コンサート検索の Web アプリを個人開発しています。
アプリ紹介記事はこちら
アプリはこちら
Natural Language を用いたスクレイピングの改善
Concert Map ではスクレイピングを利用してコンサート情報を集めていますが、その際に GCP の Natural Language を用いることで開発速度の向上とデータ取得精度の向上ができそうなため、事例として紹介します。
Cloud Natural Language の公式ドキュメント
スクレイピングでやっていること
このアプリでスクレイピングをする目的は、比較的有名なコンサートの情報を集めることです。
コンサートホールやオーケストラのホームページからコンサートの情報を取得しています。
2022 年 9 月現在はユーザー登録の機能はありませんが、スクレイピングとユーザー登録機能で大半のコンサートの情報を収集できると想定しています。
- Web スクレイピング
- ホールやオーケストラで宣伝される中規模以上のコンサートが主な対象。
- ユーザ登録
- 個人の演奏家による小規模なコンサートが主な対象
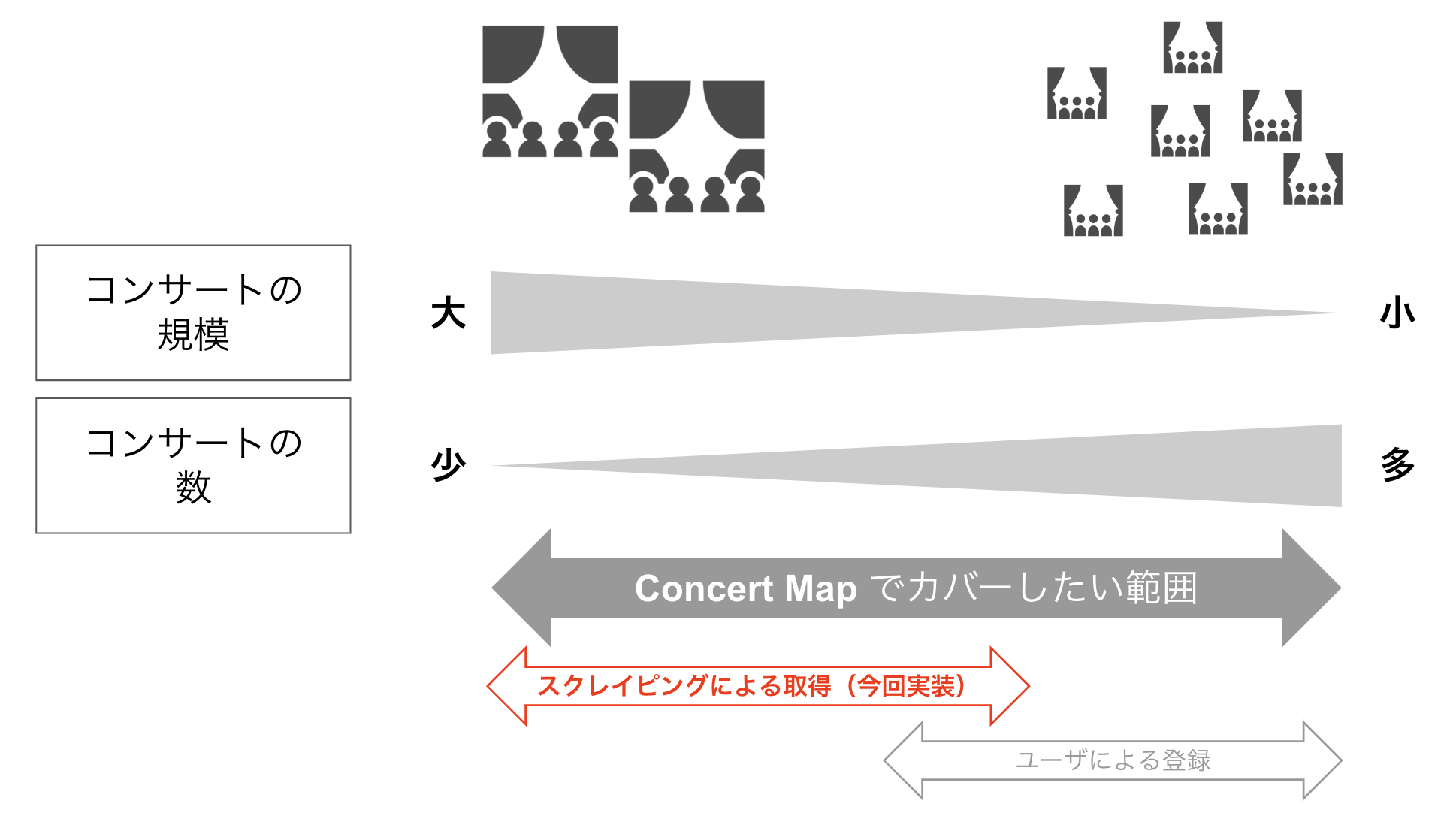
僕個人としては小規模なコンサートを聞きに行くのも好きなのですが、一般的には規模が大きいコンサートへの関心のほうが大きいでしょう。
そのためスクレイピングの取得対象となるコンサートのデータの量や質は重要です。
スクレイピング時の課題
実装に時間がかかる
スクレイピングを実装するのに 1 つのサイトで短ければ 3 時間程度、長いと 5 時間以上かかります。
またコンサートホールやオーケストラの数は 10 や 20 どころではありません。
なるべく多くのホールやオーケストラのサイトから情報を取得して掲載するコンサートの件数を増やしたいところですが、1 件あたりこれだけの時間がかかると開発工数を確保するのが難しくなってきます。
また実装に時間がかかるということはメンテナンスの時間の増加にも繋がります。
当然ですが、Web サイトのリニューアルによってサイトの構造が変わってしまうとその時点でスクレイピングが失敗するようになります。その場合は実装し直しが必要になり、そのときも最低 3 時間はかかってしまいます。
特に実装に時間がかかるのは演奏者やコンサートプログラムの取得部分の実装です。後述するように HTML の構造が曖昧な上に表記ゆれが多いため、精度高く取得しようとすればするほど実装の時間がかかってしまいます。
精度がイマイチの場合がある
Web サイトによっては構造がはっきりとしていないため、特定の情報を取得するのが難しいことあります。
特にコンサートの情報を取得する上で演奏者とプログラムの情報は HTML の構造が安定していない Web サイトが多く、単なる <p> タグで囲まれているだけのことも珍しくありません。
そのため、 HTML の構造として「この辺にはプログラムが掲載されているな」と予想してデータを取得したら次のような文字列が入ってくることがあります。
作曲者:曲名
作曲者:曲名(※当初の予定から変更しました)
作曲者:曲名(世界初演)
その他
また、コンサートプログラムは1 つの Web サイト上でも次のように表記ゆれすることがあります。
作曲者:曲名
作曲者:曲名
作曲者/曲名
作曲者 曲名
曲名(作曲者)
作曲者:曲名、作曲者:曲名
上記のようなバリエーションはあくまで一例であり、実際には様々なケースが存在しています。そのため事前に正規表現を用意して正しいデータだけを取得することが非常に困難です。
課題の解決策
前述の 2 つの課題を Natural Language を用いることで解決できるのではないかと考え、導入を検討しました。
Natural Language でできること
公式ドキュメントによると以下のことができます。
テキストを扱う 3 種類の自然言語ソリューション
AutoML
AutoML を活用した自然言語の Vertex AI を利用すると、最小限の労力と機械学習の専門知識で、高品質な独自のカスタム機械学習モデルをトレーニングし、感情の分類、抽出、検出ができます。AutoML UI を使用してトレーニング データをアップロードし、コードを 1 行も記述せずにカスタムモデルをテストできます。Natural Language API
Natural Language API の強力な事前トレーニング済みモデルは、デベロッパーがアプリケーションに自然言語理解(NLU)を簡単に適用し、感情分析、エンティティ分析、エンティティ感情分析、コンテンツ分類、構文解析などの機能を利用できるよう支援します。Healthcare Natural Language AI
構造化されていない医療文書に保存された知見をリアルタイムで分析します。Healthcare Natural Language API を使用すると、医療文書から機械で読み取り可能な医学的知見を抽出できます。一方、AutoML Entity Extraction for Healthcare は、ヘルスケアとライフ サイエンス アプリ向けのカスタム知識抽出モデルを、コーディング スキルなしで簡単に構築することを可能にします。
AutoML は独自のラベルを使用するためにモデルの構築から実施し、Natural Language API は事前に定義されたモデルをそのまま使用することができます。
参考:Cloud Natural Language API と AutoML Natural Language のどちらのツールが適切か
今回は独自のラベルを利用したいため AutoML を利用することにしました。
AutoML の利用
AutoML Natural Language はカスタムの機械学習モデルを構築してデプロイし、ドキュメントの分析、分類、エンティティの識別、態度の評価を行えるサービスです。機械学習に関するコードを一切書くことなく構築できるため、開発工数の削減や機械学習に関する学習コストの削減が狙えます。
クイックスタート によると、AutoML Natural Language は4つの別々のタスク向けにカスタムモデルをトレーニングすることができます。
- シングルラベル分類では、ドキュメントに 1 つのラベルを割り当てて分類します。
- マルチラベル分類では、1 つのドキュメントに複数のラベルを割り当てることができます
- エンティティ抽出では、ドキュメント内のエンティティを識別します。
- 感情分析では、ドキュメント内の感情的な傾向を分析します。
今回はAuto ML の中でも特にエンティティ抽出のモデルを作成します。
エンティティ抽出モデルではドキュメント中に存在するテキストに対して、ラベル付けをすることができます。
参考:AutoML Natural Language の特徴と機能
スクレイピング時の目標は、コンサートの詳細ページのテキストをまるごと取得し、その中から演奏者とコンサートプログラムのテキストを抽出することです。テキストをまるごと取得するのは実装が非常に楽で、演奏者とコンサートプログラムの実装が省けるだけで1つのスクレイピング対象サイトあたり1時間以上は工数の削減が見込めます。
取得するテキストの例は次のとおりです。
第n回 〇〇オーケストラ定期演奏会
2022年12月1日
開演: 19:00
演奏者
指揮者:指揮者名
オーケストラ:オーケストラ名
ピアノ:ピアニスト名
曲目
ショパン:ピアノ協奏曲第一番
ブラームス:交響曲第一番
料金
...
会場
...
上記のようなテキストがあったときに、演奏者と曲目でそれぞれ次のような文字列だけを抽出するのが目標です。
指揮者:指揮者名
オーケストラ:オーケストラ名
ピアノ:ピアニスト名
ショパン:ピアノ協奏曲第一番
ブラームス:交響曲第一番
導入手順
以下のように検証と実装に分けています。
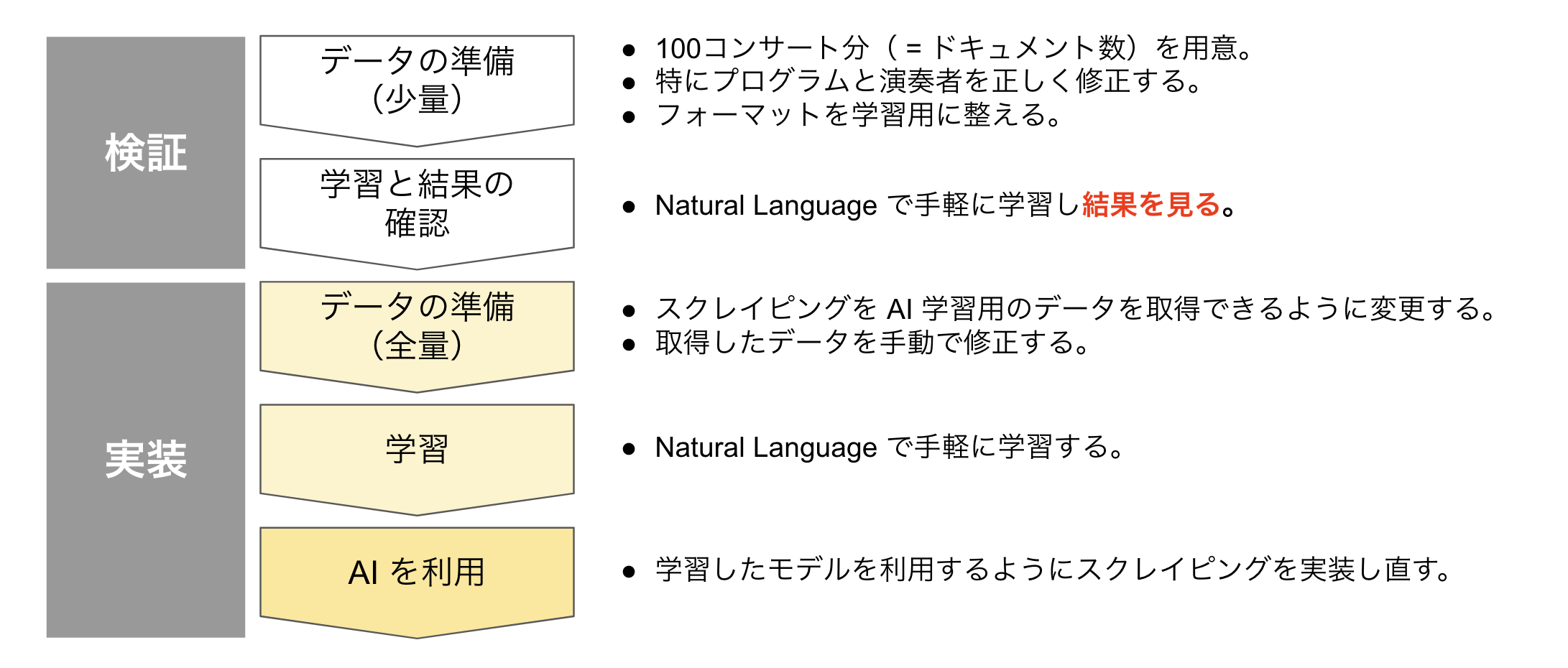
最初から全量のデータを用意して想定よりも精度が出ないと無駄手間になってしまうため、検証のフェーズを踏んでいます。
データの準備
公式ドキュメントのトレーニングデータの準備を参考にデータを準備します。
ドキュメントによると
カスタムモデルのトレーニングに使用するドキュメントは 50~100,000 個です。1~100 個の一意のラベルを使用して、モデルに抽出を学習させるエンティティにアノテーションを付けます。各アノテーションは、テキストの範囲と関連付けされたラベルです。ラベル名の文字数は 2~30 で、1~10 語のアノテーションを付けることができます。各ラベルはトレーニング データ セットで少なくとも 200 回使用することをおすすめします。
とあるため、とりあえず100個のコンサートのデータを用意しました。
トレーニングデータの準備
1つのコンサートの例としては次のようなデータになります。
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 163,
"start_offset": 141
}
},
"display_name": "title"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 68,
"start_offset": 56
}
},
"display_name": "player"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 54,
"start_offset": 45
}
},
"display_name": "player"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 29,
"start_offset": 20
}
},
"display_name": "player"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 18,
"start_offset": 1
}
},
"display_name": "player"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 79,
"start_offset": 70
}
},
"display_name": "player"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 43,
"start_offset": 31
}
},
"display_name": "player"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 110,
"start_offset": 80
}
},
"display_name": "program"
}
],
"text_snippet": {
"content": "[指揮]デニス・ラッセル・デイヴィス [ソプラノ]安井陽子 [メゾ・ソプラノ]中島郁子 [テノール]望月哲也 [バス・バリトン]山下浩司 [合唱]京響コーラス ベートーヴェン:交響曲第9番 二短調 作品125「合唱つき」 ※チケットれすQ(電子チケット)引取対象公演←詳細はコチラ 京都市交響楽団 特別演奏会「第九コンサート」"
}
},
上記の JSON データの内訳は以下のとおりです。
-
text_snippet.contentがスクレイピングでまるごと取得してくるテキストです。 -
annotations.display_nameがどのラベルかを表しています。playerとあるのが演奏者(および楽器)、programとあるのが曲目です。 -
annotations.text_extraction.text_segment以下の offset で何文字目から何文字目までがそのラベルかを表現しています。
フォーマットは JSON から JSONL に変換する必要があります。
公式ドキュメント中で JSON ファイルに変換する Python スクリプト が紹介されていますが、次のような jq コマンドを使用するのが簡単でしょう。
jq -c '.[]' training_data.json > training_data.jsonl
変換後のデータは次のように1コンサートあたり1行になります。
{"annotations":[{"text_extraction":{"text_segment":{"end_offset":163,"start_offset":141}},"display_name":"title"},{"text_extraction":{"text_segment":{"end_offset":68,"start_offset":56}},"display_name":"player"},{"text_extraction":{"text_segment":{"end_offset":54,"start_offset":45}},"display_name":"player"},{"text_extraction":{"text_segment":{"end_offset":29,"start_offset":20}},"display_name":"player"},{"text_extraction":{"text_segment":{"end_offset":18,"start_offset":1}},"display_name":"player"},{"text_extraction":{"text_segment":{"end_offset":79,"start_offset":70}},"display_name":"player"},{"text_extraction":{"text_segment":{"end_offset":43,"start_offset":31}},"display_name":"player"},{"text_extraction":{"text_segment":{"end_offset":110,"start_offset":80}},"display_name":"program"}],"text_snippet":{"content":"[指揮]デニス・ラッセル・デイヴィス [ソプラノ]安井陽子 [メゾ・ソプラノ]中島郁子 [テノール]望月哲也 [バス・バリトン]山下浩司 [合唱]京響コーラス ベートーヴェン:交響曲第9番 二短調 作品125「合唱つき」 ※チケットれすQ(電子チケット)引取対象公演←詳細はコチラ 京都市交響楽団 特別演奏会「第九コンサート」"}}
インポート CSV ファイルの作成
トレーニング用のデータを用意したら、ドキュメントごとに TRAIN VALIDATION TEST に振り分けるためのファイルを作成します。
インポート CSV ファイルの作成
今回のように1つのドキュメントしか用意しない場合、
この列に値を指定しない場合は、各行をカンマで開始して、最初の列を空であると指定します。AutoML Natural Language ではドキュメントを 3 つのセットに分け、おおよそ、データの 80% がトレーニングに、10% が検証に、10% がテストに使用されます(検証とテストに使用されるペアは最大 10,000 です)。
とあるように自動的にデータを割り当ててくれます。
この場合のインポート CSV ファイルの作成で少しハマりましたが、次のようなファイルを用意することでモデルの学習ができました。
,gs://bucket_name/training_data.jsonl
ここまでできたら Natural Language のコンソール画面からいよいよ学習させていきます。
記事が長くなってきたため、学習と導入については次回の記事にて紹介します。
おまけ
この記事の執筆時、以下のように Natural Language のページで VERTEX AI が全面的におすすめされるようになっていました。
検証開始当時、表示されていたか記憶が定かではありませんが、後日使ってみようと思います。