
はじめに
MBA取得に向けた小論文や面接の準備に追われていたため、ここしばらく記事を書く時間がありませんでした。しかし、会社が冬期休暇に入り、少し余裕ができたので、久しぶりに記事を書いてみることにしました。
最近、browser-useというPythonライブラリが登場したことを、Google検索などで知りました。以前、seleniumを使ったWebブラウザ操作の自動化に関する記事を投稿しましたが、このbrowser-useはよりインタラクティブな操作が可能で、将来的な可能性を大いに感じています。
今回は、このbrowser-useを使ったプログラミングに挑戦し、その使い勝手や将来性について確認してみたいと思います。
browser-useの特徴
browser-useは、Pythonで開発されたライブラリで、「AIエージェントがウェブブラウザを操作できるようにする」ことを目的としています。このライブラリを使うことで、AIエージェントが自律的に考えながらブラウザ操作を行うことが可能になります。
多くの記事で詳しく解説されていますが、seleniumや従来のスクレイピングとの大きな違いは、AIエージェントが試行錯誤を繰り返しながら目的を達成しようとする点にあると感じています。後ほどご紹介する標準出力の内容からも、その様子を垣間見ることができるのではないかと思います。
今回のお題
LLM - 大規模言語モデルは、学習データが過去の情報に基づいているため、最新の情報に対応するのが難しいことがあります。そこで今回は、生成AIが最近のホットな話題についてどこまで対応できるのかを確認してみたいと思います。
最近、タレントの中居正広さんが週刊誌で取り上げられているとのことで、この話題をAIに質問してみます。
質問内容: 「中居正広さんは示談金を支払ったが、何があったのか?」
このテーマでAIがどのような回答を出すのかを検証してみます。
環境構築とソースコード
今回は、@むさし さんが投稿された記事を参考にしながら、サンプルコードを作成しました。むさしさん、非常にわかりやすい記事をありがとうございます!
環境構築
これまでは、pipを直接使用してライブラリをPCにインストールしていましたが、この方法では他のプロジェクトに影響を与える可能性があります。そこで、今回は仮想環境を利用して構築を進めます。また、この環境をそのままGitHubに公開し、同梱の「requirements.txt」を使えば誰でも簡単に同じ環境を再現できるようにしました。
まず、プロジェクト専用の仮想環境を作成します。
python -m venv myenv
実行後、カレントディレクトリ直下にmyenvというフォルダが作成され、その中に必要最低限のライブラリが準備されます。
仮想環境の有効化
次に仮想環境を有効化します。Windowsの場合、以下のコマンドを実行してください。
.\myenv\Scripts\activate
LinuxやMacOSの場合は、コマンドが異なるため、それぞれの環境に合った方法を調べてください。
仮想環境が有効化されたら、次にライブラリをインストールします。リポジトリに含まれるrequirements.txtを利用すれば、必要なライブラリを一括でインストールできます。
pip install -r requirements.txt
これで、仮想環境と必要なライブラリのセットアップが完了です。
GitHubリポジトリの利用
サンプルプログラムとrequirements.txtは以下のリポジトリで公開しています。必要に応じてダウンロードしてご利用ください。
ダウンロード後、仮想環境を作成したフォルダで作業を進めてください。
プログラムソースコード
以下が今回実装したプログラムです。このプログラムでは、生成AIに「中居正広さんが示談金を支払った理由」を質問し、日本語で結果を取得します。
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
STR_JAPANESE = "日本語で訳して。"
async def main():
agent = Agent(
task="中居正広は示談金を支払ったが、なにがあった?" + STR_JAPANESE,
llm=ChatOpenAI(model="gpt-4o-mini"),
)
result = await agent.run()
print(result)
print('\n')
print('【ここから】')
if len(result.history) > 0:
print(result.history[len(result.history)-1].result[0].extracted_content)
asyncio.run(main())
このコードは、@むさし さんのプログラムを元に作成しています。一部改良を加えた点について説明します。
改良ポイント
1. AIエージェントに渡すパラメータの変更
以下の部分で、AIエージェントに渡すtaskを修正しました。また、STR_JAPANESEを追記することで、日本語で回答を取得するようにしています。
agent = Agent(
task="中居正広は示談金を支払ったが、なにがあった?" + STR_JAPANESE,
llm=ChatOpenAI(model="gpt-4o-mini"),
)
さらに、コスト削減のため、モデルに「gpt-4o-mini」を指定しています。
2. 出力部分の調整
以下のコードでは、AIの出力内容を見やすくするために、historyからextracted_contentだけを表示するようにしています。
print('【ここから】')
if len(result.history) > 0:
print(result.history[len(result.history)-1].result[0].extracted_content)
これにより、必要な情報だけを簡潔に確認できるようにしました。
以上で環境構築から実装までの解説を終わります。このプログラムを参考に、ぜひ試してみてください!
実行結果
さっそくプログラムを実行してみます。
実行時の出力
以下は、実行中のCUIのスクリーンショットです。
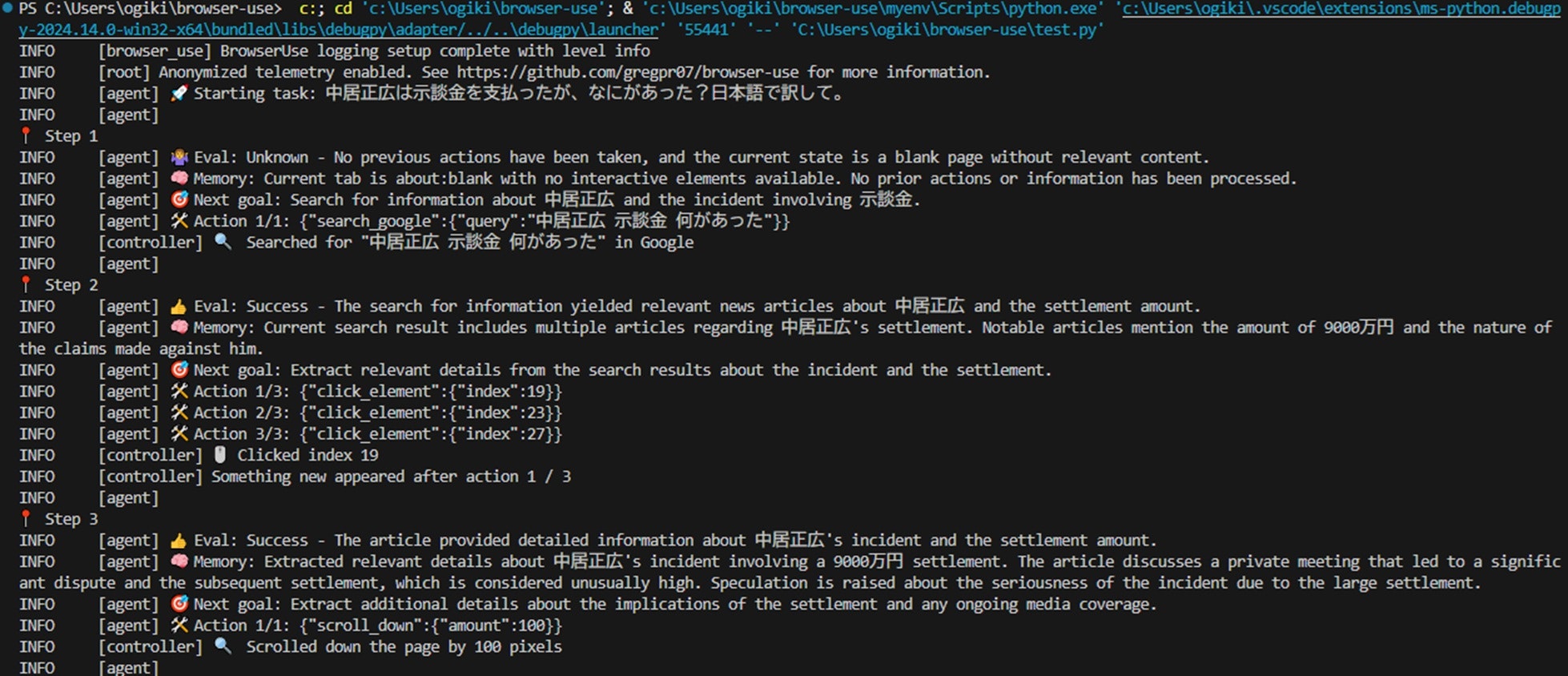
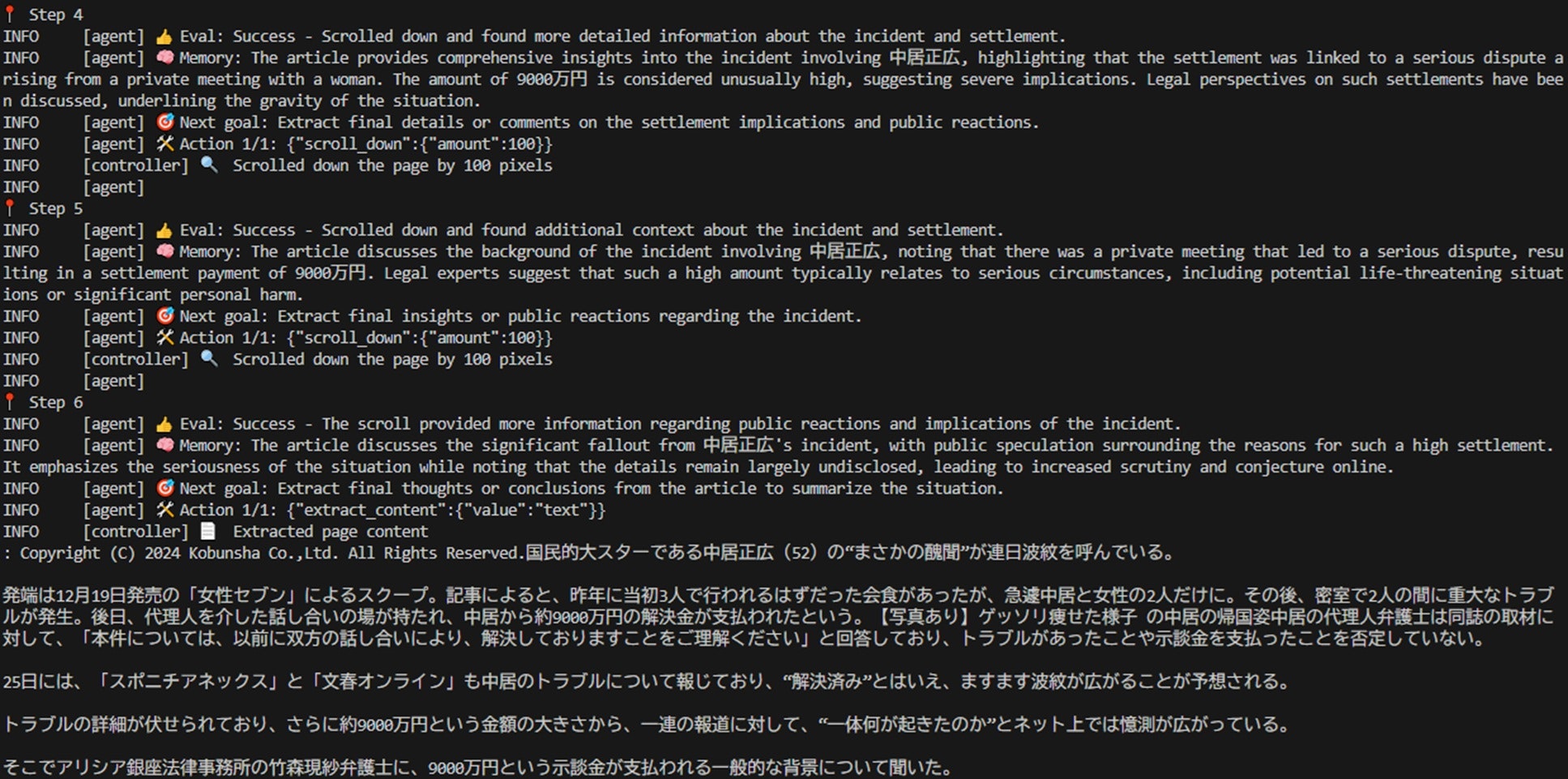
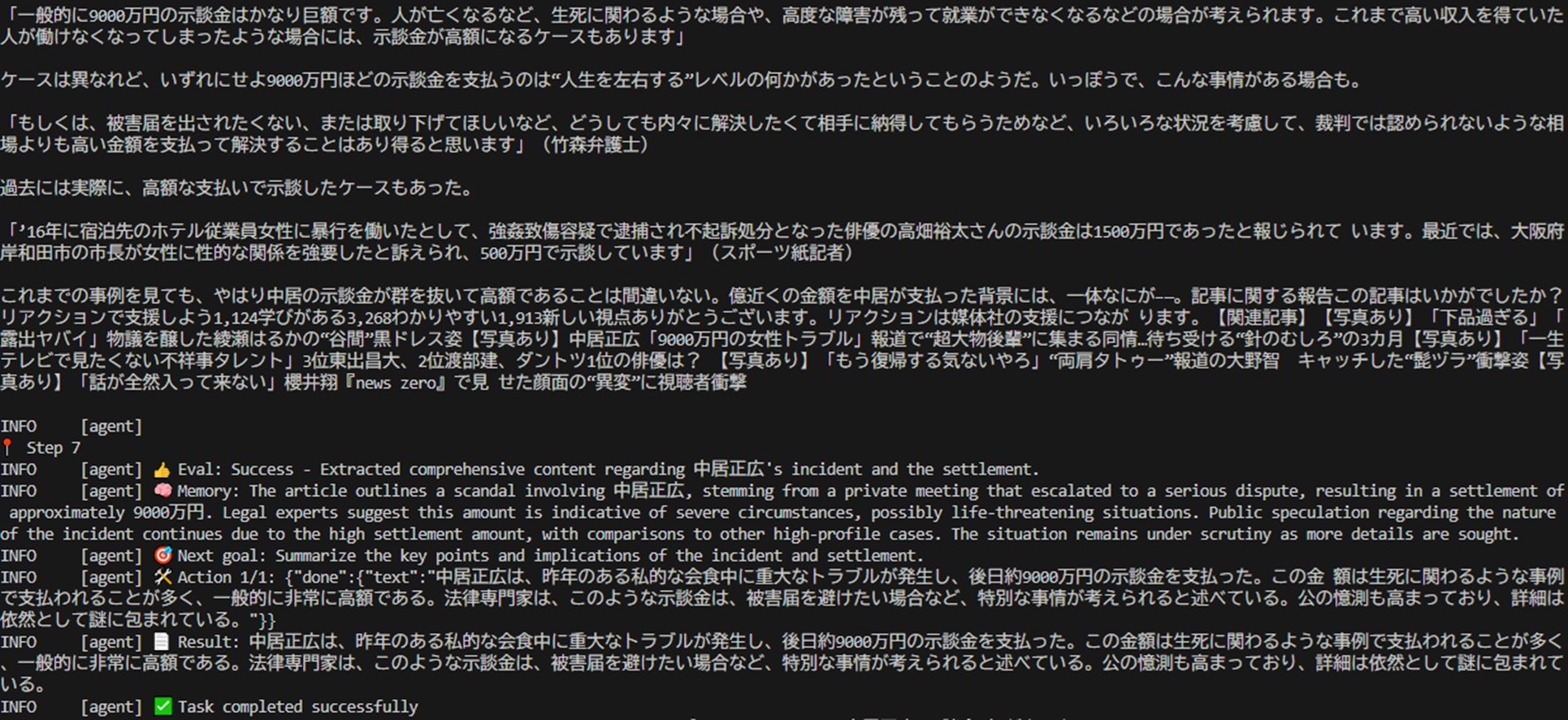
AIエージェントが自律的に処理を繰り返し、試行錯誤しながら進行している様子が伺えます。STEP7に到達して、ようやく目的の情報を取得しています。
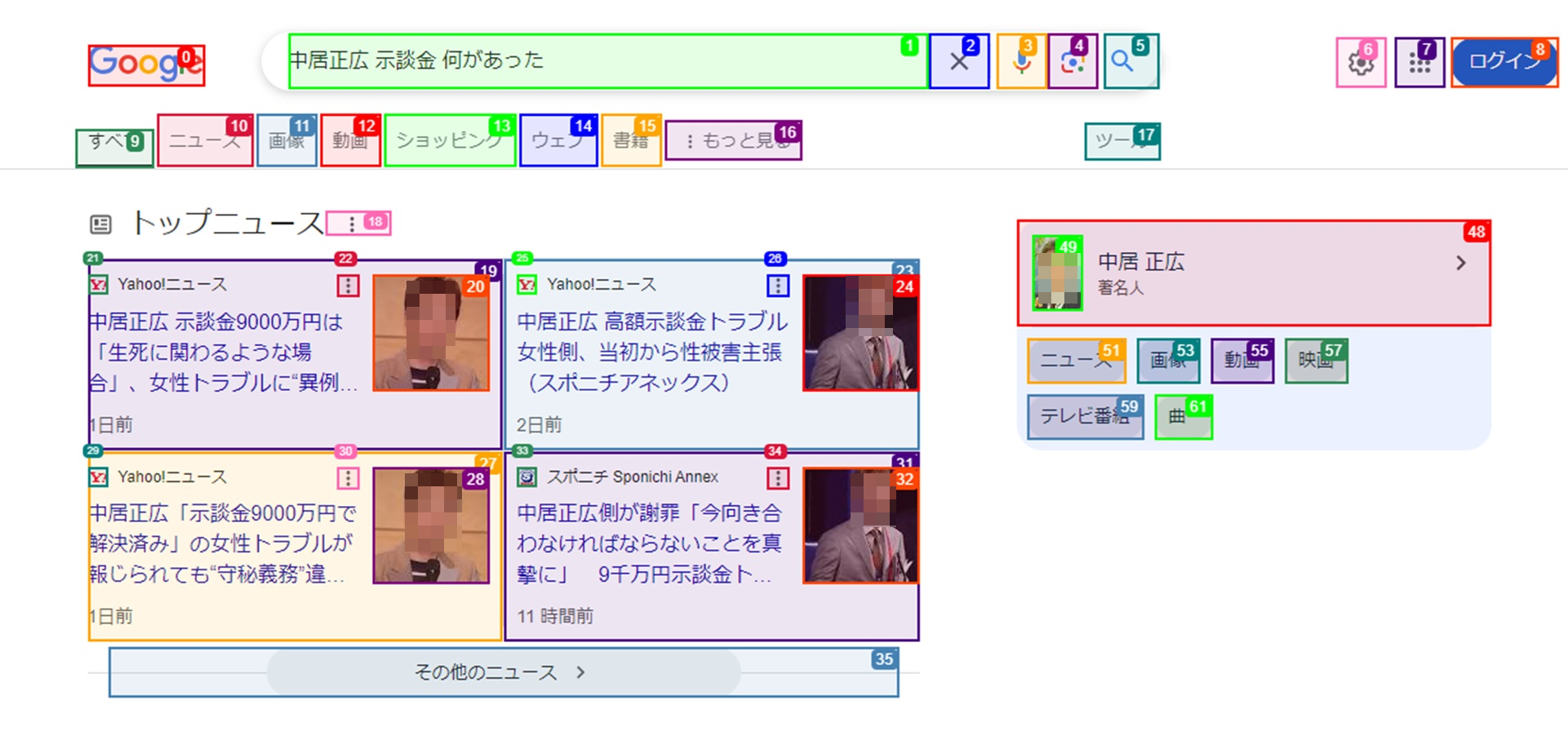
実行中のブラウザの状態
標準出力が表示される間、Google Chromeでは以下のような画面が確認できました。エージェントは関連性のありそうな要素を解析し、パーツを番号で整理していると考えられます。
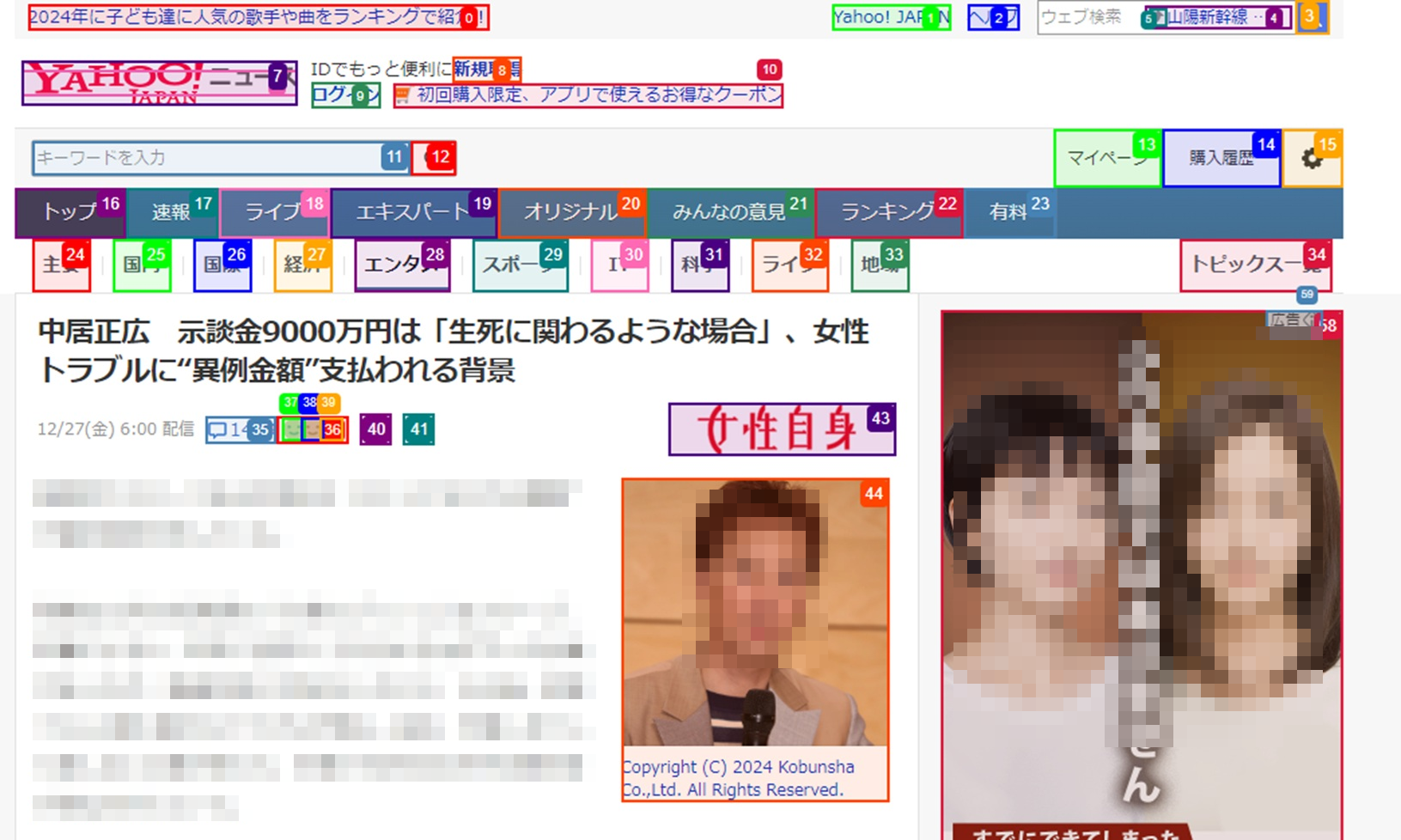
結果について
最終的な回答は、最近Web上や週刊誌で話題になっている内容を反映しているようです。
(注:筆者は週刊誌をあまり読まないため、正確性については断定できませんが、そのように見受けられます。)
おわりに
browser-useが非常に強力なツールであることが実感できました。これまでWebサイトのスクレイピングを自律的に処理を実行することはありませんでしたが、それを実現するのは非常に手間がかかります。しかし、このツールを使うことでそのプロセスが大きく簡素化されることがわかりました。
今後が非常に楽しみです。
次回は、browser-useを活用して、チャット形式での受け答えができるようにstreamlitを組み合わせて試してみたいと思います。