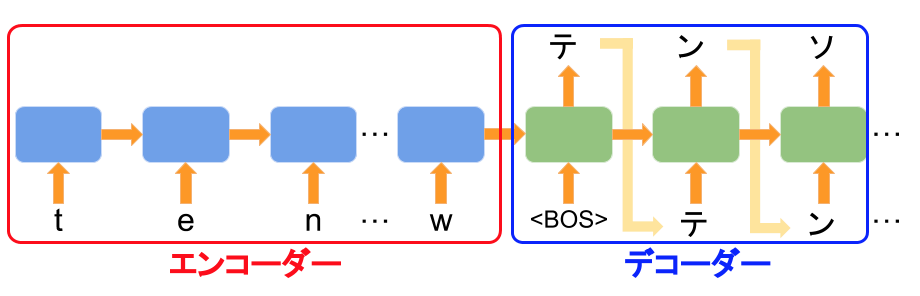
エンコーダーでは、入力文字列を1文字づつ読み込んで、都度状態を更新していきます。上記の例ですと、
- t を読み込んで状態(初期値)を更新
- e を読み込んで、 1. の状態をさらに更新
- n を読み込んで、 2. の状態をさらに更新
- ...
という流れになります。状態の初期値は適当(ゼロ配列など)に決め、最後の文字まで更新された最後の状態がエンコーダーの出力となります。「更新」ってなんやねん、となりそうですが、そこは学習フェーズで適切な更新方法を探すことになります。
一方、デコーダーでは、エンコーダーの出力をもとに、一文字づつ文字を出力を生成していきます。上記の例ですと、
- BOS を読み込み、エンコーダーの出力(状態)を更新。ついでに次に来るべき1文字を推定する (テ)
- 1.で推定した文字(テ)を読み込んで、1.の状態をさらに更新。ついでに次に来るべき1文字を推定する (ン)
- 2.で推定した文字(ン)を読み込んで、2.の状態を更に更新。ついでに次に来るべき1文字を推定する (ソ)
- ...
となります。
学習フェーズ
さて、次は学習フェーズです。
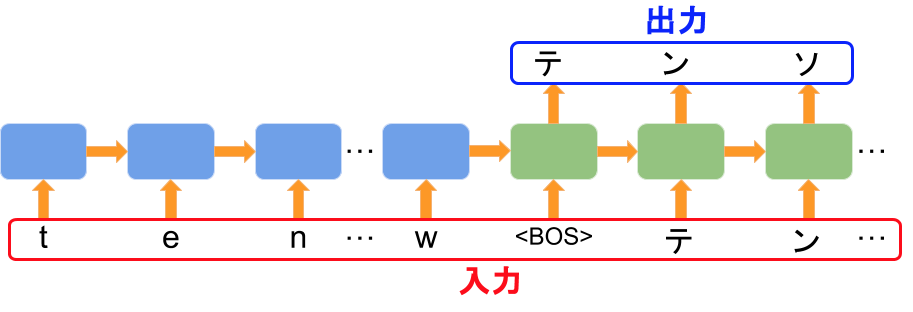
sequence to sequence では、エンコーダーとデコーダーをまとめて学習します。
入力は翻訳元の文字列と翻訳先の文字列を BOS(※ 翻訳先の文字列に含まれない文字であればなんでもよい)でくっつけたものです。
出力はデコーダーに対応する部分の出力がちょうど翻訳先の文字列となるように、「更新方法」を学習していきます。
入力に翻訳先の文字列(テン...)も含まれますが、 BOS のお陰で出力とは1文字づつずれていて、「次の文字を予測する」形となっているのがポイントですね。
データ準備
さて、今回の例に sequence to swquence を利用するには、エンコーダーに英語表記、デコーダーにカタカナ表記を入力すれば良さそうです。要するに英語表記とカタカナ表記のペアが必要になるのですが、そういったデータセットを手に入れることはできるでしょうか?
きれいなデータセットがあるに越したことはないのですが、さっと調べた限りでは使えそうなものはありませんでした。そこで今回は無料の英和辞書から日本語表記カタカナのものを抽出することで代替します。パっと思いつくデータソースは以下の2つです
| データソース | 概要 |
|---|---|
| EJDICT | 無料の英和辞書 |
| Wikipedia | 日本語ページと英語ページの両方がある記事のタイトルを辞書とみなす |
それぞれダウンロードして中身を見てみましたが、EJDICTは前処理が大変そうだったのと、データ量がWikipediaのほうが多かったので、今回は Wikipedia を利用することとしました。
Wikipedia データ加工
Wikipdeia では、クローリング/スクレイピングしなくてよいように、データのダンプを用意してくれています。Wikipediaのダンプにはいろいろな種類がありますが、今回は以下の2つをダウンロードすれば十分です。
| ファイル名 | 内容 | 用途 |
|---|---|---|
| jawiki-latest-page.sql.gz | ページ情報 | タイトルを取得する |
| jawiki-latest-langlinks.sql.gz | 別言語ページへのリンク情報 | 英語ページのタイトルを取得する |
以下の処理をして約66,000個の 英語・カタカナ の対を得ることができました。
- 適当なMySQLに2つのテーブルをリストア
- 日本語のページと英語のページを JOIN して、 csv ファイルにダンプ
- 正規表現を用いて、日本語側がカタカナ(と数字)のみの行を抽出
- 大文字を小文字に変換
できたファイルはこちらにあります。
見ていただけるとわかると思うのですが、まだまだ汚いので、翻訳の精度を上げるには、もっと抽出条件条件を詰めたほうが良さそうです。
TensorFlowでの実装
データが準備できたので、あとは実装するだけです。
sequence to sequence モデルは、TensorFlowのチュートリアルにもなっているので、そこをベースに実装するのが賢いやり方です。私が過去に対話ボットを作った際にも、チュートリアルを参考に実装して発狂しそうになりました。
生のTensorFlowで書いても良いのですが、最近は Keras や TFLearn、 TF-slim など、TensorFlowを容易に使えるライブラリが増えてきています。
今回は、最近 TensorFlow本家のリポジトリに取り込まれた skflow (tensorflow.contrib.learn) を使~~います。~~おうと思っていたのですが、諸事情により断念しました。とは言え、結構苦労しながら手を動かしたので、断念した経緯やskflowの使い方・ベストプラクティスなどについて別記事にまとめようと思います。
というわけで、今回の実装は生のTensorFlowで書いたものとなります。第5回 TensorFlow 勉強会での発表に使った VAE(Variational Auto Encoder)という sequence to sequence の派生系のネットワークをそのまま利用しました。
VAEのネットワーク構造は以下のとおりです。
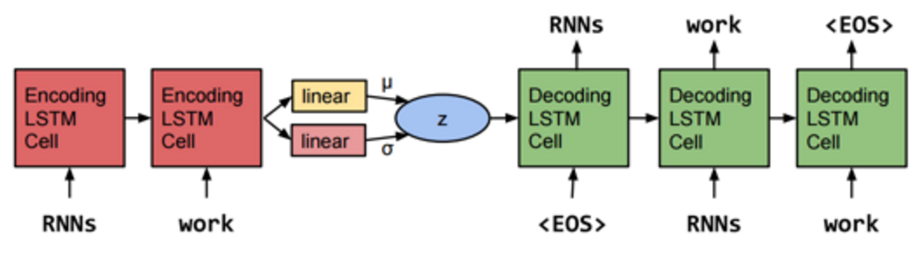
Generating Sentences from a Continuous Space
エンコーダーとデコーダーの間に見慣れないものが入っていますが、基本的に普通の sequence to sequence と同じことができます。このネットワークの詳細については、発表資料を御覧ください。
学習経過
100000ステップ学習してみた結果は以下のとおりです。最近のGPUを積んでいるマシンであれば1-2時間程度だと思います。
言語生成系のモデルは、学習過程が面白いですね。
| ステップ数 | tensorflowのカタカナ表記の推定値 |
|---|---|
| 0 | ヱ |
| 100 | |
| 500 | ー ト ラ ー ル |
| 1000 | ン ト ラ ン |
| 2000 | ン ト ラ ン |
| 5000 | ト ラ ト ラ イ ン |
| 10000 | テ ン ロ フ ィ ア |
| 20000 | ン ド |
| 30000 | テ ン コ ラ ブ |
| 40000 | テ ン コ ル フ |
| 50000 | ン ス ホ ル フ ル |
| 60000 | テ ン コ ル フ ォ |
| 70000 | テ ン ル フ ォ ー |
| 80000 | テ ン ス ル フ |
| 90000 | テ ン ス ル フ |
| 100000 | テ ン ス ル フ ォ ル |
徐々に学習されているのが見て取れますね。
パラメーターのチューニングや学習ステップの増加など、やるべきことはたくさんありますが、この記事としてはここで終わりではないぞよ、もうちっとだけ続くんじゃ、と言いたいところですが、ここで終わります。m(_ _)m
結論
TensorFlow さんに聞いたところ、 TensorFlowは 「テンスルフォル」 でした。「テンソルフロー」か「テンサーフロー」といってほしかったのですが、新たな候補がでてきてさらに混沌としてきました。
感想
- tf.contrib.learn 鬼門すぎる
おまけ
Google さんに聞いてみました。
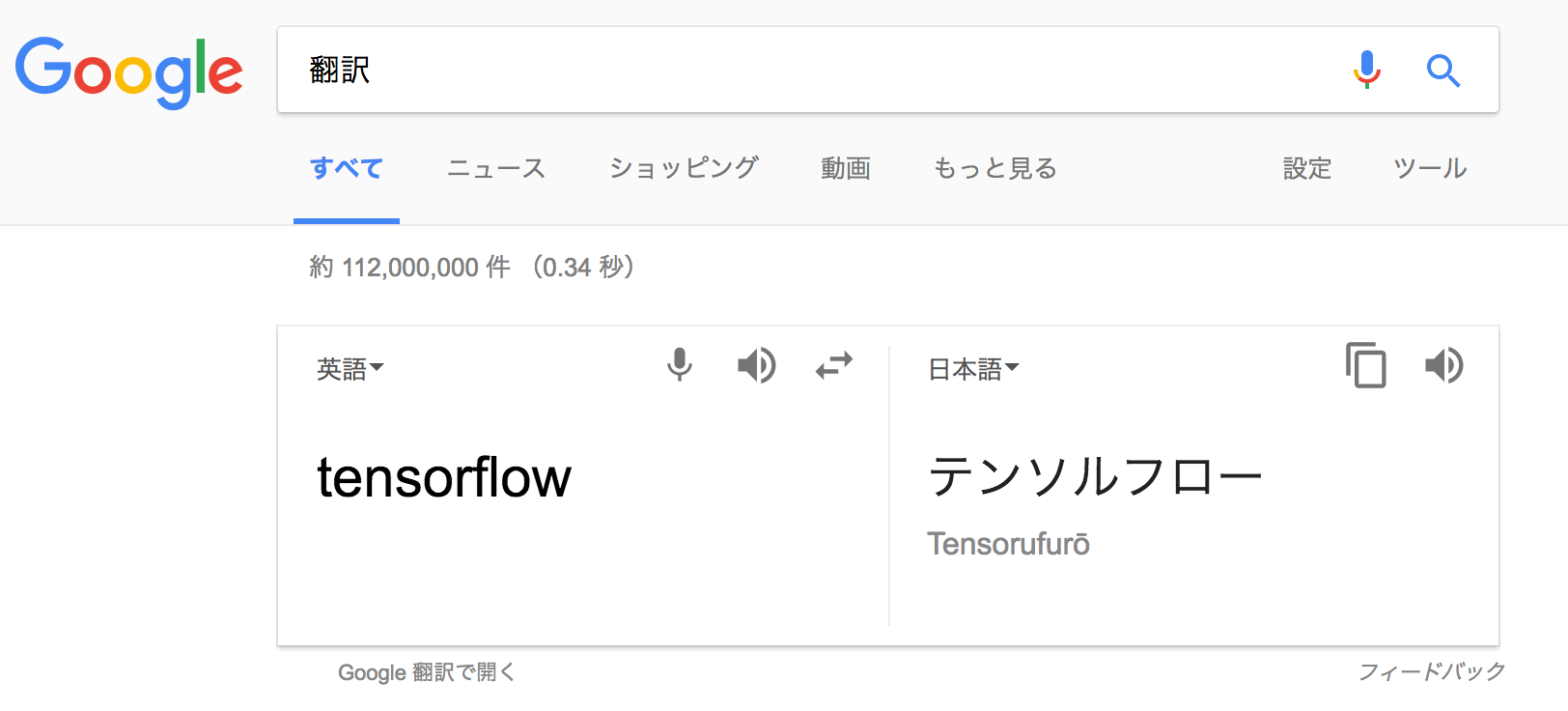
間違っていると思われる方はフィードバックするとかえてもらえるかもしれません!