
皆さん、こんにちは。大畑と申します。
小売企業でデータサイエンティスト兼データエンジニアとして働いています。
今回は、データ活用の最初のステップであるデータ理解の手法やコツをご紹介いたします。
最後までご覧いただくと、データ分析の専門家も実施しているデータ理解の手法を学ぶことができます。
データ理解の手法:探索的データ解析(EDA)というアプローチ
データ分析の現場で、最初に取り組むべき重要なステップ——それが「データ理解」。
このプロセスを支える代表的な手法が、探索的データ解析(Exploratory Data Analysis:EDA) です。
EDAとは何か?
EDAは、1970年代にアメリカの数学者 ジョン・トゥーキー(John Tukey) 氏によって提唱された手法です。
目的は、データの特徴を探索し、構造を理解すること。
彼はこう考えました:
「データは仮説を検証するためだけでなく、仮説そのものを発見するためにも使うべきだ」
この考え方に基づき、EDAというアプローチが誕生しました。
EDAの本質と実務への応用
本来、EDAは統計学の専門的な領域に属します。
実務でのデータ活用においても、そのエッセンスは非常に有効です。
ここでは、専門的な理論に偏らず、実践的な視点からEDAを活用する方法を紹介します。
データ理解の目的
- データの種類・形式・範囲の確認
- 含まれる情報の把握
- 分析や可視化の方向性の決定
- データ分析の土台づくり
可視化によるパターンの発見
以下のような可視化手法を使って、データの構造を視覚的に把握します:
- ヒストグラム
- 分布図
- 箱ひげ図(ボックスプロット)
これにより、以下の情報を得ることができます:
- データの中心傾向
- ばらつき(分散)
- 外れ値(異常値)
欠損値・異常値の特定と処理
データの品質を評価するうえで、欠損値や異常値の確認は欠かせません。
- 欠損値が多い場合 → データの補完を検討
- 異常値が存在する場合 → エラーやイレギュラーなケースの可能性
これらを適切に処理しないと、以下のような問題が発生します:
- 顧客の年齢データが欠損 → 年齢別の購買傾向が分析できない
- 極端に高い売上データ → 平均値が実態より高く算出される
仮説の構築と検証
EDAのもう一つの重要な役割が、仮説の構築と検証です。
- データから仮説を立てる
- 仮説を検証し、分析の方向性を確認
- 集計方法や分析手法の妥当性を見極め、必要に応じて修正
EDAがもたらす価値
EDAを通じて得られるのは、単なる数値の羅列ではありません。
それは、データの本質的な理解であり、分析の成功を左右する基盤です。
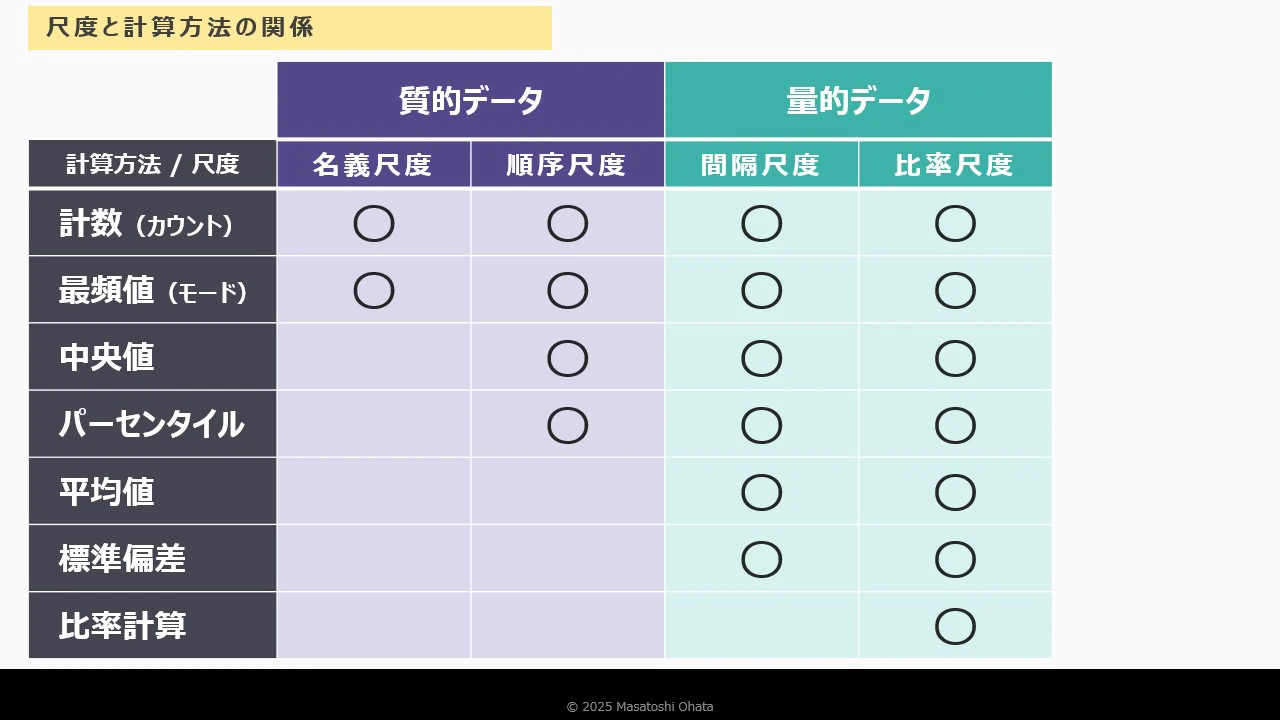
データの尺度とは?
データの性質を理解するための重要な概念、それが データの尺度です。
これは、データの種類や構造を分類し、適切な分析手法を選ぶための基礎となる考え方です。
データの尺度には、以下の4種類があります:
- 名義尺度
- 順序尺度
- 間隔尺度
- 比率尺度
それぞれの尺度には、異なる特徴と分析上の制約があります。
この違いを理解することで、データの性質に応じた適切な処理や可視化が可能になります。
なぜ尺度の理解が重要なのか?
例えば:
- 名義尺度 → 平均値は計算不可、最頻値は算出可能
- 比率尺度 → 平均値・標準偏差・比率の計算が可能
このように、尺度の理解は分析の精度を左右する重要なステップです。
名義尺度
カテゴリー分類のための尺度 です。
データ間に順序はなく、単なるグループ分けを示します。
例: 性別(男性・女性)、血液型(A型・B型・O型・AB型)
特徴:
- 順序なし
- 数値的な操作不可
- 分類や集計に適する
順序尺度
データに順序を与える尺度 です。
大小関係はあるが、間隔の大きさは不明です。
例: 学歴(小学校・中学校・高校・大学)、満足度(不満・普通・満足)
特徴:
- 順序あり
- 数値的な演算不可
- ランキングや階級の表現に適する
間隔尺度
データ間の差を測定する尺度 です。
間隔は等しいが、絶対的なゼロ点が存在しません。
例: 温度、日付、時刻
特徴:
- 差の計算は可能
- 比率の計算は不可
- ゼロ点がないため「2倍」などの表現が不適切
補足:
「ゼロ円」はお金が全くない状態を示しますが、「1月10日」は「1月20日」の半分とは言えません。
このような違いが、間隔尺度の本質です。
比率尺度
絶対的なゼロ点を持つ尺度 です。
差・間隔・比率のすべてが計算可能です。
例: 体重、身長、年齢、売上金額
特徴:
- ゼロ点あり
- 四則演算・比率計算が可能
- 最も自由度の高い分析が可能
質的データと量的データの違い
データ分析において欠かせない視点、それが 質的データと量的データ の違いです。
この分類を意識することで、分析手法の選択や結果の解釈が格段に正確になります。

質的データとは?
カテゴリーや属性を示す情報 です。
基本的には文字情報であり、分類やラベル付けに使われます。
含まれる尺度:
- 名義尺度
- 順序尺度
例:
- 性別
- 血液型
- 満足度
量的データとは?
数値で構成され、計算や測定が可能な情報 です。
統計的な処理や傾向分析に適しています。
含まれる尺度:
- 感覚尺度
- 比率尺度
例:
- 売上金額
- 年齢
- 温度
なぜ分類を意識する必要があるのか?
データの性質に応じて、適切な分析手法を選択するためです。
- 質的データ → カテゴリーごとの集計や比較に適する
- 量的データ → 平均値・標準偏差などの統計量で傾向を把握
可視化手法の違い
- 質的データ → 棒グラフ、円グラフ
- 量的データ → ヒストグラム、散布図
EDAの流れ:探索的データ解析のステップ
探索的データ解析(EDA)を進めるうえで重要なのが、具体的なステップの理解です。
ここでは、実務でも活用できるEDAの流れを紹介します。
ステップ1:タスクの目的とゴールの明確化
何を達成したいのか、どんな結果を得たいのかをはっきりさせることで、使用する列や集計方法、分析の方向性が定まります。
ステップ2:データの基本情報の確認
- 列名
- 行数
- データ型
- 欠損値の有無
これらを確認することで、データの構造や内容、形式を理解できます。
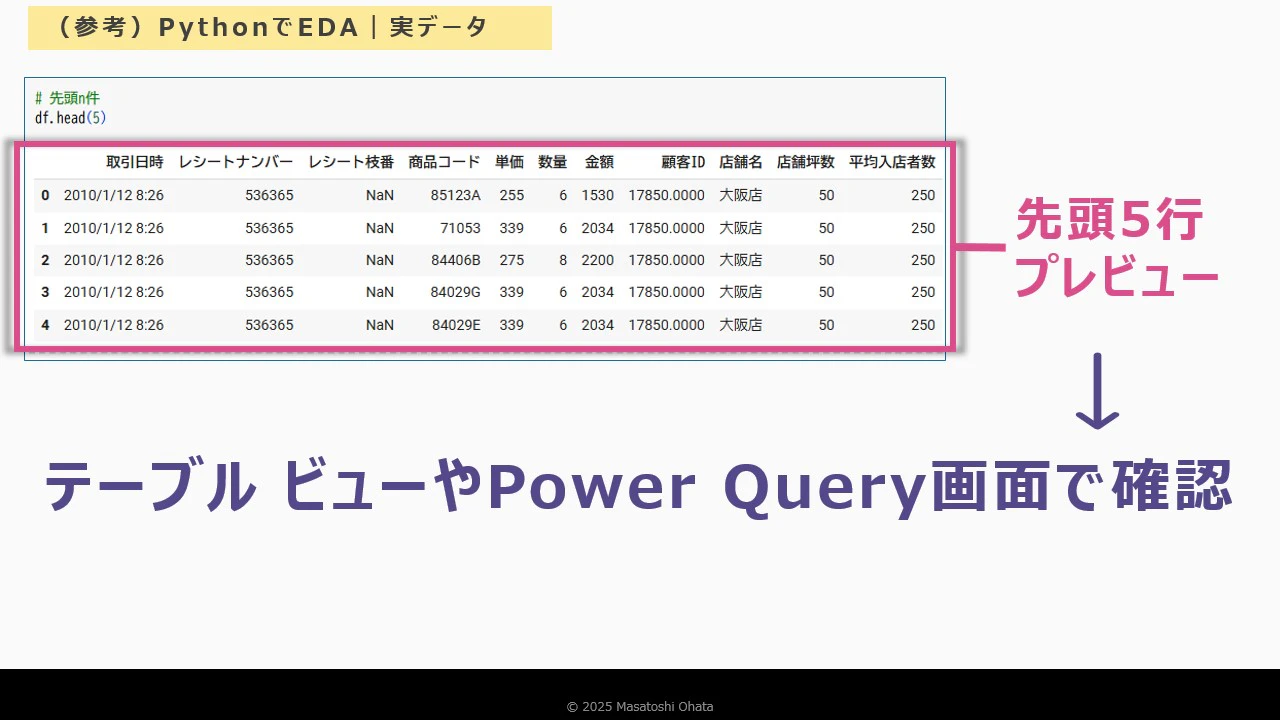
ステップ3:実データの確認
データセットの最初の数行や中間部分を確認することで、 データの中身を直感的に把握できます。
ステップ4:基本統計量の確認
- 平均値
- 標準偏差
- 四分位数
これらを計算することで、データの偏りやばらつきを把握できます。
ステップ5:分布や傾向の可視化
- ヒストグラム
- 箱ひげ図
これらの可視化を通じて、データの分布や異常値を視覚的に確認できます。
分析の精度が高まり、仮説の構築にもつながります。
Power BIによる探索的データ解析(EDA)の実践ステップ
ここでは、Power BIを使った探索的データ解析(EDA)の具体的な操作方法について紹介します。
Pythonで行うEDAと比較しながら、Power BIでの実践ステップをステップバイステップで解説します。

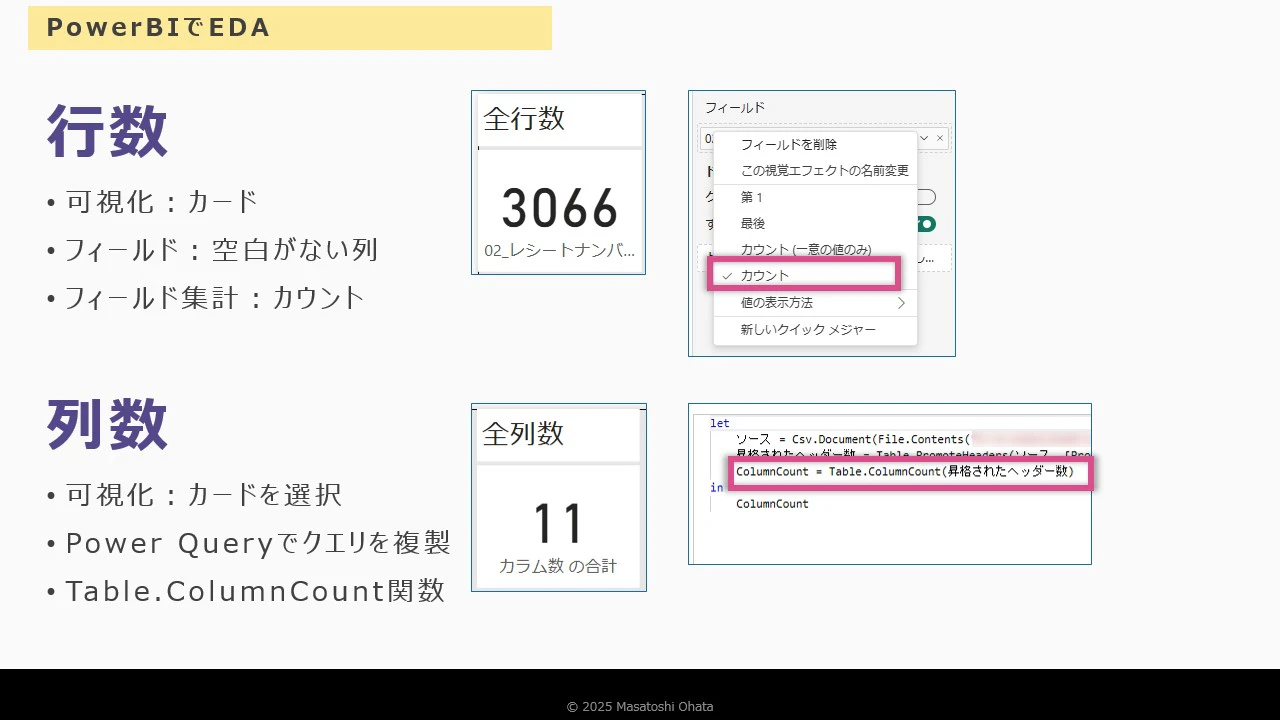
行数の確認
- カードビジュアルを使用
- 空白のない列(例:レシートナンバー)をフィールドに設定
- 集計方法を「カウント」に変更
- 今回のデモでは 3066行 が表示されました
列数の確認
- Power Queryでクエリを複製
-
Table.ColumnCount関数を使用 - カードビジュアルに設定
- 書式設定で小数点以下をゼロに調整
- 表示例:11列
列名とデータ型の確認
-
Power Queryのヘッダーで確認可能
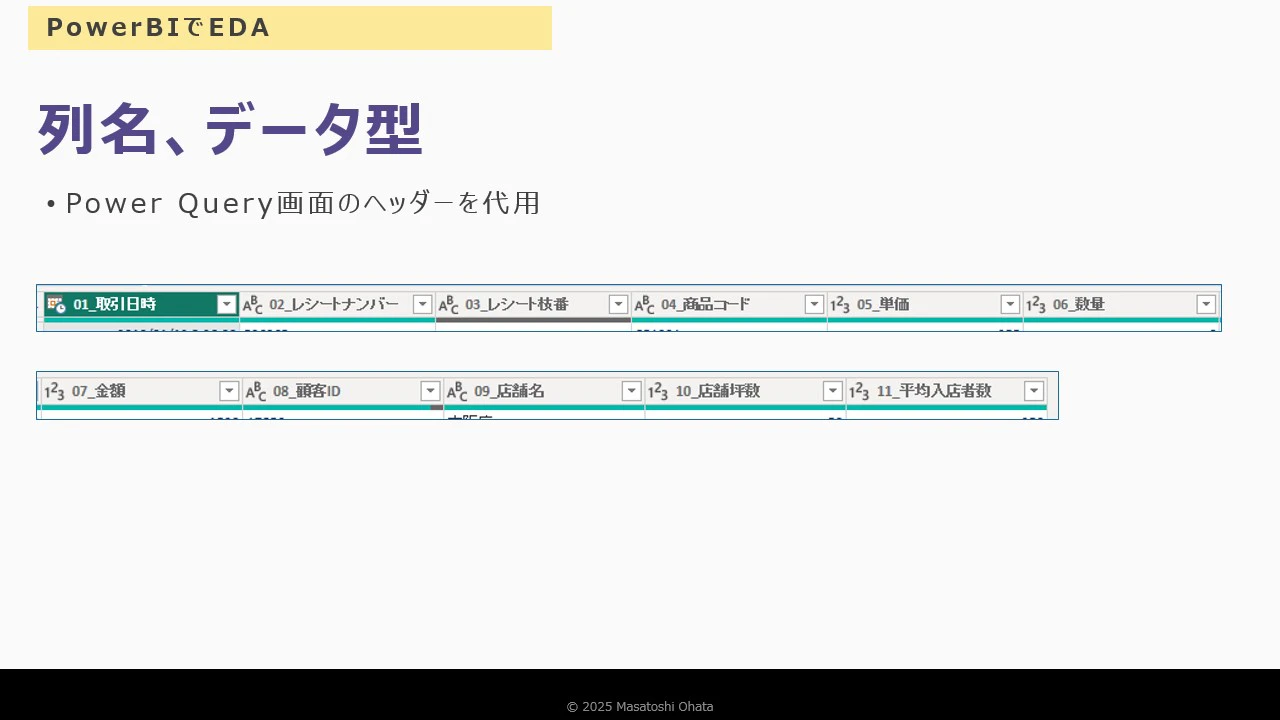
-
スクリーンショットをレポートキャンバスに貼り付けると便利
-
列名の並び順を固定するには、プレフィックス(連番)を付ける
欠損値の確認

-
ヘッダー下のバーにマウスを重ねると欠損率が表示される
-
COUNTBLANK関数でメジャーを作成
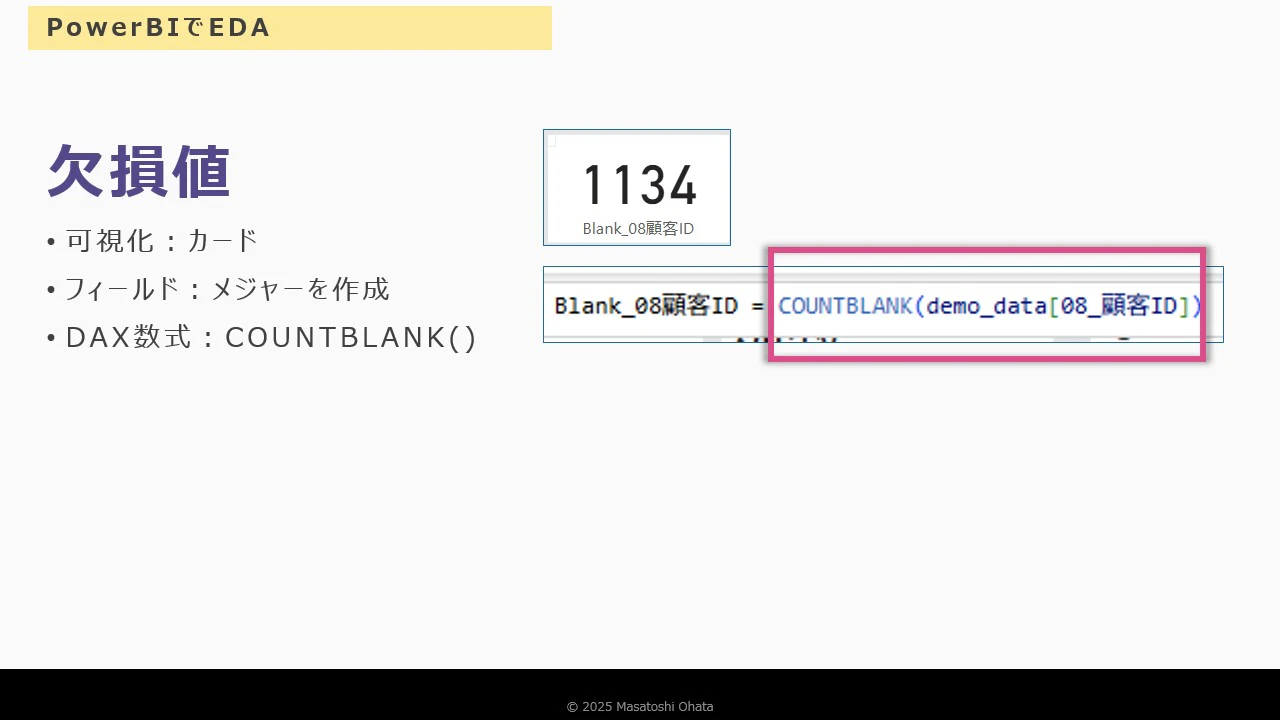
-
カードビジュアルで欠損数を表示
-
例:顧客ID列に 1134行の欠損
基本統計量の確認
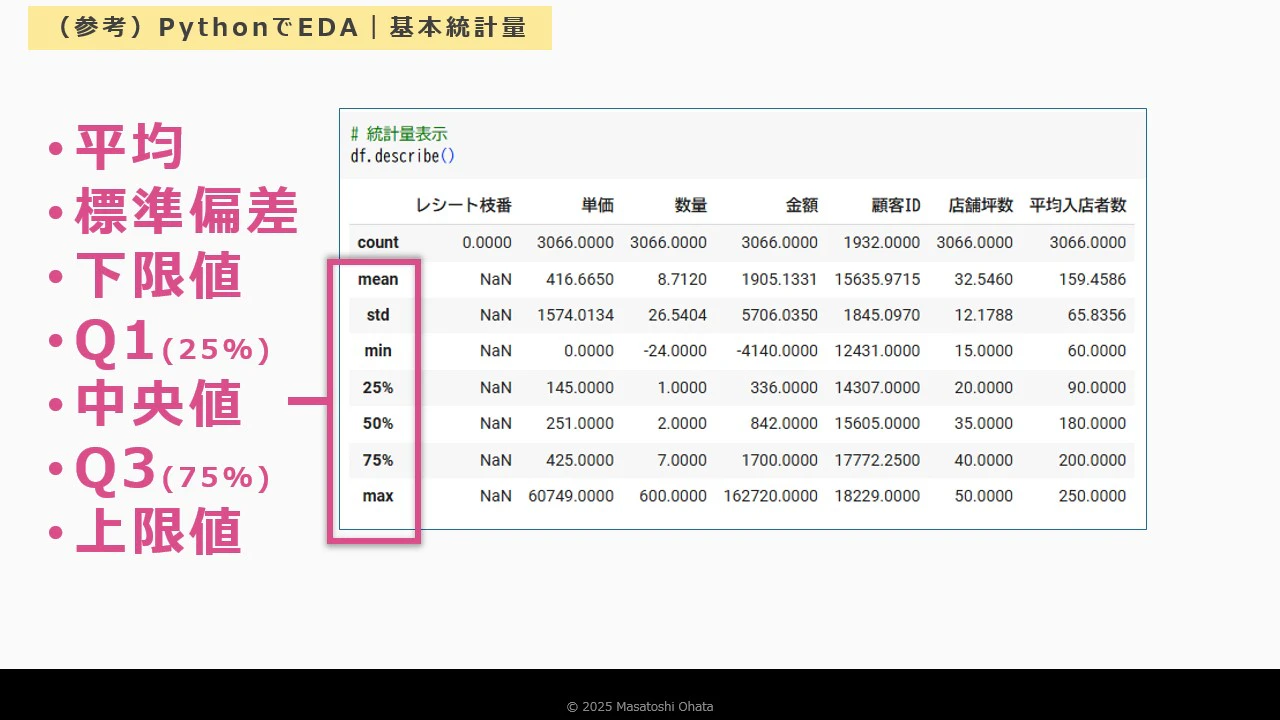
-
平均値、標準偏差、最小値、中央値、最大値 → 集計設定で算出可能
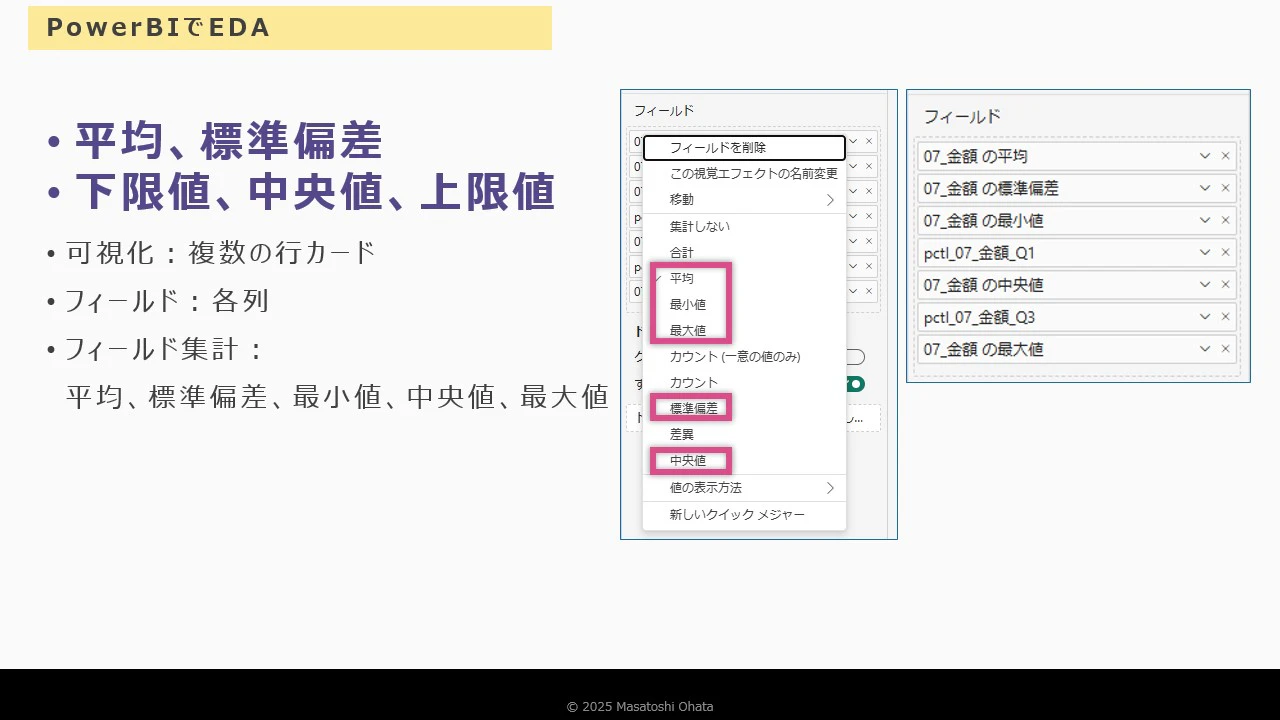
-
第一・第三四分位数 →
PERCENTILE関数でメジャーを作成
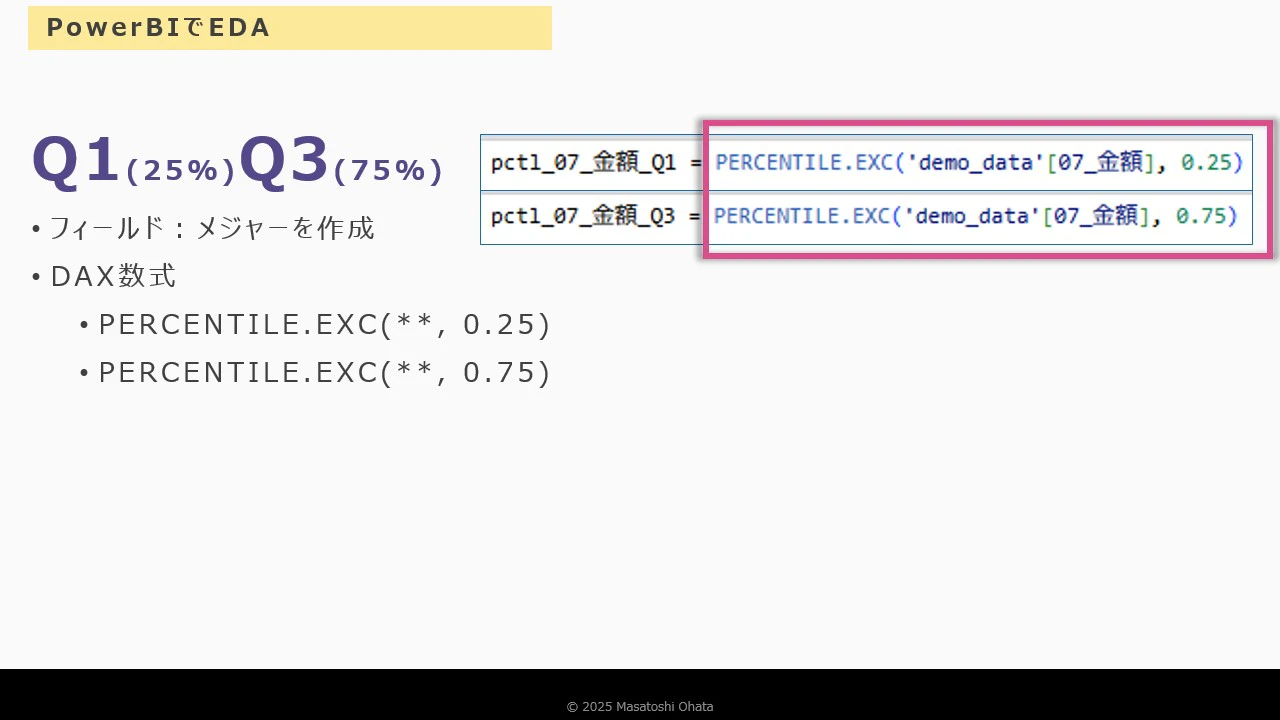
-
複数行カードに統計量を追加して表示
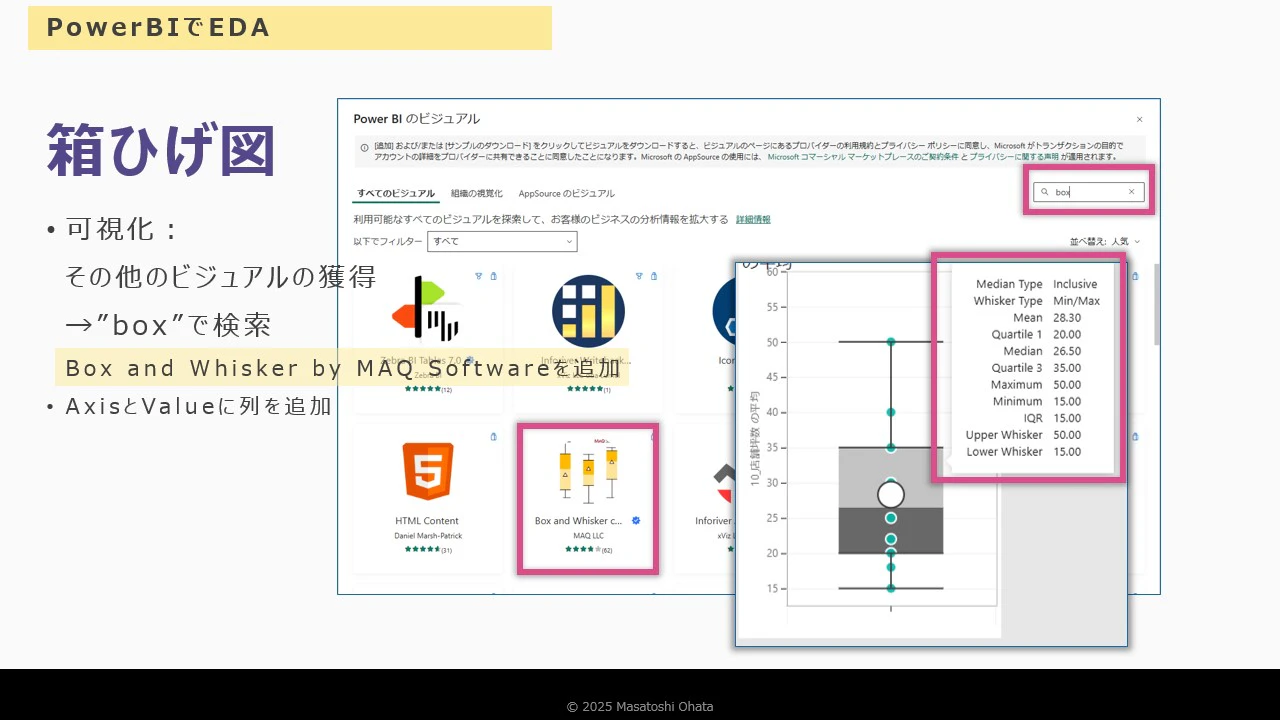
箱ひげ図の作成
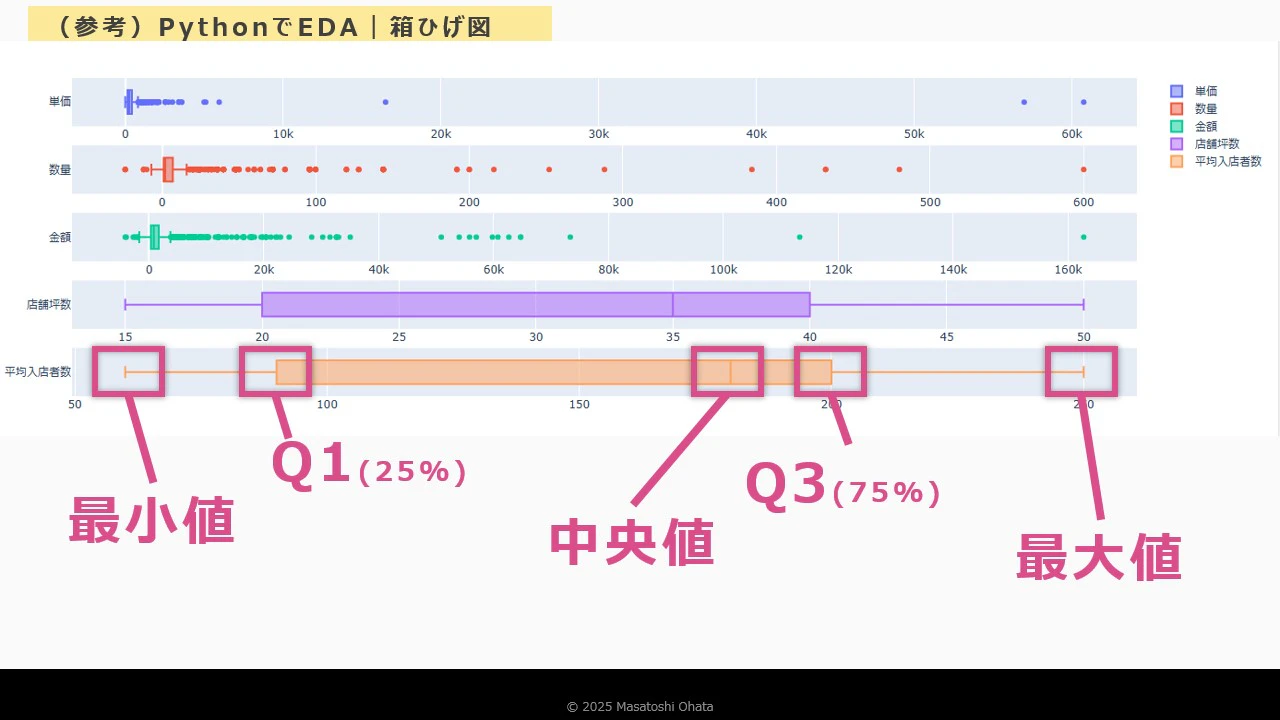
- カスタムビジュアル「Box and Whisker Chart」を追加
- 店舗の坪数などを軸に設定
- 中央値・四分位数・外れ値を視覚的に確認可能
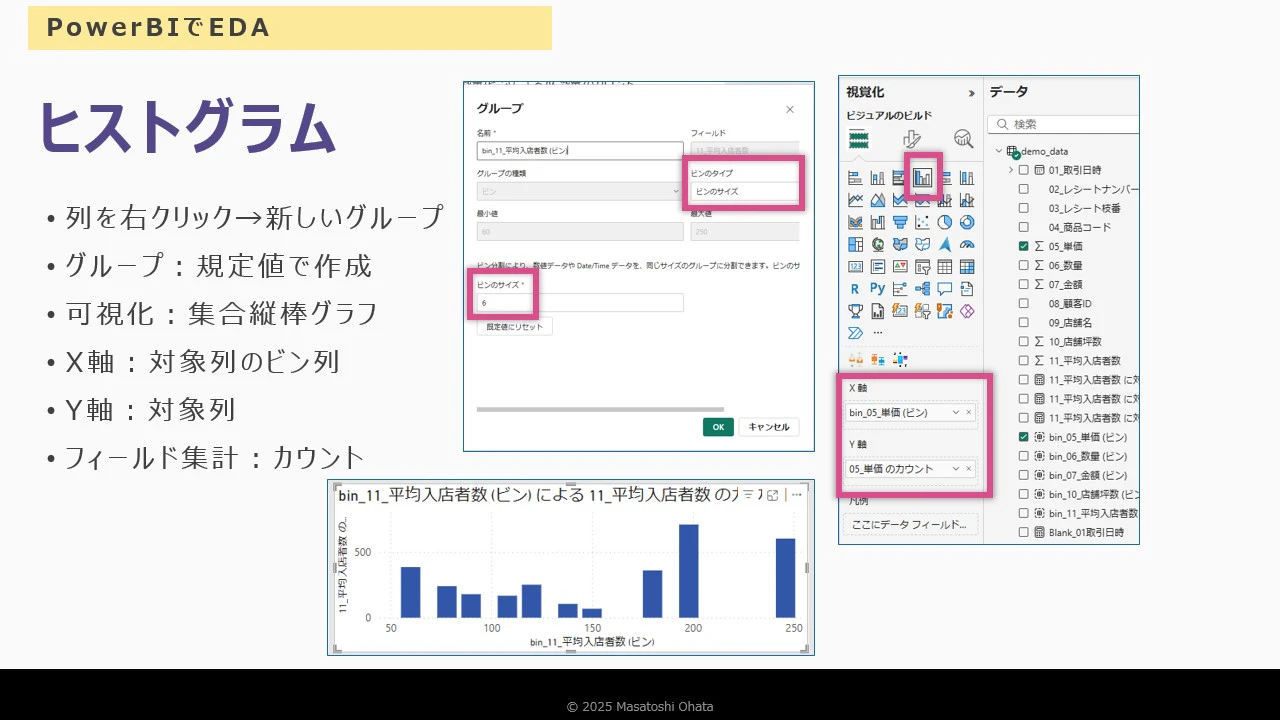
ヒストグラムの作成
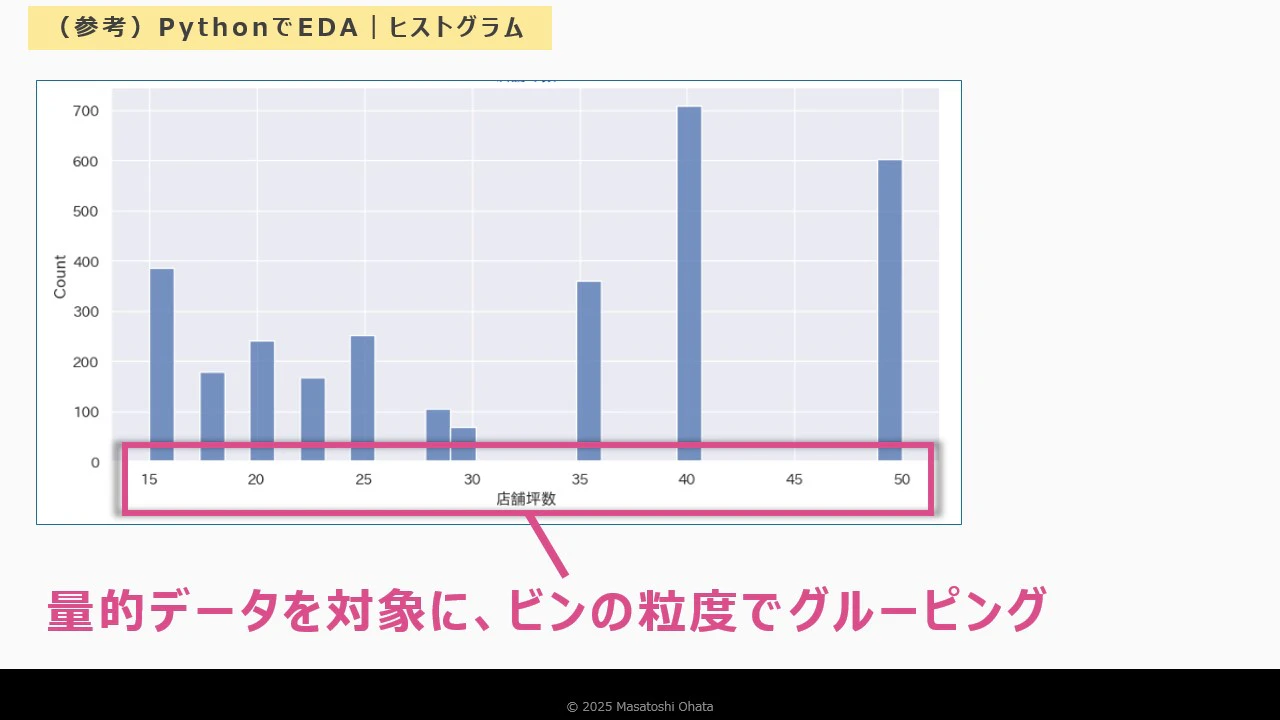
- 「グループ」機能で金額データをビン(区間)に分割
- 棒グラフで頻度を表示
- ズームスライダーで粒度を調整
- 粒度例:3000 → 500 に変更して詳細表示
散布図の確認
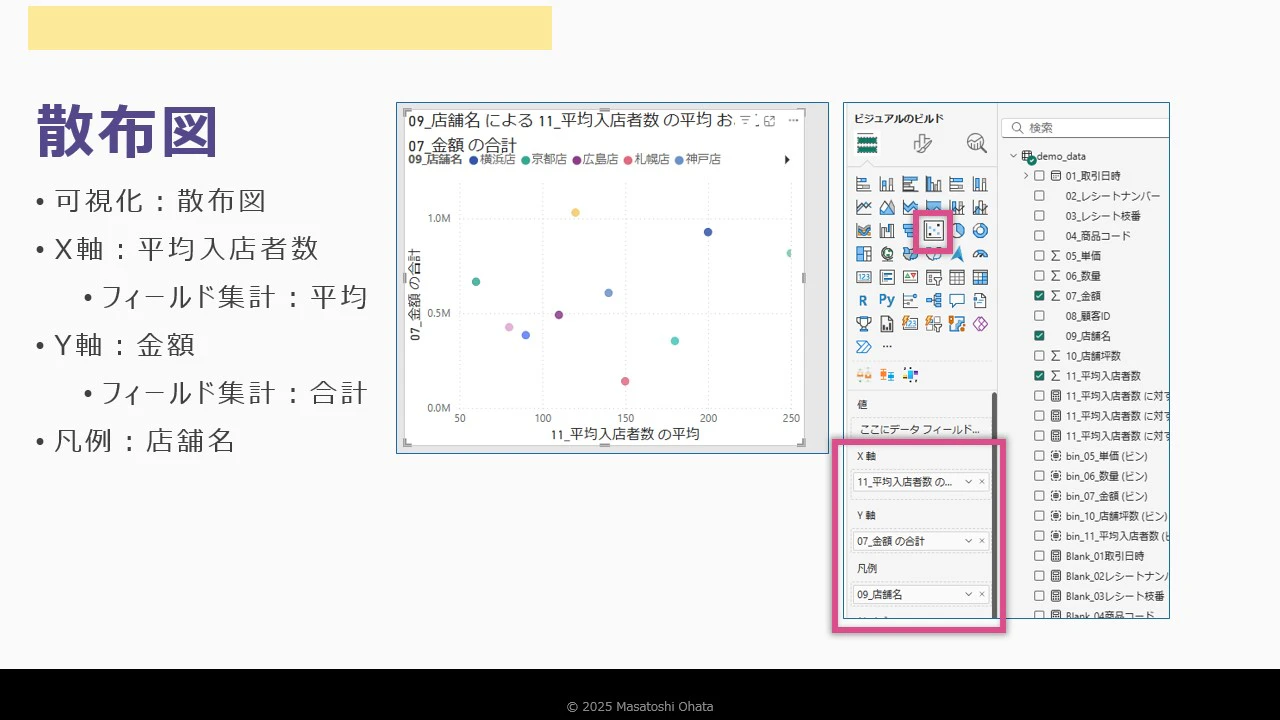
まとめ:データ理解の目的と流れ
ここまでの内容を振り返ってみましょう。
データ理解の目的 は、データの全体像を把握することです。
- パターンの探索
- 欠損値・異常値の特定
- 仮説の検証
これらのプロセスを通じて、データの信頼性を高め、分析結果の精度を向上 させることができます。
データの尺度の重要性
データの尺度 は、データの種類や性質を理解するための重要な概念です。
- 名義尺度
- 順序尺度
- 感覚尺度
- 比率尺度
それぞれ異なる特徴を持ち、適切な分析方法の選択に直結 します。
データ理解の流れ
データ理解は、以下のステップで進めます:
1. タスクの目的を決める
- 何を達成したいのか
- どんな結果を得たいのか
2. 実データや基本情報の確認
- 列名
- 行数
- データ型
- 欠損値の有無
3. 統計量や分布の確認
- 平均値
- 標準偏差
- 四分位数
- ヒストグラムや箱ひげ図による可視化
実務への応用
これらのステップを踏むことで、データの構造や特徴を深く理解し、分析に活かす ことができます。ぜひ実務でもこの流れを意識して、データ理解を実践してみてください。
また、Power BIを使えば、PythonのようなコーディングなしでEDAを実践できます。視覚的な操作でデータの構造や傾向を把握し、分析の精度を高めましょう。
YouTubeチャンネルのご紹介
YouTubeチャンネル DX塾では、Power BIやFabricを中心に、日々のデータ活用に役立つ動画を配信中です。
ぜひチャンネル登録して、スキルアップにお役立てください!
YouTubeチャンネルはこちら
最後に
📌この記事が参考になった方は、ぜひ「LGTM」や「ストック」をお願いします!
📢データ活用に興味がある方は、フォローして今後の更新もチェックしてください。