
はじめに
前回と前々回は、browser-useに関する記事を投稿し、AIが自律的にWebブラウザを使ってコンテンツ情報を取得する仕組みについて解説しました。今回は、Webブラウザを介さずに「スクレイピング」という手法でコンテンツ情報を取得するツール、Firecrawlを試してみます。
ただし、「スクレイピング」は誤った使い方をすると他のWebサイトに迷惑をかけたり、トラブルを引き起こす可能性があります。そのため、ご自身が管理しているWebサイトや利用許可を得たサイトでのみ実施するようにしてください。
それでは、Firecrawlを使ったスクレイピングに挑戦してみましょう!
Firecrawlについて
Firecrawlは、指定したURLをクロールし、その内容をマークダウン形式や構造化データに変換するAPIサービスです。手軽にウェブ情報を整理・変換できるため、データ収集や分析に役立つツールです。
今回は、以下の公式ドキュメントに掲載されているプログラムを参考に進めていきます。
FirecrawlからAPIキーを取得する方法
Firecrawlを使用するには、まずAPIキーを取得する必要があります。以下の手順に従ってAPIキーを取得してください。
サインイン
Firecrawl公式サイトにアクセスします。
サインインまたは新規登録を行うため、以下のリンクをクリックしてください:
APIキーの確認
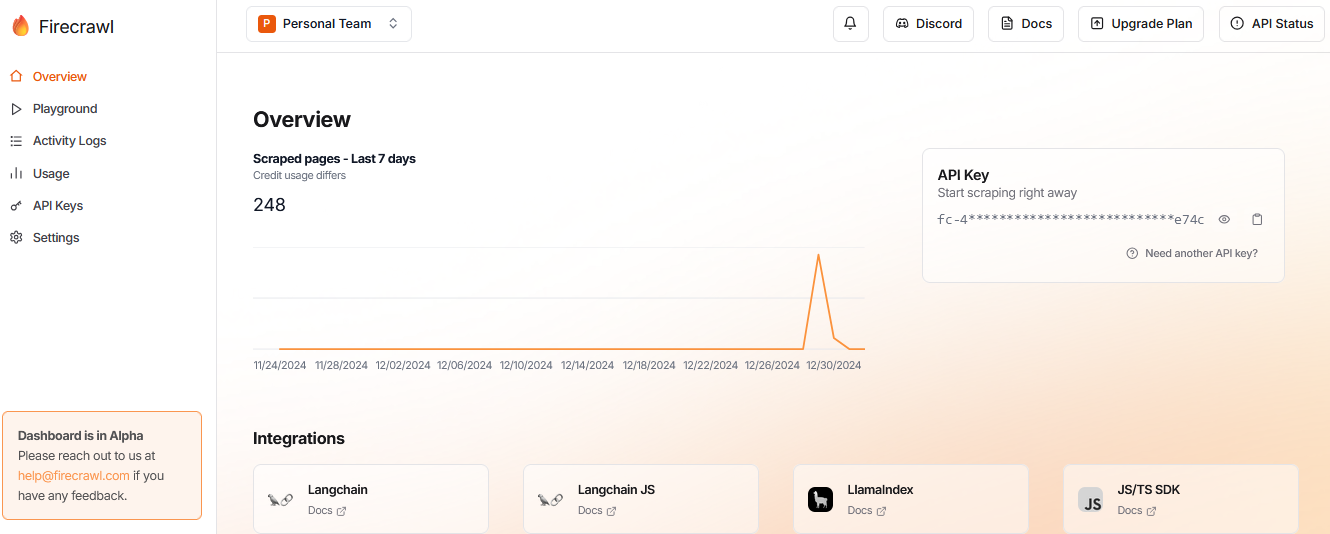
サインイン(またはログイン)後、ダッシュボードが表示されます。
画面右側に「API Key」の欄があり、「fc-***********」と表示された部分がAPIキーです。このキーをコピーしておきましょう。
環境変数にAPIキーを設定
前回の記事でも説明しましたが、APIキーをコードに直接書き込むと、GitHubにソースコードをアップロードする際などにセキュリティ上の問題が発生します。そのため、APIキーは環境変数に設定して管理するのがおすすめです。
コマンドプロンプトで以下のコマンドを実行して設定します。
SET FIRECRAWL_API_KEY=fc-******************
または、Windowsの環境設定ダイアログから、手動で環境変数を追加してください。
この方法を使用すると、プログラム内で環境変数を利用してAPIキーを安全に扱うことができます。
プログラミング
以下に今回のプログラムを示します。特に注目すべきポイントについても解説しています。
また、このプログラムはGitHubにapp2.pyとして公開していますので、自由にダウンロードしてご利用ください。
import datetime
import pytz
from firecrawl import FirecrawlApp
import os
# 日本時間の設定
JST = pytz.timezone('Asia/Tokyo')
# 出力ファイル名(タイムスタンプ付きで重複防止)
output_filename = f"crawl_results_{datetime.datetime.now(JST).strftime('%Y-%m-%d-%H-%M-%S')}.txt"
# Firecrawlの初期化とクロール実行
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
params = {'crawlerOptions':{'excludes':['blog/*']}}
crawl_result = app.crawl_url('www.npwitys.com', params=params)
# 結果をテキストファイルに出力
with open(output_filename, 'w', encoding='utf-8') as f:
for result in crawl_result:
f.write(result['markdown'] + '\n')
print(f"クロール結果を {output_filename} に出力しました。")
特筆する点
今回のプログラムでは、利用するライブラリ「firecrawl-py」およびプログラム内で活用している「FirecrawlApp」について以下のように説明します。
1. firecrawl-pyについて
Firecrawlを利用するには、事前にライブラリ「firecrawl-py」をインストールする必要があります。
ただし、最新版のライブラリを使用するとエラーが発生することが判明したため、以下のように特定のバージョンを指定してインストールしました。
pip install firecrawl-py==0.0.16
なお、GitHubリポジトリにはrequirements.txtが用意されています。そのため、以下のコマンドを実行すれば必要なライブラリが全てインストールされ、バージョンも自動的に適切なものが設定されます。
pip install -r requirements.txt
2. FirecrawlAppについて
プログラムでは、FirecrawlのAPIキーを環境変数から取得しています。以下のコードがその処理部分です。
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
また、特定の条件でデータを抽出するため、抽出条件を以下のように設定しています。この例では、blogパスに一致するものを除外しています。
params = {'crawlerOptions': {'excludes': ['blog/*']}}
さらに、対象のURLとして、私個人のホームページwww.npwitys.comを指定しています。
crawl_result = app.crawl_url('www.npwitys.com', params=params)
これらのポイントを参考にしながら、プログラムをカスタマイズしてご利用ください。
実行
それでは、プログラムを実行してみましょう。
python app2.py
実行すると、以下のようにホームページのコンテンツ情報を取得し、テキストファイルに保存できました。

おわりに
今回のプログラムでは、コンテンツ情報をテキストファイルに出力するところまでは実現できましたが、この結果だけでは実用性に欠ける部分があります。
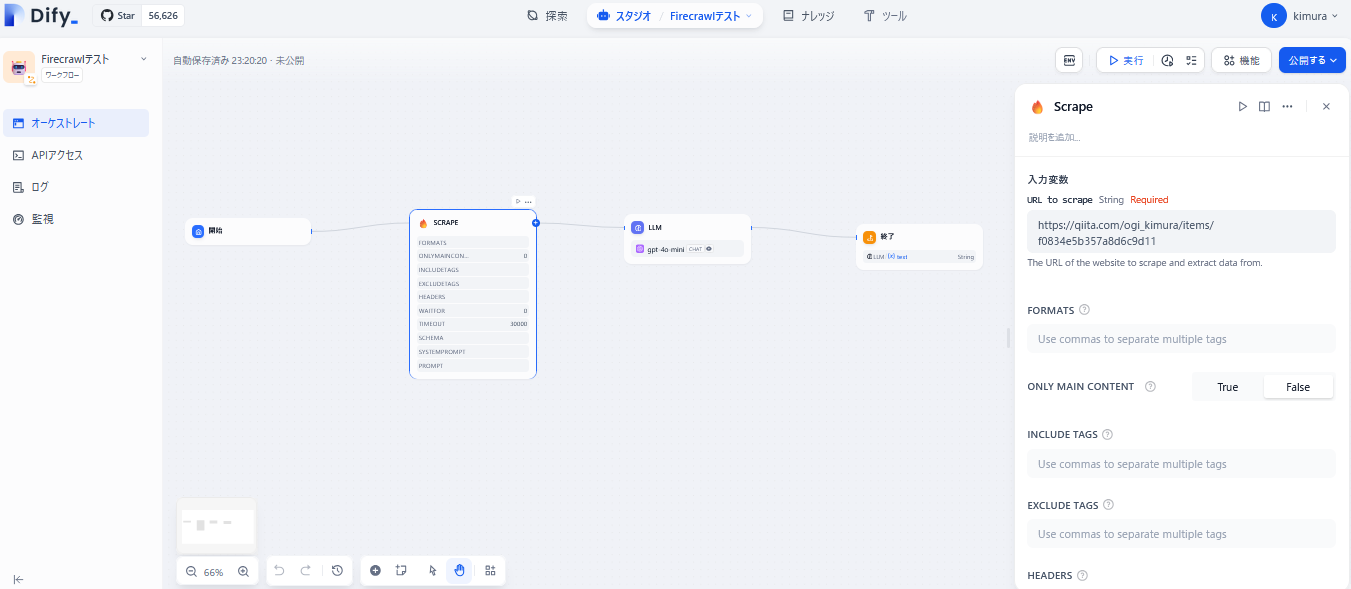
一方で、他の投稿記事やYouTubeを調べたところ、Difyを使えば、より視覚的で簡単にFirecrawlを活用できることが分かりました。次回は、Difyの「ワークフロー機能」を使って、さらに高度な処理を試してみたいと思います。
下図のように、Difyではワークフローを作成して効率的に操作を行えるようです。
最後までお読みいただき、ありがとうございました!