概要
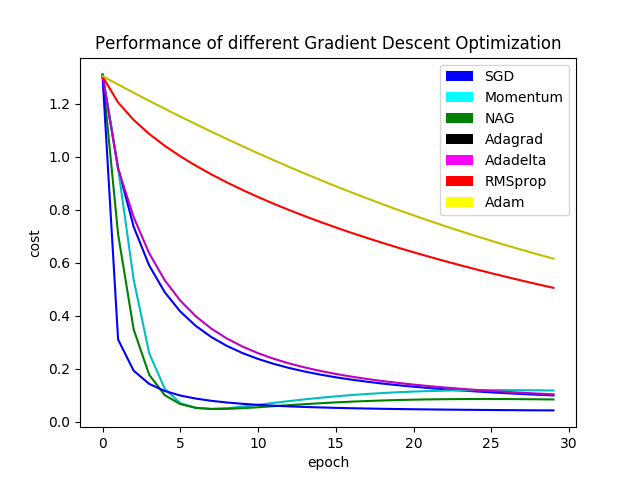
optimizerをグラフにしてみた。
写真
サンプルコード
import sys
import numpy as np
import math
import random
import matplotlib
import matplotlib.pylab as plt
from matplotlib.patches import Rectangle
plt_color_array = ['blue', 'cyan', 'green', 'black', 'magenta', 'red', 'yellow']
plt_dict = dict()
sigmoid = lambda x: 1.0 / (1.0 + np.exp(-x))
random.seed(1024)
num_input = 2
num_hidden = 64
num_output = 2
opt_algo_set = ['SGD', 'Momentum', 'NAG', 'Adagrad', 'Adadelta', 'RMSprop', 'Adam']
class NeuralNet:
def __init__(self, num_input, num_hidden, num_output):
self.num_input = num_input
self.num_hidden = num_hidden
self.num_output = num_output
def train(self, x, y, opt_algo, num_epoch = 30, mini_batch = 100, lambda_ = 0.01):
if not opt_algo in opt_algo_set:
print ('opt_algo not in %s' % opt_algo_set)
return
num_params = self.num_hidden * (self.num_input + 1) + self.num_output * (self.num_hidden + 1)
w = np.matrix(0.005 * np.random.random([num_params, 1]))
data = np.column_stack([x, y])
gamma = 0.9
epsilon = 1e-8
if opt_algo == 'RMSprop' or opt_algo == 'Adam':
eta = 0.001
else:
eta = 0.05
v = np.matrix(np.zeros(w.shape))
m = np.matrix(np.zeros(w.shape))
beta1 = 0.9
beta2 = 0.999
beta1_exp = 1.0
beta2_exp = 1.0
grad_sum_square = np.matrix(np.zeros(w.shape))
grad_expect = np.matrix(np.zeros(w.shape))
delta_expect = np.matrix(np.zeros(w.shape))
first_run = True
for epoch in range(num_epoch):
np.random.shuffle(data)
k = 0
cost_array = list()
while k < len(data):
x = data[k : k + mini_batch, 0 : -1]
y = np.matrix(data[k : k + mini_batch, -1], dtype = 'int32')
if opt_algo == 'SGD':
cost, grad = self.gradient(x, y, lambda_, w)
w -= eta * grad
elif opt_algo == 'Momentum':
cost, grad = self.gradient(x, y, lambda_, w)
v = gamma * v + eta * grad
w -= v
elif opt_algo == 'NAG':
cost, grad = self.gradient(x, y, lambda_, w - gamma * v)
v = gamma * v + eta * grad
w -= v
elif opt_algo == 'Adagrad':
cost, grad = self.gradient(x, y, lambda_, w)
grad_sum_square += np.square(grad)
delta = eta * grad / np.sqrt(grad_sum_square + epsilon)
w -= delta
elif opt_algo == 'Adadelta':
cost, grad = self.gradient(x, y, lambda_, w)
grad_expect = gamma * grad_expect + (1.0 - gamma) * np.square(grad)
if first_run == True:
delta = eta * grad
else:
delta = np.multiply(np.sqrt(delta_expect + epsilon) / np.sqrt(grad_expect + epsilon), grad)
w -= delta
delta_expect = gamma * delta_expect + (1.0 - gamma) * np.square(delta)
elif opt_algo == 'RMSprop':
cost, grad = self.gradient(x, y, lambda_, w)
grad_expect = gamma * grad_expect + (1.0 - gamma) * np.square(grad)
w -= eta * grad / np.sqrt(grad_expect + epsilon)
elif opt_algo == 'Adam':
cost, grad = self.gradient(x, y, lambda_, w)
m = beta1 * m + (1.0 - beta1) * grad
v = beta2 * v + (1.0 - beta2) * np.square(grad)
beta1_exp *= beta1
beta2_exp *= beta2
w -= eta * (m / (1.0 - beta1_exp)) / (np.sqrt(v / (1.0 - beta2_exp)) + epsilon)
k += mini_batch
cost_array.append(cost)
if first_run == True:
first_run = False
if not opt_algo in plt_dict:
plt_dict[opt_algo] = list()
plt_dict[opt_algo].extend(cost_array)
self.w1 = w[0 : self.num_hidden * (self.num_input + 1)].reshape(self.num_hidden, self.num_input + 1)
self.w2 = w[self.num_hidden * (self.num_input + 1) : ].reshape(self.num_output, self.num_hidden + 1)
def gradient(self, x, y, lambda_, w):
num_sample = len(x)
w1 = w[0 : self.num_hidden * (self.num_input + 1)].reshape(self.num_hidden, self.num_input + 1)
w2 = w[self.num_hidden * (self.num_input + 1) : ].reshape(self.num_output, self.num_hidden + 1)
b = np.matrix(np.ones([num_sample, 1]))
a1 = np.column_stack([x, b])
s2 = sigmoid(a1 * w1.T)
a2 = np.column_stack([s2, b])
a3 = sigmoid(a2 * w2.T)
y_one_hot = np.matrix(np.zeros([num_sample, self.num_output]))
y_one_hot[(np.matrix(range(num_sample)), y.T)] = 1
cost = (1.0 / num_sample) * (- np.multiply(y_one_hot, np.log(a3)) - np.multiply(1.0 - y_one_hot, np.log(1.0 - a3))).sum()
cost += (lambda_ / (2.0 * num_sample)) * (np.square(w1[ : , 0 : -1]).sum() + np.square(w2[ : , 0 : -1]).sum())
delta3 = a3 - y_one_hot
delta2 = np.multiply(delta3 * w2[ : , 0 : -1], np.multiply(s2, 1.0 - s2))
l1_grad = delta2.T * a1
l2_grad = delta3.T * a2
r1_grad = np.column_stack([w1[ : , 0 : -1], np.matrix(np.zeros([self.num_hidden, 1]))])
r2_grad = np.column_stack([w2[ : , 0 : -1], np.matrix(np.zeros([self.num_output, 1]))])
w1_grad = (1.0 / num_sample) * l1_grad + (1.0 * lambda_ / num_sample) * r1_grad
w2_grad = (1.0 / num_sample) * l2_grad + (1.0 * lambda_ / num_sample) * r2_grad
w_grad = np.row_stack([w1_grad.reshape(-1, 1), w2_grad.reshape(-1, 1)])
return cost, w_grad
if __name__ == '__main__':
x_train = np.array([[1, 0], [0, 1], [1, 1], [0, 0]])
y_train = np.array([[0], [0], [1], [1]])
x_test = np.array([[1, 0], [0, 1], [1, 1], [0, 0]])
y_test = np.array([[0], [0], [1], [1]])
clf = NeuralNet(num_input, num_hidden, num_output)
for opt_algo in opt_algo_set:
clf.train(x_train, y_train, opt_algo, num_epoch = 30, lambda_ = 0.1)
plt.subplot(111)
plt.title('Performance of different Gradient Descent Optimization')
plt.xlabel('epoch')
plt.ylabel('cost')
proxy = list()
legend_array = list()
for index, (opt_algo, epoch_cost) in enumerate(plt_dict.items()):
selected_color = plt_color_array[index % len(plt_color_array)]
plt.plot(range(len(epoch_cost)), epoch_cost, '-%s' % selected_color[0])
proxy.append(Rectangle((0, 0), 0, 0, facecolor = selected_color))
legend_array.append(opt_algo)
plt.legend(proxy, legend_array)
plt.savefig("nn-sgt1.png")
plt.show()
以上。