こんにちは。朝起きたら "#検察庁法改正案に抗議します" がTwitterトレンドに上がっていてビックリしたので分析してみました。
政治Tweetで埋まるTwitterなんてTwitterではありません。ぼくの知っているTwitterは"キンタマキラキラ金曜日"で埋まる世界です。そんなTwitterで200万も政治Tweetされるわけないじゃないですかーやだー。
安倍晋三...嘘だよな...
まずですね、前提としてこういった数字を信じてはいけませんって曽祖父が戦時中に言ってました。これをみたぼくは、「Botやスパムによる意図的なトレンド入り」をまず最初に疑いました。また、同一人物による多重投稿の恐れもあります。
幸い自分はTwitterAPIの申請を数ヶ月前に行っており、Twitter検索を自由にプログラムから触れるようになっていましたので、早速コードを書いてみたいと思います。
コーディング
from requests_oauthlib import OAuth1Session
import json
from datetime import datetime
import calendar
import csv
import time
from bs4 import BeautifulSoup
# Twitter APIにアクセスするためのコード
consumer_key = *****
consumer_key_secret = *****
access_token = *****
access_token_secret = *****
# Twitter APIにアクセス
twitter = OAuth1Session(consumer_key, consumer_key_secret, access_token, access_token_secret)
# Twitterで検索するための関数を定義する。queは検索ワード、botはbotを含めるか否か、countは取得Tweet数、max_idは検索するTweetのIDの最大値。
def get(que,max_id):
params = {'q': que, 'count': 100, 'max_id': max_id, 'modules': 'status', 'lang': 'ja'}
# Twitterへアクセス。
req = twitter.get("https://api.twitter.com/1.1/search/tweets.json", params=params)
# アクセスに成功した場合、Tweet情報を保持する。
if req.status_code == 200:
search_timeline = json.loads(req.text)
limit = req.headers['x-rate-limit-remaining']
reset = int(req.headers['x-rate-limit-reset'])
print("API remain: " + limit)
if int(limit) == 1:
print('sleep')
time.sleep((datetime.fromtimestamp(reset) - datetime.now()).seconds)
# 失敗した場合、プロセスを終了する。
elif req.status_code == 503:
time.sleep(30)
req = twitter.get("https://api.twitter.com/1.1/search/tweets.json", params=params)
if req.status_code == 200:
search_timeline = json.loads(req.text)
# API残り
limit = req.headers['x-rate-limit-remaining']
reset = int(req.headers['x-rate-limit-reset'])
print("API remain: " + limit)
if limit == 0:
print('sleep')
time.sleep((datetime.fromtimestamp(reset) - datetime.now()).seconds)
else:
print(req.status_code)
return [], 0
else:
print(req.status_code)
return [], 0
for i in range(len(search_timeline['statuses'])):
bs3obj = BeautifulSoup(search_timeline['statuses'][i]['source'], 'html.parser')
search_timeline['statuses'][i]['source'] = bs3obj.text
# この関数を実行した場合に、Tweet情報のリストを返す。
return search_timeline['statuses'], search_timeline['statuses'][-1]['id']
def TweetSearch(que, bot, rep):
max_id = 1259158522710730000 - 1
global search_timeline, tweetTime
tweetList = []
# botによるTweetを除外するか否かを指定する。
if bot:
que = str(que + ' -bot -rt')
else:
que = str(que + ' -rt')
for i in range(rep):
time.sleep(1)
result, max_id = get(que,max_id)
if max_id == 0:
break
tweetList.extend(result)
return tweetList
word = '#検察庁法改正案に抗議します'
tweetList = TweetSearch(word,False,200)
head = [i for i in tweetList[0]]
# CSVファイルに出力する
with open('tweetanalysis_02.csv','w',newline='', encoding='utf_8') as f:
writter = csv.writer(f)
writter.writerow(head)
for i in tweetList:
writter.writerow([i[key] for key in head])
速攻で仕上げるために割とガバなところがあります。
一つだけ補足しますと、TweetにはそれぞれIDが割り振られており、TweetのURL末尾18桁を見ることでそれを確認することが出来ます。
そして、そのIDの取る値はTweet時刻が遅くなるほど、大きくなっていきます。その性質を利用してTweet検索をmax_idで限定してあげることによって、複数回クエリを投げたときに重複するTweetを抜き出さないようにすることが出来ます。(1度のクエリで検索できるTweet数は100Tweetまでです)
データを眺めてみる
このプログラムを動かし、
5/9 23:46 - 5/10 2:58までの37935 TweetsをCSVに保存しました。
この時点で圧倒的に100万に到達しないことがわかります。
(実際はこの時点でトレンドには100万 Tweetsを超える表記があったはずです)
ちなみに取得したデータには'retweet_count'という項目があり、取得したそれぞれTweetが何回Retweetされたのかを知ることが出来ます。
それを簡単に足し合わせてみると、391675となるため、TwitterのトレンドはRetweetを含めたものであると考えたほうが良さそうです。(実際は5/9 23:46以前のTweetもトレンドに寄与していると考えられるため)
また、最初に提起した疑問である
・同一ユーザーによる投稿
・Bot,スパム投稿
を簡易的に検証してみます。ぼくはCSVをRなどの統計ソフトで扱えるほど凄い人間ではないので、今回は古典的手法ですがExcelを用いて簡易的にやってみます。(データ量もそこまで多くなく、自分のPCなら耐えられると踏んだため)
[データ]タブに[重複の削除]という項目から、'user'にチェックを入れ、
削除!

おお。
約1/4のTweetが重複ユーザーとして削除されました。
もちろんこれだけでは同一ユーザーがめちゃくちゃTweetしたのか、たくさんのユーザーが複数回Tweetされたのかはわかりませんが、少なくともツイートしているユーザー数は見かけよりずっと少ないことがわかります。
次にデータ投稿元を調べましょう。これはユーザーの重複を削除したデータを分析しています。
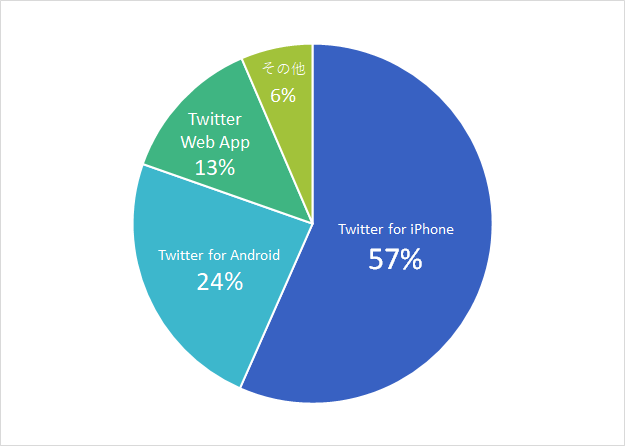
Twitter for iPhoneが半分以上を占める結果となりました。また、その他に関しても'Twitter for iPad', 'Twitter Web Client'などの公式クライアントや、非公式クライアントなどが多く、自動投稿やスパムによるTweetは無視できるほど少ないことがわかります。(ちなみに自作のTweet投稿元に'Twitter'の文字列を含めるものは設定できないため、Twitterが文字列に含まれている以上はスパムによる投稿は100%ないと断定できます。)
簡易的ではありますが、Twitterのトレンドについて解析してみました。
Pythonコードと取得したCSVファイルをgithubにアップロードしました。
https://github.com/ogadra/twitter_analysis
次回はデータを増やしてRなどで解析してみたいと考えています。
追記
よく分からないけど、取得漏れはあるみたいです。
これはTwitterAPIの使用なのか、自分が悪いのかまだわからないので再度取得を試みます。