はじめに
2025年6月25,26日に開催された AWS Summitのセッション「生成 AI アプリケーションを最適化するインメモリセマンティックキャッシュ (Level 300)」の内容が面白かったので、紹介します。
セッションの要点
生成AIアプリケーションの課題
- 応答速度が遅い(数秒かかる)
- LLM(基礎モデル)呼び出しによる高コスト
- リクエスト数増加とともにコストも線形に増加
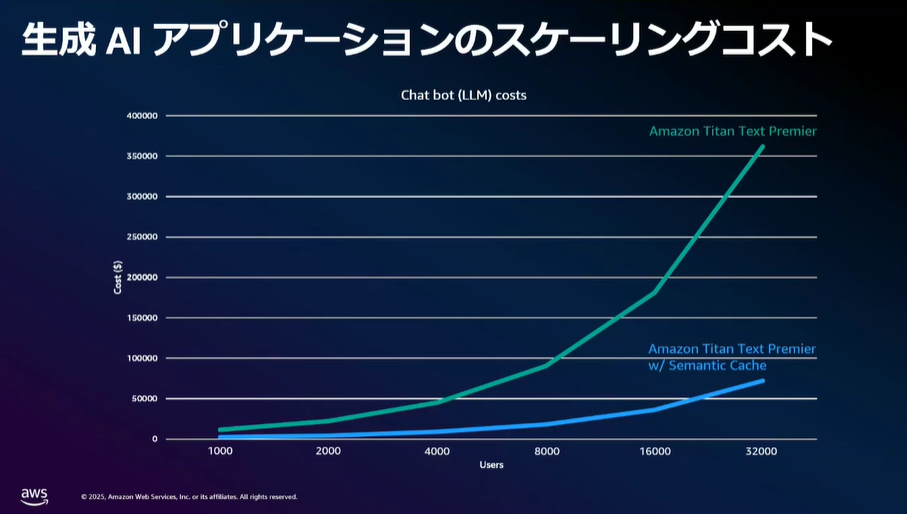
このような課題へ対応するために、MemoryDB を活用した耐久性セマンティックキャッシュについて発表がありました。
セマンティックキャッシュとは?
そもそもセマンティックキャッシュとは何でしょうか。
まず、それぞれの意味を
- 「キャッシュ」=一時的にデータを保存する仕組み
- 「セマンティック(semantic)」=意味的に近いものを扱う(LLMの根幹)
つまり、「意味的に似た過去の質問とその回答」を保存しておき、
次回以降の同様の質問にはLLMを使わずに、即座に回答できる仕組みです。
挙動について
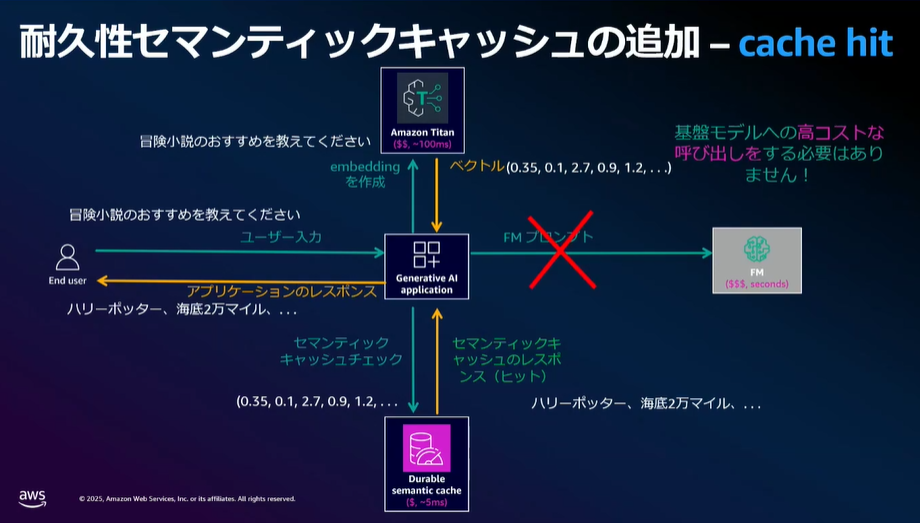
キャッシュヒットした場合
キャッシュヒットした場合の挙動は以下のようになります。
- ユーザーからの入力テキストをベクトル(数値の集合)に変換 (例:Amazon Titan Embeddings)
意味の近さを機械的に比較できるようにする - MemoryDBに類似問答があるかベクトル検索
- ユーザーにレスポンスを返す
以下はキャッシュヒット時のフローです。
MemoryDBに類似質問があれば、LLMを使わず高速に回答ができます。
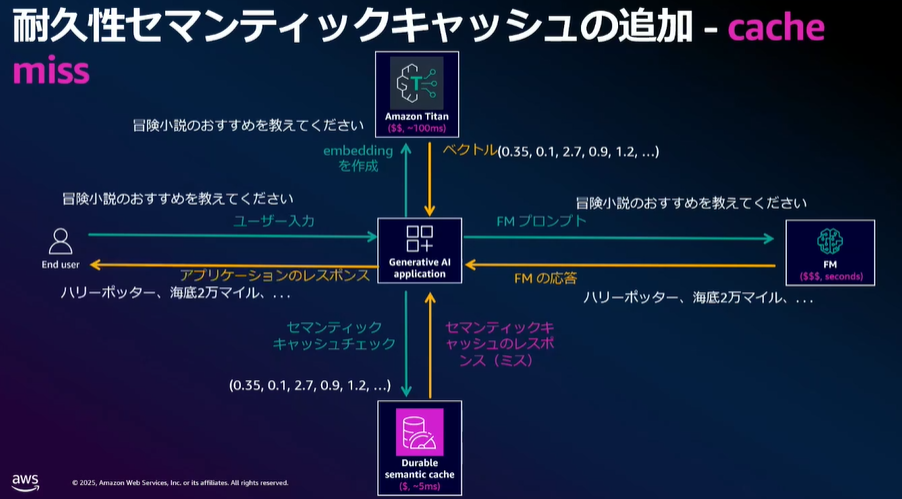
キャッシュがヒットしなかった場合
- ユーザーからの入力をベクトル化(例:Amazon Titan Embeddings)
- MemoryDBに類似問答があるかベクトル検索
- ヒットしなかったので、LLMにプロンプトを投げる(例:Amazon Bedrock)
- LLMの応答をユーザーに返す
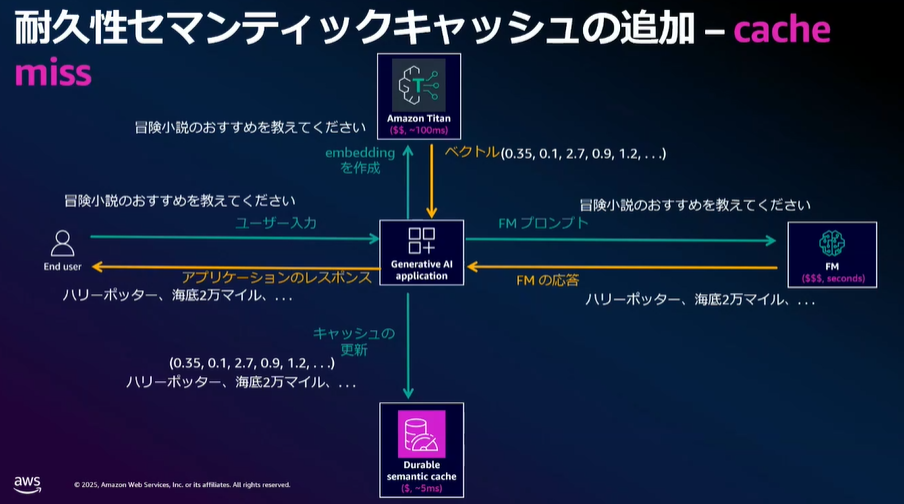
- LLMの応答をベクトル化
- キャッシュの更新
メリット
このアーキテクチャには3者にとってのメリットがあります:
| 対象 | メリット |
|---|---|
| ユーザー | 応答速度の向上(n秒 から 数十ms) |
| アプリ提供者 | LLM利用頻度減少によりコスト削減 |
| LLM提供者 | コンピューティングリソースの節約 |
発表ではLLM提供者のコンピューティングリソースの節約についての発言はありませんでしたが、
個人的には、LLM提供者にとってもメリットがあると考えています。
所感
私はAmazon Connectの構築・導入支援を行っていますが、このセッション内容は非常に実用的だと感じました。
Amazon ConnectではFAQ対応や定型的なやりとりが多く、
生成AIを毎回呼び出すよりも、
意味的に近い過去の応答をキャッシュで返せることは非常に効率的だからです。
少し話は反れますが、耐久性セマンティックキャッシュはすべてのユースケースに対応しているとは考えておりません。
FAQやカスタマーサポートなど、「決まった答えが多いシナリオ」にはあっていると考えていますが、
一方で、コード生成や長文生成のようなユースケースには適さないと考えています。
文章生成やコーディングなどのユースケースには 新しいアーキテクチャが出てくる可能性があると思いました。
次回、Amazon Connect × MemoryDBを利用した音声通話での
耐久性セマンティックキャッシュを試そうと思います。
あとがき
調べたところ、既に去年のre:Inventで発表されていたようですね。
AWS Summit で知ることができ、よいキャッチアップの機会になりました。