概要
やったこと
データ分析をしていると、ブートストラップサンプリングを(リンクのノンパラメトリック)したくなることがあります。
※ブートストラップ法の説明はここではしません。
PythonやRのライブラリでサンプリングできますが、BigQueryからデータを移行する必要があります。
面倒くさいのでSQLオンリー(BigQuery Scriptingを利用していますが)で処理できると嬉しいので作成しました。
注意
現状、以下の問題点があります。
- 今回のやり方はコンピューティング層とストレージ層を行き来し、終始オンメモリで実行できる訳ではないので実行時間はかなり遅いです。
- また、BigQuery Scriptingを使用しているためスキャン量の推測が見れません。データ量や試行回数が多くなるとスキャン量は指数関数的に増えます。
- 時間単位でテーブルへの書き込み制限がある場合、試行回数を大きくするとエラーになります。
PythonやRで楽に処理(BigQueryのテーブルをそのまま読み込める頭)できるなら、そちらを強くおすすめします(悲しい)。
今後の展望
オンメモリで処理する上手いやり方があるかもしれないので、模索したいと思います。
BQはJavascriptでもデータ処理できるので、そちらで実装した方が早くて安いかもしれません。
もし良いやり方がありましたらご教示くださいm(_ _)m
実験用データの作成
まずはこちらで実験用の正規分布に従った乱数をSQLで作成します
-- 乱数作成パラメータ
DECLARE population_sample_number INT64;
SET population_sample_number = 10;
-- 正規分布乱数の作成
CREATE OR REPLACE TEMP TABLE norm_sample AS (
WITH
generate_random AS (
SELECT
index,
RAND() AS x,
RAND() AS y,
FROM (SELECT GENERATE_ARRAY(1, population_sample_number, 1) AS idx)
,UNNEST(idx) AS index
)
,
generate_norm AS (
SELECT
index,
SQRT(-2*LOG(x))*COS(2*ACOS(-1)*y) AS norm
FROM generate_random
)
SELECT
*
FROM generate_norm
);
norm_sampleの中身↓
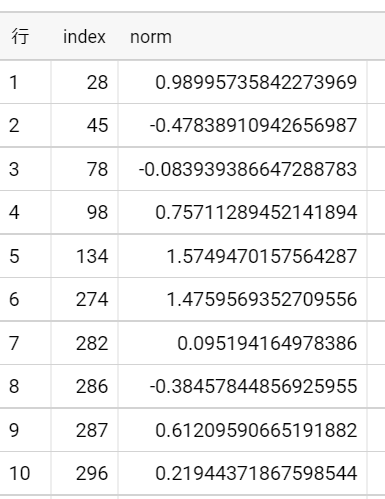
試しにサンプルサイズ10,000で乱数を生成すると、
平均は-0.0006849098015
不偏分散は1.00165907
になりました。
平均0、分散1の標準正規分布の乱数になってそうですね。
復元抽出でリサンプリング
-- 再標本化パラメータ
DECLARE seed INT64;-- 乱数生成のシード値
DECLARE trial_number INT64;-- 施行回数
DECLARE resample_number INT64;-- サンプルサイズ
DECLARE i INT64;
DECLARE seed_array ARRAY<INT64>;
SET trial_number = 10; -- 試行したい回数を入力
SET resample_number = 10; -- サンプルサイズを入力
SET seed_array = GENERATE_ARRAY(1,trial_number,1);
SET i = 0;
WHILE i < trial_number DO
SET seed = (SELECT seed_array[OFFSET(i)]);
IF i = 0 THEN
CREATE OR REPLACE TEMP TABLE resample_table AS (
SELECT
STRUCT(i AS iter_number, resampled) AS iter_table
FROM(
WITH
sample_index AS(
SELECT
ABS(MOD(FARM_FINGERPRINT(CONCAT(SAFE_CAST(index AS STRING),SAFE_CAST(seed AS STRING))),resample_number)) + 1 AS index
FROM (SELECT GENERATE_ARRAY(1, resample_number, 1) AS idx),UNNEST(idx) AS index
)
,
resample AS (
SELECT
*
FROM sample_index
JOIN norm_sample USING(index)
)
SELECT
ARRAY_AGG(STRUCT(index, norm)) AS resampled
FROM resample
)
);
ELSE
CREATE OR REPLACE TEMP TABLE resample_table AS (
SELECT * FROM resample_table
UNION ALL
SELECT
STRUCT(i AS iter_number, resampled) AS iter_table
FROM(
WITH
sample_index AS(
SELECT
ABS(MOD(FARM_FINGERPRINT(CONCAT(SAFE_CAST(index AS STRING),SAFE_CAST(seed AS STRING))),resample_number)) + 1 AS index
FROM (SELECT GENERATE_ARRAY(1, resample_number, 1) AS idx),UNNEST(idx) AS index
)
,
resample AS (
SELECT
*
FROM sample_index
JOIN norm_sample USING(index)
)
SELECT
ARRAY_AGG(STRUCT(index, norm)) AS resampled
FROM resample
)
);
END IF;
SET i = i + 1;
END WHILE;
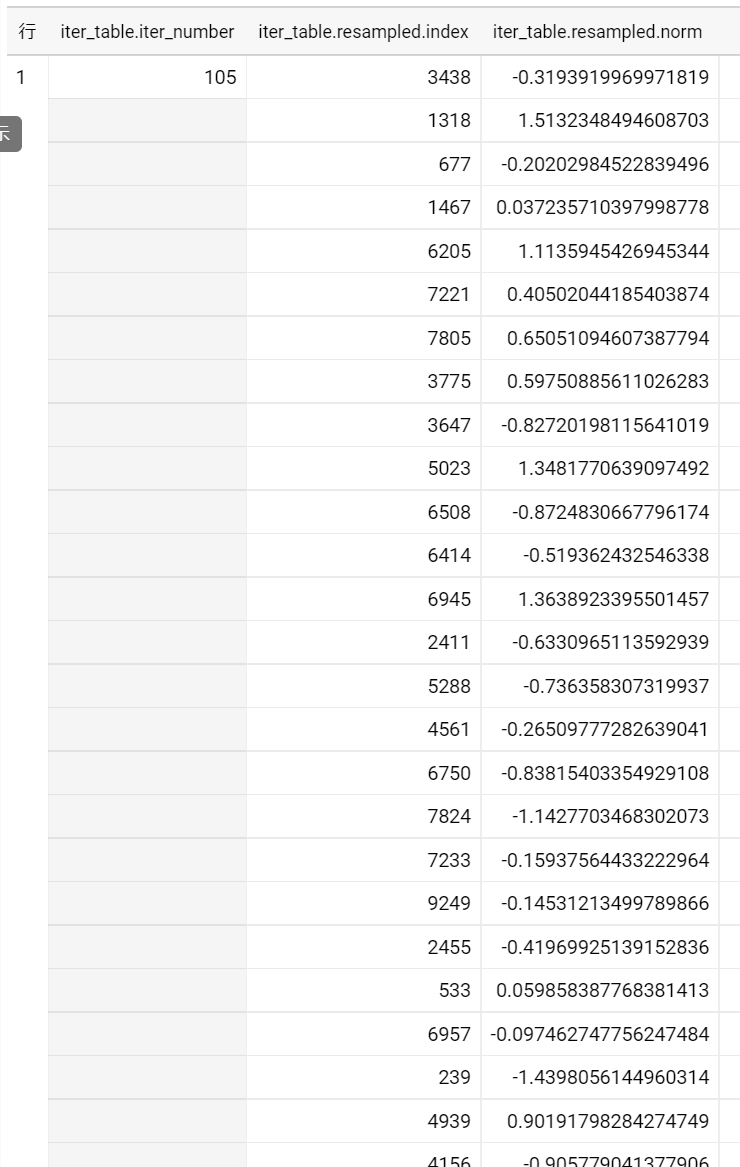
resample_tableの中身↓
試行回数毎にARRAY型でサンプルを保持しています。
集計して結果を確認
先程作成した乱数を使って、以下のパラメータで試してみました。実行時間は約6分です。
trial_number(試行回数) = 100;
resample_number(サンプルサイズ) = 10000;
以下のクエリで集計し、結果を確認しました。
-- 集計
WITH
unnest_table AS (
SELECT DISTINCT
iter_table.iter_number,
sample.index,
sample.norm
FROM resample_table
,UNNEST(iter_table.resampled) AS sample
)
SELECT
iter_number,
AVG(norm) AS average,
VAR_POP(norm) AS var,
FROM unnest_table
GROUP BY iter_number
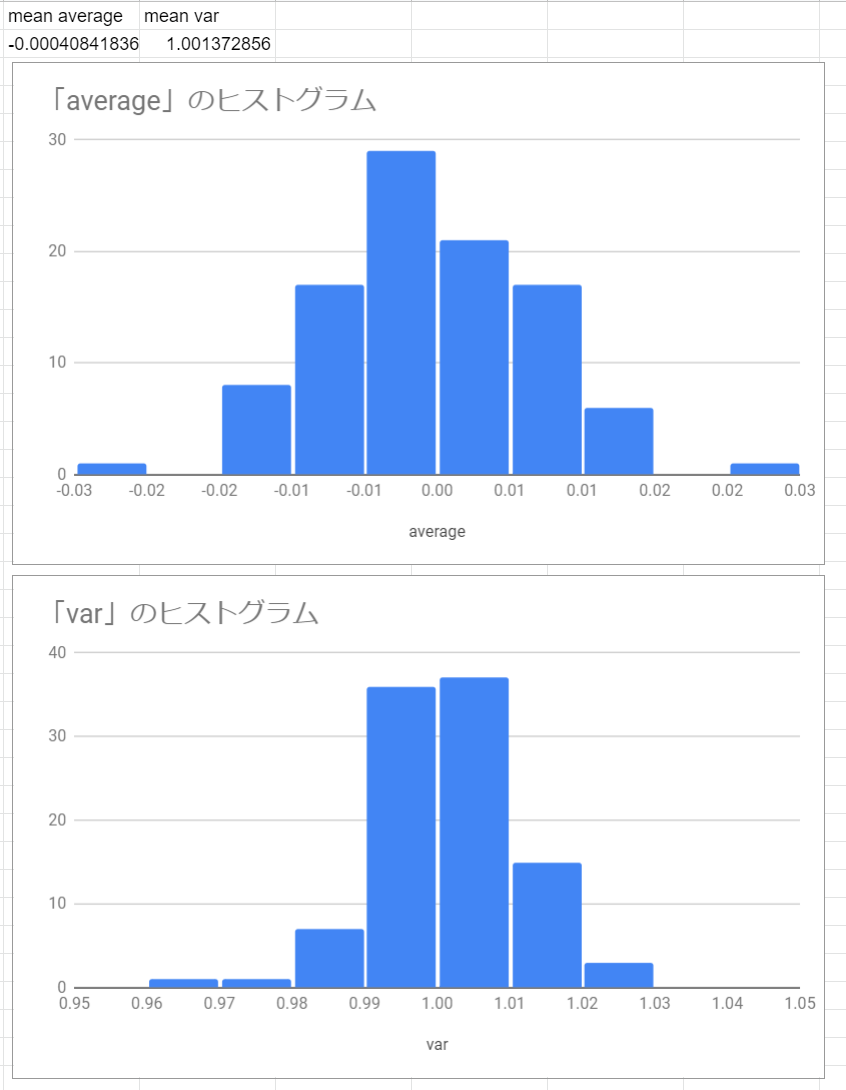
以下のような結果になりました。
概ね、先程作成したサンプルの特徴を反映してそうです。