はじめに
これは Media Do Advent Calendar 2019 の17日目の記事です。
こんにちは、株式会社メディアドゥに入社して4ヶ月ほど経ちました、ogadyです。
突然ですが、電子書籍はEPUBというファイル形式であることが一般的です。
(EPUBって何?という方は、弊社のエンジニアブログで触れていますのでご参照ください。)
現行のシステムでは、EPUBファイルを登録するときにちゃんとした形式になっているかをチェックする処理があります。オンプレミス環境で動いているのですが、この処理が100ファイルで大体15分ほどかかります。
チェック処理をシリアルに実行しているためファイル数が増えれば増えるほど時間がかかってしまっているっぽい。
今回はEPUBチェック機能だけを切り出してLambdaで処理させたら、どれくらいパフォーマンス改善できるか、試しにやってみました。
技術スタック
- インフラ:AWS (Lambda、Lambda Layer、SQS、DynamoDB、S3、CDK)
- 開発言語:Go 1.13
- EPUBチェックツール:w3c/epubcheck
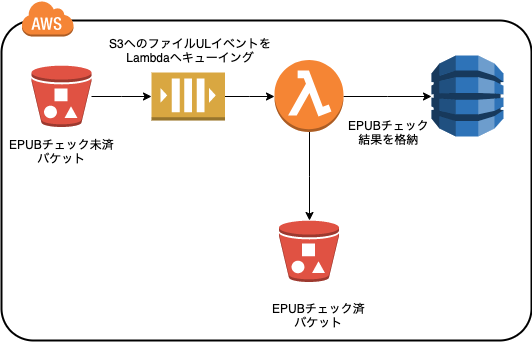
1. システム構成
- 納品されたEPUBに対してEPUBチェックをパラレルで実行するために、S3のアップロードイベントで Lambdaを発火し、同時実行させる。
- Lambdaの同時実行回数はデフォルト1,000なので、同時に1,000以上のEPUBファイルがS3にアップロードされた時のために、SQSを間にかます。
- 結果はDynamoDBに格納し、チェックが正常に完了したEPUBファイルを
EPUBチェック済みバケットに移動させる。
2. Lambda関数の実装
Usecaseの処理自体はこんな感じ
S3や、DynamoDB、SQS関連の処理は定番のものなので省略します。
package usecase
import (
"fmt"
"log"
"net/url"
"os"
"os/exec"
"strings"
"github.com/ogady/epubcheckerOnCloud/lambdaSrc/domain/model"
dynamoDBRepo "github.com/ogady/epubcheckerOnCloud/lambdaSrc/domain/repository/dynamodb"
s3Repo "github.com/ogady/epubcheckerOnCloud/lambdaSrc/domain/repository/s3"
)
type EpubCheckUsecase interface {
EpubCheck(string) error
}
type EpubCheckImpl struct {
s3Repo s3Repo.Repository
dynamoDBRepo dynamoDBRepo.Repository
}
func NewEpubCheckImpl(s3Repo s3Repo.Repository, dynamoDBRepo dynamoDBRepo.Repository) EpubCheckUsecase {
epubCheckImpl := &EpubCheckImpl{
s3Repo: s3Repo,
dynamoDBRepo: dynamoDBRepo,
}
return epubCheckImpl
}
func (u *EpubCheckImpl) EpubCheck(key string) error {
file, err := u.s3Repo.DownloadFile(key)
if err != nil {
err = fmt.Errorf("***QueryEscape エラー *** %w", err)
return err
}
res, err := execEpubCheck(file.Name())
if err != nil {
err = fmt.Errorf("***epubcheck実行時エラー*** %w", err)
return err
}
log.Printf("***EPUBチェック成功*** %#v\n", res)
splitRes := strings.Split(res, "\n")
var epubCheckInfo model.EpubCheckInfo
var epubcheckResult model.EpubcheckResult
for _, resRow := range splitRes {
switch {
case strings.Contains(resRow, "Validating"):
epubcheckResult.DefaultMessage = resRow
case strings.Contains(resRow, "No errors or warnings detected."):
epubcheckResult.CheckCompleteMesssage = resRow
case strings.Contains(resRow, "Check finished with errors"):
epubcheckResult.CheckCompleteMesssage = resRow
case strings.Contains(resRow, "SUPPRESSED"):
epubcheckResult.SuprressedMessage = resRow
case strings.Contains(resRow, "USAGE"):
epubcheckResult.UsageMessage = resRow
case strings.Contains(resRow, "INFO"):
epubcheckResult.InfoMessage = resRow
case strings.Contains(resRow, "WARNING"):
epubcheckResult.WarningMessage = resRow
case strings.Contains(resRow, "ERROR"):
epubcheckResult.ErrorMessage = resRow
case strings.Contains(resRow, "FATAL"):
epubcheckResult.FatalMessage = resRow
case strings.Contains(resRow, "Messages"):
epubcheckResult.CheckStatus = resRow
default:
}
}
/*
チェック結果をセーブする。
*/
buffKeys := strings.Split(key, "/")
fileName, err := url.QueryUnescape(buffKeys[len(buffKeys)-1])
if err != nil {
err = fmt.Errorf("***QueryEscape エラー *** %w", err)
return err
}
epubCheckInfo.UserID = "testUser"
epubCheckInfo.FileName = fileName
epubCheckInfo.Result = epubcheckResult
err = u.dynamoDBRepo.Save(epubCheckInfo)
if err != nil {
err = fmt.Errorf("***EPUBチェック結果保存失敗*** %w", err)
return err
}
/*
チェック完了したファイルをULし、チェック未済のバケットから削除する。
*/
log.Printf("***EPUBアップロード開始***\n")
err = u.s3Repo.UploadFile(key, file)
if err != nil {
err = fmt.Errorf("***EPUBアップロードエラー*** %w", err)
return err
}
err = u.s3Repo.DeleteFile(key)
if err != nil {
err = fmt.Errorf("***EPUBファイル削除エラー*** %w", err)
return err
}
log.Printf("***EPUBファイル削除完了*** %#v\n", err)
os.Remove(file.Name())
return nil
}
func execEpubCheck(filePath string) (string, error) {
encfilePath, err := url.QueryUnescape(filePath)
res, err := exec.Command("java", "-jar", "/opt/java/lib/epubcheck.jar", encfilePath).CombinedOutput()
log.Printf("Stdout of epubcheck -> %s", res)
if err != nil {
return string(res), err
}
return string(res), nil
}
標準のEPUBチェッカーがJava製なんだけど → Lambda Layer使ってみる
EPUBチェックには「W3C」が無償で提供している、w3c/epubcheckを使用します。
今回のLamda関数は社内推奨言語であるGoで作るので、java製のepubcheckツールをLambda Layerに切り出します。そしてLambda関数で、os/exec パッケージを使用して、外部コマンド発効することでEPUBチェックを実行します。
Lambda Layerにソースをアップロードする際は、Javaの場合以下のようにzipファイルにします。
hoge.zip
└ java/lib/hoge.jar
Lambda Layerは、 /opt 配下に展開されるため、Goでexec.Command() する際には/opt以下のjarファイルを指定して実行できます。
res, err := exec.Command("java", "-jar", "/opt/java/lib/hoge.jar", encfilePath).CombinedOutput()
3. AWS CDKでIaC
インフラ構成は、AWS CDKで構成します。
import cdk = require('@aws-cdk/core');
import iam = require('@aws-cdk/aws-iam');
import lambda = require('@aws-cdk/aws-lambda');
import dynamodb = require('@aws-cdk/aws-dynamodb');
import sqs = require('@aws-cdk/aws-sqs');
import s3n = require('@aws-cdk/aws-s3-notifications');
import s3 = require('@aws-cdk/aws-s3');
import { SqsEventSource } from '@aws-cdk/aws-lambda-event-sources';
import { RemovalPolicy } from '@aws-cdk/core';
export class EpubcheckerOnCloudStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// DynamoDB
const epubCheckResult = new dynamodb.Table(this, 'epubCheckResult', {
partitionKey: { name: 'file_name', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
removalPolicy: RemovalPolicy.DESTROY,
});
// Lambda Layer
const epubckeckerLayer = new lambda.LayerVersion(this, 'epubckeckerLayer', {
code: lambda.Code.asset('./lambdaLayerSrc'),
compatibleRuntimes: [lambda.Runtime.JAVA_8, lambda.Runtime.GO_1_X],
description: 'A layer to check EPUB',
});
// LambdaFunction
const lambdaFunction = new lambda.Function(this,
"epubcheckfunc", {
functionName: "epubcheckfunc",
runtime: lambda.Runtime.GO_1_X,
code: lambda.Code.asset("./lambdaSrc"),
handler: "handler",
memorySize: 1280,
timeout: cdk.Duration.minutes(15),
environment: {
"CHECKED_EPUB_BUCKET_NAME": "epub-check-completed",
"UNCHECKED_EPUB_BUCKET_NAME": "epub-check-uncompleted",
"REGION": "ap-northeast-1",
"DYNAMODB_NAME": epubCheckResult.tableName,
},
layers: [epubckeckerLayer],
});
// lambda permission for dynamoDB
epubCheckResult.grantReadWriteData(lambdaFunction)
// S3 bucket epubCheckCompleted
const epubCheckCompletedBucket = new s3.Bucket(this, "epub-check-completed", {
bucketName: "epub-check-completed",
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
removalPolicy: RemovalPolicy.DESTROY,
});
// S3 bucket epubCheckUncompleted
const epubCheckUncompletedBucket = new s3.Bucket(this, "epub-check-uncompleted", {
bucketName: "epub-check-uncompleted",
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
removalPolicy: RemovalPolicy.DESTROY,
});
// S3 , Granted for lambda permission
epubCheckCompletedBucket.grantReadWrite(lambdaFunction);
epubCheckUncompletedBucket.grantDelete(lambdaFunction);
epubCheckUncompletedBucket.grantReadWrite(lambdaFunction);
// SQS
const queue = new sqs.Queue(this, "epubCheckQueue", {
queueName: "epubCheckQueue",
visibilityTimeout: cdk.Duration.minutes(16),
});
// SQS, Granted for lambda permission
queue.grantConsumeMessages(lambdaFunction);
// S3, Add EventNotification
epubCheckUncompletedBucket.addEventNotification(s3.EventType.OBJECT_CREATED, new s3n.SqsDestination(queue), { suffix: '.epub' });
// lambda, Add EventSource
lambdaFunction.addEventSource(new SqsEventSource(queue, {
batchSize: 1,
}));
}
}
4. 使ってみよう
試しに100ファイルS3にアップロードしてみます。
CloudWatchのログはこんな感じ



× 100ファイル分
しっかり同時実行されて15秒ほどで100件のEPUBチェックが完了しました。
最初の15分と比べると圧倒的早さになりました!
後書き
今回は検証の立ち位置で実装しましたが、これを実際に現行システムから切り出せれば、大量の電子書籍が納品された時、これまでより素早く捌いていけるかなーと思います。