(もっといいやり方あれば教えてください。指摘も募集)ssmaというのを使えば良かったかも…
データの抽出・出力作業
使用ツール
- sqlPlus
- SQL Developer
- SQL Management Studio(ssis)
oracleDBからsql serverへDBデータの移行手順
初めてのDB移行で(sql server2016とバージョンが古いせいで)
結構時間かかったので試行錯誤した内容を載せておく。
作業内容はoracleDBのデータをCSVで出力してsql serverでCSVを取り込む。
エクスポート
最初はsqlPlusでspoolを使ってエクスポートしていた。
-- 検索結果をCSVへ出力する
-- コンソールメッセージを非表示にする
SET ECHO OFF
-- 1行に出力するバイト数
-- 少ないと見切れるので最大に設定する
SET LINESIZE 32767
-- 1ページの行数
-- 少ないとヘッダーが多くて見づらいので無制限に設定する
SET PAGESIZE 0
-- 「○○行が選択されました」メッセージを非表示にする
SET FEEDBACK OFF
-- 区切り文字をカンマに指定する
SET COLSEP ','
-- 各行の右端にあるスペースを削除する
SET TRIMSPOOL ON
-- 出力開始
-- 出力パス指定 と SELECT文
-- △マスタ(MST01)
SPOOL C:\TEMP\CSV\MST01.csv
SELECT
M01 || ',' ||
trim(M12) || ',' ||
FROM MST01;
SPOOL OFF
-- 〇〇マスタ(MST2)
SPOOL C:\TEMP\CSV\MST02.csv
SELECT
M021 || ',' ||
trim(M022) || ',' ||
trim(M023) || ',' ||
FROM MST02;
SPOOL OFF
1万件程度ならすぐだが、200万件となると1時間かかった・・・
ここに1000万件だと6時間かかると書いてある。→oracle非公式リファレンス:出力速度を10倍にする
今回は1DBで200万件を10DB分移行する必要があったので時間がかかりすぎる。
ちなみに非表示を追加してもさほど変わらなかった。
-- 非表示
SET TERMOUT OFF
そこでsqlDeveloperでエクスポートすると1時間かかっていたものがなんと5分で済んだ。
ダラダラとsqlを書く必要もない...sqlDeveloperバンザーイ!ありがとう
接続方法↓
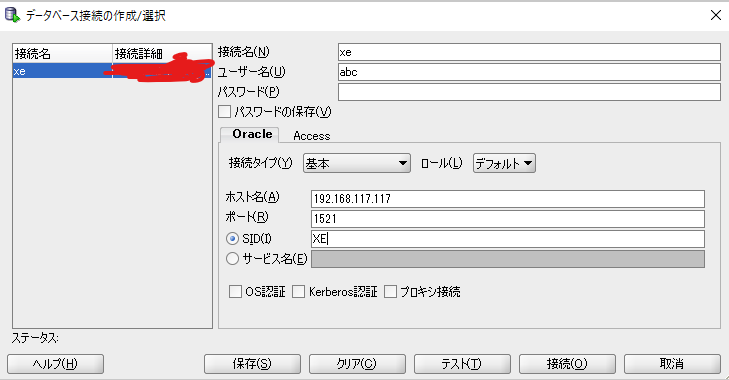
接続名:なんでもいい
ユーザ/パス:DB接続時に使うやつ
他はサーバ次第
DB右クリックからのエクスポート画面↓(複数選択可能)
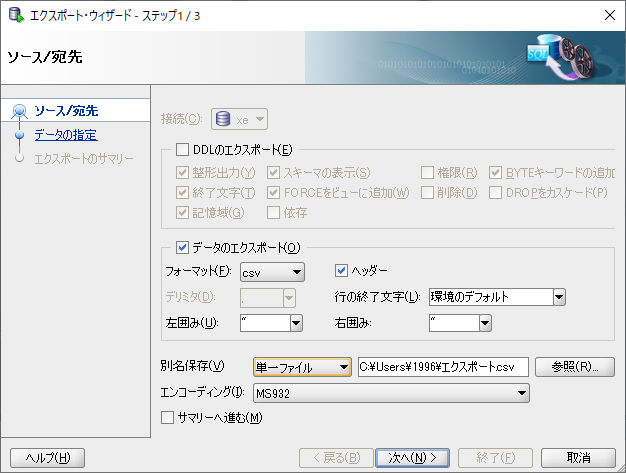
フォーマットはCSV。csvなのでデリミタ(区切り)は「,(カンマ)」になる。
のちのインポート時にデータ自体にもカンマが含まれていることがわかり、エラーが発生した為、この案は却下。
(sql serverのバージョンが2017年以降なら「,」で問題なくインポートできるらしい。一応2017バージョンのインポート文は記事最下部辺りに記載しておく。)
調べたらタブ区切りにすれば良いと書いてあったので「”」で囲むことにした。
フォーマットをTextに変更しデリミタはタブになる。tsvファイルで抽出出力を行う。
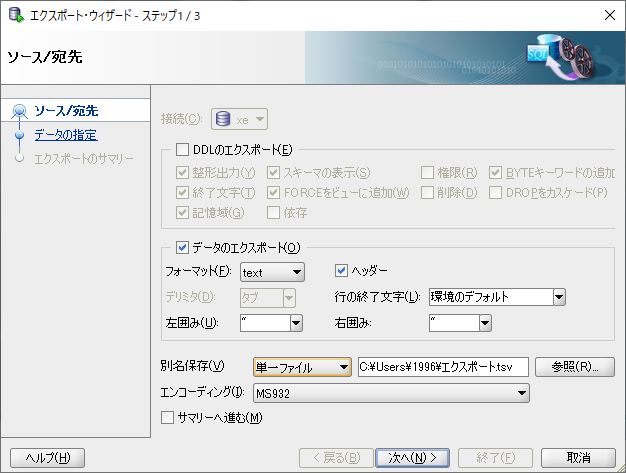
しかしこれでもインポート失敗。なんとデータにタブが含まれていた・・(なにやってんだよ..団長ぉおおお!「鉄血のオルフェンズ」)
最終的に以下に落ち着いた。
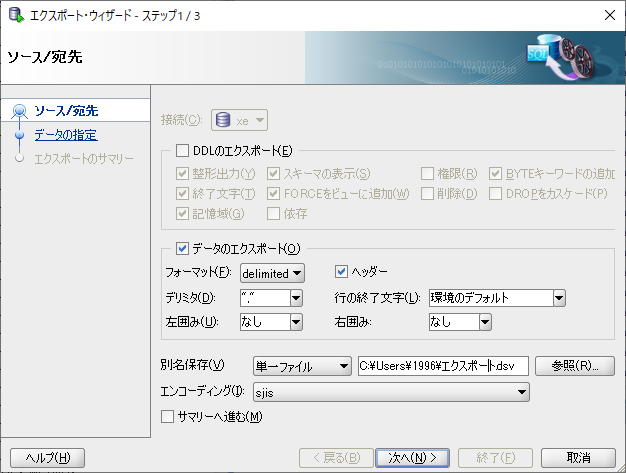
ファーマットをdelimitedにすることでデリミタを任意文字で設定できる。
左右の囲みのダブルクォーテーションは文字にしか適応されない為、
デリミタにもっていき数字を囲う形にする(じゃないとインポート時に区切りがおかしいと怒られる)。
これでインポート時の区切りの指定を「","」にすれば問題ない。
まあまたデータに","が入っていれば「"",""」とかにしてやればいいかなと。
(絶対にデータに含まれていない文字列を区切りに指定する必要があるわけだ…)
他に良い方法あれば教えてください・・・
このエクスポート画面の詳細はここ→ 参照0
ヘッダーのチェックを外せばカラムは含まれない等書いてある。
時刻取得
全エクスポート完了後に気づいた。
時刻が取得できていないということを。。
オラクルのデフォルトで表示されない設定らしい(んなアホな…)。
1番簡単なのは設定を変えてやればよい。
下の2番目の記事が参考になる。
OracleでDate型の時刻が00:00:00になる原因
Oracle SQL Developerで時刻を表示する
Oracle 非公式リファレンス
あと一応、a5m2で見る場合00:00:00のようなオール0はデフォルト非表示設定っぽいから
「ない!」って焦らないように。
それとエクスポート画面のエンコード
Sjisだと英文字が文字化けしたからデフォのMS932にした。
oracleDBのエンコードは以下SQLで確認できる。
SELECT VALUE FROM NLS_DATABASE_PARAMETERS
WHERE PARAMETER='NLS_CHARACTERSET'
インポート
ここではSQL server Management Studioを使っている。
BULK INSERTを使うとCSVを読み込めるらしい。
デリミタ変更してエクスポートしたファイル形式はdsvになるが問題ない。
DB名はドラッグ&ドロップで貼り付けが確実。
これをコピペするとバックスラッシュは「¥」に変換されるが問題ない。
BULK INSERT [DB名].[テーブル名]
FROM 'C:\CSV\あああ.dsv' --対象ファイルのフルパス
WITH ( DATAFILETYPE = 'char' --選択したデータ型で読み込み
, FIRSTROW = 2 --1行目はカラムだった為2行目スタート
, FIELDTERMINATOR = '\",\"' --区切り
, KEEPNULLS ); --NULLはNULLと入力
データにカンマがあったのでダブルクォーテーションで囲んでいる 参照1
あとタブの区切りは「¥t」と書くらしい SQLドキュメント
(sql serverのバージョン2017年以降のパターン↓)
BULK INSERT [DB名].[テーブル名]
FROM 'C:\CSV\あああ.csv' --対象ファイルのフルパス
WITH ( FORMAT = 'CSV' --CSVファイル指定
, DATAFILETYPE = 'char' --選択したデータ型で読み込み
, FIRSTROW = 2 --1行目はカラムだった為2行目スタート
, FIELDTERMINATOR = ',' --区切り
, KEEPNULLS ); --NULLはNULLと入力
照合順序変更
インポート時の重複エラーが発生。
オラクルでは問題なかったのに、、
よく見ると大文字小文の区別をしていない。
sql serverはデフォルトで区別をしないようだ
データベースを右クリック→プロパティから編集が可能↓
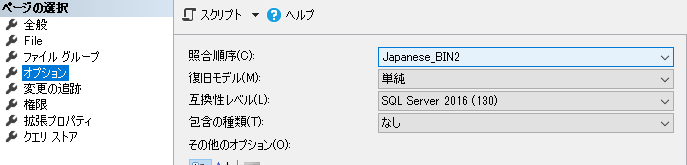
しかしこれでは新規追加されたテーブルにしか反映されないらしい・・・
テーブル→列→対象列名→右クリック→プロパティから照合順序を確認したら確かに変わっていなかった。
カラムをSQL文で編集する必要があるらしいが、面倒なのでテーブルを作り直した。
COLLATEというのを使い照合順序を指定できる。詳しくはドキュメント→ 列の照合順序の設定または変更
空白削除
データの空白削除を行い忘れたのでtrimしようとしたらsql serverにはそもそも関数がないそうで。。
rtrimとltrimに別れているようだ。
丁度右端だけ削除したかったので以下のようにした。
UPDATE [DB名].[テーブル名] SET カラム名 = RTRIM(カラム名);
インポート時(SQL server Management Studio)で起こったエラー
メッセージ 208、レベル 16、状態 82、行 1
オブジェクト名 '〇〇' が無効です。
接続先を間違えている。対象のテーブルを選択後に新しいクエリを作成する。それか単にDB.テーブル名を間違えてるか。
メッセージ 4860、レベル 16、状態 1、行 1
一括読み込みできません。ファイル "〇〇" が存在しません。
これはパスを間違えいるか、ファイルがないか。注意点はインポートするファイルをインポート先サーバーにもっていかないといけない。
おまけ
2014年に処理速度を計っている人がいたのでのせておく
OracleからのCSV出力を考える