はじめに
Wan2.2は、アリババが開発したオープンソースの動画生成AIモデルで、ComfyUIから動作させることができます。公式のブログにも書かれていますが、大きな特徴としてはコンシューマーグレードのGPUをサポートしているため、個人などでも十分に活用できるという点ではないでしょうか。
https://blog.comfy.org/p/wan21-video-model-native-support
(コンシューマーグレードのGPUをサポート:T2V-1.3Bモデルは8.19GBのVRAMしか必要としないため、ほぼすべてのコンシューマーグレードのGPUと互換性があります。RTX 4090で約4分で5秒の480Pビデオを生成できます )
さて、前回の記事でも試行錯誤してインストールをしていたComfyUIですが、24年10月頃にComfyUI Desktopという形でアプリケーションとして展開されているのに気がつきました。ComfyUI-Managerなどもデフォルトで実装されているため、利用者はすぐに画像や動画の生成に取り掛かることが可能となります。今回は、ComfyUI Desktopを活用して、動画生成を行って見たいと思います。
手順
1.ダウンロードする

2.インストール

3.GPUを選択


4.インストール先を指定
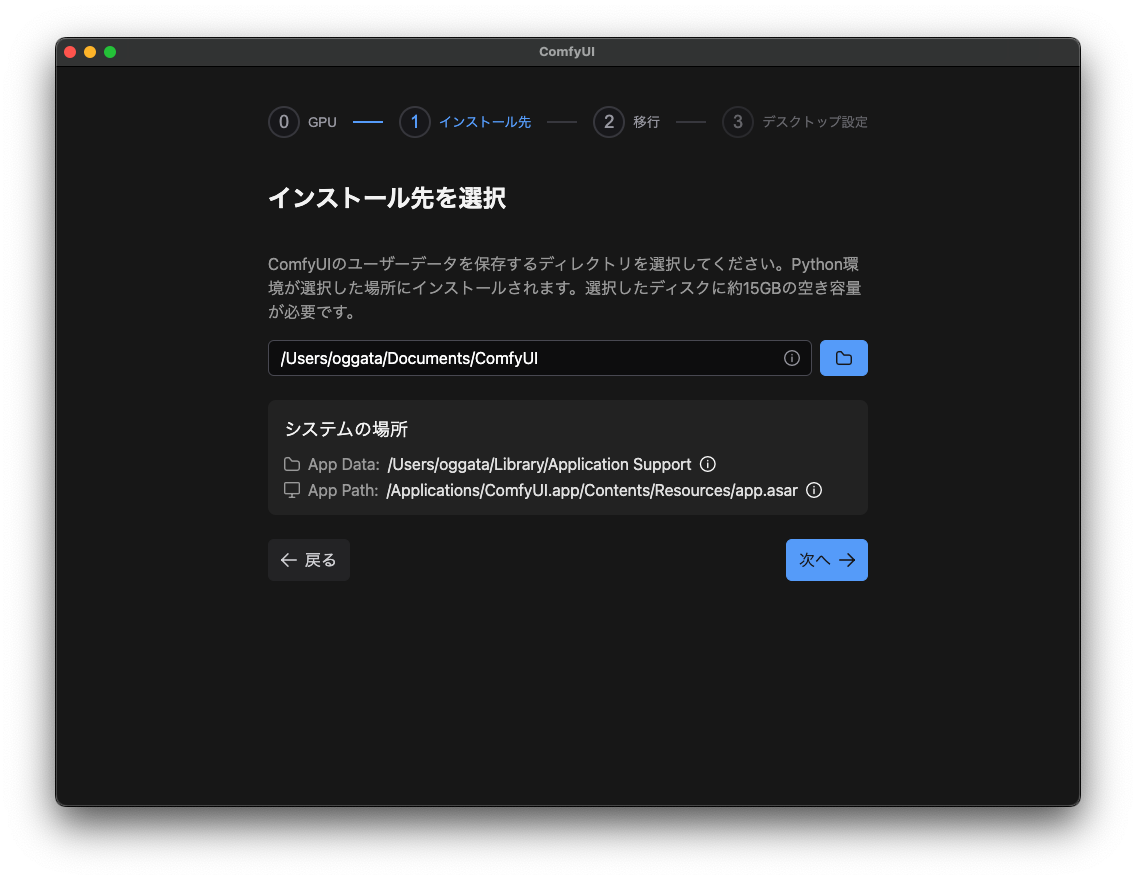
5.既存のインストール先を指定
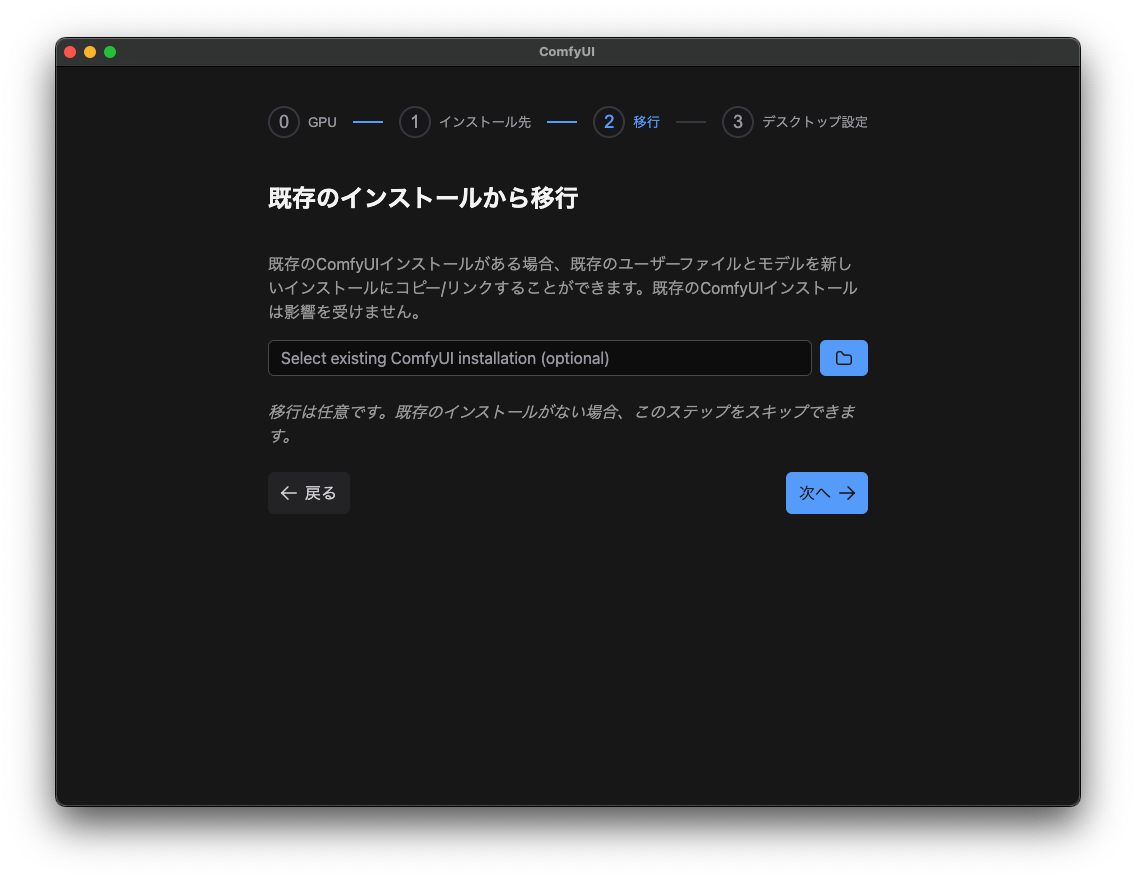
6.デスクトップアプリの設定

7.ワークフロー > テンプレート > ビデオ > Wan 2.2 を選択
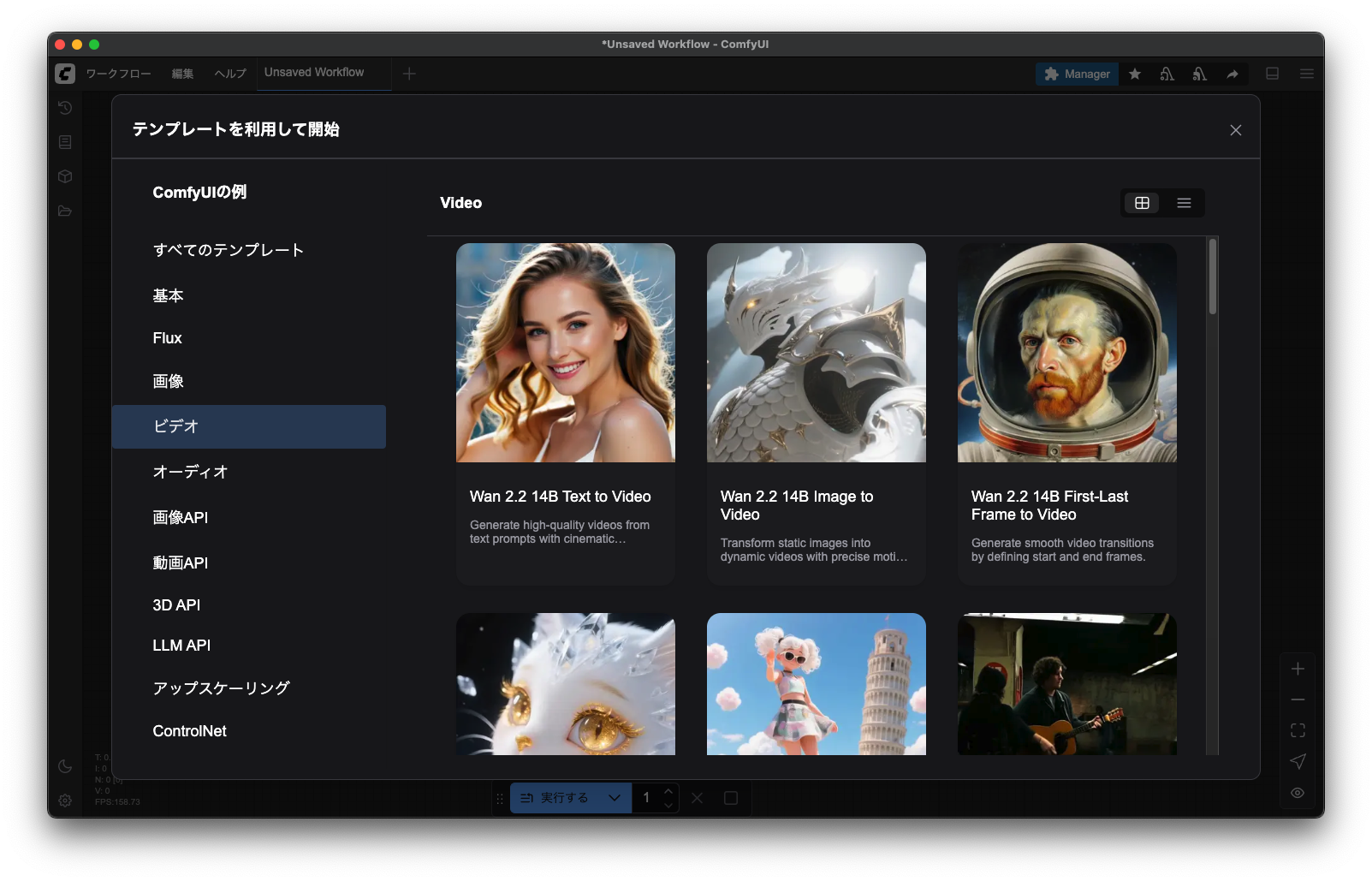
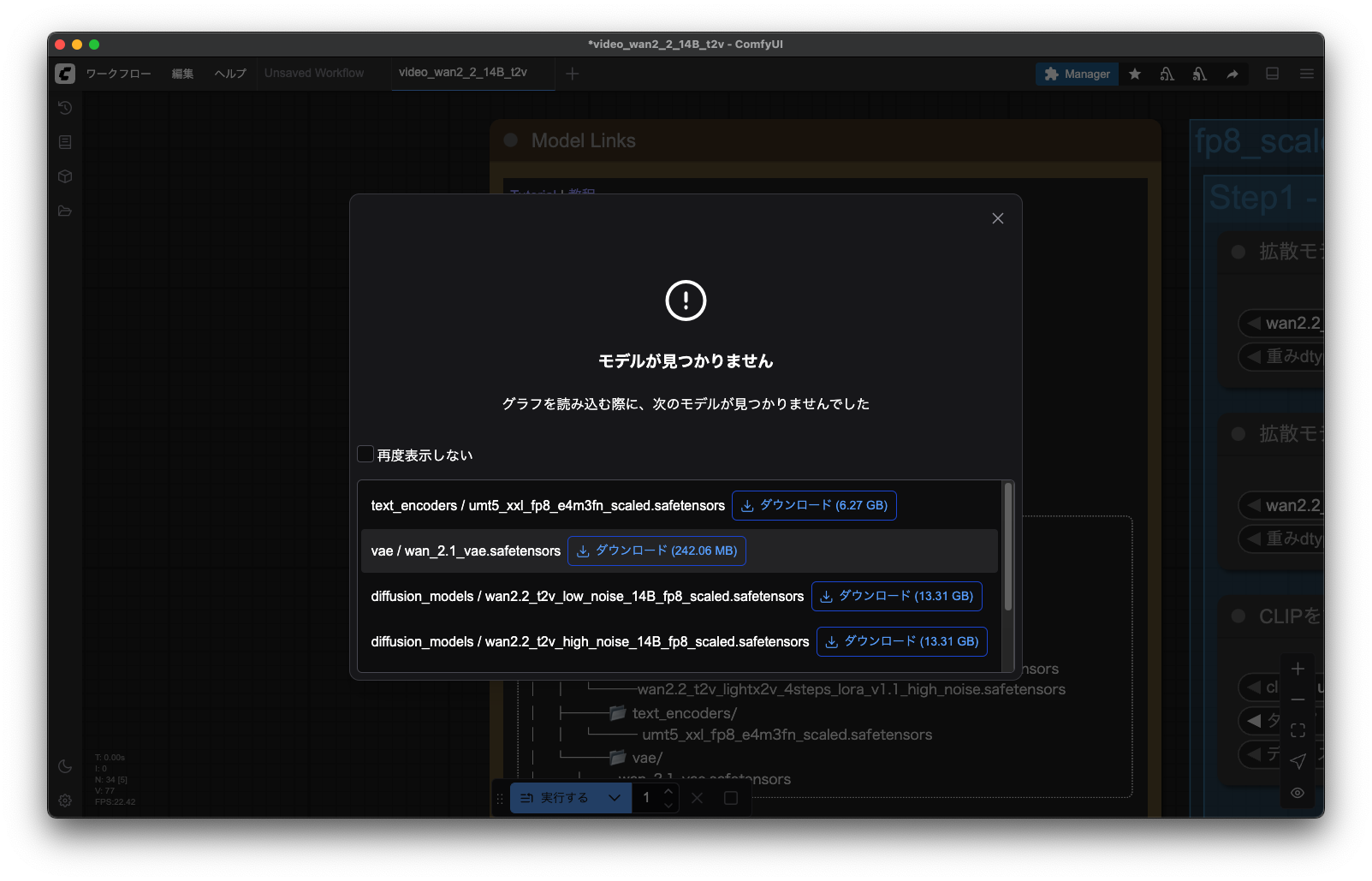
8.必要なモデルをインストール
不足しているモデルなどは自動的に表示してくれるので、ダウンロードを実行する。
ファイルの詳細については下記に記載。
ちなみに、、私の場合は、ストレージが足りなかったので、モデルは外付けストレージに変更して使いました。
設定ファイルはここ。
less /Users/UserName/Library/Application Support/ComfyUI/extra_models_config.yaml
comfyui_desktop:
is_default: "true"
custom_nodes: custom_nodes/
download_model_base: models
base_path: /Users/UserName/Documents/ComfyUI
desktop_extensions:
custom_nodes: /Applications/ComfyUI.app/Contents/Resources/ComfyUI/custom_nodes
download_model_baseはmodelsというフォルダに格納されているので、ここにシンボリックリンクを貼ってUSBドライブにモデルを置くようにしました。
cd /Users/UserName/Documents/ComfyUI
ln -s /Volumes/USB-STORAGE-NAME/ComfyUIModelsDir /Users/UserName/Documents/ComfyUI/models
9.ワークフローを開く
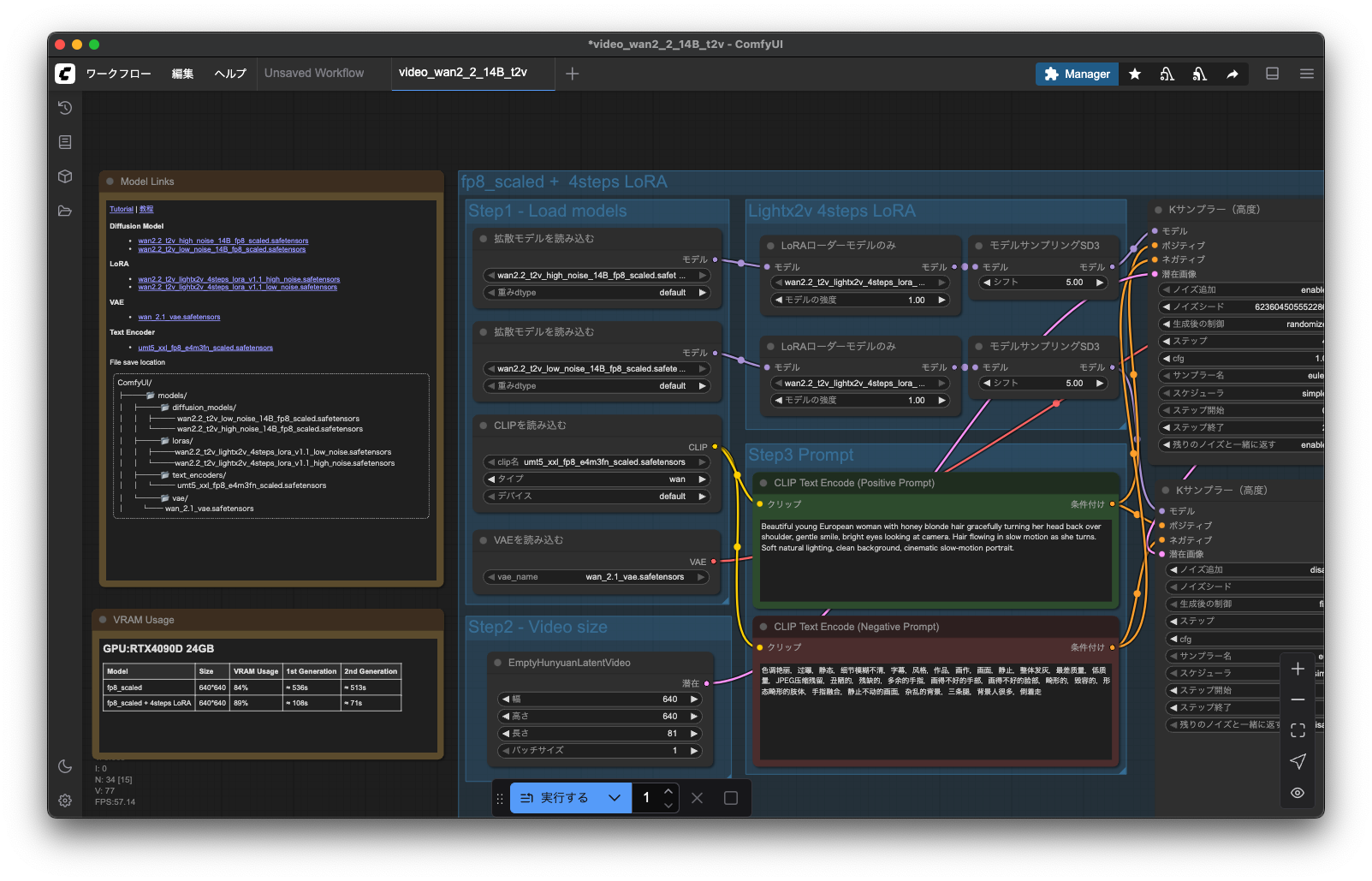
流れの説明
1. Load Models(モデル読み込み)
拡散モデルの読み込み
ファイル: wan2.1_l2v_1.3B_fp16.safetensors
これはWan2.1のメイン拡散モデルです。
役割: テキストプロンプトから動画フレームを生成する核となるニューラルネットワーク
1.3B: 13億パラメータを持つモデル
fp16: 16ビット浮動小数点精度(メモリ使用量を抑制)
l2v: Latent-to-Video(潜在空間から動画生成)を意味
CLIPモデルの読み込み
ファイル: umt5_xxl_fp3_e4m3fn_scaled.safetensors
テキストエンコーダーです。
役割: 入力されたテキストプロンプトを数値ベクトルに変換
UMT5: Unified Multimodal T5の略で、マルチモーダル対応
XXL: 最大サイズのモデル
fp3_e4m3fn: 3ビット浮動小数点(超低精度で軽量化)
2. Prompt作成
Positive Prompt(ポジティブプロンプト)
生成したい内容を記述します。
例: "A cat walking in a beautiful garden, cinematic lighting, 4K quality"
Negative Prompt(ネガティブプロンプト)
避けたい要素を記述します。
例: "blurry, low quality, distorted, ugly, watermark"
3. Kサンプラーの設定
主要パラメータ:
Steps: 推論ステップ数(20-50が一般的)
CFG Scale: プロンプト従属度(7-15推奨)
Sampler: サンプリング手法(DPM++、Euler aなど)
Scheduler: ノイズ除去スケジュール(Karras、Normalなど)
高いSteps数ほど品質向上しますが、生成時間も長くなります。
4. Video Size設定
解像度とフレーム数の指定:
Width/Height: 動画の解像度(例:512x512、768x768)
Frames: 生成フレーム数(16-64フレームが一般的)
FPS: フレームレート(通常8-24fps)
メモリ制約を考慮して適切なサイズを選択します。
5. VAE読み込み
ファイル: wan_2.1_vae.safetensors
VAE(Variational AutoEncoder)の役割:
潜在空間と画像空間の変換を担当
拡散モデルは潜在空間で動作するため、最終的な画像変換に必要
エンコード: 画像→潜在表現
デコード: 潜在表現→画像
6. VAEデコード
生成された潜在表現を実際の動画フレームに変換する処理です。
各フレームを潜在空間から画素空間に変換
色彩やディテールが復元される
最もメモリを消費する工程
7. 動画作成・保存
デコードされたフレームを動画ファイルに結合します。
フォーマット: MP4、GIF、WebMなど
品質設定: ビットレート、圧縮レベル
フレーム補間: 必要に応じてフレーム間補間

sample
howto
Error
Prompt outputs failed validation: CheckpointLoaderSimple: - Value not in list: ckpt_name: 'v1-5-pruned-emaonly-fp16.safetensors' not in []
#GoogleColabでの実行方法
本家
https://github.com/Comfy-Org/ComfyUI-Manager
の
This repository provides Colab notebooks that allow you to install and use ComfyUI, including ComfyUI-Manager. To use ComfyUI, click on this link.
から開いて、
ドライブにコピー
を押下
comfyui-frontend-package is not installed. Please install the updated requirements.txt file by running:
/usr/bin/python3 -m pip install -r /content/drive/MyDrive/ComfyUI/requirements.txt
This error is happening because the ComfyUI frontend is no longer shipped as part of the main repo but as a pip package instead.
CalledProcessError: Command '['/usr/bin/python3', '-m', 'uv', 'pip', 'install', 'PyGithub']' returned non-zero exit status 1.
フロントエンドを別リポジトリで管理
ComfyUI Manager > 「Update ComfyUI」を使用する