Python で手書き文字認識をするチュートリアルはよくあるんですが、既存のデータセットを使って「はい予測精度90%でました」ばかりで、「僕の数字も認識してくれよ!」ってなります。せっかくなので数字を自分で手書きして、 AI(えーあい) に認識してもらうアプリケーションを作ります。(ウィンドウの描画に使用したゲームエンジンpyxelについては記事末尾に参考リンクをまとめておきます。)
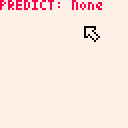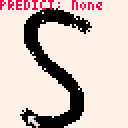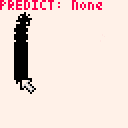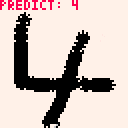
文字を書いてsを押すと、その数字を予測します。コード全体はこちら(pyxelDigitRecognition)
注意:機械学習を使いますが、遊びの記事なので全然厳密ではありません。
この記事の対象読者
-
ペイントソフトを作りたい人
-
手書き文字認識をしてみたい人
-
(適当な実装を許してくれる人)
環境
-
scikit-learn 0.21.3
-
pyxel 1.2.4
-
Windows 10
記事の流れ
- Pyxel でペイントソフトをつくる
- digit データセットで学習
- 予測してみる
1. Pyxel でペイントソフトをつくる
まず単純なお絵描きソフトを作ります。
作り方はかなり簡単で以下のようにします。
画面の各ピクセルを表す二次元配列を作る(今回は64x64)
WHILE True: # 各フレームで
if マウスをドラッグ中:
マウスの座標の色を変える
二次元配列をもとに画面を描画
実装の際はマウスの座標の周りも同時に色を変えて、太い線を描画しています(下図)。
ペイントソフト(クリックで展開)
# constants
WINDOW_SIZE = 64
# 0 white, -1 black ウィンドウの色情報
windowData = [[0]*WINDOW_SIZE for _ in range(WINDOW_SIZE)]
pyxel.init(WINDOW_SIZE, WINDOW_SIZE) # window 初期化
pyxel.mouse(visible=True)
def update():
if pyxel.btnp(pyxel.MOUSE_LEFT_BUTTON, hold=2, period=1):
# マウスの座標の色を変える
x, y = pyxel.mouse_x, pyxel.mouse_y
if 0 <= x < pyxel.width and 0 <= y < pyxel.height:
windowData[y][x] = -1
def draw():
pyxel.cls(pyxel.COLOR_WHITE)
for y in range(pyxel.height):
for x in range(pyxel.width):
if windowData[y][x]==-1:
pyxel.pix(x, y, pyxel.COLOR_BLACK)
pyxel.run(update, draw)
できたのはこれ。

2. digit データセットで学習
データを集めるのはめんどくさいので、sklearn の digit データセットを使用します。
これは手書き数字認識でよく使用される MNIST を小さくした?感じのデータセットで、
- 8x8 ピクセル
- 16段階グレースケール
- 10 クラス(0~9)
- データ数:1797
です。公式ドキュメントによればこんな画像が入っています。

分類は k近傍法を使用してみました。k近傍法は先人が説明し尽くしているので、リンクだけ貼ります。
●アルゴリズム
OpenCV documentation
●irisデータへの使用例
K近傍法(多クラス分類)
学習するコード(クリックで展開)
def train():
digits = load_digits()
X = digits.data
y = digits.target
X_train,X_test,y_train,y_test = train_test_split(X, y)
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test)) # 0.98
# save model
with open('knn_digit.pkl', 'wb') as f:
pickle.dump(knn, f)
交差検証も何もしていませんが、遊びなのでこれでよしとします。(せいど98%!)
3. 予測してみる
学習できた()ので実際に予測してみます。
お絵描きの画面は 64x64, RGB なので、予測する前に 8x8, 16段階グレースケールに変換することに気を付けます。今回はウィンドウを 8x8 の画像で保存し、それを読みだして数字認識をします。
予測するコード(クリックで展開)
def predict() -> int:
with open('knn_digit.pkl', 'rb') as f:
loaded_model = pickle.load(f)
img = Image.open("images/screen_shot.png") # ウィンドウの画像
img = img.convert('L') # convet (r,g,b) to 0-255
img = (255 - np.array(img))//16 + 1 # convert to 0-15
img = img.reshape(1, 64)
pred = loaded_model.predict(img)[0] # np.array to int
return pred
これで数字認識ができるようになりました。大きく丁寧に書くと結構認識できます!
ただ 8x8 に圧縮してるので、小さい数字や細い文字は予測できないのであしからず。
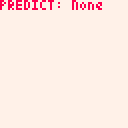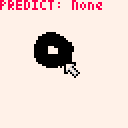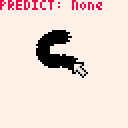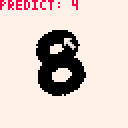
上のgifの「8」は小さく書きすぎて、 8x8 ピクセルにすると潰れてしまうのが原因です(画像ちっさい…)。

最後に
簡単にまとめましたが、pickleで学習モデルを読み込むとPyxelのウィンドウが落ちてしまうのが治せず結構困ったりしました。(モデルの読み込みを別のpythonファイルで実行するとなぜかうまく行きました…)
今回のアルゴリズムもデータセットも全く実用に耐えるものではありませんが、アプリケーションにすると中々面白かったです!
お気づきの点がありましたら、ご意見お待ちしております。