この記事は TensorFlow Advent Calendar 2017の最終日の記事です。
何を書こうか迷っていたのですが、最近 kubeflow というものを知ったので、それについて書こうと思います。
機械学習システムの実運用
TensorFlowが公開されて2年ほど経ち、いろいろな事例が出てくるようになりました。昨年度は、いわゆるPOC(Proof of Concept)の事例が多かったように思いますが、徐々にビジネスで本格的に深層学習を使っているような事例も出てくるようになってきており、今後は深層学習のアルゴリズムそのものではなく、如何に実システムに組み込み運用するか、という観点も重要になってくるだろうと思います。
言い古された話ですが、機械学習を本番に導入して運用していくには、いろいろんはハードルがあります。このあたりは2014年にGoogleから出された論文「[Machine Learning: The High Interest Credit Card of Technical Debt]
(https://research.google.com/pubs/pub43146.html)」に詳しくまとめられています(日本語の[まとめ](https://www.slideshare.net/recruitcojp/ss-42745505))ので、興味のあるかたは目を通してみることをおすすめしますが、ざっっくりとまとめると
- 機械学習システムは本質的にデータに依存しているため、従来のシステムのようにコードだけのメンテナンスでは不十分
- 外界とデータでつながってしまっているため、外界の複雑さに影響されて複雑になりがち
といったことが書いてあります(リンク先を読んでいただいたほうが正確です)。
で、個人的には、機械学習システムを作るにあたって以下の3つくらいはおさえておかないとまずいな、と思っています。
- 本番環境と分析環境が独立していること
- 機械学習モデルがモジュール化されており、切り替えが容易なこと
- データの流れがわかりやすいこと
Kubeflow
さて、Kubeflowとは、簡単に言うとKubernetes上で簡単に機械学習用の環境を構築できるようにしたものです。具体的には、以下の manifest が含まれています。
- JupyterHub (Jupyterを複数ユーザーで使えるようにしたもの)
- TensorFlow Training Controller (学習用の分散環境が簡単に構築できる)
- TensorFlow Serving (構築したモデルを公開できる)
分析官に分析環境(JupyterHub)を提供し、TensorFlow Serving を使うことで自動的に機械額数モデルがモジュール化されます。おまけに分散環境も手に入るにくいやつです。
今回は、この kubeflow をクラウド/ローカル両方の環境で触ってみます。
Kubernetes 環境の構築
まずは Kubernetes 環境を準備します。お手軽に構築できる Kubernetes 環境として、
-
GKE (Goole Kubernetes Engine)
- Google Container Engine だと思っていたけど名前が変わっていた
-
Minukube
- ローカルでお手軽にKubernetes環境を構築するツール
の2つがありますが、まずは GKE から環境を構築します。
GKE 環境の構築
gcloud コマンドがインストール済の場合は、簡単にクラスタを構築できます。
$ gcloud container clusters create cpu-cluster \
--machine-type=n1-standard-4 \
--num-nodes=2
--machine-type や --num-nodes は適当に決めていただければOKです。
ちなみにですが、アルファ版の機能を使うと、以下のような感じでGKEでもGPUインスタンスを指定することができます。
$ gcloud alpha container clusters create gpu-cluster \
--accelerator type=nvidia-tesla-k80,count=1 \
--zone=asia-east1-a \
--enable-kubernetes-alpha \
--machine-type=n1-standard-4 \
--num-nodes=2
ただし、アルファ版なので、以下のような制限がありますのでご注意ください。
- SLAの範囲外なので、プロダクション環境での利用は推奨しない
- マスター/ノードのアップグレードができない
- クラスタは30日で勝手に削除される
次に、cluster role binding を作成します。GKDでは、これがないとロールの作成に失敗してしまうようです。
$ kubectl create clusterrolebinding default-admin \
--clusterrole=cluster-admin \
--user=<user_gmail_address>
Minikube 環境の構築
次に、Minikube の環境構築を行います。といってもとても簡単で、Macの場合は
$ brew cask install minikube
です。Linuxの場合も1ラインでインストールできますが、詳しくはMinikubeのREADME.mdを御覧ください。
ksonnetのインストール
次に、ksonnetをインストールします。ksonnetは、Kubernetesのmanifestを管理してくれるツールです。
これもインストールは簡単です。
$ brew install ksonnet/tap/ks
ksonnetにkubeflowのインストール
では、次に kubeflow をインストールします。
$ ks init kubeflow # kubeflow という初期設定済のディレクトリができる
$ cd kubeflow
$ ks registry add kubeflow github.com/google/kubeflow/tree/master/kubeflow # リポジトリを登録
$ ks pkg install kubeflow/core
$ ks pkg install kubeflow/tf-serving
$ ks pkg install kubeflow/tf-job
$ ks generate core kubeflow-core --name=kubeflow-core
次に環境を登録します。
$ kubectl config use-context minikube # コンテキストを minikubeにうつして
$ ks env add minikube # 環境(minikube)を追加
$ kubectl config use-context <gke-context-name> # コンテキストを gke-xxx にうつして
$ ks env add gke # 環境(gke)を追加
ここで は以下のコマンドで確認できます。
$ kubectl config get-contexts
apply
では、実際に動かしてみましょう。まずはGKEでJupyterHubを立ち上げます。
$ ks apply gke -c kubeflow-core
kubectl get svc をしてみると、JupyterHubが立ち上がっているのがわかります。
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.51.240.1 <none> 443/TCP 36m
tf-hub-0 ClusterIP None <none> 8000/TCP 11m
tf-hub-lb LoadBalancer 10.51.252.204 35.201.216.247 80:31460/TCP 11m
tf-hub-lb(35.201.216.247:31460)にアクセスしてみると、

いい感じですね。ユーザー名とパスワードは自由に設定できます。
Sign Inボタンを押すと、利用するリソースを指定できます。Imageには
- gcr.io/kubeflow/tensorflow-notebook-cpu
- gcr.io/kubeflow/tensorflow-notebook-gpu
のいずれか(もしくは独自にカスタマイズしたもの)を指定できます。
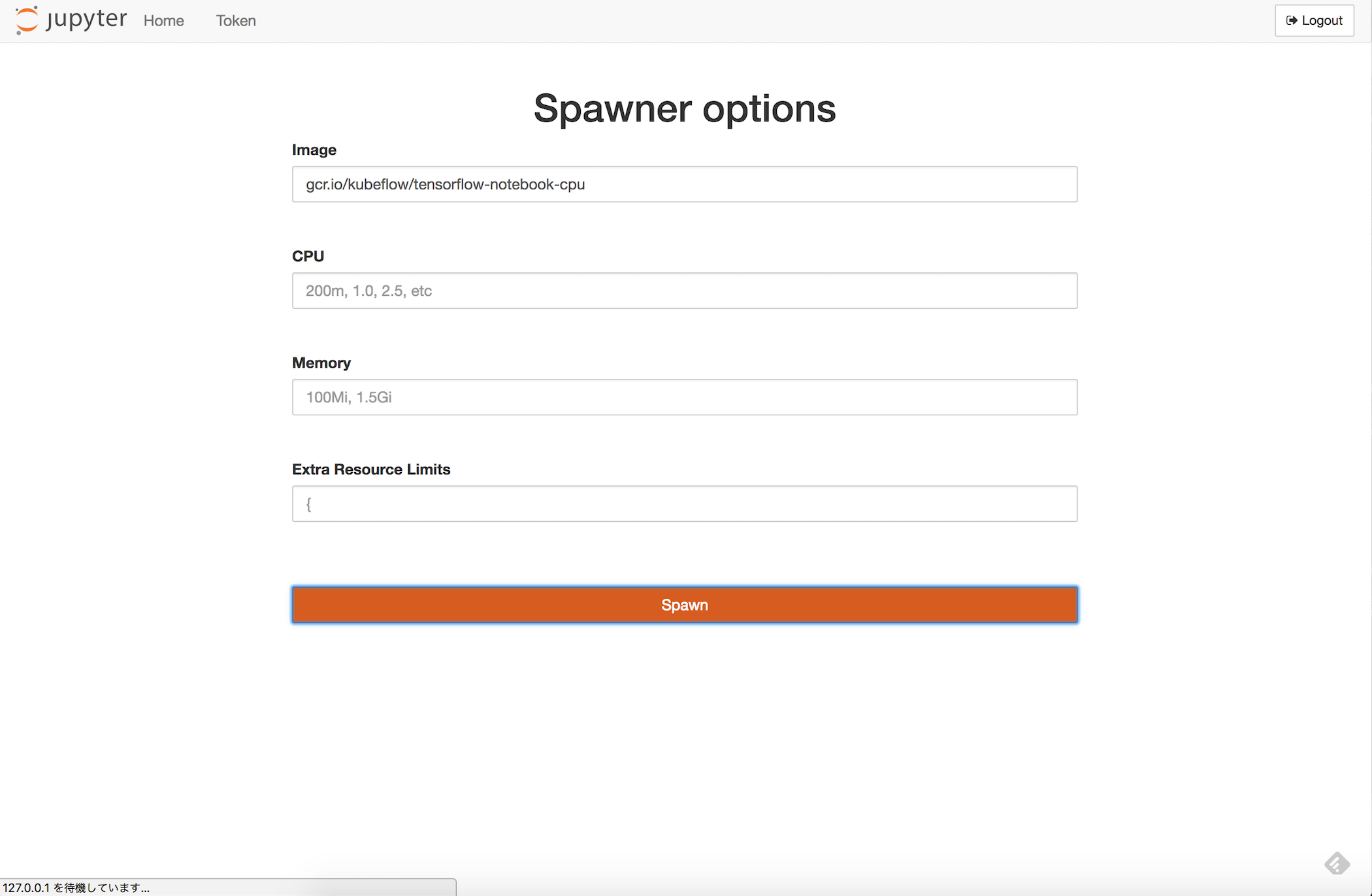
リソースを適当に指定して Spawn すると、普通のJupyterNotebookの画面となり、tensorflowが入っていることが確認できます。(ただし、 Pythonのバージョンが3.6.xのため、warningがでています。。。)
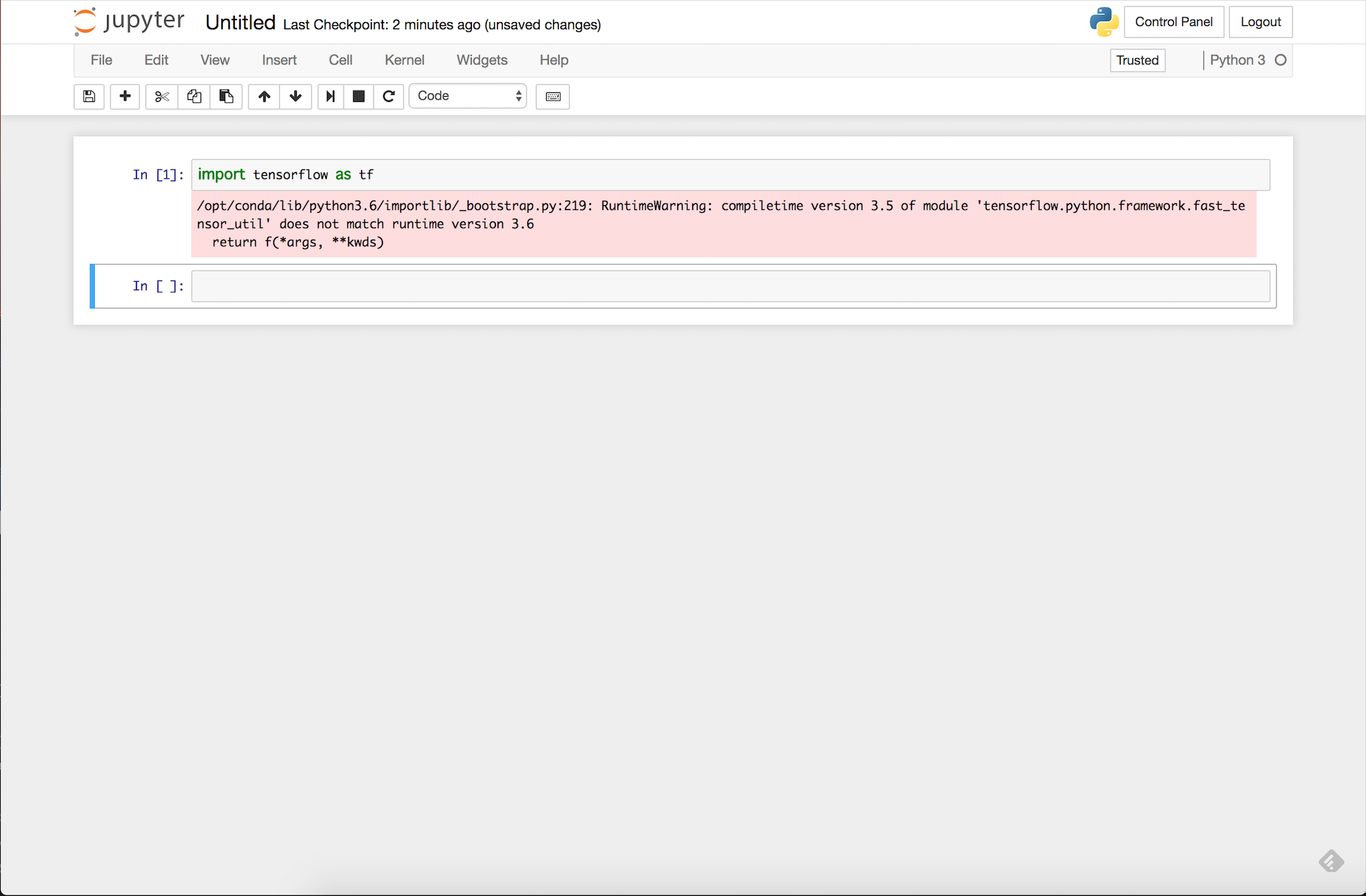
あとはJupyterNotebookを使いだけです。
これで、分析官は自分好みのイメージとリソースを指定して、好き勝手な環境を手に入れられることがわかりました。
分散環境でモデルを構築してみる
次に、モデルの構築について見てみます。モデルを構築するには、 tf-jobプロトタイプを使うようです。具体的には
$ ks generate tf-job ${JOB_NAME} --name=${JOB_NAME}
としてcomponentを作成した後で、
$ ks param set ${JOB_NAME} image ${IMAGE}
でパラメータを設定して(今はできないようで、ファイルに直接書き込まないといけない模様)、
$ ks apply ${ENVIRONMENT} -c ${JOB_NAME}
でジョブを投げます。独自のジョブを作るのはちょっと面倒なので、ここではtf-cnnというサンプルを利用します。
$ ks generate tf-cnn cnn --name=cnn
$ ks apply <env_name> -c cnn
kubectl の proxy 機能を使ってログをみてみると、なにやらちゃんと動いているようです。
$ kubectl proxy
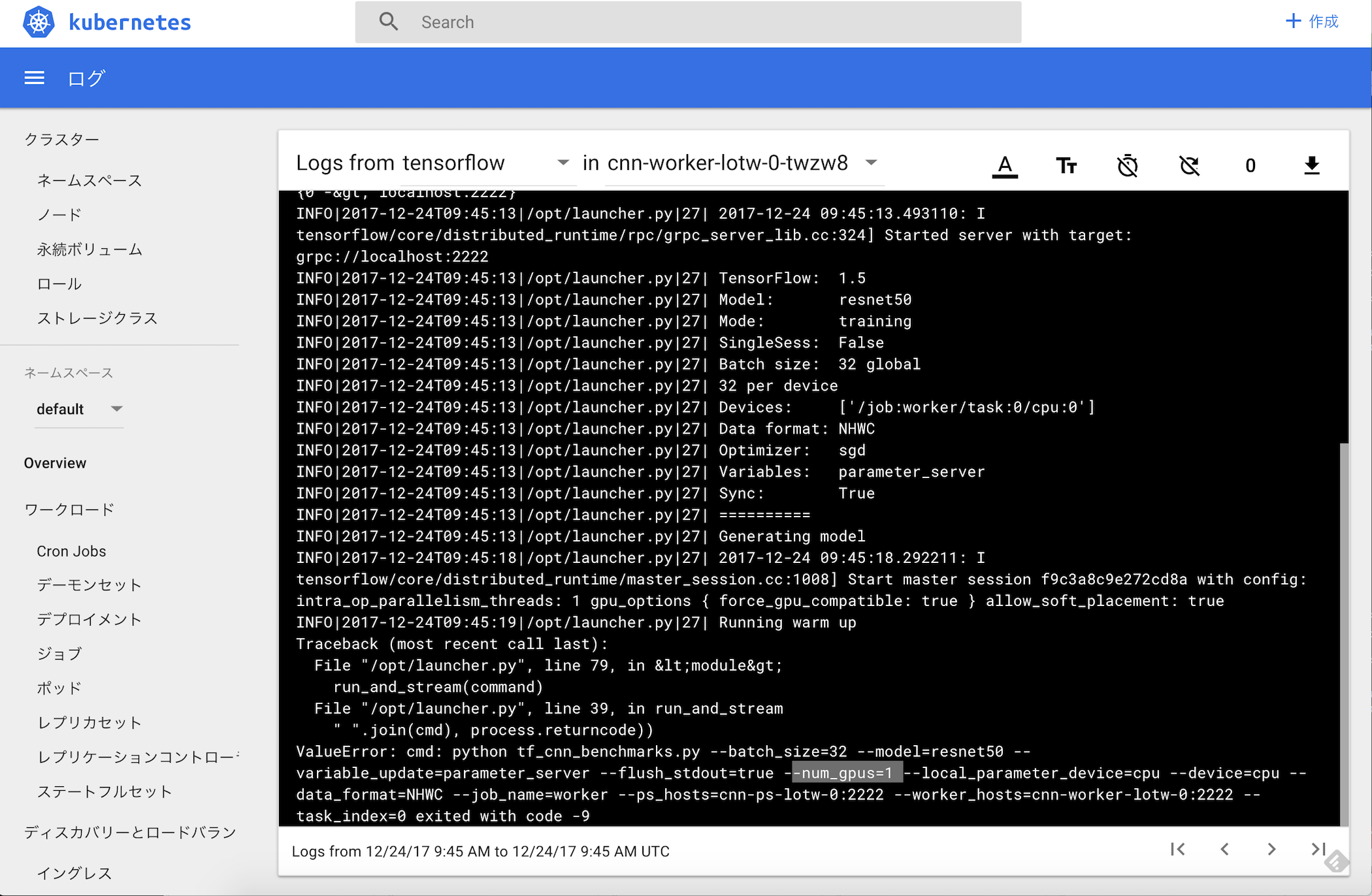
ログを見てみると、resnet50を学習しようとして失敗しているようです。(なんでだろうか。原因不明)
ちなみに、このサンプルはもともと Google Cloud ML のためのものです。きちんと調べられていませんが、互換性があるのだと思います。
モデルをサーブしてみる
最後に、モデルをサーブしてみます。公式のREADME.mdに従うと、model_pathのところでエラーになったので、書き換えています。
$ ks generate tf-serving inception \
--name=inception \
--namespace=default \
--model_path=gs://kubeflow-models/inception
$ ks apply <env_name> -c inception
これだけだと、うまく動いているかわからないので、 tensorflow-serving から inception_client.py というファイルをひっぱてきて、おもむろに実行します。
画像認識する画像(cat.jpg)は

です。(ちなみに、 pip で grpcio と tensorflow-serving-api をインストールシておく必要があります。)
$ python serving/inception_client.py --server 35.194.134.209:9000 --image cat.jpg
E1225 10:49:54.754749000 140736620450752 ev_epollex_linux.cc:1482] Skipping epollex becuase GRPC_LINUX_EPOLL is not defined.
E1225 10:49:54.754778000 140736620450752 ev_epoll1_linux.cc:1261] Skipping epoll1 becuase GRPC_LINUX_EPOLL is not defined.
E1225 10:49:54.754786000 140736620450752 ev_epollsig_linux.cc:1761] Skipping epollsig becuase GRPC_LINUX_EPOLL is not defined.
outputs {
key: "classes"
value {
dtype: DT_STRING
tensor_shape {
dim {
size: 1
}
dim {
size: 5
}
}
string_val: "Egyptian cat"
string_val: "tabby, tabby cat"
string_val: "tiger cat"
string_val: "lynx, catamount"
string_val: "Siamese cat, Siamese"
}
}
outputs {
key: "scores"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
dim {
size: 5
}
}
float_val: 8.14393520355
float_val: 7.33330821991
float_val: 6.97384166718
float_val: 5.12769412994
float_val: 3.70395231247
}
}
というわけで、正しく動作していそうです。
まとめ
kubeflowというツールをいじってみました。公式のとおりだと動かなかったり、まだまだなところもありますが、分析環境やServing環境がお手軽にてにはいるのはいいなぁと思いました。